Изучаем MySQL
Получите доступ к своим данным
Винисиус М. Гриппа и Сергей Кузьмичев
Второе издание, 2021
перевод В.Айсин
Благодарности за Learning MySQL, второе издание
Прошло много времени с тех пор, как была опубликована хорошая книга, посвященная MySQL и ее экосистеме, и с тех пор произошло много изменений. Многие темы четко освещены примерами, от установки и проектирования баз данных до обслуживания и архитектуры для высокой доступности и облака. Также рассматриваются многие сторонние инструменты, такие как dbdeployer и ProxySQL, которые являются хорошими друзьями администраторов баз данных MySQL, но часто не упоминаются в литературе. Очень хорошая работа Винисиуса и Сергея. Не пропустите последнюю главу — это очень интересно!
— Фредерик Декамп, евангелист MySQL в Oracle
Прежде всего, я хочу поблагодарить Винисиуса и Сергея за то, что они сделали возможной книгу моих мечтаний для всех новичков в MySQL, пока я работаю над версией для разработчиков. Эта книга предлагает наиболее полную информацию о MySQL, не только о том, как начать работу, но и по таким сложным темам, как высокая доступность и балансировка нагрузки. Это гладкое чтение с хорошо организованным содержанием, соответствующим качеству публикации O'Reilly. Я настоятельно рекомендую эту книгу всем читателям, от разработчиков до операторов.
— Алкин Тезуйсал, старший технический менеджер PlanetScale
Эта книга — потрясающий ресурс, независимо от того, устанавливаете ли вы MySQL в первый раз, изучаете балансировку нагрузки или переносите базу данных в облако. Я очень ее рекомендую.
— Бретт Холлеман, инженер-программист
Эта книга необходима всем, кто хочет погрузиться в экосистему MySQL. Благодаря четкому и объективному общению он охватывает темы от базовых до продвинутых. Просто незаменимая книга для расширения знаний MySQL.
— Диего Эллас, генеральный директор PerformanceDB
Проводит читателя через все важные концепции MySQL, от основ SQL и моделирования данных до сложных тем, таких как высокая доступность и облако, используя ясный, краткий, прямой язык.
— Чарли Батиста, Percona
Предисловие
Системы управления базами данных являются частью ядра многих компаний. Даже если бизнес не ориентирован на технологии, ему необходимо хранить, получать доступ и управлять данными быстрым, безопасным и надежным способом. Из-за пандемии COVID-19 многие области, которые традиционно сопротивлялись цифровой трансформации, такие как судебные системы во многих странах, теперь интегрируются с помощью технологий из-за ограничений на поездки и встречи, а онлайн-покупки и работа на дому популярны как никогда прежде.
Но не только стихийные бедствия привели к таким далеко идущим изменениям. С появлением 5G у нас скоро будет гораздо больше машин, подключенных к Интернету, чем людей. Огромные объемы данных уже собираются, хранятся и используются для обучения моделей машинного обучения, искусственного интеллекта и многого другого. Мы живем в начале следующей революции.
Появилось несколько типов баз данных, помогающих хранить больше данных, особенно неструктурированных данных, включая базы данных NoSQL, такие как MongoDB, Cassandra и Redis. Однако традиционные базы данных SQL остаются популярными, и нет никаких признаков того, что они исчезнут в ближайшем будущем. И в мире SQL, несомненно, самым популярным решением с открытым исходным кодом является MySQL.
Оба автора этой книги работали со многими клиентами со всех уголков мира. За это время мы извлекли много уроков и испытали огромное количество вариантов использования, начиная от критически важных монолитных приложений и заканчивая более простыми приложениями микросервисов. Эта книга полна советов и рекомендаций, которые, как мы думаем, большинство читателей сочтут полезными в своей повседневной деятельности.
Для кого эта книга
Эта книга в первую очередь предназначена для тех, кто впервые использует MySQL или изучает ее как вторую базу данных. Если вы впервые выходите на арену баз данных, первые главы познакомят вас с концепциями проектирования баз данных и покажут, как развертывать MySQL в различных операционных системах и в облаке.
Для тех, кто работает в другой экосистеме, такой как Postgres, Oracle или SQL Server, в книге рассматриваются стратегии резервного копирования, высокой доступности и аварийного восстановления.
Мы надеемся, что все читатели сочтут эту книгу хорошим дополнением к изучению или обзору основ, от архитектуры до рекомендаций по производственной среде.
Как устроена эта книга
Мы знакомим вас со многими темами, от основного процесса установки, дизайна базы данных, резервного копирования и восстановления до анализа производительности процессора и исследования ошибок. Мы разделили книгу на четыре основные части:
Начало с MySQL
Использование MySQL
MySQL в производстве
Разные темы
Давайте посмотрим, как мы организовали главы.
Начало с MySQL
В главе 1, Установка MySQL объясняется, как установить и настроить программное обеспечение MySQL в различных операционных системах. В этой главе содержится гораздо больше деталей, чем в большинстве книг. Мы знаем, что те, кто начинает свою карьеру с MySQL, часто незнакомы с различными дистрибутивами Linux и вариантами установки, а для запуска «hello world» MySQL требуется гораздо больше шагов, чем для компиляции hello world на любом языке программирования. Вы увидите, как настроить MySQL в Linux, Windows, macOS и Docker, а также как быстро развернуть экземпляры для тестирования.
Использование MySQL
Прежде чем углубиться в создание и использование баз данных, мы рассмотрим правильное проектирование базы данных в главе 2, Моделирование и проектирование баз данных. Вы узнаете, как получить доступ к функциям вашей базы данных, и увидите, как элементы информации в вашей базе данных связаны друг с другом. Вы увидите, что плохой дизайн базы данных сложно изменить, и это может привести к проблемам с производительностью. Мы введем понятие сильных и слабых сущностей и их взаимосвязей (внешних ключей (foreign keys)) и объясним процесс нормализации. В этой главе также показано, как загружать и настраивать примеры баз данных, такие как sakila, world и employee.
В главе 3, Основы SQL мы исследуем знаменитые команды SQL, являющиеся частью операций CRUD (создание, чтение, обновление и удаление (create, read, update, delete)). Вы увидите, как читать данные из существующей базы данных MySQL, сохранять в ней данные и манипулировать существующими данными.
В главе 4, Работа со структурами баз данных мы объясняем, как создавать новую базу данных MySQL, а также создавать и изменять таблицы, индексы и другие структуры баз данных.
Глава 5, Расширенные запросы охватывает более сложные операции, такие как использование вложенных запросов и использование различных механизмов баз данных MySQL. Эта глава даст вам возможность выполнять более сложные запросы.
MySQL в производстве
Теперь, когда вы знаете, как установить MySQL и манипулировать данными, следующим шагом будет понимание того, как MySQL обрабатывает одновременный доступ к одним и тем же данным. Концепции изоляции, транзакций и взаимоблокировок рассматриваются в главе 6, Транзакции и блокировка.
В главе 7, Дополнительные возможности MySQL вы увидите более сложные запросы, которые вы можете выполнять в MySQL, а также узнаете, как наблюдать за планом запроса, чтобы проверить, эффективен ли запрос или нет. Мы также расскажем о различных механизмах, доступных в MySQL (наиболее известными являются InnoDB и MyISAM).
В главе 8, Управление пользователями и привилегиями вы узнаете, как создавать и удалять пользователей в базе данных. Этот шаг является одним из самых важных с точки зрения безопасности, поскольку пользователи с большими привилегиями, чем им нужно, могут нанести значительный ущерб базе данных и репутации компании. Вы увидите, как устанавливать политики безопасности, давать и удалять привилегии и ограничивать доступ к определенным сетевым IP-адресам.
Глава 9, Использование файлов опций посвящена файлам конфигурации MySQL или файлам опций, которые содержат все необходимые параметры для запуска MySQL и оптимизации ее производительности. Те, кто знаком с MySQL, узнают файл конфигурации /etc/my.cnf. Вы также увидите, что можно настроить доступ пользователей с помощью специальных файлов параметров.
Базы данных без политик резервного копирования рано или поздно обречены на катастрофу. В главе 10, Резервное копирование и восстановление мы обсудим различные типы резервных копий (логические и физические), варианты, доступные для выполнения этой задачи, и те, которые больше подходят для больших производственных баз данных.
В главе 11, Конфигурирование и настройка сервера обсуждаются основные параметры, на которые необходимо обратить внимание при настройке нового сервера. Мы предоставляем формулы для этого и помогаем определить, является ли значение параметра правильным для рабочей нагрузки базы данных.
Разные темы
Установив самое необходимое, пришло время выйти за рамки. В главе 12, Мониторинг серверов MySQL рассказывается, как отслеживать базу данных и собирать из нее данные. Поскольку поведение рабочей нагрузки базы данных может меняться в зависимости от количества пользователей, транзакций и обрабатываемых данных, крайне важно определить, какой ресурс перегружен и что вызывает проблему.
В главе 13, Высокая доступность объясняется, как реплицировать серверы для обеспечения высокой доступности. Мы также представляем концепцию кластера, выделяя два решения: кластер InnoDB и кластер Galera/PXC.
Глава 14, MySQL в облаке расширяет вселенную MySQL до облака. Вы узнаете о варианте «база данных как услуга» (DBaaS) и о том, как использовать управляемые службы баз данных, предоставляемые тремя наиболее известными поставщиками облачных услуг: Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure.
В главе 15, Балансировка нагрузки MySQL мы покажем вам наиболее часто используемые инструменты для распределения запросов между различными серверами MySQL, чтобы добиться еще большей производительности от MySQL.
Наконец, в главе 16, Разное представлены более продвинутые методы и инструменты анализа, а также немного программирования. В этой главе мы поговорим о MySQL Shell, Flame Graph и о том, как анализировать ошибки.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские соглашения:
- Курсив
- Указывает новые термины, URL-адреса, адреса электронной почты, имена файлов и расширения файлов.
Моноширный шрифт- Используется для листингов программ, а также внутри абзацев для ссылки на элементы программы, такие как имена переменных или функций, базы данных, типы данных, переменные среды, операторы и ключевые слова.
Моноширный жирный- Показывает команды или другой текст, который пользователь должен ввести буквально.
Моноширный курсив- Показывает текст, который следует заменить значениями, заданными пользователем, или значениями, определенными контекстом.
Использование примеров кода
Примеры кода доступны для загрузки по адресу https://github.com/learning-mysql-2nd/learning-mysql-2nd (и локально learning_mysql/learning-mysql-2nd-main.zip).
Если у вас есть технический вопрос или проблема с использованием примеров кода, отправьте электронное письмо по адресу bookquestions@oreilly.com.
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. В общем, если к этой книге прилагается пример кода, вы можете использовать его в своих программах и документации. Вам не нужно обращаться к нам за разрешением, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, разрешения не требуется. Для продажи или распространения примеров из книг O'Reilly требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и код примера, разрешения не требуется. Включение значительного количества примеров кода из этой книги в документацию по вашему продукту требует разрешения.
Мы ценим, но обычно не требуем указания авторства. Атрибуция обычно включает название, автора, издателя и ISBN. Например: «Learning MySQL, 2nd ed., by Vinicius M. Grippa and Sergey Kuzmichev (O’Reilly). Copyright 2021 Vinicius M. Grippa and Sergey Kuzmichev, 978-1-492-08592-8».
Если вы считаете, что использование вами примеров кода выходит за рамки добросовестного использования или разрешений, данных выше, не стесняйтесь обращаться к нам по адресу permissions@oreilly.com.
Благодарности
От Винисиуса Гриппы
Спасибо следующим людям, которые помогли улучшить эту книгу: Корбину Коллинзу, Чарли Батисте, Сами Алрусу и Бретту Холлеману. Без них эта книга не достигла бы того совершенства, к которому мы стремились.
Спасибо сообществу MySQL (особенно Шломи Ноаку, Джузеппе Максиа, Джереми Коулу и Брендану Греггу) и всем блоггерам Planet MySQL, Multiple Nines, Percona Blog и MySQL Entomologist, которые предоставили так много материала и так много замечательных инструментов.
Спасибо всем в Percona, которые предоставили средства для написания этой книги, особенно Бенни Гранту, Карине Пунцо и Марсело Альтманну, и тем, кто помог мне вырасти как профессионалу и человеку.
Спасибо сотрудникам O'Reilly, которые отлично справляются с изданием книг и проведением конференций.
Я хочу поблагодарить своих родителей Дивалдо и Регину, мою сестру Юлиану и мою подругу Карин за терпение и поддержку этого проекта во многих отношениях. Особая благодарность Пауло Пифферу, который дал мне первую возможность работать с тем, что я люблю.
И наконец, Сергею Кузьмичеву, соавтору этой книги. Без его опыта, самоотверженности и тяжелой работы эта книга была бы невозможна. Я благодарен ему за то, что он был моим коллегой, и за то, что я имел честь работать с ним над этим проектом.
От Сергея Кузьмичева
Я хотел бы поблагодарить мою жену Кейт за поддержку и помощь на каждом этапе этого сложного, но полезного проекта. От размышлений о том, стоит ли браться за написание этой книги, до многих трудных дней ее написания, она была рядом. Наш первый ребенок родился, когда книга была написана, и все же Кейт нашла время и силы, чтобы продолжать мотивировать и помогать мне.
Спасибо моим родителям, родственникам и друзьям, которые на протяжении многих лет помогали мне расти как личности и как специалисту. Спасибо, что поддержали меня в этом проекте.
Спасибо замечательным людям из Percona за помощь со всеми техническими и нетехническими вопросами и проблемами, которые у меня возникли при написании этой книги: Иво Пановичу, Пшемыславу Малковскому, Свете Смирновой и Маркосу Альбе. Спасибо Стюарту Беллу и всем сотрудникам службы поддержки Percona за невероятный уровень помощи, которую мы получали на каждом этапе пути.
Спасибо всем в O'Reilly за руководство и помощь в создании этого издания. Спасибо Корбину Коллинзу за помощь в формировании структуры книги и за то, что мы твердо придерживаемся нашего пути. Спасибо Рэйчел Хед за обнаружение множества проблем на этапе редактирования и за выявление проблем с техническими деталями MySQL в нашем тексте. Без вас и всех сотрудников O'Reilly эта книга не была бы книгой, а просто набором слабо связанных слов.
Особая благодарность нашим техническим редакторам Сами Алрусу, Бретту Холлеману и Чарли Батисте. Они сыграли важную роль в обеспечении высочайшего качества технического и нетехнического содержания этой книги.
Спасибо всем в сообществе MySQL за то, что они открыты, полезны и делятся своими знаниями всеми возможными способами. Мир MySQL — это не огороженный сад, а открытый для всех. Я хотел бы упомянуть Валерия Кравчука, Марка Каллагана, Дмитрия Кравчука и Джереми Коула за то, что они помогли мне через их блоги лучше понять внутреннее устройство MySQL.
Я хочу поблагодарить авторов первого издания этой книги: Хью Э. Уильямса и Сейеда М. М. Тахагоги. Благодаря их работе мы построили этот проект на прочном фундаменте.
Наконец, что не менее важно, я хотел бы поблагодарить Винисиуса Гриппу за то, что он был прекрасным соавтором и коллегой. Без него эта книга была бы другой.
Это издание я посвящаю своему сыну Григорию.
Глава 1
Установка MySQL
Давайте начнем наш путь обучения с установки MySQL и первого доступа к ней.
Обратите внимание, что в этой книге мы не полагаемся на одну версию MySQL. Вместо этого мы будем использовать наши коллективные знания MySQL в реальном мире. Основное внимание в книге уделяется операционным системам Linux (в основном Ubuntu/Debian и CentOS/RHEL или их производным), а также MySQL 5.7 и MySQL 8.0, поскольку именно их мы считаем «текущими» версиями, способными выполнять рабочие нагрузки. Серии MySQL 5.7 и 8.0 все еще находятся в стадии разработки, а это означает, что новые версии с исправлениями ошибок и новыми функциями будут продолжать выпускаться.
Поскольку MySQL становится самой популярной базой данных с открытым исходным кодом (Oracle, занимающий первое место, не является открытым исходным кодом), потребность в быстром процессе установки возросла. Вы можете думать об установке MySQL с нуля, как о выпечке пирога: исходный код — это рецепт. Но даже при наличии исходного кода рецепт создания программного обеспечения не так прост. Для компиляции требуется время, и обычно необходимо установить дополнительные библиотеки разработки, которые подвергают производственную среду риску. Скажем, вы хотите шоколадный торт; даже если у вас есть инструкции, как испечь его самостоятельно, вы можете не захотеть испортить свою кухню или у вас может не быть времени, чтобы испечь его, поэтому вы идете в пекарню и просто его покупаете. Для MySQL, если вы хотите, чтобы она была готова к использованию без усилий, связанных с компиляцией, вы можете использовать пакеты дистрибутива.
Пакеты дистрибутива для MySQL доступны для различных платформ, включая дистрибутивы Linux, Windows и macOS. Эти пакеты обеспечивают гибкий и быстрый способ начать использовать MySQL. Возвращаясь к примеру с шоколадным тортом, предположим, что вы хотите что-то изменить. Может быть, вы хотите белый шоколадный торт. Для MySQL у нас есть так называемые форки, которые включают несколько различных опций. Мы рассмотрим некоторые из них в следующем разделе.
Форки MySQL
В разработке программного обеспечения форк происходит, когда кто-то копирует исходный код и начинает свой собственный путь независимой разработки и поддержки. Форк может следовать по пути, близкому к пути исходной версии, как это делает дистрибутив Percona MySQL, или отклоняться от него, как MariaDB. Поскольку исходный код MySQL является открытым и бесплатным, новые проекты могут разветвлять код без разрешения его первоначального создателя. Давайте взглянем на несколько наиболее заметных форков.
MySQL Community Edition
MySQL Community Edition, также известный как исходная или ванильная версия MySQL, является версией с открытым исходным кодом, распространяемой Oracle. Эта версия способствует развитию механизма InnoDB и новых функций, и она первой получает обновления, новые функции и исправления ошибок.
Percona Server for MySQL
Дистрибутив Percona MySQL представляет собой бесплатную замену MySQL Community Edition с открытым исходным кодом. Разработка следует за этой версией, уделяя особое внимание повышению производительности и общей экосистемы MySQL. Percona Server также включает дополнительные усовершенствования, такие как движок MyRocks, плагин Audit Log и плагин PAM Authentication. Соучредителями Percona были Петр Зайцев и Вадим Ткаченко.
MariaDB Server
MariaDB Server, созданный Майклом «Монти» Видениусом и распространяемый MariaDB Foundation, на сегодняшний день является форком, который больше всего отдалился от ванильного MySQL. В последние годы он разработал новые функции и механизмы, такие как MariaDB ColumnStore, и стал первой базой данных, интегрировавшей функции кластеризации Galera 4.
MySQL Enterprise Edition
MySQL Enterprise Edition в настоящее время является единственной версией с коммерческой лицензией (это означает, что за ее использование необходимо платить, как за лицензию Windows). Также распространяемая Oracle, она содержит все функции Community Edition, а также эксклюзивные функции безопасности, резервного копирования и высокой доступности.
Варианты установки и платформы
Во-первых, вы должны выбрать версию MySQL, совместимую с вашей операционной системой (ОС). Вы можете проверить совместимость на веб-сайте MySQL. Те же политики поддержки доступны для Percona Server и MariaDB.
Мы часто слышим вопрос: можно ли установить MySQL на неподдерживаемую ОС? В большинстве случаев ответ положительный. Например, можно установить MySQL в Windows 7, но высок риск возникновения ошибки или непредсказуемого поведения (например, утечки памяти или недостаточной производительности). Из-за этих рисков мы не рекомендуем делать это для производственных сред.
Следующим шагом будет решить, следует ли установить версию для разработки или общедоступную версию (General Availability) (GA). Разрабатываемые релизы содержат новейшие функции, но мы не рекомендуем их для производства, поскольку они нестабильны. Выпуски GA, также называемые производственными (production) или стабильными (stable) релизами, предназначены для использования в производственной среде.
Последнее, что нужно решить, это какой формат дистрибутива установить для операционной системы. Для большинства случаев использования подходит бинарный дистрибутив. Двоичные дистрибутивы доступны в собственном формате для многих платформ, например пакеты .rpm для Linux или пакеты .dmg для macOS. Дистрибутивы также доступны в универсальных форматах, таких как архивы .zip или сжатые файлы .tar (tarballs). В Windows вы можете использовать установщик MySQL для установки бинарного дистрибутива.
Процесс установки состоит из четырех основных шагов, описанных в следующих разделах. Очень важно правильно следовать им и установить минимальные требования безопасности для базы данных MySQL.
1. Загрузите дистрибутив, который вы хотите установить
У каждого дистрибутива есть свой владелец и, как следствие, свой источник. Некоторые дистрибутивы Linux предоставляют пакеты по умолчанию в своих репозиториях. Например, в CentOS 8 ванильный дистрибутив MySQL доступен в репозиториях по умолчанию. Когда в ОС доступны пакеты по умолчанию, нет необходимости загружать MySQL с веб-сайта или настраивать репозиторий самостоятельно, что упрощает процесс установки.
Мы покажем, как установить репозитории и скачать файлы без необходимости заходить на сайт в процессе установки. Однако, если вы хотите загрузить MySQL самостоятельно, вы можете использовать следующие ссылки:
2. Установите дистрибутив
Установка состоит из элементарных шагов, чтобы сделать MySQL работоспособным и подключить его к сети, но не защитить MySQL. Например, на этом этапе пользователь root MySQL может подключиться без пароля, что довольно опасно, поскольку пользователь root имеет привилегии для выполнения любых действий, включая удаление базы данных.
3. Выполните любую необходимую настройку после установки
На этом шаге нужно убедиться, что сервер MySQL работает правильно. Очень важно убедиться, что ваш сервер защищен, и первым шагом для этого является выполнение скрипта mysql_secure_installation. Вы измените пароль для пользователя root, отключите доступ для пользователя root с удаленного сервера и удалите тестовую базу данных.
4. Запустите тесты
Некоторые администраторы баз данных запускают тесты для каждого развертывания, чтобы определить, подходит ли производительность для проекта, для которого они используют базу. Наиболее распространенным инструментом для этого является sysbench. Здесь важно подчеркнуть, что sysbench выполняет синтетическую рабочую нагрузку, тогда как когда приложение запущено, мы называем это реальной рабочей нагрузкой. Синтетические рабочие нагрузки обычно предоставляют отчеты о максимальной производительности сервера, но они не могут воспроизвести реальную рабочую нагрузку (с присущими ей блокировками, разным временем выполнения запросов, хранимыми процедурами, триггерами и т. д.).
В следующем разделе мы подробно рассмотрим процесс установки для нескольких наиболее часто используемых платформ.
Установка MySQL в Linux
Экосистема Linux разнообразна и имеет множество вариантов, включая Red Hat Enterprise Linux (RHEL), CentOS, Ubuntu, Debian и другие. В этом разделе рассматриваются только самые популярные из них, иначе эта книга была бы целиком посвящена процессу установки!
Установка MySQL на CentOS 7
CentOS, сокращение от Community Enterprise Linux Operating System, была основана в 2004 году, а Red Hat приобрела ее в 2014 году. CentOS — это версия Red Hat для сообщества, поэтому они практически идентичны, но CentOS бесплатна, а поддержка предоставляется сообществом вместо самой Red Hat. CentOS 7 была выпущена в 2014 году, а ее срок службы истекает в 2024 году.
Установка MySQL 8.0
Чтобы установить MySQL 8.0 на CentOS 7 с помощью репозитория yum, выполните следующие шаги.
Войдите на сервер Linux. Обычно из соображений безопасности пользователи входят на серверы Linux как непривилегированные пользователи. Вот пример входа пользователя на Linux с терминала macOS с использованием закрытого ключа:
$ ssh -i key.pem centos@3.227.11.227После успешного подключения вы увидите что-то вроде этого в терминале:
[centos@ip-172-30-150-91 ~]$Станьте root в Linux. После подключения к серверу вам необходимо стать пользователем root:
$ sudo su - rootЗатем вы увидите подсказку, подобную следующей, в вашем терминале:
[root@ip-172-30-150-91 ~]#Стать root важно, потому что для установки MySQL необходимо выполнить такие задачи, как создание пользователя MySQL в Linux, настройка каталогов и установка разрешений. Также можно использовать команду sudo для всех примеров, которые мы покажем, которые должны выполняться пользователем root. Следует учесть, что, если вы забудете добавить к команде префикс sudo, процесс установки будет неполным.
Настройте репозиторий yum. Выполните следующую команду, чтобы настроить репозиторий MySQL yum:
# rpm -Uvh https://repo.mysql.com/mysql80-community-release-el7.rpmУстановите MySQL 8.0 Community Server. Поскольку в репозитории MySQL yum есть репозитории для нескольких версий MySQL (основные версии 5.7 и 8.0), сначала мы должны отключить все репозитории:
# sed -i 's/enabled=1/enabled=0/'
/etc/yum.repos.d/mysql-community.repo
Далее нам нужно включить репозиторий MySQL 8.0 и выполнить следующую команду для установки MySQL 8.0:
# yum --enablerepo=mysql80-community install mysql-community-serverЗапустите службу MySQL. Теперь запустите службу MySQL с помощью команды systemctl:
# systemctl start mysqldТакже возможно запустить процесс MySQL вручную, что может оказаться полезным для устранения проблем с инициализацией, когда MySQL отказывается запускаться. Чтобы запустить MySQL вручную, укажите расположение файла my.cnf и какой пользователь может манипулировать файлами базы данных и процессом:
# mysqld --defaults-file=/etc/my.cnf --user=mysqlУзнайте пароль по умолчанию для пользователя root. Когда вы устанавливаете MySQL 8.0, MySQL создает временный пароль для учетной записи пользователя root. Чтобы определить пароль учетной записи пользователя root, выполните следующую команду:
# grep "A temporary password" /var/log/mysqld.logКоманда выдает следующий вывод:
2020-05-31T15:04:12.256877Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: #z?hhCCyj2ajЗащитите установку MySQL. MySQL предоставляет сценарий оболочки, который вы можете запустить в системах Unix, mysql_secure_installation, который позволяет вам улучшить безопасность установки вашего сервера следующими способами:
-
Вы можете установить пароль для учетной записи root.
-
Вы можете отключить root-доступ из-за пределов локального хоста.
-
Вы можете удалить анонимные учетные записи пользователей.
-
Вы можете удалить тестовую базу данных, к которой по умолчанию могут обращаться анонимные пользователи.
Выполните команду mysql_secure_installation для защиты сервера MySQL:
# mysql_secure_installationВам будет предложено ввести текущий пароль учетной записи root:
Enter the password for user root:Введите временный пароль, полученный на предыдущем шаге, и нажмите Enter. Появится следующее сообщение:
The existing password for the user account root has expired. Please set a new password.
New password:
Re-enter new password:
Вам нужно будет дважды ввести новый пароль для учетной записи root. Более поздние версии MySQL поставляются с политикой проверки, что означает, что новый пароль должен соответствовать минимальным требованиям, чтобы его можно было принять. Требования по умолчанию заключаются в том, что пароли должны иметь длину не менее восьми символов и включать:
Хотя бы один цифровой символ
Хотя бы один символ нижнего регистра
Хотя бы один символ верхнего регистра
Хотя бы один специальный (не буквенно-цифровой) символ
Затем он предложит вам несколько вопросов yes/no о том, хотите ли вы внести некоторые первоначальные изменения в настройку. Чтобы обеспечить максимальную защиту, мы рекомендуем удалить анонимных пользователей, отключить удаленный вход в систему root и удалить тестовую базу данных (т. е. ответить yes на все варианты):
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
Подключитесь к MySQL. Этот шаг необязателен, но мы используем его для проверки правильности выполнения всех шагов. Используйте эту команду для подключения к серверу MySQL:
# mysql -u root -pОн запросит пароль пользователя root. Введите пароль и нажмите Enter:
Enter password:В случае успеха он покажет командную строку MySQL:
mysql>Запускайте MySQL 8.0 при загрузке сервера (опционально). Чтобы настроить автозапуск MySQL при каждой загрузке сервера, используйте следующую команду:
# systemctl enable mysqldУстановка MariaDB 10.5
Чтобы установить MariaDB 10.5 на CentOS 7, вам необходимо выполнить те же шаги, что и для ванильного дистрибутива MySQL.
Станьте root в Linux. Во-первых, нам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите репозиторий MariaDB. Следующий набор команд загрузит репозиторий MariaDB и настроит его для следующего шага. Обратите внимание, что в командах yum мы используем параметр -y. Эта опция сообщает Linux, что на все последующие вопросы ответ будет yes:
# yum install wget -y
# wget https://downloads.mariadb.com/MariaDB/mariadb_repo_setup
# chmod +x mariadb_repo_setup
# ./mariadb_repo_setup
Установите MariaDB. После настройки репозитория следующая команда установит последнюю стабильную версию MariaDB и ее зависимости:
# yum install MariaDB-server -yКонец вывода будет примерно таким:
Installed:
MariaDB-compat.x86_64 0:10.5.8-1.el7.centos
Dependency Installed:
MariaDB-client.x86_64 0:10.5.8-1.el7.centos MariaDB-common.x86_64
0:10.5.8-1.el7.centos boost-program-options.x86_64 0:1.53.0-28.el7
galera-4.x86_64 0:26.4.6-1.el7.centos
libaio.x86_64
0:0.3.109-13.el7
lsof.x86_64 0:4.87-6.el7
pcre2.x86_64 0:10.23-2.el7
perl.x86_64
4:5.16.3-299.el7_9
perl-Carp.noarch 0:1.26-244.el7
...
Replaced:
mariadb-libs.x86_64 1:5.5.64-1.el7
Complete!
Complete! в конце вывода указывает на успешную установку.
Запустите MariaDB. Установив MariaDB, инициализируйте службу с помощью команды systemctl:
# systemctl start mariadb.serviceВы можете использовать эту команду, чтобы проверить ее статус:
# systemctl status mariadb
mariadb.service - MariaDB 10.5.8 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disabled)
...
Feb 07 12:55:04 ip-172-30-150-91.ec2.internal systemd[1]: Started MariaDB 10.5.8 database server.
Защитите MariaDB. На данный момент MariaDB будет работать в небезопасном режиме. В отличие от MySQL 8.0, у MariaDB будет пустой пароль root, поэтому вы сможете мгновенно получить доступ:
# mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 44
Server version: 10.5.8-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]>
Вы можете выполнить mysql_secure_installation для защиты MariaDB точно так же, как и для MySQL 8.0 (подробности см. в предыдущем разделе). Есть небольшое различие в выводе с одним дополнительным вопросом:
Switch to unix_socket authentication [Y/n] y
Enabled successfully!
Reloading privilege tables..
... Success!
Ответ yes изменяет соединение с TCP/IP на режим сокета Unix. Мы обсудим различные типы соединений в разделе «Файлы MySQL 5.7 по умолчанию».
Установка Percona Server 8.0
Установите Percona Server 8.0 на CentOS 7, выполнив следующий шаг.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите репозиторий Percona. Вы можете установить репозиторий Percona yum, выполнив следующую команду от имени пользователя root или с помощью sudo:
# yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmПри установке создается новый файл репозитория /etc/yum.repos.d/percona-original-release.repo. Теперь включите репозиторий Percona Server 8.0 с помощью этой команды:
# percona-release setup ps80Установите Percona Server 8.0. Чтобы установить сервер, выполните эту команду:
# yum install percona-server-serverИнициализируйте Percona Server 8.0 с помощью systemctl. После установки двоичных файлов Percona Server 8.0 запустите службу:
# systemctl start mysqlИ подтвердите его статус:
# systemctl status mysql
mysqld.service - MySQL Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2021-02-07 13:22:15 UTC; 6s ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Process: 14472 ExecStartPre=/usr/bin/mysqld_pre_systemd (code=exited, status=0/SUCCESS)
Main PID: 14501 (mysqld)
Status: "Server is operational"
Tasks: 39 (limit: 5789)
Memory: 345.2M
CGroup: /system.slice/mysqld.service
└─14501 /usr/sbin/mysqld
Feb 07 13:22:14 ip-172-30-92-109.ec2.internal systemd[1]: Starting MySQL Server...
Feb 07 13:22:15 ip-172-30-92-109.ec2.internal systemd[1]: Started MySQL Server.
На этом этапе шаги аналогичны установке vanilla. Обратитесь к разделам о получении временного пароля и выполнении команды mysql_secure_installation в разделе «Установка MySQL 8.0».
Установка MySQL 5.7
Установите MySQL 5.7 на CentOS 7, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите репозиторий MySQL 5.7. Вы можете установить репозиторий MySQL 5.7 yum, выполнив следующую команду от имени пользователя root или с помощью sudo:
# yum localinstall\
https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm -y
При установке создается новый файл репозитория /etc/yum.repos.d/mysql-community.repo.
Установите двоичные файлы MySQL 5.7. Чтобы установить сервер, выполните эту команду:
# yum install mysql-community-server -yИнициализируйте MySQL 5.7 с помощью systemctl. После того, как вы установили двоичные файлы MySQL 5.7, запустите службу:
# systemctl start mysqldИ запустите эту команду, чтобы проверить его статус:
# systemctl status mysqldНа этом этапе шаги аналогичны стандартной установке MySQL 8.0. Обратитесь к разделам о получении временного пароля и выполнении команды mysql_secure_installation в разделе «Установка MySQL 8.0».
Установка Percona Server 5.7
Установите Percona Server 5.7 на CentOS 7, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите репозиторий Percona. Вы можете установить репозиторий Percona yum, выполнив следующую команду от имени пользователя root или с помощью sudo:
# yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmПри установке создается новый файл репозитория /etc/yum.repos.d/percona-original-release.repo. Используйте эту команду, чтобы включить репозиторий Percona Server 5.7:
# percona-release setup ps57Установите двоичные файлы Percona Server 5.7. Чтобы установить сервер, выполните эту команду:
# yum install Percona-Server-server-57 -yИнициализируйте Percona Server 5.7 с помощью systemctl. После установки двоичных файлов Percona Server 5.7 запустите службу:
# systemctl start mysqlИ подтвердите его статус:
# systemctl status mysqlНа этом этапе шаги аналогичны стандартной установке MySQL 8.0. Обратитесь к разделам о получении временного пароля и выполнении команды mysql_secure_installation в разделе «Установка MySQL 8.0».
Установка MySQL на CentOS 8
Текущая версия CentOS — CentOS 8, построенная на основе RHEL 8. Как правило, CentOS имеет тот же десятилетний жизненный цикл поддержки, что и сам RHEL. Этот традиционный жизненный цикл поддержки означает конец срока службы CentOS 8 в 2029 году. Однако в декабре 2020 года объявление Red Hat сигнализировало о намерении поставить надгробный камень на могиле CentOS 8 гораздо раньше — в 2021 году. (Red Hat будет поддерживать CentOS 7 вместе с RHEL 7 до 2024 года.) Текущие пользователи CentOS должны будут перейти либо на сам RHEL, либо на более новый проект CentOS Stream. Возникают некоторые проекты сообщества, но на данный момент будущее CentOS неопределенно.
Однако мы расскажем об этапах установки здесь, поскольку многие пользователи используют RHEL 8 и Oracle Linux 8 в отрасли.
Установка MySQL 8.0
Последняя версия MySQL 8.0 доступна для установки из репозитория AppStream по умолчанию с использованием модуля MySQL, который по умолчанию включен в системах CentOS 8 и RHEL 8. Таким образом, есть некоторые отличия от традиционного метода yum. Давайте посмотрим на детали.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите двоичные файлы MySQL 8.0. Выполните следующую команду, чтобы установить пакет mysql-server и ряд его зависимостей:
# dnf install mysql-serverПри появлении запроса нажмите y, а затем Enter, чтобы подтвердить, что вы хотите продолжить:
Output
...
Transaction Summary
=======================================================================
Install 50 Packages
Upgrade
8 Packages
Total download size: 50 M
Is this ok [y/N]: y
Запустите MySQL. На данный момент вы установили MySQL на свой сервер, но он еще не работает. Установленный вами пакет настраивает MySQL для запуска в качестве службы systemd с именем mysqld.service. Чтобы запустить MySQL, вам нужно использовать команду systemctl:
# systemctl start mysqld.serviceПроверьте, запущена ли служба. Чтобы проверить, правильно ли работает служба, выполните следующую команду:
# systemctl status mysqldЕсли вы успешно запустили MySQL, вывод покажет, что служба MySQL активна:
# systemctl status mysqld
mysqld.service - MySQL 8.0 database server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; disabled; vendor preset: disabled)
Active: active (running) since Sun 2020-06-21 22:57:57 UTC; 6s ago
Process: 15966 ExecStartPost=/usr/libexec/mysql-check-upgrade (code=exited, status=0/SUCCESS)
Process: 15887 ExecStartPre=/usr/libexec/mysql-prepare-db-dir mysqld.service (code=exited, status=0/SUCCESS)
Process: 15862 ExecStartPre=/usr/libexec/mysql-check-socket (code=exited, status=0/SUCCESS)
Main PID: 15924 (mysqld)
Status: "Server is operational"
Tasks: 39 (limit: 23864)
Memory: 373.7M
CGroup: /system.slice/mysqld.service
└─15924 /usr/libexec/mysqld --basedir=/usr
Jun 21 22:57:57 ip-172-30-222-117.ec2.internal systemd[1]: Starting MySQL 8.0 database server...
Jun 21 22:57:57 ip-172-30-222-117.ec2.internal systemd[1]: Started MySQL 8.0 database server.
Защитите MySQL 8.0. Как и при установке MySQL 8.0 на CentOS 7, вам необходимо выполнить команду mysql_secure_installation (подробности см. в соответствующем разделе «Установка MySQL 8.0»). Основное отличие состоит в том, что для CentOS 8 нет временного пароля, поэтому, когда скрипт запрашивает пароль root, оставьте его пустым и нажмите Enter.
Запустите MySQL 8.0 при загрузке сервера (опционально). Чтобы настроить запуск MySQL при каждой загрузке сервера, используйте следующую команду:
# systemctl enable mysqldУстановка Percona Server 8.0
Чтобы установить Percona Server 8.0 на CentOS 8, вам необходимо сначала установить репозиторий. Давайте пройдемся по шагам.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите двоичные файлы Percona Server 8.0. Выполните следующую команду, чтобы установить репозиторий Percona:
# yum install https://repo.percona.com/yum/percona-release-latest.noarh.rpmПри появлении запроса нажмите y, а затем Enter, чтобы подтвердить, что вы хотите продолжить:
Last metadata expiration check: 0:03:49 ago on Sun 07 Feb 2021 01:16:41 AM UTC.
percona-release-latest.noarch.rpm
Dependencies resolved.
<snip>
Total size: 19 k
Installed size: 31 k
Is this ok [y/N]: y
Downloading Packages:
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing :
1/1
Installing : percona-release-1.0-25.noarch
1/1
Running scriptlet: percona-release-1.0-25.noarch
1/1
* Enabling the Percona Original repository
<*> All done!
* Enabling the Percona Release repository
<*> All done!
The percona-release package now contains a percona-release script that
can enable additional repositories for our newer products. For example, to
enable the Percona Server 8.0 repository use:
percona-release setup ps80
Note: To avoid conflicts with older product versions, the percona-release setup
command may disable our original repository for some products. For more
information, please visit:
https://www.percona.com/doc/percona-repo-config/percona-release.html
Verifying: percona-release-1.0-25.noarch 1/1
Installed:
percona-release-1.0-25.noarch
Включите репозиторий для Percona 8.0. При установке создается новый файл репозитория в /etc/yum.repos.d/percona-original-release.repo. Включите репозиторий Percona Server 8.0 с помощью этой команды:
# percona-release setup ps80Команда предлагает вам отключить модуль RHEL 8 для MySQL. Вы можете сделать это сейчас, нажав y:
* Disabling all Percona Repositories
On RedHat 8 systems it is needed to disable dnf mysql module to install
Percona-Server
Do you want to disable it? [y/N] y
Disabling dnf module...
Percona Release release/noarch YUM repository
6.4 kB/s | 1.4 kB
00:00
Dependencies resolved.
<snip>
Complete!
dnf mysql module was disabled
* Enabling the Percona Server 8.0 repository
* Enabling the Percona Tools repository
<*> All done!
Или сделайте это вручную с помощью следующей команды:
# dnf module disable mysqlУстановите двоичные файлы Percona Server 8.0. Теперь вы готовы установить Percona Server 8.0 на свой сервер CentOS 8/RHEL 8. Чтобы избежать повторного запроса о том, хотите ли вы продолжить, добавьте -y в командную строку:
# yum install percona-server-server -yЗапустите и защитите Percona Server 8.0. Теперь, когда вы установили двоичные файлы Percona Server 8.0, вы можете запустить службу mysqld и настроить ее на запуск при загрузке системы:
# systemctl enable --now mysqld
# systemctl start mysqld
Проверьте статус услуги. Важно подтвердить, что вы успешно выполнили все шаги. Используйте эту команду для проверки состояния службы:
# systemctl status mysqld
mysqld.service - MySQL Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2021-02-07 01:30:50 UTC; 28s ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Process: 12864 ExecStartPre=/usr/bin/mysqld_pre_systemd (code=exited, status=0/SUCCESS)
Main PID: 12942 (mysqld)
Status: "Server is operational"
Tasks: 39 (limit: 5789)
Memory: 442.6M
CGroup: /system.slice/mysqld.service
└─12942 /usr/sbin/mysqld
Feb 07 01:30:40 ip-172-30-92-109.ec2.internal systemd[1]: Starting MySQL Server..
Feb 07 01:30:50 ip-172-30-92-109.ec2.internal systemd[1]: Started MySQL Server.
Установка MySQL 5.7
Установите MySQL 5.7 на CentOS 8, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Отключить модуль MySQL по умолчанию. Такие системы, как RHEL 8, Oracle Linux 8 и CentOS 8, включают модуль MySQL по умолчанию. Если этот модуль не отключен, он маскирует пакеты, предоставляемые репозиториями MySQL, не позволяя вам установить версию, отличную от MySQL 8.0. Итак, используйте эти команды, чтобы удалить этот модуль по умолчанию:
# dnf remove @mysql
# dnf module reset mysql && dnf module disable mysql
Настройте репозиторий MySQL 5.7. Для CentOS 8 нет репозитория MySQL, поэтому вместо него мы будем использовать репозиторий CentOS 7 в качестве эталона. Создайте новый файл репозитория:
# vi /etc/yum.repos.d/mysql-community.repoИ вставьте в файл следующие данные:
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/7/$basearch/
enabled=1
gpgcheck=0
[mysql-connectors-community]
name=MySQL Connectors Community
baseurl=http://repo.mysql.com/yum/mysql-connectors-community/el/7/$basearch/
enabled=1
gpgcheck=0
[mysql-tools-community]
name=MySQL Tools Community
baseurl=http://repo.mysql.com/yum/mysql-tools-community/el/7/$basearch/
enabled=1
gpgcheck=0
Установите двоичные файлы MySQL 5.7. С отключенным модулем по умолчанию и настроенным репозиторием выполните следующую команду, чтобы установить пакет mysql-server и его зависимости:
# dnf install mysql-community-serverПри появлении запроса нажмите y, а затем Enter, чтобы подтвердить, что вы хотите продолжить:
Output
...
Install 5 Packages
Total download size: 202 M
Installed size: 877 M
Is this ok [y/N]: y
Запустите MySQL. Вы установили исполняемые файлы MySQL на свой сервер, но он еще не работает. Установленный вами пакет настраивает MySQL для запуска в качестве службы systemd с именем mysqld.service. Чтобы запустить MySQL, вам нужно использовать команду systemctl:
# systemctl start mysqld.serviceПроверьте, запущена ли служба. Чтобы убедиться, что служба работает правильно, выполните следующую команду:
# systemctl status mysqldЕсли вы успешно запустили MySQL, вывод покажет, что служба MySQL активна:
# systemctl status mysqld
mysqld.service - MySQL Server
Loaded: loaded (/usr/lib/systemd/system/mysqld.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2021-02-07 18:22:12 UTC; 9s ago
Docs: man:mysqld(8)
http://dev.mysql.com/doc/refman/en/using-systemd.html
Process: 14396 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid $MYSQLD_OPTS (code=exited, status=0/SUCCESS)
Process: 8137 ExecStartPre=/usr/bin/mysqld_pre_systemd (code=exited, status=0/SUCCESS)
Main PID: 14399 (mysqld)
Tasks: 27 (limit: 5789)
Memory: 327.2M
CGroup: /system.slice/mysqld.service
└─14399 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
Feb 07 18:22:02 ip-172-30-36-53.ec2.internal systemd[1]: Starting MySQL Server...
Feb 07 18:22:12 ip-172-30-36-53.ec2.internal systemd[1]: Started MySQL Server.
Защитите MySQL 5.7. На этом этапе шаги аналогичны стандартной установке MySQL 8.0. Обратитесь к разделам о получении временного пароля и выполнении команды mysql_secure_installation в разделе «Установка MySQL 8.0».
Запустите MySQL 5.7 при загрузке сервера (опционально). Чтобы настроить запуск MySQL при каждой загрузке сервера, используйте следующую команду:
# systemctl enable mysqldУстановка MySQL на Ubuntu 20.04 LTS (Focal Fossa)
Ubuntu — это дистрибутив Linux, основанный на Debian, который состоит в основном из бесплатного программного обеспечения с открытым исходным кодом. Официально существует три версии Ubuntu: Desktop, Server и Core для устройств и роботов IoT. Версия, с которой мы будем работать в этой книге, — это Server.
Установка MySQL 8.0
Для Ubuntu процесс немного отличается, так как Ubuntu использует репозиторий apt. Давайте пройдемся по шагам.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Настройте репозиторий apt. В Ubuntu 20.04 (Focal Fossa) вы можете установить MySQL, используя репозиторий пакетов apt. Во-первых, убедитесь, что ваша система обновлена:
# apt updateУстановите MySQL 8.0. Затем установите пакет mysql-server:
# apt install mysql-server -yКоманда apt install установит MySQL, но не предложит вам установить пароль или внести какие-либо другие изменения в конфигурацию. В отличие от установки CentOS, Ubuntu инициализирует MySQL в небезопасном режиме.
Для новых установок MySQL вам потребуется запустить встроенный сценарий безопасности системы управления базами данных (СУБД). Этот сценарий изменяет некоторые менее безопасные параметры по умолчанию для удаленного входа в систему root и тестовой базы данных. Мы решим эту проблему на этапе защиты после инициализации MySQL.
Запустите MySQL. На данный момент вы установили MySQL на свой сервер, но он еще не работает. Чтобы запустить MySQL, вам нужно использовать команду systemctl:
# systemctl start mysqlПроверьте, запущена ли служба. Чтобы убедиться, что служба работает правильно, выполните следующую команду:
# systemctl status mysqlЕсли вы успешно запустили MySQL, вывод покажет, что служба MySQL активна:
mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2021-02-07 20:19:51 UTC; 22s ago
Process: 3514 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=exited, status=0/SUCCESS)
Main PID: 3522 (mysqld)
Status: "Server is operational"
Tasks: 38 (limit: 1164)
Memory: 332.7M
CGroup: /system.slice/mysql.service
└─3522 /usr/sbin/mysqld
Feb 07 20:19:50 ip-172-30-202-86 systemd[1]: Starting MySQL Community Server...
Feb 07 20:19:51 ip-172-30-202-86 systemd[1]: Started MySQL Community Server.
Защитите MySQL 8.0. На этом этапе шаги аналогичны стандартной установке на CentOS 7 (см. «Установка MySQL 8.0»). Однако MySQL 8.0 в Ubuntu инициализируется незащищенным, что означает, что пароль root пуст. Чтобы защитить его, выполните mysql_secure_installation:
# mysql_secure_installationЭто проведет вас через ряд запросов, чтобы внести некоторые изменения в параметры безопасности установки MySQL, которые аналогичны параметрам версии CentOS, как описано ранее.
Здесь есть небольшая разница, потому что в Ubuntu можно изменить политику проверки, которая управляет надежностью пароля. В этом примере мы устанавливаем политику проверки на MEDIUM (1):
Securing the MySQL server deployment.
Connecting to MySQL using a blank password.
VALIDATE PASSWORD COMPONENT can be used to test passwords and improve security. It checks the strength of password and allows the users to set only those passwords which are secure enough. Would you like to setup VALIDATE PASSWORD component?
Press y|Y for Yes, any other key for No: y
There are three levels of password validation policy:
LOW Length >= 8
MEDIUM Length >= 8, numeric, mixed case, and special characters
STRONG Length >= 8, numeric, mixed case, special characters and dictionary
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 1
Please set the password for root here.
New password:
Re-enter new password:
Estimated strength of the password: 50
Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y
By default, a MySQL installation has an anonymous user, allowing anyone to log into MySQL without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother.
You should remove them before moving into a production environment.
Установка Percona Server 8
Установите Percona Server 8.0 на Ubuntu 20.04 LTS, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Установите защиту конфиденциальности GNU. Oracle подписывает загружаемые пакеты MySQL с помощью GNU Privacy Guard (GnuPG), альтернативы с открытым исходным кодом известной Pretty Good Privacy (PGP), созданной Филом Циммерманном. Большинство дистрибутивов Linux поставляются с установленным по умолчанию GnuPG, но в этом случае его необходимо установить:
# apt-get install gnupg2 -yПолучите пакеты репозитория с веб-сайта Percona. Затем извлеките пакеты репозитория из репозитория Percona с помощью команды wget:
# wget https://repo.percona.com/apt/percona-release_latest.$(lsb_release -sc)_all.debУстановите загруженный пакет с помощью dpkg. После загрузки установите пакет с помощью следующей команды:
# dpkg -i percona-release_latest.$(lsb_release -sc)_all.debЗатем вы можете проверить репозиторий, настроенный в файле /etc/apt/sources.list.d/percona-original-release.list.
Включите репозиторий. Следующим шагом является включение Percona Server 8.0 в репозиторий и его обновление:
# percona-release setup ps80
# apt update
Установите двоичные файлы Percona Server 8.0. Затем установите пакет percona-server-server с помощью команды apt-get install:
# apt-get install percona-server-server -yЗапустите MySQL. На данный момент вы установили MySQL на свой сервер, но он еще не работает. Чтобы запустить MySQL, вам нужно использовать команду systemctl:
# systemctl start mysqlПроверьте, запущена ли служба. Чтобы убедиться, что служба работает правильно, выполните следующую команду:
# systemctl status mysqlВ этот момент Percona Server будет работать в небезопасном режиме. Выполнение mysql_secure_installation проведет вас через ряд запросов, чтобы внести некоторые изменения в параметры безопасности вашей установки MySQL, которые идентичны описанным для установки vanilla MySQL 8.0 в предыдущем разделе.
Установка MariaDB 10.5
Установите MariaDB 10.5 на Ubuntu 20.04 LTS, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Обновите систему с помощью менеджера пакетов apt. Убедитесь, что ваша система обновлена, и установите пакет software-properties-common с помощью следующих команд:
# apt update && sudo apt upgrade
# apt -y install software-properties-common
Этот пакет содержит общие файлы для свойств программного обеспечения, таких как серверная часть D-Bus, и абстракцию используемых репозиториев apt.
Импортируйте GPG-ключ MariaDB. Выполните следующую команду, чтобы добавить ключ репозитория в систему:
# apt-key adv --fetch-keys 'https://mariadb.org/mariadb_release_signing_key.asc'
Добавьте репозиторий MariaDB. После импорта ключа GPG репозитория вам необходимо добавить репозиторий apt, выполнив следующую команду:
# add-apt-repository 'deb [arch=amd64] http://mariadb.mirror.globo.tech/repo/10.5/ubuntu focal main'
Установите бинарные файлы MariaDB 10.5. Следующим шагом будет установка сервера MariaDB:
# apt install mariadb-server mariadb-clientПроверьте, запущена ли служба. Чтобы проверить, правильно ли работает служба MariaDB, выполните следующую команду:
# systemctl status mysqlНа данный момент MariaDB 10.5 будет работать в небезопасном режиме. Выполнение mysql_secure_installation проведет вас через ряд запросов, чтобы внести некоторые изменения в параметры безопасности вашей установки MySQL, которые идентичны тем, которые описаны для установки vanilla MySQL 8.0 в Ubuntu ранее в этом разделе.
Установка MySQL 5.7
Установите MySQL 5.7 на Ubuntu 20.04 LTS, выполнив следующие действия.
Станьте root в Linux. Во-первых, вам нужно стать root. См. инструкции в разделе «Установка MySQL 8.0».
Обновите систему с помощью менеджера пакетов apt. Вы можете убедиться, что ваша система обновлена, и установить пакет software-properties-common с помощью следующей команды:
# apt update -y && sudo apt upgrade -yДобавьте и настройте репозиторий MySQL 5.7. Добавьте репозиторий MySQL, выполнив следующие команды:
# wget https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.deb
# dpkg -i mysql-apt-config_0.8.12-1_all.deb
В командной строке выберите ubuntu bionic, как показано на рис. 1-1, и нажмите ОК.

Рисунок 1-1. Выберите ubuntu bionic
Следующее приглашение показывает, что MySQL 8.0 выбран по умолчанию (рис. 1-2). Выбрав эту опцию, нажмите Enter.

Рисунок 1-2. Выберите вариант MySQL Server & Cluster.
Для следующего варианта, как показано на рис. 1-3, выберите MySQL 5.7 и нажмите OK.

Рисунок 1-3. Выберите вариант MySQL 5.7.
Вернувшись на главный экран, нажмите OK для выхода, как показано на рис. 1-4.

Рисунок 1-4. Нажмите OK, чтобы выйти
Далее вам необходимо обновить пакеты MySQL:
# apt-get update -yПодтвердите политику Ubuntu для установки MySQL 5.7:
# apt-cache policy mysql-serverПроверьте вывод, чтобы узнать, какая версия MySQL 5.7 доступна:
# apt-cache policy mysql-server
mysql-server:
Installed: (none)
Candidate: 8.0.23-0ubuntu0.20.04.1
Version table:
8.0.23-0ubuntu0.20.04.1 500
500 http://br.archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages
500 http://br.archive.ubuntu.com/ubuntu focal-security/main amd64 Packages
8.0.19-0ubuntu5 500
500 http://br.archive.ubuntu.com/ubuntu focal/main amd64 Packages
5.7.33-1ubuntu18.04 500
500 http://repo.mysql.com/apt/ubuntu bionic/mysql-5.7 amd64 Packages
Установите двоичные файлы MySQL 5.7. Теперь, когда вы убедились, что доступна версия MySQL 5.7 (5.7.33-1ubuntu18.04), установите ее:
# apt-get install mysql-client=5.7.33-1ubuntu18.04 -y
# apt-get install mysql-community-server=5.7.33-1ubuntu18.04 -y
# apt-get install mysql-server=5.7.33-1ubuntu18.04 -y
В процессе установки вам будет предложено выбрать пароль root, как показано на рисунке 1-5.

Рисунок 1-5. Определите пароль root и нажмите OK.
Проверьте, запущена ли служба. Чтобы проверить, правильно ли работает служба MySQL 5.7, выполните следующую команду:
# systemctl status mysqlНа этом этапе в MySQL 5.7 будет установлен пароль для пользователя root. Тем не менее, вы все равно захотите запустить mysql_secure_installation, чтобы установить политику паролей, удалить удаленный вход root и анонимных пользователей, а также удалить тестовую базу данных. Подробности см. в разделе «Безопасность MySQL 8.0».
Установка MySQL на macOS Big Sur
MySQL для macOS доступен в нескольких различных формах. Поскольку большую часть времени MySQL устанавливается на macOS в целях разработки, мы продемонстрируем только то, как установить его с помощью собственного установщика macOS (файл .dmg). Имейте в виду, что также можно использовать архив для установки MySQL на macOS.
Установка MySQL 8
Сначала загрузите файл MySQL .dmg с веб-сайта MySQL.
После загрузки запустите пакет, чтобы начать процедуру установки, как показано на рисунке 1-6.

Рисунок 1-6. Пакет MySQL 8.0.23 .dmg
Затем вам нужно авторизовать запуск MySQL, как показано на рис. 1-7.

Рисунок 1-7. Запрос авторизации MySQL 8.0.23
Рисунок 1-8 показывает экран приветствия установщика.

Рисунок 1-8. Начальный экран MySQL 8.0.23
Рисунок 1-9 показывает лицензионное соглашение. Даже с программным обеспечением с открытым исходным кодом необходимо согласиться с условиями лицензии; в противном случае вы не сможете продолжить.

Рисунок 1-9. Лицензионное соглашение MySQL 8.0.23
Теперь вы можете определить местоположение и настроить установку, как показано на рис. 1-10.

Рисунок 1-10. Настройка установки MySQL 8.0.23
Вы собираетесь продолжить стандартную установку. После нажатия Install вам может быть предложено ввести пароль пользователя macOS для запуска установки с более высокими привилегиями, как показано на рис. 1-11.

Рисунок 1-11. запрос авторизации macOS
После того, как вы установили MySQL, в процессе установки вам будет предложено выбрать шифрование пароля. Вам следует использовать более новый метод аутентификации (вариант по умолчанию), как показано на рис. 1-12, который является более безопасным.

Рисунок 1-12. Шифрование паролей MySQL 8.0.23
Последний шаг состоит из создания пароля root и инициализации MySQL, как показано на рисунке 1-13.

Рисунок 1-13. Корневой пароль MySQL 8.0.23
Теперь вы установили MySQL Server, но он не загружен (или не запущен) по умолчанию. Для начала откройте System Preferences и найдите значок MySQL, как показано на рис. 1-14.

Рисунок 1-14. MySQL в системных настройках
Щелкните значок, чтобы открыть панель MySQL. Вы должны увидеть что-то похожее на рисунок 1-15.

Рисунок 1-15. Варианты запуска MySQL
Помимо очевидного варианта запуска процесса MySQL, есть панель конфигурации (с расположением файлов MySQL) и возможность повторной инициализации базы данных (вы уже инициализировали ее во время установки). Запустите процесс MySQL. Вас могут снова попросить ввести пароль администратора.
При работающей MySQL можно проверить соединение и убедиться, что MySQL Server работает правильно. Вы можете использовать MySQL Workbench, чтобы проверить это, или установить клиент MySQL, используя brew:
$ brew install mysql-clientПосле того, как вы установили клиент MySQL, вы можете подключиться с паролем, который вы определили на рис. 1-13. В терминале выполните следующую команду:
$ mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.23 MySQL Community Server - GPL
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type help; or \h for help. Type \c to clear the current input statement.
mysql> SELECT @@version;
+-----------+
| @@version |
+-----------+
| 8.0.23 |
+-----------+
1 row in set (0.00 sec)
Установка MySQL в Windows 10
Oracle предоставляет MySQL Installer for Windows, облегчающий установку. Обратите внимание, что MySQL Installer — это 32-разрядное приложение, но оно может устанавливать MySQL в 32-разрядных и 64-разрядных двоичных файлах. Чтобы начать процесс установки, вам необходимо запустить установочный файл и выбрать тип установки, как показано на рисунке 1-16.
Выберите тип установки Developer Default и нажмите Next. Мы не будем подробно останавливаться на других вариантах, потому что не рекомендуем использовать MySQL для производственных систем, главным образом потому, что экосистема MySQL разработана для Linux.

Рисунок 1-16. Настройка установки MySQL 8.0.23 Windows
Далее установщик проверяет, все ли требования выполнены (Рисунок 1-17).

Рисунок 1-17. Требования к установке
Щелкните Execute. Возможно, потребуется установить Microsoft Visual C++ (рис. 1-18).

Рисунок 1-18. Установите Microsoft Visual C++, если требуется
Нажмите Next, и программа установки покажет продукты, готовые к установке (Рисунок 1-19).

Рисунок 1-19. Нажмите Execute, чтобы установить программное обеспечение MySQL.
Нажмите Execute, и вы попадете на экран, где вы можете настроить свойства MySQL. Вы можете использовать параметры по умолчанию для TCP/IP и порта X-протокола, как показано на рис. 1-20, или настроить их по своему усмотрению.
Далее вы выберете метод аутентификации. Выберите более новую версию, которая является более безопасной, как показано на рисунке 1-21.

Рисунок 1-20. Тип и параметры конфигурации сети

Рисунок 1-21. Шифрование паролей — используйте пароли на основе SHA-256.
Затем укажите пароль пользователя root и укажите, хотите ли вы добавить дополнительных пользователей в базу данных MySQL, как показано на рисунке 1-22.

Рисунок 1-22. Настройка пользователей
Настроив пользователей, определите имя службы и пользователя, который будет запускать службу, как показано на рис. 1-23.

Рисунок 1-23. Настройка имени службы
Когда вы нажмете Next, программа установки начнет настройку MySQL. Как только установщик MySQL завершит свое выполнение, вы должны увидеть что-то вроде рис. 1-24.

Рисунок 1-24. Если установка прошла нормально, ошибок нет
Теперь ваш сервер базы данных работает. Поскольку вы выбрали профиль Developer, программа установки выполнит установку MySQL Router. MySQL Router не обязателен для этой установки, и, поскольку мы не рекомендуем Windows для производства, мы пропустим эту часть. Мы углубимся в детали маршрутизатора в MySQL Router.
Теперь вы можете проверить свой сервер с помощью MySQL Workbench, как показано на рисунке 1-25. Вы должны увидеть вариант подключения к MySQL.

Рисунок 1-25. Параметр подключения к MySQL в MySQL Workbench
Дважды щелкните соединение, и Workbench предложит вам ввести пароль, как показано на рисунке 1-26.

Рисунок 1-26. Введите пароль root для подключения
Теперь вы можете начать использовать MySQL на своей платформе Windows, как показано на рис. 1-27.

Рисунок 1-27. Теперь вы можете приступить к тестированию вашей среды
Содержимое каталога MySQL
В процессе установки MySQL создает все файлы, необходимые для запуска сервера. MySQL хранит свои файлы в каталоге, называемом каталогом данных (data directory). Администраторы баз данных (DBA) обычно называют это datadir, что является именем параметра MySQL, в котором хранится путь к этому каталогу. Расположение по умолчанию для дистрибутивов Linux — /var/lib/mysql. Вы можете проверить его местоположение, выполнив следующую команду в экземпляре MySQL:
mysql> SELECT @@datadir;
+-----------------+
| @@datadir |
+-----------------+
| /var/lib/mysql/ |
+-----------------+
1 row in set (0.00 sec)
Файлы MySQL 5.7 по умолчанию
В следующем списке кратко описаны файлы и подкаталоги, которые обычно находятся в каталоге данных:
- Файлы журнала REDO
-
MySQL создает файлы журнала повторов как ib_logfile0 и ib_logfile1 в каталоге данных. Она записывает в файлы журналов повторного выполнения по кругу, поэтому файлы не превышают размер своей конфигурации (опция
innodb_log_file_size). Как и в любой другой системе управления реляционными базами данных (RDBMS), совместимой с ACID, файлы повторного выполнения необходимы для обеспечения устойчивости данных и возможности восстановления после аварийного сценария. - Файл auto.cnf
-
В MySQL 5.6 появился файл auto.cnf. Он имеет только один раздел
[auto], содержащий один параметр и значениеserver_uuid.server_uuidсоздает уникальную подпись для сервера, и уровень репликации использует ее для связи с разными серверами для репликации данных. - Файлы *.pem
-
Короче говоря, эти файлы позволяют использовать зашифрованные соединения для связи между клиентом и сервером MySQL. Зашифрованные соединения являются фундаментальной частью уровня сетевой безопасности, чтобы избежать несанкционированного доступа во время передачи данных от приложения к серверу MySQL. MySQL 5.7 включает SSL по умолчанию и также создает сертификаты. Однако можно использовать сертификаты, предоставленные различными центрами сертификации (CA) на рынке.
- Подкаталог performance_schema
-
MySQL Performance Schema — это функция для мониторинга выполнения MySQL Server на низком уровне во время выполнения. Когда мы можем использовать Performance Schema для мониторинга конкретной метрики, мы говорим, что у MySQL есть инструменты. Например, инструменты Performance Schema могут отображать количество подключенных пользователей:
mysql> SELECT * FROM performance_schema.users; +-----------------+---------------------+-------------------+ | USER | CURRENT_CONNECTIONS | TOTAL_CONNECTIONS | +-----------------+---------------------+-------------------+ | NULL | 40 | 46 | | event_scheduler | 1 | 1 | | root | 0 | 1 | | rsandbox | 2 | 3 | | msandbox | 1 | 2 | +-----------------+---------------------+-------------------+ 5 rows in set (0.03 sec)Хотя инструментарий существует со времен MySQL 5.6, именно в MySQL 5.7 он получил множество улучшений и стал фундаментальной частью инструментов DBA для исследования и устранения неполадок на уровне MySQL.
- файл ibtmp1
-
Когда приложению необходимо создать временные таблицы или MySQL необходимо использовать внутреннюю временную таблицу на диске, MySQL создает их в общем временном табличном пространстве. Поведение по умолчанию заключается в создании автоматически расширяющегося файла данных с именем ibtmp1, размер которого немного превышает 12 МБ (его размер контролируется параметром
innodb_temp_data_file_path). - Файл ibdata1
-
Файл ibdata1, вероятно, самый известный файл в экосистеме MySQL. Для MySQL 5.7 и старше он содержит данные для словаря данных InnoDB, буфера двойной записи, буфера изменений и журналов отмены. Он также может содержать данные таблицы и индекса, если мы отключим опцию
innodb_file_per_table. Когдаinnodb_file_per_tableвключен, каждая пользовательская таблица имеет табличное пространство и выделенный файл. Обратите внимание, что в каталоге данных MySQL может быть несколько файлов ibdata. - Файл mysql.sock
-
Это файл сокета Unix, который сервер использует для связи с локальными клиентами. Этот файл существует только во время работы MySQL, и его удаление или создание файла вручную может привести к проблемам.
- Подкаталог mysql
-
Каталог mysql соответствует системной схеме MySQL, которая содержит информацию о сервере MySQL во время его работы. Например, он включает информацию о пользователях и их привилегиях, таблицы часовых поясов и репликацию. Вы можете увидеть файлы, названные в соответствии с их соответствующими именами таблиц, с помощью команды
ls:# cd /var/lib/mysql # ls -l mysql/ -rw-r-----. 1 vinicius.grippa percona 8820 Feb 20 15:51 columns_priv.frm -rw-r-----. 1 vinicius.grippa percona 0 Feb 20 15:51 columns_priv.MYD -rw-r-----. 1 vinicius.grippa percona 4096 Feb 20 15:51 columns_priv.MYI -rw-r-----. 1 vinicius.grippa percona 9582 Feb 20 15:51 db.frm -rw-r-----. 1 vinicius.grippa percona 976 Feb 20 15:51 db.MYD -rw-r-----. 1 vinicius.grippa percona 5120 Feb 20 15:51 db.MYI -rw-r-----. 1 vinicius.grippa percona 65 Feb 20 15:51 db.opt -rw-r-----. 1 vinicius.grippa percona 8780 Feb 20 15:51 engine_cost.frm -rw-r-----. 1 vinicius.grippa percona 98304 Feb 20 15:51 engine_cost.ibd ... -rw-r-----. 1 vinicius.grippa percona 10816 Feb 20 15:51 user.frm -rw-r-----. 1 vinicius.grippa percona 1292 Feb 20 15:51 user.MYD -rw-r-----. 1 vinicius.grippa percona 4096 Feb 20 15:51 user.MYI
Файлы MySQL 8.0 по умолчанию
MySQL 8.0 внес несколько изменений в ядро структуры каталогов данных. Некоторые из этих изменений связаны с реализацией нового словаря данных, а другие — с улучшением управления базой данных. В следующем списке описаны новые файлы и изменения:
- Файлы табличного пространства undo
-
MySQL (InnoDB) использует файлы undo для отмены транзакций, которые необходимо откатить, и обеспечения изолированных транзакций всякий раз, когда необходимо выполнить согласованное чтение.
Начиная с MySQL 8.0 файлы журнала отмены были отделены от системного табличного пространства (ibdata1) и помещены в каталог данных. Также можно установить другое местоположение, изменив параметр
innodb_undo_directory. - Файлы .dblwr (представлены в версии 8.0.20)
-
Буфер двойной записи отвечает за запись страниц, сброшенных из пула буферов на диск, до того, как MySQL запишет страницы в файлы данных. Имена файлов двойной записи имеют следующий формат: #ib_<page_size>_<file_number>.dblwr (например, #ib_16384_0.dblwr, #ib_16384_0.dblwr). Расположение этих файлов можно изменить, изменив параметр
innodb_doublewrite_dir. - Файл mysql.ibd (представлен в версии 8.0)
-
В MySQL 5.7 таблицы словарей и системные таблицы хранили данные и метаданные в каталоге mysql внутри каталога datadir. В MySQL 8.0 все это хранится в файле mysql.ibd и защищено механизмами InnoDB для обеспечения согласованности.
Использование интерфейса командной строки
Бинарный файл mysql представляет собой простую оболочку SQL с возможностью редактирования строки ввода. Его использование простое (мы уже использовали его несколько раз в процессе установки). Чтобы вызвать его, выполните следующую команду:
# mysqlМы можем расширить его функциональность, выполнив в нем запросы:
# mysql -uroot -pseKret -e "SHOW ENGINE INNODB STATUS\G"И мы можем выполнять более сложные команды, соединяя их с другими командами для выполнения более сложных задач. Например, мы можем извлечь дамп из одной базы данных, отправить его по сети и восстановить на другом сервере MySQL в той же командной строке:
# mysql -e "SHOW MASTER STATUS\G" && nice -5 mysqldump \
--all-databases --single-transaction -R --master-data=2 --flush-logs \
--log-error=/tmp/donor.log --verbose=TRUE | ssh mysql@192.168.0.1 mysql \
1> /tmp/receiver.log 2>&1
MySQL 8.0 представила MySQL Shell, который намного мощнее своего предшественника. MySQL Shell поддерживает языки JavaScript, Python и SQL, предоставляя возможности разработки и администрирования для MySQL Server. Подробнее об этом мы поговорим в разделе «MySQL Shell».
Использование Docker
С появлением виртуализации и ее популяризацией с помощью облачных сервисов появилось множество платформ, включая Docker. Созданный в 2013 году, Docker — это решение, которое предлагает портативный и гибкий способ развертывания программного обеспечения. Он обеспечивает изоляцию ресурсов за счет использования функций Linux, таких как контрольные группы (cgroups) и пространства имен ядра (kernel namespaces).
Docker полезен для администраторов баз данных, которым часто требуется установить определенную версию MySQL, MariaDB или Percona Server для MySQL для проведения некоторых экспериментов. С помощью Docker можно за считанные секунды развернуть экземпляр MySQL для выполнения некоторых тестов. После завершения тестов вы можете уничтожить экземпляр и освободить ресурсы операционной системы для других задач. Все процессы развертывания виртуальной машины (ВМ), установки пакетов и настройки базы данных проще при использовании Docker.
Установка Docker
Преимущество использования Docker заключается в том, что после запуска службы команды одинаковы во всех операционных системах. Одинаковые команды означают, что кривая обучения использованию Docker проходит быстрее по сравнению с изучением различных версий Linux, таких как, например, CentOS и Ubuntu.
Процесс установки Docker в чем-то похож на установку MySQL. Для Windows и macOS вы просто устанавливаете бинарные файлы, после чего сервис запускается и работает. Для операционных систем на базе Linux без графического интерфейса процесс требует настройки репозитория.
Установка Docker на CentOS 7
Пакеты CentOS для Docker, как правило, старше, чем пакеты, доступные для RHEL и в официальных репозиториях Docker. На момент написания статьи версия Docker, предоставляемая обычными репозиториями CentOS, была 1.13.1, а стабильная версия основной ветки — 20.10.3. Для целей этой книги нет никакой разницы, но мы всегда рекомендуем использовать последнюю версию для рабочих сред.
Выполните следующую команду, чтобы установить пакет Docker из репозитория CentOS по умолчанию:
# yum install docker -yЕсли вы хотите установить Docker из вышестоящего репозитория, чтобы убедиться, что вы используете последнюю версию, выполните следующие действия:
-
Установите
yum-utils, чтобы включить командуyum-config-manager:# yum install yum-utils -y -
Используйте
yum-config-managerдля добавления репозитория docker-ce:# yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo -
Установите необходимые пакеты:
# yum install docker-ce docker-ce-cli containerd.io -y -
Запустите службу Docker:
# systemctl start docker -
Включите службу Docker для автоматического запуска после перезагрузки системы:
# systemctl enable --now docker -
Чтобы проверить, запущена ли служба Docker, выполните команду
systemctl status:# systemctl status docker -
Чтобы убедиться, что Docker Engine установлен правильно, вы можете запустить контейнер hello-world:
# docker run hello-world
Установка Docker на Ubuntu 20.04 (Focal Fossa)
Чтобы установить последнюю версию Docker из вышестоящего репозитория, сначала удалите все старые версии Docker (называемые docker, docker.io или docker-engine). Это можно сделать с помощью команды:
# apt-get remove -y docker docker-engine docker.io containerd runcПосле удаления репозитория по умолчанию вы можете начать процесс установки:
-
Убедитесь, что Ubuntu обновлена с помощью этой команды:
-
Установите пакеты, чтобы разрешить apt использовать репозиторий через HTTPS:
-
Затем добавьте официальный GPG-ключ Docker:
-
Имея ключ, добавьте стабильный репозиторий Docker:
-
Теперь используйте команду
aptдля установки пакетов Docker: -
Ubuntu запустит службу для вас, но вы можете проверить это, выполнив эту команду:
-
Чтобы служба Docker автоматически запускалась при перезагрузке ОС, используйте:
-
Проверьте версию Docker, которую вы установили:
-
Чтобы убедиться, что Docker Engine установлен правильно, вы можете запустить контейнер hello-world:
# apt-get update -y# apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo \
apt-key add -
# add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# apt-get install -y docker-ce docker-ce-cli containerd.io# systemctl status docker# systemctl enable --now docker# docker --version# docker run hello-worldРазвертывание контейнера MySQL
После того, как вы установили и запустили Docker Engine, следующим шагом будет развертывание контейнера MySQL Docker.
Чтобы развернуть последнюю версию MySQL с помощью Docker, выполните следующую команду:
# docker run --name mysql-latest \
-p 3306:3306 -p 33060:33060 \
-e MYSQL_ROOT_HOST=% \
-e MYSQL_ROOT_PASSWORD='learning_mysql' \
-d mysql/mysql-server:latest
Docker Engine запустит последнюю версию экземпляра MySQL и будет удаленно доступен из любого места с указанным корневым паролем. Установка MySQL с Docker означает, что у вас нет доступа к каким-либо инструментам, утилитам или стандартным библиотекам, доступным на традиционном хосте (голом железе или виртуальной машине). Вам нужно будет либо развернуть эти инструменты отдельно, либо использовать команды, поставляемые с образом Docker, если они вам нужны.
Затем подключитесь к контейнеру MySQL с помощью клиента MySQL:
# docker exec -it mysql-latest mysql -uroot -plearning_mysqlПоскольку вы сопоставили TCP-порт 3306 в контейнере с портом 3306 на хосте Docker с параметром -p 3306:3306, вы можете подключиться к базе данных MySQL из любого доступного клиента MySQL (Workbench, MySQL Shell), который может подключаться к хосту (hostname или IP) и этот порт.
Давайте рассмотрим несколько команд для управления контейнером.
Чтобы остановить контейнер MySQL Docker, запустите:
# docker stop mysql-latestНе пытайтесь использовать docker run для повторного запуска контейнера. Вместо этого используйте:
# docker start mysql-latestЧтобы исследовать проблему, например, если контейнер не запускается, откройте его журналы с помощью этой команды:
# docker logs mysql-latestЧтобы удалить созданный вами контейнер Docker, запустите:
# docker stop mysql-latest
# docker rm mysql-latest
Чтобы проверить, какие и сколько контейнеров Docker запущены на хосте, используйте:
# docker psМожно настроить параметризацию MySQL с помощью параметров командной строки для Docker Engine. Чтобы настроить размер буферного пула InnoDB и метод flush, выполните следующее:
# docker run --name mysql-latest \
-p 3306:3306 -p 33060:33060 \
-e MYSQL_ROOT_HOST=% \
-e MYSQL_ROOT_PASSWORD='strongpassword' \
-d mysql/mysql-server:latest \
--innodb_buffer_pool_size=256M \
--innodb_flush_method=O_DIRECT
Чтобы запустить версию MySQL, отличную от последней версии, сначала убедитесь, что она доступна в Docker Hub. Например, предположим, что вы хотите запустить MySQL 5.7.31. Первый шаг — проверить официальный список образов MySQL Docker в Docker Hub, чтобы узнать, существует ли он.
Как только вы подтвердите его существование, запустите его с помощью следующей команды:
# docker run --name mysql-5.7.31 \
-p 3307:3306 -p 33061:33060 \
-e MYSQL_ROOT_HOST=% \
-e MYSQL_ROOT_PASSWORD='learning_mysql' \
-d mysql/mysql-server:5.7.31
Можно одновременно запускать несколько экземпляров MySQL Docker, но потенциальной проблемой являются конфликты TCP-портов. Обратите внимание, что в предыдущем примере мы сопоставили разные порты хоста для контейнера mysql-5.7.31 (3307 и 33061). Кроме того, имя контейнера должно быть уникальным.
Развертывание контейнеров MariaDB и Percona Server
Выполните те же действия, что и в предыдущем разделе, для развертывания контейнера MySQL для развертывания контейнера MariaDB или Percona Server. Основное отличие состоит в том, что они используют разные образы Docker и имеют собственные официальные репозитории.
Чтобы развернуть контейнер MariaDB, запустите:
# docker run --name maria-latest \
-p 3308:3306 \
-e MYSQL_ROOT_HOST=% \
-e MYSQL_ROOT_PASSWORD='learning_mysql' \
-d mariadb:latest
А для Percona Server запустите:
# docker run --name ps-latest \
-p 3309:3306 -p 33063:33060 \
-e MYSQL_ROOT_HOST=% \
-e MYSQL_ROOT_PASSWORD='learning_mysql' \
-d percona/percona-server:latest \
--innodb_buffer_pool_size=256M \
--innodb_flush_method=O_DIRECT
Использование песочниц
В разработке программного обеспечения sandbox — это среда тестирования, которая изолирует изменения кода и позволяет экспериментировать и тестировать перед развертыванием в рабочей среде. Администраторы баз данных в основном используют песочницы для тестирования новых версий программного обеспечения, тестов производительности и анализа ошибок, а данные, присутствующие в MySQL, одноразовые.
В 2018 году Джузеппе Максиа представил DBdeployer, инструмент, который обеспечивает простой и быстрый способ развертывания MySQL и его форков. Он поддерживает различные топологии MySQL, такие как master/slave (source/replica), master/master (source/source), Galera Cluster и Group Replication.
Установка DBdeployer
Инструмент разработан на языке Go и работает с macOS и Linux (Ubuntu и CentOS), а также предоставляются автономные исполняемые файлы. Получить последнюю версию здесь:
# wget https://github.com/datacharmer/dbdeployer/releases/download/v1.58.2/ dbdeployer-1.58.2.linux.tar.gz
# tar -xvf dbdeployer-1.58.2.linux.tar.gz
# mv dbdeployer-1.58.2.linux /usr/local/bin/dbdeployer
Если у вас есть каталог /usr/local/bin/ в переменной $PATH, то теперь вы сможете запускать команды dbdeployer:
# dbdeployer --version
dbdeployer version 1.58.2
Использование DBdeployer
Первым шагом в использовании DBdeployer является загрузка двоичного файла MySQL, который вы хотите запустить, и его распаковка в каталог, где вы храните свои двоичные файлы. Мы будем использовать Linux — Generic tarballs, поскольку они совместимы с большинством дистрибутивов Linux, и мы будем хранить наши двоичные файлы в каталоге /opt/mysql:
# wget https://dev.mysql.com/get/Downloads/MySQL-8.0/ \
mysql-8.0.11-linux-glibc2.12-x86_64.tar.gz
# mkdir /opt/mysql
# dbdeployer --sandbox-binary=/opt/mysql/ unpack \
mysql-8.0.11-linux-glibc2.12-x86_64.tar.gz
Команда unpack извлечет и переместит файлы в указанный каталог. Ожидаемый результат этой операции:
# dbdeployer --sandbox-binary=/opt/mysql/ unpack
mysql-8.0.11-linux-glibc2.12-x86_64.tar.gz
Unpacking tarball mysql-8.0.11-linux-glibc2.12-x86_64.tar.gz to /opt/mysql/8.0.11
.........100.........200........289
Renaming directory /opt/mysql/mysql-8.0.11-linux-glibc2.12-x86_64 to /opt/mysql/8.0.11
Теперь мы можем использовать следующую команду для создания новой автономной песочницы MySQL с недавно извлеченным двоичным файлом:
# dbdeployer --sandbox-binary=/opt/mysql/ deploy single 8.0.11И мы можем наблюдать, как DBdeployer инициализирует MySQL:
# dbdeployer --sandbox-binary=/opt/mysql/ deploy single 8.0.11
Creating directory /root/sandboxes
Database installed in $HOME/sandboxes/msb_8_0_11
run 'dbdeployer usage single' for basic instructions'
. sandbox server started
Подтвердите, что MySQL работает командой ps:
# ps -ef | grep mysql
root 4249 1 0 20:18 pts/0 00:00:00 /bin/sh bin/mysqld_safe
--defaults-file=/root/sandboxes/msb_8_0_11/my.sandbox.cnf
root 4470 4249 1 20:18 pts/0 00:00:00 /opt/mysql/8.0.11/bin/mysqld
--defaults-file=/root/sandboxes/msb_8_0_11/my.sandbox.cnf
--basedir=/opt/mysql/8.0.11 --datadir=/root/sandboxes/msb_8_0_11/data
--plugin-dir=/opt/mysql/8.0.11/lib/plugin --user=root
--log-error=/root/sandboxes/msb_8_0_11/data/msandbox.err
--pid-file=/root/sandboxes/msb_8_0_11/data/mysql_sandbox8011.pid
--socket=/tmp/mysql_sandbox8011.sock --port=8011
root 4527 3836 0 20:18 pts/0 00:00:00 grep --color=auto mysql
Теперь мы можем подключиться к MySQL с помощью DBdeployer команды use:
# cd sandboxes/msb_8_0_11/
# ./use
или используя учетные данные root по умолчанию:
# mysql -uroot -pmsandbox -h 127.0.0.1 -P 8011Если мы хотим настроить среду репликации с топологией source/replica, мы можем сделать это с помощью следующей командной строки:
# dbdeployer --sandbox-binary=/opt/mysql/ deploy replication 8.0.11И у нас будет запущено три процесса mysqld:
# ps -ef | grep mysql
root 4673 1 0 20:26 pts/0 00:00:00 /bin/sh bin/mysqld_safe
--defaults-file=/root/sandboxes/rsandbox_8_0_11/master/my.sandbox.cnf
root 4942 4673 1 20:26 pts/0 00:00:00 /opt/mysql/8.0.11/bin/mysqld
...
--pid-file=/root/sandboxes/rsandbox_8_0_11/master/data/mysql_sandbox201
12.pid --socket=/tmp/mysql_sandbox20112.sock --port=20112
root 5051 1 0 20:26 pts/0 00:00:00 /bin/sh bin/mysqld_safe
--defaults-file=/root/sandboxes/rsandbox_8_0_11/node1/my.sandbox.cnf
root 5320 5051 1 20:26 pts/0 00:00:00 /opt/mysql/8.0.11/bin/mysqld
--defaults-file=/root/sandboxes/rsandbox_8_0_11/node1/my.sandbox.cnf
...
--pid-file=/root/sandboxes/rsandbox_8_0_11/node1/data/mysql_sandbox2011
3.pid --socket=/tmp/mysql_sandbox20113.sock --port=20113
root 5415 1 0 20:26 pts/0 00:00:00 /bin/sh bin/mysqld_safe
--defaults-file=/root/sandboxes/rsandbox_8_0_11/node2/my.sandbox.cnf
root 5684 5415 1 20:26 pts/0 00:00:00 /opt/mysql/8.0.11/bin/mysqld
...
--pid-file=/root/sandboxes/rsandbox_8_0_11/node2/data/mysql_sandbox2011
4.pid --socket=/tmp/mysql_sandbox20114.sock --port=20114
Еще одна топология, которую может настроить DBdeployer, — это Group Replication. В этом примере мы определим base-port. Сделав это, мы прикажем DBdeployer настроить наши серверы, начиная с порта 49007:
# dbdeployer deploy --topology=group replication --sandbox-binary=/opt/mysql/\
8.0.11 --base-port=49007
Теперь давайте посмотрим на пример развертывания Galera Cluster с использованием Percona XtraDB Cluster 5.7.32. Мы укажем base-port и хотим, чтобы наши узлы были настроены с опцией log-slave-updates:
# wget https://downloads.percona.com/downloads/Percona-XtraDB-Cluster-57/\
Percona-XtraDB-Cluster-5.7.32-31.47/binary/tarball/Percona-XtraDB-Cluster-\
5.7.32-rel35-47.1.Linux.x86_64.glibc2.17-debug.tar.gz
# dbdeployer --sandbox-binary=/opt/mysql/ unpack\
Percona-XtraDB-Cluster-5.7.32-rel35-47.1.Linux.x86_64.glibc2.17-debug.tar.gz
# dbdeployer deploy --topology=pxc replication\
--sandbox-binary=/opt/mysql/ 5.7.32 --base-port=45007 -c log-slave-updates
Как мы видели, параметры MySQL можно настраивать. Одним из интересных вариантов является включение репликации MySQL с использованием глобальных идентификаторов транзакций (global transaction identifiers) или GTID (мы более подробно обсудим GTID в главе 13):
# dbdeployer deploy replication --sandbox-binary=/opt/mysql/ 5.7.32 --gtidНаш последний пример показывает, что можно одновременно развернуть несколько автономных версий — здесь мы создаем пять автономных экземпляров:
# dbdeployer deploy multiple --sandbox-binary=/opt/mysql/ 5.7.32 -n 5Предыдущие примеры — это лишь небольшая часть возможностей DBdeployer. Полная документация доступна на GitHub. Другой вариант понять вселенную возможностей — использовать --help в командной строке:
# dbdeployer --help
dbdeployer makes MySQL server installation an easy task.
Runs single, multiple, and replicated sandboxes.
Usage:
dbdeployer [command]
Available Commands:
admin sandbox management tasks
cookbook Shows dbdeployer samples
defaults tasks related to dbdeployer defaults
delete delete an installed sandbox
delete-binaries delete an expanded tarball
deploy deploy sandboxes
downloads Manages remote tarballs
export Exports the command structure in JSON format
global Runs a given command in every sandbox
help Help about any command
import imports one or more MySQL servers into a sandbox
info Shows information about dbdeployer environment samples
sandboxes List installed sandboxes
unpack unpack a tarball into the binary directory
update Gets dbdeployer newest version
usage Shows usage of installed sandboxes
versions List available versions
Flags:
--config string configuration file (default "/root/.dbdeployer/config.json")
-h, --help help for dbdeployer
--sandbox-binary string Binary repository (default "/root/opt/mysql")
--sandbox-home string Sandbox deployment directory (default "/root/sandboxes")
--shell-path string Which shell to use for generated scripts (default "/usr/bin/bash")
--skip-library-check Skip check for needed libraries (may cause nasty errors)
--version version for dbdeployer
Use "dbdeployer [command] --help" for more information about a command.Обновление сервера MySQL
Если чаще всего возникает вопрос о репликации, второй наиболее распространенный вопрос касается обновления экземпляра MySQL. Если процедура не будет тщательно протестирована до того, как она будет запущена в производство, высока вероятность возникновения проблем. Существует два типа обновлений, которые вы можете выполнить:
-
Мажорным обновлением (major upgrade) MySQL будет изменение версии с 5.6 на 5.7 или с 5.7 на 8.0. Такое обновление труднее и сложнее, чем незначительное обновление, потому что изменения в архитектуре более существенны. Например, значительное изменение в MySQL 8.0 включало изменение словаря данных, который теперь является транзакционным и инкапсулируется InnoDB.
-
Минорное обновление (minor upgrade) будет меняться с MySQL 5.7.29 на 5.7.30 или MySQL 8.0.22 на MySQL 8.0.23. В большинстве случаев вам потребуется установить новую версию с помощью диспетчера пакетов вашего дистрибутива. Минорное обновление проще основного, потому что оно не связано с какими-либо изменениями в архитектуре. Модификации направлены на исправление ошибок, повышение производительности и оптимизацию кода.
Чтобы начать планирование обновления, сначала выберите одну из двух стратегий. Это рекомендуемые стратегии в соответствии с документацией, которые мы используем:
- Обновление на месте
-
Это включает в себя закрытие MySQL, замену старых двоичных файлов или пакетов MySQL новыми, перезапуск MySQL в существующем каталоге данных и запуск
mysql_upgrade. - Логическое обновление
-
Это включает в себя экспорт данных в формате SQL из старой версии MySQL с использованием утилиты резервного копирования или экспорта, такой как mysqldump или mysqlpump, установку новой версии MySQL и применение данных SQL к новой версии MySQL. Другими словами, этот процесс включает перестройку всего словаря данных и пользовательских данных. Логическое обновление обычно занимает больше времени, чем обновление на месте.
Независимо от выбранной вами стратегии, важно установить стратегию отката на случай, если что-то пойдет не так. Стратегия отката зависит от выбранного вами плана обновления, а размер базы данных и существующая топология (например, если вы используете реплики или Galera Cluster) будут влиять на это решение.
Вот некоторые дополнительные моменты, которые следует учитывать при планировании обновления:
-
Поддерживается обновление с MySQL 5.7 до 8.0. Однако обновление поддерживается только между выпусками GA. Для MySQL 8.0 требуется обновление версии MySQL 5.7 GA (5.7.9 или выше). Обновления версий MySQL 5.7, отличных от GA, не поддерживаются.
-
Перед обновлением до следующей версии рекомендуется выполнить обновление до последней версии. Например, обновите до последней версии MySQL 5.7 перед обновлением до MySQL 8.0.
-
Обновления, пропускающие версии, не поддерживаются. Например, обновление напрямую с MySQL 5.6 до 8.0 не поддерживается.
Давайте рассмотрим пример обновления с исходной версии MySQL 5.7 до восходящей версии MySQL 8.0 с использованием метода на месте:
-
Остановите службу MySQL. Выполните полное завершение работы с помощью
systemctl:# systemctl stop mysqld -
Удалите старые бинарники:
# yum erase mysql-community -yЭтот процесс удаляет только двоичные файлы и не затрагивает datadir (см. «Содержание каталога MySQL»).
-
Следуйте обычным шагам процесса установки (см. «Установка MySQL в Linux»). Например, чтобы использовать версию сообщества MySQL 8.0 в CentOS 7 с помощью
yum:# yum-config-manager --enable mysql80-community -
Установите новые бинарники:
# yum install mysql-community-server -y -
Запустите службу MySQL:
# systemctl start mysqld
В журналах мы можем наблюдать, что MySQL обновил словарь данных и теперь мы используем MySQL 8.0.21:
# tail -f /var/log/mysqld.log
2020-08-09T21:20:10.356938Z 2 [System] [MY-011003] [Server] Finished populating Data Dictionary tables with data.
2020-08-09T21:20:11.734091Z 5 [System] [MY-013381] [Server] Server upgrade from '50700' to '80021' started.
2020-08-09T21:20:17.342682Z 5 [System] [MY-013381] [Server] Server upgrade from '50700' to '80021' completed.
...
2020-08-09T21:20:17.463685Z 0 [System] [MY-010931] [Server] /usr/sbin/mysqld: ready for connections. Version: '8.0.21' socket: '/var/lib/mysql/mysql.sock' port: 3306 MySQL Community Server - GPL.
Распространенный вопрос заключается в том, безопасно ли обновляться до последней мажорной версии. Ответ… это зависит от многого. Как и в случае с любым новым продуктом в отрасли, первые пользователи, как правило, получают выгоду от новых функций, но они также являются тестировщиками, и они могут обнаружить новые ошибки и пострадать от них. Когда был выпущен MySQL 8.0, мы рекомендовали дождаться трех второстепенных выпусков, прежде чем рассматривать возможность перехода. Золотое правило этой книги — все тестировать заранее, прежде чем переходить к следующему шагу. Если вы узнаете об этом из этой книги, мы будем считать, что наша миссия выполнена.
Глава 2
Моделирование и проектирование баз данных
При внедрении новой базы данных легко попасть в ловушку быстрого запуска чего-либо, не затрачивая при этом достаточно времени и усилий на проектирование. Эта небрежность часто приводит к дорогостоящим изменениям дизайна и повторной реализации в будущем. Проектирование базы данных похоже на набросок чертежей дома; глупо начинать строить без детальных планов. Примечательно, что хороший дизайн позволяет вам расширять исходное здание, не снося все и не начиная с нуля. И, как вы увидите, плохой дизайн напрямую связан с низкой производительностью базы данных.
Как не стоит разрабатывать базу данных
Проектирование базы данных, вероятно, не самая захватывающая задача в мире, но на самом деле она становится одной из самых важных. Прежде чем мы опишем процесс проектирования, давайте рассмотрим пример проектирования базы данных в процессе работы.
Представьте, что мы хотим создать базу данных для хранения оценок студентов факультета информатики университета. Мы могли бы создать таблицу Student_Grades для хранения оценок каждого учащегося и каждого курса. В таблице будут столбцы с именами и фамилиями каждого студента и каждого курса, который они прошли, название курса и результат в процентах (показанный как Pctg). У нас будет отдельная строка для каждого студента для каждого из их курсов:
+------------+---------+-----------------------+------+
| GivenNames | Surname | CourseName | Pctg |
+------------+---------+-----------------------+------+
| John Paul | Bloggs | Data Science | 72 |
| Sarah | Doe | Programming 1 | 87 |
| John Paul | Bloggs | Computing Mathematics | 43 |
| John Paul | Bloggs | Computing Mathematics | 65 |
| Sarah | Doe | Data Science | 65 |
| Susan | Smith | Computing Mathematics | 75 |
| Susan | Smith | Programming 1 | 55 |
| Susan | Smith | Computing Mathematics | 80 |
+------------+---------+-----------------------+------+
Список красивый и компактный, мы можем легко получить доступ к оценкам для любого студента или любого курса, и он похож на электронную таблицу. Однако у нас может быть более одного ученика с одним и тем же именем. Например, в выборке данных есть две записи для Сьюзен Смит и курса вычислительной математики. Какая Сьюзен Смит набрала 75%, а какая 80%? Обычный способ отличить повторяющиеся записи данных состоит в том, чтобы присвоить каждой записи уникальный номер. Здесь мы можем присвоить уникальный номер StudentID каждому студенту:
+------------+------------+---------+-----------------------+------+
| StudentID | GivenNames | Surname | CourseName | Pctg |
+------------+------------+---------+-----------------------+------+
| 12345678 | John Paul | Bloggs | Data Science | 72 |
| 12345121 | Sarah | Doe | Programming 1 | 87 |
| 12345678 | John Paul | Bloggs | Computing Mathematics | 43 |
| 12345678 | John Paul | Bloggs | Computing Mathematics | 65 |
| 12345121 | Sarah | Doe | Data Science | 65 |
| 12345876 | Susan | Smith | Computing Mathematics | 75 |
| 12345876 | Susan | Smith | Programming 1 | 55 |
| 12345303 | Susan | Smith | Computing Mathematics | 80 |
+------------+------------+---------+-----------------------+------+
Теперь мы знаем, какая Сьюзен Смит набрала 80%: та, у которой студенческий билет 12345303.
Есть еще одна проблема. В нашей таблице Джон Пол Блоггс имеет две оценки по курсу вычислительной математики: он провалил его один раз с 43%, а затем сдал его с 65% со второй попытки. В реляционной базе данных строки образуют набор, и между ними нет неявного порядка. Глядя на эту таблицу, мы можем предположить, что проход произошел после сбоя, но мы не можем быть уверены. Нет никакой гарантии, что новая оценка появится после старой, поэтому нам нужно добавить информацию о том, когда была выставлена каждая оценка, скажем, добавив год (Year) и семестр (Sem):
+------------+------------+---------+-----------------------+------+-----+------+
| StudentID | GivenNames | Surname | CourseName | Year | Sem | Pctg |
+------------+------------+---------+-----------------------+------+-----+------+
| 12345678 | John Paul | Bloggs | Data Science | 2019 | 2 | 72 |
| 12345121 | Sarah | Doe | Programming 1 | 2020 | 1 | 87 |
| 12345678 | John Paul | Bloggs | Computing Mathematics | 2019 | 2 | 43 |
| 12345678 | John Paul | Bloggs | Computing Mathematics | 2020 | 1 | 65 |
| 12345121 | Sarah | Doe | Data Science | 2020 | 1 | 65 |
| 12345876 | Susan | Smith | Computing Mathematics | 2019 | 1 | 75 |
| 12345876 | Susan | Smith | Programming 1 | 2019 | 2 | 55 |
| 12345303 | Susan | Smith | Computing Mathematics | 2020 | 1 | 80 |
+------------+------------+---------+-----------------------+------+-----+------+
Обратите внимание, что таблица Student_Grades стала немного раздутой. Мы повторяли студенческий билет, имя и фамилию каждый год. Мы могли бы разделить информацию и создать таблицу Student_Details:
+------------+------------+---------+
| StudentID | GivenNames | Surname |
+------------+------------+---------+
| 12345121 | Sarah | Doe |
| 12345303 | Susan | Smith |
| 12345678 | John Paul | Bloggs |
| 12345876 | Susan | Smith |
+------------+------------+---------+
И мы могли бы хранить меньше информации в таблице Student_Grades:
+------------+-----------------------+------+-----+------+
| StudentID | CourseName | Year | Sem | Pctg |
+------------+-----------------------+------+-----+------+
| 12345678 | Data Science | 2019 | 2 | 72 |
| 12345121 | Programming 1 | 2020 | 1 | 87 |
| 12345678 | Computing Mathematics | 2019 | 2 | 43 |
| 12345678 | Computing Mathematics | 2020 | 1 | 65 |
| 12345121 | Data Science | 2020 | 1 | 65 |
| 12345876 | Computing Mathematics | 2019 | 1 | 75 |
| 12345876 | Programming 1 | 2019 | 2 | 55 |
| 12345303 | Computing Mathematics | 2020 | 1 | 80 |
+------------+-----------------------+------+-----+------+
Чтобы найти оценки учащегося, нам нужно сначала найти его идентификатор учащегося в таблице Student_Details, а затем прочитать оценки для этого идентификатора учащегося из таблицы Student_Grades.
Однако есть еще вопросы, которые мы не рассмотрели. Например, должны ли мы хранить информацию о дате зачисления учащегося, почтовом адресе и адресе электронной почты, оплате или посещаемости? Должны ли мы хранить разные типы почтовых адресов? Как мы должны хранить адреса, чтобы ничего не ломалось, когда ученики меняют свои адреса?
Реализация базы данных таким образом проблематична; мы продолжаем сталкиваться с вещами, о которых не думали, и вынуждены постоянно менять структуру нашей базы данных. Мы можем сэкономить много доработок, тщательно документируя требования заранее, а затем прорабатывая их для разработки согласованного дизайна.
Процесс проектирования базы данных
В проектировании базы данных есть три основных этапа, на каждом из которых создается описание более низкого уровня:
- Анализ требований
-
Сначала мы определяем и записываем, что нам нужно от базы данных, какие данные мы будем хранить и как элементы данных соотносятся друг с другом. На практике это может включать детальное изучение требований к приложению и общение с людьми в различных ролях, которые будут взаимодействовать с базой данных и приложением.
- Концептуальный дизайн
-
Как только мы узнаем требования к базе данных, мы преобразуем их в формальное описание структуры базы данных. Позже в этой главе мы увидим, как использовать моделирование для создания концептуального проекта.
- Логичный дизайн
-
Наконец, мы сопоставляем структуру базы данных с существующей системой управления базами данных и таблицами базы данных.
В конце главы мы рассмотрим, как можно использовать инструмент MySQL Workbench с открытым исходным кодом для преобразования концептуального проекта в схему базы данных MySQL.
Модель отношений сущностей
На базовом уровне базы данных хранят информацию об отдельных объектах или сущностях (entities), а также об ассоциациях или отношениях (relationships) между этими сущностями. Например, база данных университета может хранить информацию о студентах, курсах и зачислении. Учащийся и курс являются сущностями, тогда как зачисление — это отношение между учащимся и курсом. Точно так же база данных запасов и продаж может хранить информацию о продуктах, клиентах и продажах. Товар и покупатель — это сущности, а продажа — это отношения между покупателем и товаром. Когда вы только начинаете, вы часто путаетесь между сущностями и отношениями, и в конечном итоге вы можете проектировать отношения как сущности и наоборот. Лучший способ улучшить свои навыки проектирования баз данных — много практиковаться.
В популярном подходе к концептуальному проектированию используется модель Entity Relationship (ER), которая помогает преобразовать требования в формальное описание сущностей и отношений в базе данных. Мы начнем с рассмотрения того, как работает процесс моделирования ER, а затем рассмотрим его в разделе «Примеры моделирования отношений сущностей» для трех примеров баз данных.
Представление сущностей
Чтобы помочь визуализировать дизайн, подход к моделированию ER включает в себя рисование ER-диаграммы. На диаграмме ER мы представляем сущность, заданную прямоугольником, содержащим имя сущности. В нашем примере с базой данных продаж наша ER-диаграмма будет отображать наборы сущностей продуктов и клиентов, как показано на рис. 2-1.

Рисунок 2-1. Набор сущностей представлен именованным прямоугольником
Обычно мы используем базу данных для хранения определенных характеристик или атрибутов (attributes) сущностей. Мы могли бы записать имя, адрес электронной почты, почтовый адрес и номер телефона каждого клиента в базу данных продаж. В более сложном приложении для управления взаимоотношениями с клиентами (CRM) мы могли бы также хранить имена супругов и детей клиента, языки, на которых говорит клиент, историю взаимодействия клиента с нашей компанией и так далее. Атрибуты описывают сущность, которой они принадлежат.
Мы можем сформировать атрибут из более мелких частей; например, мы составляем почтовый адрес из номера улицы, города, почтового индекса и страны. Мы классифицируем атрибуты как составные, если они таким образом состоят из более мелких частей, и как простые в противном случае.
Некоторые атрибуты могут иметь несколько значений для данного объекта — например, клиент может предоставить несколько телефонных номеров, поэтому атрибут телефонного номера является многозначным.
Атрибуты помогают отличить один объект от других объектов того же типа. Мы могли бы использовать атрибут имени, чтобы различать клиентов, но это может оказаться неадекватным решением, поскольку несколько клиентов могут иметь одинаковые имена. Чтобы отличить их друг от друга, нам нужен атрибут (или минимальная комбинация атрибутов), гарантированно уникальный для каждого клиента. Идентифицирующий атрибут или атрибуты образуют уникальный ключ, и в данном конкретном случае мы называем его первичным ключом (primary key).
В нашем примере мы можем предположить, что нет двух клиентов с одинаковым адресом электронной почты, поэтому адрес электронной почты может быть первичным ключом. Однако при проектировании базы данных нам необходимо тщательно продумать последствия нашего выбора. Например, если мы решим идентифицировать клиентов по их адресам электронной почты, как мы поступим с клиентом, имеющим несколько адресов электронной почты? Любые приложения, которые мы создаем для использования этой базы данных, могут рассматривать каждый адрес электронной почты как отдельного человека. Было бы трудно адаптировать все, чтобы люди могли иметь более одного адреса. Использование адреса электронной почты в качестве ключа также означает, что каждый клиент должен иметь адрес электронной почты; в противном случае мы не сможем отличить клиентов, у которых его нет.
Глядя на другие атрибуты того, который может служить альтернативным ключом, мы видим, что, хотя два клиента могут иметь один и тот же номер телефона (поэтому мы не можем использовать номер телефона в качестве ключа), вполне вероятно, что люди, у которых есть один и тот же телефонный номер не будет одного и того же имени, поэтому мы можем использовать комбинацию телефонного номера и имени в качестве составного ключа.
Ясно, что может быть несколько возможных ключей, которые можно использовать для идентификации объекта; мы выбираем одну из альтернатив или ключей-кандидатов в качестве нашего основного или первичного ключа. Обычно мы выбираем на основе того, насколько мы уверены, что атрибут будет непустым и уникальным для каждой сущности, и насколько мал ключ (более короткие ключи быстрее поддерживать и использовать для выполнения операций поиска).
На диаграмме ER атрибуты представлены в виде помеченных овалов, связанных с их сущностью, как показано на рис. 2-2. Атрибуты, составляющие первичный ключ, показаны подчеркнутыми. Части любых составных атрибутов нарисованы соединенными с овалом составного атрибута, а многозначные атрибуты показаны как овалы с двойной линией.

Рисунок 2-2. Представление диаграммы ER сущности клиента
Значения атрибутов выбираются из области допустимых значений. Например, мы можем указать, что атрибуты имени и фамилии клиента могут представлять собой строку длиной до 100 символов, а номер телефона может быть строкой длиной до 40 символов. Точно так же цена продукта может быть положительным рациональным числом.
Атрибуты могут быть пустыми; например, некоторые клиенты могут не указывать свои номера телефонов. Однако первичный ключ объекта (включая компоненты многоатрибутного первичного ключа) никогда не должен быть неизвестным (технически он должен быть NOT NULL). Таким образом, если клиент может не указывать адрес электронной почты, мы не можем использовать адрес электронной почты в качестве ключа.
Вы должны хорошо подумать, классифицируя атрибут как многозначный: все ли значения эквивалентны или они на самом деле представляют разные вещи? Например, при перечислении нескольких телефонных номеров для клиента, было бы более полезно пометить их отдельно как номер рабочего телефона клиента, номер домашнего телефона, номер мобильного телефона и т. д.?
Давайте посмотрим на другой пример. В требованиях к базе данных продаж может быть указано, что продукт имеет название и цену. Мы можем видеть, что продукт является сущностью, потому что это отдельный объект. Однако название продукта и цена не являются отдельными объектами; это атрибуты, которые описывают сущность продукта. Обратите внимание: если мы хотим иметь разные цены для разных рынков, тогда цена больше не связана только с сущностью продукта, и нам нужно будет моделировать ее по-разному.
Для некоторых приложений никакая комбинация атрибутов не может однозначно идентифицировать объект (или было бы слишком громоздко использовать большой составной ключ), поэтому мы создаем искусственный атрибут, который определяется как уникальный и поэтому может использоваться в качестве ключа: номера учащихся, номера социального страхования, номера водительских прав и номера библиотечных карт — это примеры уникальных атрибутов, созданных для различных приложений. В нашем приложении для инвентаризации и продаж мы можем хранить разные товары с одинаковыми названиями и ценами. Например, мы могли бы продать две модели «Four-Port USB 2.0 Hub» по цене 4,95 доллара каждая. Чтобы различать продукты, мы можем присвоить каждому товару уникальный идентификационный номер; это будет первичный ключ. Каждый объект продукта будет иметь атрибуты имени, цены и идентификатора продукта. Это показано на диаграмме ER на рис. 2-3.

Рисунок 2-3. Представление диаграммы ER сущности продукта
Представление отношений
Сущности могут участвовать в отношениях с другими сущностями. Например, клиент может купить продукт, студент может пройти курс, у сотрудника может быть адрес и так далее.
Как и сущности, отношения могут иметь атрибуты: мы можем определить продажу как отношение между сущностью клиента (идентифицируемой уникальным адресом электронной почты) и заданным номером сущности продукта (идентифицируемой уникальным ID продукта), которое существует на определенную дату и время (временную метку).
Затем наша база данных могла бы записывать каждую продажу и сообщать нам, например, что в 15:13 в среду, 22 марта, Маркос Альбе купил один «Raspberry Pi 4», один «SSD M.2 NVMe на 500 ГБ» и два комплекта «2000 Watt 5.1 Channel Sub-Woofer Speakers».
На каждой стороне отношений может появляться разное количество сущностей. Например, каждый клиент может купить любое количество продуктов, и каждый продукт может быть куплен любым количеством клиентов. Это известно как отношение многие ко многим (many-to-many). Мы также можем иметь отношения один ко многим (one-to-many). Например, у одного человека может быть несколько кредитных карт, но каждая кредитная карта принадлежит только одному человеку. Глядя на это с другой стороны, отношение один ко многим становится отношением многие к одному; например, многие кредитные карты принадлежат одному человеку. Наконец, серийный номер на автомобильном двигателе является примером отношения один к одному (one-to-one); каждый двигатель имеет только один серийный номер, и каждый серийный номер принадлежит только одному двигателю. Мы используем сокращенные термины 1:1, 1:N и M:N для отношений «один к одному», «один ко многим» и «многие ко многим».
Количество сущностей по обе стороны отношения (мощность (cardinality) отношения) определяет ключевые ограничения (key constraints) отношения. Важно тщательно продумать кардинальность (или мощность) отношений. Существует множество взаимосвязей, которые сначала могут показаться однозначными, но на деле оказываются более сложными. Например, люди иногда меняют свои имена; в некоторых приложениях, таких как полицейские базы данных, это представляет особый интерес, поэтому может возникнуть необходимость в моделировании отношения «многие ко многим» между сущностью-лицом и сущностью-именем. Перепроектирование базы данных может быть дорогостоящим и трудоемким, если вы предполагаете, что связь проще, чем она есть на самом деле.
На диаграмме ER мы представляем набор отношений с именованным ромбом. Мощность отношений часто указывается рядом с ромбом отношений; это стиль, который мы используем в этой книге. (Еще один распространенный стиль — это наличие стрелки на линии, соединяющей сущность со стороны «1» с ромбом отношения.) Рисунок 2-4 показывает взаимосвязь между объектами customer и product, а также атрибуты number и timestamp взаимосвязи sale.

Рисунок 2-4. Представление диаграммы ER сущностей клиента и продукта, а также отношения продажи между ними.
Частичное и полное участие
Отношения между сущностями могут быть необязательными или обязательными. В нашем примере мы могли бы решить, что человек считается покупателем, только если он купил продукт. С другой стороны, мы могли бы сказать, что покупатель — это человек, о котором мы знаем и который, как мы надеемся, мог бы что-то купить, то есть в нашей базе данных можно указать людей, которые никогда не покупают продукт. В первом случае объект клиента имеет полное участие в отношениях покупки (все клиенты купили продукт, и у нас не может быть клиента, который не купил продукт), а во втором случае он имеет частичное участие (покупатель может купить товар). Они называются ограничениями участия в отношениях. На диаграмме ER мы обозначаем полное участие двойной линией между полем сущности и ромбом отношений.
Сущность или атрибут?
Время от времени мы сталкиваемся со случаями, когда задаемся вопросом, должен ли элемент быть атрибутом или сущностью сам по себе. Например, адрес электронной почты может быть смоделирован как самостоятельный объект. Если вы сомневаетесь, рассмотрите следующие эмпирические правила:
- Представляет ли элемент непосредственный интерес для базы данных?
-
Объекты прямого интереса должны быть сущностями, а информация, описывающая их, должна храниться в атрибутах. Наша база данных запасов и продаж действительно заинтересована в клиентах, а не в их адресах электронной почты, поэтому адрес электронной почты лучше всего моделировать как атрибут сущности клиента.
- Есть ли у предмета собственные компоненты?
-
Если это так, мы должны найти способ представления этих компонентов; отдельная сущность может быть лучшим решением. В примере с оценками учащихся в начале главы мы сохранили название курса, год и семестр для каждого курса, который изучает студент. Было бы более компактно рассматривать курс как отдельный объект и создавать идентификационный номер класса для идентификации каждый раз, когда курс предлагается студентам («предложение»).
- Может ли объект иметь несколько экземпляров?
-
Если это так, мы должны найти способ хранить данные о каждом экземпляре. Самый простой способ сделать это — представить объект как отдельный объект. В нашем примере с продажами мы должны спросить, разрешено ли клиентам иметь более одного адреса электронной почты; если это так, мы должны смоделировать адрес электронной почты как отдельный объект.
- Объект часто не существует или неизвестен?
-
Если это так, то это фактически атрибут только некоторых объектов, и было бы лучше моделировать его как отдельный объект, а не как атрибут, который часто бывает пустым. Рассмотрим простой пример: чтобы хранить оценки студентов по разным курсам, мы могли бы иметь атрибут для оценки студента по каждому возможному курсу, как показано на рис. 2-5. Но поскольку большинство учащихся получат оценки только по некоторым из этих курсов, лучше представить оценки в виде отдельного набора сущностей, как показано на рис. 2-6.

Рисунок 2-5. Представление на диаграмме ER оценок учащихся как атрибутов сущности ученика

Рисунок 2-6. Представление на диаграмме ER оценок учащихся как отдельного объекта
Сущность или отношения?
Простой способ решить, должен ли объект быть сущностью или отношением, — это сопоставить существительные в требованиях с сущностями, а глаголы — с отношениями. Например, в утверждении «Программа на получение степени состоит из одного или нескольких курсов» мы можем идентифицировать сущности «программа» и «курс» и отношение «состоит из». Точно так же в утверждении «Студент записывается на одну программу» мы можем идентифицировать сущности «студент» и «программа» и отношение «записывается». Конечно, мы можем выбрать термины для сущностей и отношений, отличные от тех, которые появляются в отношениях, но рекомендуется не отклоняться слишком далеко от соглашений об именах, используемых в требованиях, чтобы можно было проверить проект на соответствие требованиям. При прочих равных постарайтесь, чтобы дизайн был простым, и по возможности избегайте введения тривиальных сущностей. То есть нет необходимости иметь отдельную сущность для зачисления учащегося, когда мы можем смоделировать ее как связь между существующими студенческими и программными сущностями.
Промежуточные сущности
Часто можно концептуально упростить связь «многие ко многим», заменив ее новой промежуточной (intermediate) сущностью (иногда называемой ассоциированной (associate) сущностью) и соединив исходные сущности через связь «многие к одному» и «один ко многим».
Рассмотрим такое утверждение: «Пассажир может забронировать место на рейс». Это отношение «многие ко многим» между сущностями «пассажир» и «рейс». Соответствующий фрагмент диаграммы ER показан на рисунке 2-7.

Рисунок 2-7. Пассажир участвует в отношениях M:N с рейсом
Однако давайте посмотрим на это с обеих сторон отношений:
На любой рейс может быть забронировано много пассажиров.
Любой пассажир может иметь бронирование на несколько рейсов.
Следовательно, мы можем рассматривать отношения «многие ко многим» как фактически два отношения «один ко многим», по одному в каждом направлении. Это указывает нам на существование скрытой промежуточной сущности, бронирования, между сущностями рейса и пассажира. Требование можно было бы лучше сформулировать так: «Пассажир может забронировать место на рейсе». Обновленный фрагмент ER-диаграммы показан на рис. 2-8.

Рисунок 2-8. Промежуточный объект бронирования между объектами пассажира и рейса
Каждый пассажир может участвовать в нескольких бронированиях, но каждое бронирование принадлежит одному пассажиру, поэтому кардинальность этого отношения равна 1:N. Точно так же может быть много бронирований для данного рейса, но каждое бронирование относится к одному рейсу, поэтому это отношение также имеет кардинальность 1:N. Поскольку каждое бронирование должно быть связано с конкретным пассажиром и рейсом, организация, осуществляющая бронирование, полностью участвует во взаимоотношениях с этими организациями (как описано в разделе «Частичное и полное участие»). Это общее участие не может быть эффективно отражено в представлении на рис. 2-7.
Слабые и сильные сущности
Контекст очень важен в нашем повседневном общении; если мы знаем контекст, мы можем работать с гораздо меньшим количеством информации. Например, мы обычно называем членов семьи только по имени или прозвищу. Там, где существует двусмысленность, мы добавляем дополнительную информацию, например фамилию, чтобы прояснить наши намерения. При проектировании базы данных мы можем опустить некоторую ключевую информацию для сущностей, которые зависят от других сущностей. Например, если бы мы хотели сохранить имена дочерних объектов наших клиентов, мы могли бы создать дочернюю сущность и хранить только достаточно ключевой информации, чтобы идентифицировать ее в контексте ее родителя. Мы могли бы просто указать имя ребенка, исходя из предположения, что у клиента никогда не будет нескольких детей с одинаковым именем. Здесь дочерняя сущность является слабой (weak) сущностью, и ее связь с сущностью клиента называется идентифицирующей связью (identifying relationship). Слабые сущности полностью участвуют в идентифицирующей связи, поскольку они не могут существовать в базе данных независимо от сущности, которой они принадлежат.
На диаграмме ER мы показываем слабые объекты и идентифицирующие отношения двойными линиями, а частичный ключ слабого объекта — пунктирным подчеркиванием, как на рис. 2-9. Слабый объект однозначно идентифицируется в контексте принадлежащего ему (или сильного (strong))) объекта, поэтому полный ключ слабого объекта представляет собой комбинацию его собственного (частичного) ключа с ключом объекта-владельца. Чтобы однозначно идентифицировать ребенка в нашем примере, нам нужно имя ребенка и адрес электронной почты родителя ребенка.

Рисунок 2-9. Представление диаграммы ER слабой сущности
На рис. 2.10 показана сводка символов, которые мы объяснили для ER-диаграмм.

Рисунок 2-10. Краткое изложение символов диаграммы ER
Нормализация базы данных
Нормализация базы данных — важная концепция при разработке реляционной структуры данных. Доктор Эдгар Ф. Кодд, изобретатель модели реляционной базы данных, предложил нормальные формы в начале 70-х, и они до сих пор широко используются в отрасли. Даже с появлением баз данных NoSQL в краткосрочной или среднесрочной перспективе нет никаких признаков того, что реляционные базы данных исчезнут или что обычные формы выйдут из употребления.
Основная цель нормальных форм — уменьшить избыточность данных и повысить целостность данных. Нормализация также облегчает процесс перепроектирования и расширения структуры базы данных.
Официально существует шесть нормальных форм, но большинство архитекторов баз данных имеют дело только с первыми тремя формами. Это связано с тем, что процесс нормализации является прогрессивным, и мы не можем достичь более высокого уровня нормализации базы данных, пока не будут удовлетворены предыдущие уровни. Однако использование всех шести норм слишком сильно ограничивает модель базы данных, и в целом их становится очень сложно реализовать.
В реальных рабочих нагрузках обычно возникают проблемы с производительностью. Это одна из причин существования заданий извлечения, преобразования, загрузки (extract, transform, load) (ETL): они денормализуют данные для их обработки.
Рассмотрим первые три нормальные формы:
- Первая нормальная форма (1NF) преследует следующие цели
-
Удалить повторяющиеся группы в отдельных таблицах.
Создать отдельную таблицу для каждого набора связанных данных.
Определить каждый набор связанных данных с помощью первичного ключа.
Если отношение содержит составные или многозначные атрибуты, оно нарушает первую нормальную форму. И наоборот, отношение находится в первой нормальной форме, если оно не содержит составных или многозначных атрибутов. Таким образом, отношение находится в первой нормальной форме, если каждый атрибут в этом отношении имеет единственное значение соответствующего типа.
- Целями второй нормальной формы (2NF) являются
-
Создать отдельные таблицы для наборов значений, которые применяются к нескольким записям.
Связать эти таблицы с помощью внешнего ключа.
Записи не должны зависеть ни от чего, кроме первичного ключа таблицы (при необходимости составного ключа).
- Третья нормальная форма (3NF) добавляет еще одну цель
-
- Исключить поля, не зависящие от ключа.
Значения в записи, которые не являются частью ключа этой записи, не принадлежат таблице. Как правило, каждый раз, когда содержимое группы полей может относиться к нескольким записям в таблице, следует подумать о размещении этих полей в отдельной таблице.
В таблице 2-1 перечислены нормальные формы, от наименее до наиболее нормализованной. Ненормализованная форма (UNF) — это модель базы данных, которая не удовлетворяет ни одному из условий нормализации базы данных. Существуют и другие формы нормализации, но они выходят за рамки данного обсуждения.
| UNF (1970) |
1NF (1970) |
2NF (1971) |
3NF (1971) |
4NF (1977) |
5NF (1979) |
6NF (2003) |
|
|---|---|---|---|---|---|---|---|
| Первичный ключ (без повторяющихся кортежей) | Может быть | Да | Да | Да | Да | Да | Да |
| Нет повторяющихся групп | Нет | Да | Да | Да | Да | Да | Да |
| Атомарные столбцы (ячейки имеют одно значение) | Нет | Да | Да | Да | Да | Да | Да |
| Каждая нетривиальная функциональная зависимость либо не начинается с надлежащего подмножества ключа-кандидата, либо заканчивается первичным атрибутом (никаких частичных функциональных зависимостей непервичных атрибутов от ключей-кандидатов). | Нет | Нет | Да | Да | Да | Да | Да |
| Каждая нетривиальная функциональная зависимость начинается с суперключа или заканчивается первичным атрибутом (без транзитивных функциональных зависимостей непервичных атрибутов от ключей-кандидатов). | Нет | Нет | Нет | Да | Да | Да | Да | Каждая нетривиальная функциональная зависимость либо начинается с суперключа, либо заканчивается элементарным простым атрибутом. | Нет | Нет | Нет | Нет | Да | Да | Н/Д | Каждая нетривиальная функциональная зависимость начинается с суперключа | Нет | Нет | Нет | Нет | Да | Да | Н/Д | Каждая нетривиальная многозначная зависимость начинается с суперключа | Нет | Нет | Нет | Нет | Да | Да | Н/Д | Каждая зависимость соединения имеет компонент суперключа | Нет | Нет | Нет | Нет | Нет | Да | Н/Д | Каждая зависимость соединения имеет только суперключевые компоненты. | Нет | Нет | Нет | Нет | Нет | Да | Н/Д | Каждое ограничение является следствием ограничений предметной области и ключевых ограничений. | Нет | Нет | Нет | Нет | Нет | Нет | Н/Д | Каждая зависимость соединения тривиальна | Нет | Нет | Нет | Нет | Нет | Нет | Да |
Нормализация таблицы примеров
Чтобы прояснить эти понятия, давайте рассмотрим пример нормализации вымышленной таблицы учеников.
Начнем с ненормализованной таблицы:
Student# Advisor Adv-Room Class1 Class2 Class3
1022 Jones 412 101-07 143-01 159-02
4123 Smith 216 201-01 211-02 214-01
Первая нормальная форма: нет повторяющихся групп
Таблицы должны иметь только одно поле для каждого атрибута. Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в нашей ненормализованной таблице указывают на проблемы с дизайном.
Электронные таблицы часто имеют несколько полей для одного и того же атрибута (например, address1, address2, address3), а таблицы — нет. Вот еще один способ взглянуть на эту проблему: при отношении «один ко многим» не помещайте одну сторону и многие стороны в одну и ту же таблицу. Вместо этого создайте другую таблицу в первой нормальной форме, удалив повторяющуюся группу, например, с Class#, как показано здесь:
Student# Advisor Adv-Room Class#
1022 Jones 412 101-07
1022 Jones 412 143-01
1022 Jones 412 159-02
4123 Smith 216 201-01
4123 Smith 216 211-02
4123 Smith 216 214-01
Вторая нормальная форма: устранение избыточных данных
Обратите внимание на несколько значений Class# для каждого значения Student# в предыдущей таблице. Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме.
Следующие две таблицы демонстрируют преобразование во вторую нормальную форму. Теперь у нас есть таблица Students:
Student# Advisor Adv-Room
1022 Jones 412
4123 Smith 216
и таблица Registration:
Student# Class#
1022 101-07
1022 143-01
1022 159-02
4123 201-01
4123 211-02
4123 214-01
Третья нормальная форма: исключение данных, не зависящих от ключа
В предыдущем примере Adv-Room (номер офиса консультанта) функционально зависит от атрибута Advisor. Решение состоит в том, чтобы переместить этот атрибут из таблицы Students в таблицу Faculty, как показано ниже.
Теперь таблица Students выглядит так:
Student# Advisor
1022 Jones
4123 Smith
А вот и таблица Faculty:
Name Room Dept
Jones 412 42
Smith 216 42
Примеры моделирования отношений сущностей
В предыдущих разделах мы рассмотрели гипотетические примеры, чтобы помочь вам понять основы проектирования баз данных, диаграмм ER и нормализации. Теперь мы рассмотрим несколько примеров ER из демонстрационных баз данных, доступных для MySQL. Для визуализации диаграмм ER мы будем использовать MySQL Workbench.
MySQL Workbench использует физическое представление ER. Модели физических диаграмм ER более детализированы и показывают процессы, необходимые для добавления информации в базу данных. Вместо использования символов мы используем таблицы на диаграмме ER, что делает ее ближе к реальной базе данных. MySQL Workbench делает еще один шаг вперед и использует расширенные диаграммы сущность-связь (EER). Диаграммы EER представляют собой расширенную версию диаграмм ER.
Мы не будем вдаваться во все детали, но главное преимущество диаграммы EER заключается в том, что она предоставляет все элементы диаграммы ER, добавляя поддержку:
Наследование атрибутов и отношений
Типы категорий или союзов
Специализация и обобщение
Подклассы и суперклассы
Давайте начнем с процесса загрузки образцов баз данных и визуализации их диаграмм EER в MySQL Workbench.
Первая база, которую мы будем использовать, — это база данных sakila. Разработка этой базы данных началась в 2005 году. Ранние проекты были основаны на базе данных, использованной в официальном документе Dell Three Approaches to MySQL Applications on Dell PowerEdge Servers, который был разработан для представления онлайн-магазина DVD. Точно так же образец базы данных sakila предназначен для представления магазина проката DVD и заимствует имена фильмов и актеров из образца базы данных Dell. Вы можете использовать следующие команды для импорта базы данных sakila в ваш экземпляр MySQL:
# wget https://downloads.mysql.com/docs/sakila-db.tar.gz
# tar -xvf sakila-db.tar.gz
# mysql -uroot -pmsandbox < sakila-db/sakila-schema.sql
# mysql -uroot -pmsandbox < sakila-db/sakila-data.sql
sakila также предоставляет модель EER в файле sakila.mwb. Вы можете открыть файл с помощью MySQL Workbench, как показано на рисунке 2-11.

Рисунок 2-11. Модель EER базы данных sakila; обратите внимание на физическое представление объектов вместо использования символов
Далее идет база данных world, в которой используются выборочные данные из Statistics Finland.
Следующие команды импортируют базу данных world в ваш экземпляр MySQL:
# wget https://downloads.mysql.com/docs/world-db.tar.gz
# tar -xvf world-db.tar.gz
# mysql -uroot -plearning_mysql < world-db/world.sql
База данных world не поставляется с файлом EER, как это делает sakila, но вы можете создать модель EER из базы данных с помощью MySQL Workbench. Для этого выберите Reverse Engineer в меню Database, как показано на рис. 2-12.

Рисунок 2-12. Реверс-инжиниринг из базы данных world
Workbench подключится к базе данных (если она еще не подключена) и предложит вам выбрать схему, которую вы хотите реконструировать, как показано на рисунке 2-13.

Рисунок 2-13. Выбор схемы
Нажмите Continue, а затем нажмите Execute на следующем экране, показанном на рис. 2-14.

Рисунок 2-14. Нажмите Execute, чтобы начать процесс реверс-инжиниринга.
В результате получается модель ER для базы данных world, показанная на рис. 2-15.

Рисунок 2-15. Модель ER для базы данных world
Последняя база данных, которую вы импортируете, — это база данных employees. Фушэн Ван и Карло Дзаньоло создали исходные данные в Siemens Corporate Research. Джузеппе Максиа создал реляционную схему, а Патрик Крюс экспортировал данные в реляционный формат.
Чтобы импортировать базу данных, сначала вам нужно клонировать репозиторий Git:
# git clone https://github.com/datacharmer/test_db.git
# cd test_db
# cat employees.sql | mysql -uroot -psekret
Затем вы можете снова использовать процедуру реверс-инжиниринга в MySQL Workbench, чтобы создать модель ER для базы данных employees, как показано на рисунке 2-16.

Рисунок 2-16. Модель ER для базы данных employees
Важно внимательно просмотреть модели ER, показанные здесь, чтобы понять отношения между сущностями и их атрибутами. Как только концепции затвердеют, приступайте к практике. Вы увидите, как это сделать, в следующем разделе. Мы покажем вам, как создать базу данных на вашем сервере MySQL в главе 4.
Использование модели отношений сущностей
В этом разделе рассматриваются шаги, необходимые для создания модели электронной отчетности и ее развертывания в таблицах базы данных. Ранее мы видели, что MySQL Workbench позволяет нам реконструировать существующую базу данных. Но как смоделировать новую базу данных и развернуть ее? Мы можем автоматизировать этот процесс с помощью инструмента MySQL Workbench.
Сопоставление сущностей и отношений с таблицами базы данных
При преобразовании модели ER в схему базы данных мы работаем с каждой сущностью, а затем с каждым отношением в соответствии с правилами, обсуждаемыми в следующих разделах, чтобы в итоге получить набор таблиц базы данных.
Сопоставление сущностей с таблицами базы данных
Для каждой сильной сущности создайте таблицу, содержащую ее атрибуты, и назначьте первичный ключ. Сюда же включаются части любых составных атрибутов.
Для каждой слабоой сущности создайте таблицу, содержащую ее атрибуты и первичный ключ объекта-владельца. Первичный ключ объекта-владельца здесь является внешним ключом, потому что это ключ не этой таблицы, а другой таблицы. Первичный ключ таблицы для слабого объекта представляет собой комбинацию внешнего ключа и частичного ключа слабого объекта. Если связь с сущностью-владельцем имеет какие-либо атрибуты, добавьте их в эту таблицу.
Для многозначного атрибута каждой сущности создайте таблицу, содержащую первичный ключ сущности и атрибут.
Сопоставление отношений с таблицами базы данных
Каждое отношение «один к одному» между двумя объектами включает первичный ключ одного объекта в качестве внешнего ключа в таблице, принадлежащей другому объекту. Если один объект полностью участвует в отношениях, поместите внешний ключ в его таблицу. Если оба полностью участвуют в отношениях, рассмотрите возможность их объединения в одну таблицу.
Для каждого неидентифицирующего отношения «один ко многим» между двумя объектами включите первичный ключ объекта на стороне «1» в качестве внешнего ключа в таблицу для объекта на стороне «N». Добавьте любые атрибуты отношения в таблицу вместе с внешним ключом. Обратите внимание, что идентификация отношений «один ко многим» (между слабой сущностью и сущностью-владельцем) фиксируется как часть этапа сопоставления сущностей.
Для каждой связи «многие ко многим» между двумя сущностями создайте новую таблицу, содержащую первичный ключ каждой сущности в качестве первичного ключа, и добавьте любые атрибуты связи. Этот шаг помогает идентифицировать промежуточные объекты.
Для каждой связи, включающей более двух сущностей, создайте таблицу с первичными ключами всех участвующих сущностей и добавьте любые атрибуты связи.
Создание модели ER базы данных банка
Мы обсудили модели баз данных для оценок учащихся и информации о клиентах, а также три EER с открытым исходным кодом, доступные для MySQL. Теперь давайте посмотрим, как мы можем смоделировать базу данных банка. Мы собрали все реквизиты от заинтересованных сторон и определили наши требования к системе онлайн-банкинга, и мы решили, что нам нужны следующие сущности:
Сотрудники
Филиалы
Клиенты
Счета
Теперь, следуя только что описанным правилам сопоставления, мы создадим таблицы и атрибуты для каждой таблицы. Мы установили первичные ключи, чтобы каждая таблица имела столбец с уникальным идентификатором для своих записей. Далее нам нужно определить отношения между таблицами.
Отношения «многие ко многим» (N:M)
Мы установили этот тип отношений между филиалами и сотрудниками, а также между счетами и клиентами. Сотрудник может работать в любом количестве филиалов, а в филиале может быть любое количество сотрудников. Точно так же у клиента может быть много учетных записей, и учетная запись может быть совместной учетной записью, принадлежащей более чем двум клиентам.
Для моделирования этих отношений нам понадобятся еще две промежуточные сущности. Создаем их следующим образом:
account_customers
branch_employees
Сущности account_customers и branch_employees будут связующим звеном между сущностями счета и клиента, а также сущностями филиала и сотрудника соответственно. Мы преобразуем отношение N:M в два отношения 1:N. Вы увидите, как выглядит дизайн в следующем разделе.
Связь один ко многим (1:N)
Этот тип отношений существует между филиалами и счетами, а также между клиентами и account_customers. Это поднимает концепцию неотождествляющих отношений (nonidentifying relationship). Например, в таблице account поле branch_id не является частью первичного ключа (одна из причин этого заключается в том, что вы можете перенести свой банковский счет в другой филиал). В настоящее время принято сохранять суррогатный ключ в качестве первичного ключа в каждой таблице; поэтому подлинная идентифицирующая связь, в которой внешний ключ также является частью первичного ключа в модели данных, встречается редко.
Поскольку мы создаем физическую модель EER, мы также собираемся определить первичные ключи. Обычно и рекомендуется использовать автоматически увеличивающиеся беззнаковые поля для первичного ключа.
На рис. 2-17 показано окончательное представление модели банка.

Рисунок 2-17. Модель EER для банковской базы данных
Обратите внимание, что есть элементы, которые мы не рассмотрели для этой модели. Например, наша модель не поддерживает клиента с несколькими адресами (скажем, рабочим адресом и домашним адресом). Мы сделали это намеренно, чтобы подчеркнуть важность сбора необходимых данных перед развертыванием базы данных.
Вы можете скачать модель из репозитория книги на GitHub. Файл называется bank_model.mwb.
Преобразование EER в базу данных MySQL с помощью Workbench
Рекомендуется использовать инструмент для рисования диаграмм ER; таким образом, вы можете легко редактировать и переопределять их, пока окончательные диаграммы не станут четкими и однозначными. Как только вы освоитесь с моделью, вы можете развернуть ее. MySQL Workbench позволяет преобразовывать модель EER в операторы языка определения данных (DDL) для создания базы данных MySQL с помощью параметра Forward Engineer в меню базы данных (рис. 2-18).

Рисунок 2-18. Форвард-инжиниринг базы данных в MySQL Workbench
Вам нужно будет ввести учетные данные для подключения к базе данных, после чего MySQL Workbench предложит некоторые параметры. Для этой модели мы собираемся использовать стандартные параметры, как показано на рис. 2-19, со снятыми флажками всех параметров, кроме последнего.

Рисунок 2-19. Варианты создания базы данных
На следующем экране будет задан вопрос, какие элементы модели мы хотим сгенерировать. Поскольку у нас нет ничего особенного вроде триггеров, хранимых процедур, пользователей и т. д., мы будем создавать только объекты таблицы и их отношения; остальные опции не отмечены.
Затем MySQL Workbench предоставит нам сценарий SQL, который будет выполняться для создания базы данных из нашей модели, как показано на рисунке 2-20.

Рисунок 2-20. Скрипт, созданный для создания базы данных
Когда мы нажмем Continue, MySQL Workbench выполнит операторы на нашем сервере MySQL, как показано на рисунке 2-21.

Рисунок 2-21. MySQL Workbench запускает скрипт
Мы рассмотрим детали операторов в этом скрипте в разделе «Создание таблиц».
Глава 3
Базовый SQL
Как упоминалось в главе 2, д-р Эдгар Ф. Кодд разработал модель реляционной базы данных и ее нормальные формы в начале 1970-х годов. В 1974 году исследователи из лаборатории IBM в Сан-Хосе начали работу над крупным проектом, призванным доказать жизнеспособность реляционной модели, под названием System R. В то же время доктор Дональд Чемберлин и его коллеги также работали над определением языка базы данных. Они разработали структурированный английский язык запросов (SEQUEL), который позволял пользователям запрашивать реляционную базу данных, используя четко определенные предложения в английском стиле. Позже он был переименован в язык структурированных запросов (SQL) по юридическим причинам.
Первые системы управления базами данных, основанные на SQL, стали коммерчески доступными к концу 70-х годов. С ростом активности, связанной с разработкой языков баз данных, появилась стандартизация для упрощения, и сообщество остановилось на SQL. В процессе стандартизации принимали участие как американские, так и международные организации по стандартизации (ANSI и ISO), и в 1986 году был утвержден первый стандарт SQL. Позже стандарт несколько раз пересматривался, а названия (SQL:1999, SQL:2003, SQL:2008 и т. д.) указывали на версии, выпущенные в соответствующие годы. Мы будем использовать фразу стандарт SQL или стандартный SQL для обозначения текущей версии стандарта SQL в любое время.
MySQL расширяет стандартный SQL, предоставляя дополнительные возможности. Например, MySQL реализует STRAIGHT_JOIN, синтаксис которого не распознается другими СУБД.
В этой главе представлена реализация SQL в MySQL, которую мы часто называем операциями CRUD: create, read, update и delete. Мы покажем вам, как читать данные из базы данных с помощью оператора SELECT и выбирать, какие данные извлекать и в каком порядке они отображаются. Мы также покажем вам основы изменения ваших баз данных с помощью инструкции INSERT для добавления данных, UPDATE для изменения данных и DELETE для удаления данных. Наконец, мы объясним, как использовать нестандартные операторы SHOW TABLES и SHOW COLUMNS для изучения вашей базы данных.
Использование базы данных sakila
В главе 2 мы показали вам принципы построения диаграммы базы данных с использованием модели ER. Мы также представили шаги, которые необходимо предпринять для преобразования модели ER в формат, подходящий для построения реляционной базы данных. В этом разделе будет показана структура базы данных MySQL sakila, чтобы вы могли начать знакомиться с различными реляционными моделями баз данных. Мы не будем здесь объяснять операторы SQL, используемые для создания базы данных; это тема главы 4.
Если вы еще не импортировали базу данных, выполните шаги, описанные в разделе «Примеры моделирования отношений сущностей», чтобы выполнить задачу.
Чтобы выбрать базу данных sakila в качестве нашей текущей базы данных, мы будем использовать оператор USE. Введите следующую команду:
mysql> USE sakila;
Database changed
mysql>
Вы можете проверить, какая база данных является активной, набрав команду SELECT DATABASE();:
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| sakila |
+------------+
1 row in set (0.00 sec)
Теперь давайте рассмотрим, какие таблицы составляют базу данных sakila, используя оператор SHOW TABLES:
mysql> SHOW TABLES;
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
| actor_info |
| ... |
| customer |
| customer_list |
| film |
| film_actor |
| film_category |
| film_list |
| film_text |
| inventory |
| language |
| nicer_but_slower_film_list |
| payment |
| rental |
| sales_by_film_category |
| sales_by_store |
| staff |
| staff_list |
| store |
+----------------------------+
23 rows in set (0.00 sec)
Пока никаких сюрпризов не было. Давайте узнаем больше о каждой из таблиц, составляющих базу данных sakila. Во-первых, давайте воспользуемся оператором SHOW COLUMNS для просмотра таблицы actor (обратите внимание, что выходные данные были свернуты, чтобы соответствовать полям страницы):
mysql> SHOW COLUMNS FROM actor;
+-------------+-------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------+-------------------+------+-----+-------------------+...
| actor_id | smallint unsigned | NO | PRI | NULL |...
| first_name | varchar(45) | NO | | NULL |...
| last_name | varchar(45) | NO | MUL | NULL |...
| last_update | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------+-------------------+------+-----+-------------------+...
...+-----------------------------------------------+
...| Extra |
...+-----------------------------------------------+
...| auto_increment |
...| |
...| |
...| DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-----------------------------------------------+
4 rows in set (0.01 sec)
Ключевое слово DESCRIBE идентично SHOW COLUMNS FROM, и мы можем сократить его до просто DESC, поэтому мы можем написать предыдущий запрос следующим образом:
mysql> DESC actor;Полученный результат идентичен. Рассмотрим структуру таблицы более подробно. Таблица actor содержит четыре столбца: actor_id, first_name, last_name и last_update. Мы также можем извлечь типы столбцов: smallint для actor_id, varchar(45) для first_name и last_name и отметку времени для last_update. Ни один из столбцов не принимает значение NULL (пустое), actor_id — это первичный ключ (PRI), а last_name — это первый столбец неуникального индекса (MUL). Не беспокойтесь о деталях; все, что сейчас важно, — это имена столбцов, которые мы будем использовать для команд SQL.
Далее давайте изучим таблицу city, выполнив оператор DESC:
mysql> DESC city;
+-------------+-------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------+-------------------+------+-----+-------------------+...
| city_id | smallint unsigned | NO | PRI | NULL |...
| city | varchar(50) | NO | | NULL |...
| country_id | smallint unsigned | NO | MUL | NULL |...
| last_update | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------+-------------------+------+-----+-------------------+...
...+-----------------------------------------------+
...| Extra |
...+-----------------------------------------------+
...| auto_increment |
...| |
...| |
...| DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-----------------------------------------------+
4 rows in set (0.01 sec)
Опять же, важно ознакомиться со столбцами в каждой таблице, так как мы будем часто использовать их позже, когда будем обсуждать запросы.
В следующем разделе показано, как исследовать данные, которые MySQL хранит в базе данных sakila и ее таблицах.
Оператор SELECT и основные методы запросов
В предыдущих главах было показано, как установить и настроить MySQL и использовать командную строку MySQL, а также была представлена модель ER. Теперь вы готовы приступить к изучению языка SQL, который используют все клиенты MySQL для изучения данных и управления ими. В этом разделе представлено наиболее часто используемое ключевое слово SQL: SELECT. Мы объясняем основные элементы стиля и синтаксиса, а также особенности предложения WHERE, логических операторов и сортировки (многое из этого также относится к нашим более поздним обсуждениям INSERT, UPDATE и DELETE). Это не конец нашего обсуждения SELECT; вы найдете больше в главе 5, где мы покажем вам, как использовать его расширенные функции.
Однотабличные SELECT
Самая простая форма SELECT считывает данные во всех строках и столбцах таблицы. Подключитесь к MySQL с помощью командной строки и выберите базу данных sakila:
mysql> USE sakila;
Database changed
Давайте получим все данные в таблице language:
mysql> SELECT * FROM language;
+-------------+----------+---------------------+
| language_id | name | last_update |
+-------------+----------+---------------------+
| 1 | English | 2006-02-15 05:02:19 |
| 2 | Italian | 2006-02-15 05:02:19 |
| 3 | Japanese | 2006-02-15 05:02:19 |
| 4 | Mandarin | 2006-02-15 05:02:19 |
| 5 | French | 2006-02-15 05:02:19 |
| 6 | German | 2006-02-15 05:02:19 |
+-------------+----------+---------------------+
6 rows in set (0.00 sec)
Вывод состоит из шести строк, и каждая строка содержит значения для всех столбцов, присутствующих в таблице. Теперь мы знаем, что существует шесть языков, и мы можем видеть языки, их идентификаторы и время последнего обновления каждого языка.
Простой оператор SELECT состоит из четырех компонентов:
-
Ключевое слово
SELECT. -
Столбцы для отображения. Символ звездочки (
*) — это подстановочный знак, обозначающий все столбцы. -
Ключевое слово
FROM. -
Имя таблицы.
Итак, в этом примере мы запросили все столбцы из таблицы language, и это то, что нам вернул MySQL.
Давайте попробуем еще один простой SELECT. На этот раз мы получим все столбцы из таблицы city:
mysql> SELECT * FROM city;
+---------+------------------------+------------+---------------------+
| city_id | city | country_id | last_update |
+---------+------------------------+------------+---------------------+
| 1 | A Corua (La Corua) | 87 | 2006-02-15 04:45:25 |
| 2 | Abha | 82 | 2006-02-15 04:45:25 |
| 3 | Abu Dhabi | 101 | 2006-02-15 04:45:25 |
| ... |
| 599 | Zhoushan | 23 | 2006-02-15 04:45:25 |
| 600 | Ziguinchor | 83 | 2006-02-15 04:45:25 |
+---------+------------------------+------------+---------------------+
600 rows in set (0.00 sec)
Имеется 600 городов, и выходные данные имеют ту же базовую структуру, что и в нашем первом примере.
Этот пример дает некоторое представление о том, как работают отношения между таблицами. Рассмотрим первую строку результатов. В столбце country_id вы увидите значение 87. Как вы увидите позже, мы можем проверить таблицу country, чтобы узнать, что страна с кодом 87 — это Испания. Мы обсудим, как писать запросы об отношениях между таблицами, в разделе «Объединение двух таблиц».
Если вы посмотрите на полный вывод, вы также увидите, что есть несколько разных городов с одним и тем же идентификатором country_id. Наличие повторяющихся значений country_id не является проблемой, поскольку мы ожидаем, что в стране будет много городов (отношение «один ко многим»).
Теперь вы должны чувствовать себя комфортно, выбирая базу данных, перечисляя ее таблицы и извлекая все данные из таблицы с помощью оператора SELECT. Для практики вы можете поэкспериментировать с другими таблицами в базе данных sakila. Помните, что вы можете использовать оператор SHOW TABLES, чтобы узнать имена таблиц.
Выбор столбцов
Ранее мы использовали подстановочный знак * для получения всех столбцов в таблице. Если вы не хотите отображать все столбцы, можно уточнить, перечислив нужные столбцы в том порядке, в котором вы хотите их разделить запятыми. Например, если вам нужен только столбец city из таблицы city, введите:
mysql> SELECT city FROM city;
+--------------------+
| city |
+--------------------+
| A Corua (La Corua) |
| Abha |
| Abu Dhabi |
| Acua |
| Adana |
+--------------------+
5 rows in set (0.00 sec)
Если вам нужны столбцы city и city_id в таком порядке, вы должны использовать:
mysql> SELECT city, city_id FROM city;
+--------------------+---------+
| city | city_id |
+--------------------+---------+
| A Corua (La Corua) | 1 |
| Abha | 2 |
| Abu Dhabi | 3 |
| Acua | 4 |
| Adana | 5 |
+--------------------+---------+
5 rows in set (0.01 sec)
Вы даже можете перечислить столбцы более одного раза:
mysql> SELECT city, city FROM city;
+--------------------+--------------------+
| city | city |
+--------------------+--------------------+
| A Corua (La Corua) | A Corua (La Corua) |
| Abha | Abha |
| Abu Dhabi | Abu Dhabi |
| Acua | Acua |
| Adana | Adana |
+--------------------+--------------------+
5 rows in set (0.00 sec)
Хотя это может показаться бессмысленным, это может быть полезно в сочетании с псевдонимами в более сложных запросах, как вы увидите в главе 5.
Вы можете указать имена базы данных, таблицы и столбца в операторе SELECT. Это позволяет вам избежать команды USE и работать с любой базой данных и таблицей напрямую с помощью SELECT; это также помогает устранять неоднозначности, как мы покажем в разделе «Объединение двух таблиц». Например, предположим, что вы хотите получить столбец name из таблицы language в базе данных sakila. Вы можете сделать это с помощью следующей команды:
mysql> SELECT name FROM sakila.language;
+----------+
| name |
+----------+
| English |
| Italian |
| Japanese |
| Mandarin |
| French |
| German |
+----------+
6 rows in set (0.01 sec)
Компонент sakila.language после ключевого слова FROM указывает базу данных sakila и ее таблицу language. Нет необходимости вводить USE sakila; перед выполнением этого запроса. Этот синтаксис также можно использовать с другими операторами SQL, включая операторы UPDATE, DELETE, INSERT и SHOW, которые мы обсудим позже в этой главе.
Выбор строк с помощью предложения WHERE
В этом разделе представлено предложение WHERE и объясняется, как использовать операторы для написания выражений. Вы увидите их в инструкциях SELECT и других инструкциях, таких как UPDATE и DELETE; мы покажем вам примеры позже в этой главе.
Основы WHERE
Предложение WHERE — это мощный инструмент, позволяющий фильтровать, какие строки возвращаются оператором SELECT. Вы используете его, чтобы возвращать строки, соответствующие условию, например, имеющие значение столбца, которое точно соответствует строке, число, большее или меньшее значения, или строку, которая является префиксом другой строки. Почти все наши примеры в этой и последующих главах содержат предложения WHERE, и вы хорошо с ними познакомитесь.
Простейшее предложение WHERE — это предложение, которое точно соответствует значению. Рассмотрим пример, когда вы хотите узнать детали английского языка в таблице language. Вот что вы должны ввести:
mysql> SELECT * FROM sakila.language WHERE name = 'English';
+-------------+---------+---------------------+
| language_id | name | last_update |
+-------------+---------+---------------------+
| 1 | English | 2006-02-15 05:02:19 |
+-------------+---------+---------------------+
1 row in set (0.00 sec)
MySQL возвращает все строки, соответствующие вашим критериям поиска — в данном случае только одну строку и все ее столбцы.
Давайте попробуем другой пример точного соответствия. Предположим, вы хотите узнать имя актера со значением actor_id, равным 4, в таблице actor. Вы должны ввести:
mysql> SELECT first_name FROM actor WHERE actor_id = 4;
+------------+
| first_name |
+------------+
| JENNIFER |
+------------+
1 row in set (0.00 sec)
Здесь вы указываете столбец и строку, включая столбец first_name после ключевого слова SELECT и указывая WHERE actor_id = 4.
Если значение соответствует более чем одной строке, результаты будут содержать все совпадения. Предположим, вы хотите просмотреть все города, принадлежащие Бразилии, для которой значение country_id равно 15. Введите:
mysql> SELECT city FROM city WHERE country_id = 15;
+----------------------+
| city |
+----------------------+
| Alvorada |
| Angra dos Reis |
| Anpolis |
| Aparecida de Goinia |
| Araatuba |
| Bag |
| Belm |
| Blumenau |
| Boa Vista |
| Braslia |
| ... |
+----------------------+
28 rows in set (0.00 sec)
Результаты показывают названия 28 городов, принадлежащих Бразилии. Если бы мы могли объединить информацию, которую мы получаем из таблицы city, с информацией, которую мы получаем из таблицы country, мы могли бы отображать названия городов с их соответствующими странами. Мы увидим, как выполнить этот тип запроса, в разделе «Объединение двух таблиц».
Теперь давайте извлечем значения, принадлежащие диапазону. Получение нескольких значений просто для числовых диапазонов, поэтому давайте начнем с поиска названий всех городов с идентификатором city_id меньше 5. Для этого выполните следующую инструкцию:
mysql> SELECT city FROM city WHERE city_id < 5;
+--------------------+
| city |
+--------------------+
| A Corua (La Corua) |
| Abha |
| Abu Dhabi |
| Acua |
+--------------------+
4 rows in set (0.00 sec)
Для чисел часто используются следующие операторы: «равно» (=), «больше» (>), «меньше» (<), «меньше или равно» (<=), «больше или равно» (>=) и «не равно» (<> или !=).
Рассмотрим еще один пример. Если вы хотите найти все языки, для которых language_id не равен 2, введите:
mysql> SELECT language_id, name FROM sakila.language
-> WHERE language_id <> 2;
+-------------+----------+
| language_id | name |
+-------------+----------+
| 1 | English |
| 3 | Japanese |
| 4 | Mandarin |
| 5 | French |
| 6 | German |
+-------------+----------+
5 rows in set (0.00 sec)
Предыдущие выходные данные показывают первый, третий и все последующие языки в таблице. Обратите внимание, что вы можете использовать оператор <> или != для условия не равно.
Вы можете использовать те же операторы для строк. По умолчанию сравнения строк не чувствительны к регистру и используют текущий набор символов. Например:
mysql> SELECT first_name FROM actor WHERE first_name < 'B';
+------------+
| first_name |
+------------+
| ALEC |
| AUDREY |
| ANNE |
| ANGELA |
| ADAM |
| ANGELINA |
| ALBERT |
| ADAM |
| ANGELA |
| ALBERT |
| AL |
| ALAN |
| AUDREY |
+------------+
13 rows in set (0.00 sec)
Под «без учета регистра» мы подразумеваем, что B и b будут считаться одним и тем же фильтром, поэтому этот запрос даст тот же результат:
mysql> SELECT first_name FROM actor WHERE first_name < 'b';
+------------+
| first_name |
+------------+
| ALEC |
| AUDREY |
| ANNE |
| ANGELA |
| ADAM |
| ANGELINA |
| ALBERT |
| ADAM |
| ANGELA |
| ALBERT |
| AL |
| ALAN |
| AUDREY |
+------------+
13 rows in set (0.00 sec)
Другая распространенная задача, выполняемая со строками, — поиск совпадений, начинающихся с префикса, содержащих строку или заканчивающихся суффиксом. Например, нам может понадобиться найти все названия альбомов, начинающиеся со слова «Retro». Мы можем сделать это с помощью оператора LIKE в предложении WHERE. Давайте рассмотрим пример, в котором мы ищем фильм с названием, содержащим слово «family»:
mysql> SELECT title FROM film WHERE title LIKE '%family%';
+----------------+
| title |
+----------------+
| CYCLONE FAMILY |
| DOGMA FAMILY |
| FAMILY SWEET |
+----------------+
3 rows in set (0.00 sec)
Давайте посмотрим, как это работает. Предложение LIKE используется со строками и означает, что совпадение должно соответствовать шаблону в следующей строке. В нашем примере мы использовали LIKE '%family%', что означает, что строка должна содержать family, и ей может предшествовать или следовать ноль или более символов. Большинство строк, используемых с LIKE, содержат символ процента (%) в качестве подстановочного знака, который соответствует всем возможным строкам. Вы можете использовать его для определения строки, которая заканчивается суффиксом, например "%ing", или строки, которая начинается с определенной подстроки, например "Corruption%".
Например, "John%" будет соответствовать всем строкам, начинающимся с John, таким как John Smith и John Paul Getty. Шаблон "%Paul" соответствует всем строкам, в конце которых есть Paul. Наконец, шаблон "%Paul%" соответствует всем строкам, в которых есть Paul, в том числе в начале или в конце.
Если вы хотите, чтобы в предложении LIKE соответствовал только один подстановочный знак, вы используете символ подчеркивания (_). Например, если вы хотите получить названия всех фильмов с участием актера, чье имя начинается с трех букв NAT, вы используете:
mysql> SELECT title FROM film_list WHERE actors LIKE 'NAT_%';
+----------------------+
| title |
+----------------------+
| FANTASY TROOPERS |
| FOOL MOCKINGBIRD |
| HOLES BRANNIGAN |
| KWAI HOMEWARD |
| LICENSE WEEKEND |
| NETWORK PEAK |
| NUTS TIES |
| TWISTED PIRATES |
| UNFORGIVEN ZOOLANDER |
+----------------------+
9 rows in set (0.04 sec)
Сочетание условий с AND, OR, NOT и XOR
До сих пор мы использовали предложение WHERE для проверки одного условия, возвращая все строки, которые ему соответствуют. Вы можете комбинировать два или более условий, используя логические операторы AND, OR, NOT и XOR.
Начнем с примера. Предположим, вы хотите найти названия научно-фантастических фильмов с рейтингом PG. Это легко сделать с помощью оператора AND:
mysql> SELECT title FROM film_list WHERE category LIKE 'Sci-Fi'
-> AND rating LIKE 'PG';
+----------------------+
| title |
+----------------------+
| CHAINSAW UPTOWN |
| CHARADE DUFFEL |
| FRISCO FORREST |
| GOODFELLAS SALUTE |
| GRAFFITI LOVE |
| MOURNING PURPLE |
| OPEN AFRICAN |
| SILVERADO GOLDFINGER |
| TITANS JERK |
| TROJAN TOMORROW |
| UNFORGIVEN ZOOLANDER |
| WONDERLAND CHRISTMAS |
+----------------------+
12 rows in set (0.07 sec)
Операция AND в предложении WHERE ограничивает результаты теми строками, которые удовлетворяют обоим условиям.
Оператор OR используется для поиска строк, удовлетворяющих хотя бы одному из нескольких условий. Для иллюстрации представьте, что вам нужен список фильмов в категориях Children или Family. Вы можете сделать это с помощью OR и двух предложений LIKE:
mysql> SELECT title FROM film_list WHERE category LIKE 'Children'
-> OR category LIKE 'Family';
+------------------------+
| title |
+------------------------+
| AFRICAN EGG |
| APACHE DIVINE |
| ATLANTIS CAUSE |
...
| WRONG BEHAVIOR |
| ZOOLANDER FICTION |
+------------------------+
129 rows in set (0.04 sec)
Операция OR в предложении WHERE ограничивает ответы теми, которые удовлетворяют любому из двух условий. Кроме того, мы можем заметить, что результаты упорядочены. Это просто совпадение; в этом случае о них сообщается в том порядке, в котором они были добавлены в базу данных. Мы вернемся к сортировке вывода в разделе «Предложение ORDER BY».
Вы можете комбинировать AND и OR, но вам нужно четко указать очередность выполнения этих условий. Скобки объединяют части оператора вместе и помогают сделать выражения читабельными; вы можете использовать их так же, как и в базовой математике. Допустим, теперь вам нужны sci-fi или family фильмы с рейтингом PG. Вы можете написать этот запрос следующим образом:
mysql> SELECT title FROM film_list WHERE (category like 'Sci-Fi'
-> OR category LIKE 'Family') AND rating LIKE 'PG';
+------------------------+
| title |
+------------------------+
| BEDAZZLED MARRIED |
| CHAINSAW UPTOWN |
| CHARADE DUFFEL |
| CHASING FIGHT |
| EFFECT GLADIATOR |
...
| UNFORGIVEN ZOOLANDER |
| WONDERLAND CHRISTMAS |
+------------------------+
30 rows in set (0.07 sec)
Скобки поясняют порядок оценки: вам нужны фильмы либо из научной фантастики, либо из семейной категории, но все они должны иметь рейтинг PG.
С помощью круглых скобок можно изменить порядок оценки. Самый простой способ увидеть, как это работает, — поиграть с вычислениями:
mysql> SELECT (2+2)*3;
+---------+
| (2+2)*3 |
+---------+
| 12 |
+---------+
1 row in set (0.00 sec)mysql> SELECT 2+2*3;
+-------+
| 2+2*3 |
+-------+
| 8 |
+-------+
1 row in set (0.00 sec)
Унарный оператор NOT инвертирует логический оператор. Ранее мы приводили пример перечисления всех языков с language_id, не равным 2. Вы также можете написать этот запрос с оператором NOT:
mysql> SELECT language_id, name FROM sakila.language
-> WHERE NOT (language_id = 2);
+-------------+----------+
| language_id | name |
+-------------+----------+
| 1 | English |
| 3 | Japanese |
| 4 | Mandarin |
| 5 | French |
| 6 | German |
+-------------+----------+
5 rows in set (0.01 sec)
Выражение в круглых скобках (language_id = 2) задает соответствие условию, а операция NOT отменяет его, поэтому вы получаете все, кроме тех результатов, которые соответствуют условию. Есть несколько других способов написать предложение WHERE с той же идеей. В главе 5 вы увидите, что некоторые из них работают лучше, чем другие.
Рассмотрим другой пример с использованием NOT и круглых скобок. Предположим, вы хотите получить список всех названий фильмов с FID меньше 7, но не с номерами 4 или 6. Это можно сделать с помощью следующего запроса:
mysql> SELECT fid,title FROM film_list WHERE FID < 7 AND NOT (FID = 4 OR FID = 6);
+------+------------------+
| fid | title |
+------+------------------+
| 1 | ACADEMY DINOSAUR |
| 2 | ACE GOLDFINGER |
| 3 | ADAPTATION HOLES |
| 5 | AFRICAN EGG |
+------+------------------+
4 rows in set (0.06 sec)
Понимание приоритета оператора может быть немного сложным, и иногда администраторам баз данных требуется много времени, чтобы отладить запрос и определить, почему он не возвращает запрошенные значения. В следующем списке показаны доступные операторы в порядке от самого высокого приоритета к самому низкому. Операторы, показанные вместе в строке, имеют одинаковый приоритет:
INTERVALBINARY,COLLATE!-(унарный минус),~(унарный бит инверсии)^*,/,DIV,%,MOD-,+<<,>>&\|=(сравнение),<=>,>=,>,<=,<,<>,!=,IS,LIKE,REGEXP,IN,MEMBER OFBETWEEN,CASE,WHEN,THEN,ELSENOTAND,&&XOROR,\|\|=(присваивание),:=
Эти операторы можно комбинировать различными способами для получения желаемых результатов. Например, вы можете написать запрос для получения названий любых фильмов с ценой от 2 до 4 долларов, относящихся к категории Documentary или Horror и с актером по имени Bob:
mysql> SELECT title
-> FROM film_list
-> WHERE price BETWEEN 2 AND 4
-> AND (category LIKE 'Documentary' OR category LIKE 'Horror')
-> AND actors LIKE '%BOB%';
+------------------+
| title |
+------------------+
| ADAPTATION HOLES |
+------------------+
1 row in set (0.08 sec)
Наконец, прежде чем мы перейдем к сортировке, обратите внимание, что можно выполнять запросы, которые не соответствуют ни одному результату. В этом случае запрос вернет пустой набор:
mysql> SELECT title FROM film_list
-> WHERE price BETWEEN 2 AND 4
-> AND (category LIKE 'Documentary' OR category LIKE 'Horror')
-> AND actors LIKE '%GRIPPA%';
Empty set (0.04 sec)
Предложение ORDER BY
Мы обсудили, как выбирать столбцы и какие строки возвращаются как часть результата запроса, но не обсуждали, как управлять отображением результата. В реляционной базе данных строки таблицы образуют набор; между строками нет внутреннего порядка, поэтому мы должны попросить MySQL отсортировать результаты, если мы хотим, чтобы они были в определенном порядке. В этом разделе объясняется, как использовать для этого предложение ORDER BY. Сортировка не влияет на то, что возвращается; это влияет только на то, в каком порядке возвращаются результаты.
Предположим, вы хотите вернуть список первых 10 клиентов в базе данных sakila, отсортированных по name в алфавитном порядке. Вот что вы должны ввести:
mysql> SELECT name FROM customer_list
-> ORDER BY name
-> LIMIT 10;
+-------------------+
| name |
+-------------------+
| AARON SELBY |
| ADAM GOOCH |
| ADRIAN CLARY |
| AGNES BISHOP |
| ALAN KAHN |
| ALBERT CROUSE |
| ALBERTO HENNING |
| ALEX GRESHAM |
| ALEXANDER FENNELL |
| ALFRED CASILLAS |
+-------------------+
10 rows in set (0.01 sec)
Предложение ORDER BY указывает, что требуется сортировка, за которой следует столбец, который следует использовать в качестве ключа сортировки. В этом примере вы сортируете по имени в алфавитном порядке по возрастанию — по умолчанию сортировка выполняется без учета регистра и в порядке возрастания, а MySQL автоматически сортирует в алфавитном порядке, поскольку столбцы представляют собой строки символов. Способ сортировки строк определяется используемым набором символов и порядком сортировки. Мы обсуждаем их в разделе «Сопоставление и наборы символов». В большей части этой книги мы предполагаем, что вы используете настройки по умолчанию.
Давайте посмотрим на другой пример. На этот раз вы отсортируете вывод из таблицы адресов в порядке возрастания на основе столбца last_update и отобразите только первые пять результатов:
mysql> SELECT address, last_update FROM address
-> ORDER BY last_update LIMIT 5;
+-----------------------------+---------------------+
| address | last_update |
+-----------------------------+---------------------+
| 1168 Najafabad Parkway | 2014-09-25 22:29:59 |
| 1031 Daugavpils Parkway | 2014-09-25 22:29:59 |
| 1924 Shimonoseki Drive | 2014-09-25 22:29:59 |
| 757 Rustenburg Avenue | 2014-09-25 22:30:01 |
| 1892 Nabereznyje Telny Lane | 2014-09-25 22:30:02 |
+-----------------------------+---------------------+
5 rows in set (0.00 sec)
Как видите, можно сортировать разные типы столбцов. Кроме того, мы можем составить сортировку с двумя или более столбцами. Например, допустим, вы хотите отсортировать адреса по алфавиту, но сгруппировать по районам:
mysql> SELECT address, district FROM address
-> ORDER BY district, address;
+----------------------------------------+----------------------+
| address | district |
+----------------------------------------+----------------------+
| 1368 Maracabo Boulevard | |
| 18 Duisburg Boulevard | |
| 962 Tama Loop | |
| 535 Ahmadnagar Manor | Abu Dhabi |
| 669 Firozabad Loop | Abu Dhabi |
| 1078 Stara Zagora Drive | Aceh |
| 663 Baha Blanca Parkway | Adana |
| 842 Salzburg Lane | Adana |
| 614 Pak Kret Street | Addis Abeba |
| 751 Lima Loop | Aden |
| 1157 Nyeri Loop | Adygea |
| 387 Mwene-Ditu Drive | Ahal |
| 775 ostka Drive | al-Daqahliya |
| ... |
| 1416 San Juan Bautista Tuxtepec Avenue | Zufar |
| 138 Caracas Boulevard | Zulia |
+----------------------------------------+----------------------+
603 rows in set (0.00 sec)
Вы также можете сортировать в порядке убывания и управлять этим поведением для каждого ключа сортировки. Предположим, вы хотите отсортировать адреса в алфавитном порядке по убыванию, а районы — по возрастанию. Вы бы напечатали это:
mysql> SELECT address,district FROM address
-> ORDER BY district ASC, address DESC
-> LIMIT 10;
+-------------------------+-------------+
| address | district |
+-------------------------+-------------+
| 962 Tama Loop | |
| 18 Duisburg Boulevard | |
| 1368 Maracabo Boulevard | |
| 669 Firozabad Loop | Abu Dhabi |
| 535 Ahmadnagar Manor | Abu Dhabi |
| 1078 Stara Zagora Drive | Aceh |
| 842 Salzburg Lane | Adana |
| 663 Baha Blanca Parkway | Adana |
| 614 Pak Kret Street | Addis Abeba |
| 751 Lima Loop | Aden |
+-------------------------+-------------+
10 rows in set (0.01 sec)
Если происходит конфликт значений и вы не указываете другой ключ сортировки, порядок сортировки не определен. Это может быть не важно для вас; вас может не волновать порядок появления двух клиентов с одинаковым именем «Джон А. Смит». Если вы хотите применить определенный порядок в этом случае, вам нужно добавить дополнительные столбцы в предложение ORDER BY, как показано в предыдущем примере.
Предложение LIMIT
Как вы могли заметить, несколько предыдущих запросов использовали предложение LIMIT. Это полезная нестандартная инструкция SQL, позволяющая контролировать количество выводимых строк. Его базовая форма позволяет вам ограничить количество строк, возвращаемых оператором SELECT, что полезно, когда вы хотите ограничить объем данных, передаваемых по сети или выводимых на экран. Вы можете использовать его, например, для получения выборки данных из таблицы, как показано здесь:
mysql> SELECT name FROM customer_list LIMIT 10;
+------------------+
| name |
+------------------+
| VERA MCCOY |
| MARIO CHEATHAM |
| JUDY GRAY |
| JUNE CARROLL |
| ANTHONY SCHWAB |
| CLAUDE HERZOG |
| MARTIN BALES |
| BOBBY BOUDREAU |
| WILLIE MARKHAM |
| JORDAN ARCHULETA |
+------------------+
Предложение LIMIT может иметь два аргумента. В этом случае первый аргумент указывает первую возвращаемую строку, а второй указывает максимальное количество возвращаемых строк. Первый аргумент известен как смещение (offset). Предположим, вам нужно пять строк, но вы хотите пропустить первые пять строк, что означает, что результат начнется с шестой строки. Смещения записи для LIMIT начинаются с 0, поэтому вы можете сделать это следующим образом:
mysql> SELECT name FROM customer_list LIMIT 5, 5;
+------------------+
| name |
+------------------+
| CLAUDE HERZOG |
| MARTIN BALES |
| BOBBY BOUDREAU |
| WILLIE MARKHAM |
| JORDAN ARCHULETA |
+------------------+
5 rows in set (0.00 sec)
Результатом являются строки с 6 по 10 из запроса SELECT.
Существует альтернативный синтаксис, который вы можете увидеть для ключевого слова LIMIT: вместо LIMIT 10, 5 вы можете написать LIMIT 10 OFFSET 5. Синтаксис OFFSET отбрасывает указанные в нем N значений.
Вот пример без смещения:
mysql> SELECT id, name FROM customer_list
-> ORDER BY id LIMIT 10;
+----+------------------+
| ID | name |
+----+------------------+
| 1 | MARY SMITH |
| 2 | PATRICIA JOHNSON |
| 3 | LINDA WILLIAMS |
| 4 | BARBARA JONES |
| 5 | ELIZABETH BROWN |
| 6 | JENNIFER DAVIS |
| 7 | MARIA MILLER |
| 8 | SUSAN WILSON |
| 9 | MARGARET MOORE |
| 10 | DOROTHY TAYLOR |
+----+------------------+
10 rows in set (0.00 sec)
А вот результаты со смещением 5:
mysql> SELECT id, name FROM customer_list
-> ORDER BY id LIMIT 10 OFFSET 5;
+----+----------------+
| ID | name |
+----+----------------+
| 6 | JENNIFER DAVIS |
| 7 | MARIA MILLER |
| 8 | SUSAN WILSON |
| 9 | MARGARET MOORE |
| 10 | DOROTHY TAYLOR |
| 11 | LISA ANDERSON |
| 12 | NANCY THOMAS |
| 13 | KAREN JACKSON |
| 14 | BETTY WHITE |
| 15 | HELEN HARRIS |
+----+----------------+
10 rows in set (0.01 sec)
Объединение двух таблиц
До сих пор мы работали только с одной таблицей в наших запросах SELECT. Однако в большинстве случаев потребуется информация из более чем одной таблицы одновременно. Когда мы изучили таблицы в базе данных sakila, стало очевидно, что, используя отношения, мы можем отвечать на более интересные запросы. Например, было бы полезно знать страну, в которой находится каждый город. В этом разделе показано, как отвечать на такие запросы, объединяя две таблицы. Мы вернемся к этому вопросу в рамках более подробного обсуждения объединений в главе 5.
В этой главе мы используем только один синтаксис соединения. Есть еще два (LEFT и RIGHT JOIN), и каждый из них дает вам разные способы объединения данных из двух или более таблиц. Мы используем здесь синтаксис INNER JOIN, который чаще всего используется в повседневной деятельности. Давайте рассмотрим пример, а затем объясним подробнее, как это работает:
mysql> SELECT city, country FROM city INNER JOIN country
-> ON city.country_id = country.country_id
-> WHERE country.country_id < 5
-> ORDER BY country, city;
+----------+----------------+
| city | country |
+----------+----------------+
| Kabul | Afghanistan |
| Batna | Algeria |
| Bchar | Algeria |
| Skikda | Algeria |
| Tafuna | American Samoa |
| Benguela | Angola |
| Namibe | Angola |
+----------+----------------+
7 rows in set (0.00 sec)
Вывод показывает города в каждой стране со значением country_id меньше 5. Вы можете впервые увидеть, какие города находятся в каждой стране.
Как работает INNER JOIN? Оператор состоит из двух частей: во-первых, двух имен таблиц, разделенных ключевыми словами INNER JOIN; и, во-вторых, ключевого слова ON, указывающего необходимые столбцы для составления условия. В этом примере две таблицы, которые необходимо объединить, - это city и country, выраженные как city INNER JOIN country (для базового INNER JOIN не имеет значения, в каком порядке вы перечисляете таблицы, поэтому использование country INNER JOIN city будет иметь тот же эффект). В предложении ON (ON city.country_id = country.country_id) мы сообщаем MySQL столбцы, которые содержат отношения между таблицами; вы должны помнить об этом из нашего проекта и нашего предыдущего обсуждения в главе 2.
Если в условии соединения имена столбцов в обеих таблицах, используемых для сопоставления, одинаковы, вместо этого вы можете использовать предложение USING:
mysql> SELECT city, country FROM city
-> INNER JOIN country using (country_id)
-> WHERE country.country_id < 5
-> ORDER BY country, city;
+----------+----------------+
| city | country |
+----------+----------------+
| Kabul | Afghanistan |
| Batna | Algeria |
| Bchar | Algeria |
| Skikda | Algeria |
| Tafuna | American Samoa |
| Benguela | Angola |
| Namibe | Angola |
+----------+----------------+
7 rows in set (0.01 sec)
Диаграмма Венна на рис. 3-1 иллюстрирует внутреннее соединение.

Рисунок 3-1. Представление диаграммы Венна для INNER JOIN
Прежде чем мы покинем SELECT, мы познакомим вас с одной из функций, которые вы можете использовать для агрегирования значений. Предположим, вы хотите подсчитать, сколько городов Италии есть в нашей базе данных. Вы можете сделать это, объединив две таблицы и подсчитав количество строк с этим идентификатором страны. Вот как это работает:
mysql> SELECT COUNT(1) FROM city INNER JOIN country
-> ON city.country_id = country.country_id
-> WHERE country.country_id = 49
-> ORDER BY country, city;
+----------+
| count(1) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
Мы объясним дополнительные возможности SELECT и агрегатных функций в главе 5. Дополнительные сведения о функции COUNT() см. в разделе «Агрегатные функции».
Оператор INSERT
Оператор INSERT используется для добавления новых данных в таблицы. В этом разделе объясняется его основной синтаксис и рассматриваются несколько простых примеров добавления новых строк в базу данных sakila. В главе 4 мы обсудим, как загружать данные из существующих таблиц или внешних источников данных.
Основы INSERT
Вставка данных обычно происходит в двух случаях: при массовой загрузке в большом пакете при создании базы данных и при добавлении данных по мере необходимости при использовании базы данных. В MySQL в сервер встроены различные оптимизации для каждой ситуации. Важно отметить, что доступны различные синтаксисы SQL, облегчающие работу с сервером в обоих случаях. В этом разделе мы объясним основной синтаксис INSERT и покажем примеры его использования для массовой вставки и вставки одной записи.
Давайте начнем с основной задачи вставки одной новой строки в таблицу language. Для этого вам нужно понять структуру таблицы. Как мы объяснили в разделе «Использование базы данных sakila», вы можете узнать это с помощью оператора SHOW COLUMNS:
mysql> SHOW COLUMNS FROM language;
+-------------+-------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------+-------------------+------+-----+-------------------+...
| language_id | tinyint unsigned | NO | PRI | NULL |...
| name | char(20) | NO | | NULL |...
| last_update | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------+-------------------+------+-----+-------------------+...
...+-----------------------------------------------+
...| Extra |
...+-----------------------------------------------+
...| auto_increment |
...| |
...| DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-----------------------------------------------+
3 rows in set (0.00 sec)
Это говорит о том, что столбец language_id создается автоматически, а столбец last_update обновляется каждый раз, когда происходит операция UPDATE. Вы узнаете больше об атрибуте AUTO_INCREMENT, который автоматически назначает следующий доступный идентификатор, в главе 4.
Давайте добавим новую строку для португальского языка. Есть два способа сделать это. Чаще всего MySQL заполняет значение по умолчанию для language_id, например:
mysql> INSERT INTO language VALUES (NULL, 'Portuguese', NOW());
Query OK, 1 row affected (0.10 sec)
Если вы сейчас выполните SELECT для таблицы, мы увидим, что MySQL вставил строку:
mysql> SELECT * FROM language;
+-------------+------------+---------------------+
| language_id | name | last_update |
+-------------+------------+---------------------+
| 1 | English | 2006-02-15 05:02:19 |
| 2 | Italian | 2006-02-15 05:02:19 |
| 3 | Japanese | 2006-02-15 05:02:19 |
| 4 | Mandarin | 2006-02-15 05:02:19 |
| 5 | French | 2006-02-15 05:02:19 |
| 6 | German | 2006-02-15 05:02:19 |
| 7 | Portuguese | 2020-09-26 09:11:36 |
+-------------+------------+---------------------+
7 rows in set (0.00 sec)
Обратите внимание, что мы использовали функцию NOW() в столбце last_update. Функция NOW() возвращает текущую дату и время сервера MySQL.
Второй вариант — вставить значение столбца language_id вручную. Теперь, когда у нас уже есть семь языков, мы должны использовать 8 для следующего значения language_id. Мы можем проверить это с помощью этой инструкции SQL:
mysql> SELECT MAX(language_id) FROM language;
+------------------+
| max(language_id) |
+------------------+
| 7 |
+------------------+
1 row in set (0.00 sec)
Функция MAX() сообщает вам максимальное значение для столбца, переданного в качестве параметра. Это чище, чем использование SELECT language_id FROM language, который выводит все строки и требует, чтобы вы проверили их, чтобы найти максимальное значение. Добавление предложения ORDER BY и LIMIT делает это проще, но использование MAX() намного проще, чем SELECT language_id FROM language ORDER BY language_id DESC LIMIT 1, который возвращает тот же ответ.
Теперь мы готовы вставить строку. В этом INSERT мы также собираемся вставить значение last_update вручную. Вот нужная команда:
mysql> INSERT INTO language VALUES (8, 'Russian', '2020-09-26 10:35:00');
Query OK, 1 row affected (0.02 sec)
MySQL сообщает, что одна строка была затронута (в данном случае добавлена), что мы можем подтвердить, снова проверив содержимое таблицы:
mysql> SELECT * FROM language;
+-------------+------------+---------------------+
| language_id | name | last_update |
+-------------+------------+---------------------+
| 1 | English | 2006-02-15 05:02:19 |
| 2 | Italian | 2006-02-15 05:02:19 |
| 3 | Japanese | 2006-02-15 05:02:19 |
| 4 | Mandarin | 2006-02-15 05:02:19 |
| 5 | French | 2006-02-15 05:02:19 |
| 6 | German | 2006-02-15 05:02:19 |
| 7 | Portuguese | 2020-09-26 09:11:36 |
| 8 | Russian | 2020-09-26 10:35:00 |
+-------------+------------+---------------------+
8 rows in set (0.00 sec)
Однострочный стиль INSERT обнаруживает дубликаты первичного ключа и останавливается, как только он их находит. Например, предположим, что мы пытаемся вставить другую строку с тем же самым language_id:
mysql> INSERT INTO language VALUES (8, 'Arabic', '2020-09-26 10:35:00');
ERROR 1062 (23000): Duplicate entry '8' for key 'language.PRIMARY'
Операция INSERT останавливается, когда обнаруживает повторяющийся ключ. Вы можете добавить предложение IGNORE, чтобы предотвратить ошибку, если хотите, но обратите внимание, что строка все равно не будет вставлена:
mysql> INSERT IGNORE INTO language VALUES (8, 'Arabic', '2020-09-26 10:35:00');
Query OK, 0 rows affected, 1 warning (0.00 sec)
Однако в большинстве случаев вы захотите узнать о возможных проблемах (в конце концов, первичные ключи должны быть уникальными), поэтому этот синтаксис IGNORE используется редко.
Также можно вставить несколько значений одновременно:
mysql> INSERT INTO language VALUES (NULL, 'Spanish', NOW()),
-> (NULL, 'Hebrew', NOW());
Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0
Обратите внимание, что MySQL сообщает о результатах массовой вставки иначе, чем одиночной вставки.
Первая строка сообщает вам, сколько строк было вставлено, а первая запись во второй строке сообщает вам, сколько строк (или записей) было фактически обработано. Если вы используете INSERT IGNORE и пытаетесь вставить повторяющуюся запись (такую, для которой первичный ключ совпадает с первичным ключом существующей строки), MySQL молча пропустит ее вставку и сообщит о ней как о дубликате во второй записи во второй строке:
mysql> INSERT IGNORE INTO language VALUES (9, 'Portuguese', NOW()),
(11, 'Hebrew', NOW());
Query OK, 1 row affected, 1 warning (0.01 sec)
Records: 2 Duplicates: 1 Warnings: 1
Мы обсудим причины предупреждений, показанных как третья запись во второй строке вывода, в главе 4.
Альтернативный синтаксис
Существует несколько альтернатив синтаксису VALUES, продемонстрированному в предыдущем разделе. В этом разделе мы рассмотрим их и объясним преимущества и недостатки каждого из них. Если вас устраивает базовый синтаксис, который мы описали выше, и вы хотите перейти к новой теме, можете сразу переходить к «Оператор DELETE».
Синтаксис VALUES, который мы использовали, имеет некоторые преимущества: он работает как для одиночной, так и для массовой вставки, вы получаете сообщение об ошибке, если забыли указать значения для всех столбцов, и вам не нужно вводить имена столбцов. Однако у него также есть некоторые недостатки: вам нужно помнить порядок столбцов, вам нужно указать значение для каждого столбца, а синтаксис тесно связан с базовой структурой таблицы. То есть, если вы измените структуру таблицы, вам нужно изменить операторы INSERT. К счастью, мы можем избежать этих недостатков, изменив синтаксис.
Предположим, вы знаете, что таблица актеров состоит из четырех столбцов, и вы помните их имена, но забыли их порядок. Вы можете вставить строку, используя следующий подход:
mysql> INSERT INTO actor (actor_id, first_name, last_name, last_update)
-> VALUES (NULL, 'Vinicius', 'Grippa', NOW());
Query OK, 1 row affected (0.03 sec)
Имена столбцов заключаются в круглые скобки после имени таблицы, а значения, хранящиеся в этих столбцах, перечислены в круглых скобках после ключевого слова VALUES. Итак, в этом примере создается новая строка, а значение 201 сохраняется в виде actor_id (помните, у actor_id есть свойство auto_increment), Vinicius сохраняется как first_name, Grippa сохраняется как last_name, а столбец last_update заполняется текущей отметкой времени. Преимущества этого синтаксиса заключаются в том, что он удобочитаем и гибок (устраняет третий недостаток, который мы описали) и не зависит от порядка (устраняет первый недостаток). Проблема в том, что вам нужно знать имена столбцов и вводить их.
Этот новый синтаксис может также устранить второй недостаток более простого подхода, т. е. он позволяет вставлять значения только для некоторых столбцов. Чтобы понять, как это может быть полезно, давайте изучим таблицу городов:
mysql> DESC city;
+-------------+----------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------+----------------------+------+-----+-------------------+...
| city_id | smallint(5) unsigned | NO | PRI | NULL |...
| city | varchar(50) | NO | | NULL |...
| country_id | smallint(5) unsigned | NO | MUL | NULL |...
| last_update | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------+----------------------+------+-----+-------------------+...
...+-----------------------------------------------+
...| Extra |
...+-----------------------------------------------+
...| auto_increment |
...| |
...| |
...| on update CURRENT_TIMESTAMP |
...|-----------------------------------------------+
4 rows in set (0.00 sec)
Обратите внимание, что столбец last_update имеет значение по умолчанию CURRENT_TIMESTAMP. Это означает, что если вы не вставите значение для столбца last_update, MySQL по умолчанию вставит текущую дату и время. Это как раз то, что нам нужно: когда мы сохраняем запись, мы не хотим проверять дату и время и вводить их. Давайте попробуем вставить неполную запись:
mysql> INSERT INTO city (city, country_id) VALUES ('Bebedouro', 19);
Query OK, 1 row affected (0.00 sec)
Мы не устанавливали значение для столбца city_id, поэтому MySQL по умолчанию использует следующее доступное значение (из-за свойства auto_increment), а last_update сохраняет текущую дату и время. Проверить это можно запросом:
mysql> SELECT * FROM city where city like 'Bebedouro';
+---------+-----------+------------+---------------------+
| city_id | city | country_id | last_update |
+---------+-----------+------------+---------------------+
| 601 | Bebedouro | 19 | 2021-02-27 21:34:08 |
+---------+-----------+------------+---------------------+
1 row in set (0.01 sec)
Вы также можете использовать этот подход для массовой вставки следующим образом:
mysql> INSERT INTO city (city,country_id) VALUES
-> ('Sao Carlos',19),
-> ('Araraquara',19),
-> ('Ribeirao Preto',19);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
Помимо необходимости запоминать и вводить имена столбцов, недостатком этого подхода является то, что вы можете случайно пропустить значения для столбцов. MySQL установит для пропущенных столбцов значения по умолчанию. Все столбцы в таблице MySQL имеют значение по умолчанию NULL, если другое значение по умолчанию не назначено явно при создании или изменении таблицы.
Если вам нужно использовать значения по умолчанию для столбцов таблицы, вы можете использовать ключевое слово DEFAULT (поддерживается в MySQL 5.7 и более поздних версиях). Вот пример добавления строки в таблицу стран с использованием DEFAULT:
mysql> INSERT INTO country VALUES (NULL, 'Uruguay', DEFAULT);
Query OK, 1 row affected (0.01 sec)
Ключевое слово DEFAULT указывает MySQL использовать значение по умолчанию для этого столбца, поэтому в нашем примере вставляются текущая дата и время. Преимущества этого подхода заключаются в том, что вы можете использовать функцию массовой вставки со значениями по умолчанию, и вы никак не сможете случайно пропустить столбец.
Есть еще один альтернативный синтаксис INSERT. В этом подходе вы перечисляете имена столбцов и значения вместе, поэтому вам не нужно мысленно сопоставлять список значений с более ранним списком столбцов. Вот пример добавления новой строки в таблицу стран:
mysql> INSERT INTO country SET country_id=NULL,
-> country='Bahamas', last_update=NOW();
Query OK, 1 row affected (0.01 sec)
Синтаксис требует, чтобы вы перечислили имя таблицы, ключевое слово SET, а затем пары столбец-равно-значение, разделенные запятыми. Столбцы, для которых не указаны значения, устанавливаются в значения по умолчанию. Опять же, недостатки заключаются в том, что вы можете случайно пропустить значения для столбцов и что вам нужно запомнить и ввести имена столбцов. Существенным дополнительным недостатком является то, что вы не можете использовать этот метод для массовой вставки.
Вы также можете вставить, используя значения, возвращенные из запроса. Мы обсудим это в главе 7.
Оператор DELETE
Оператор DELETE используется для удаления одной или нескольких строк из таблицы. Здесь мы объясняем удаление из одной таблицы, а в главе 7 обсуждаем удаление из нескольких таблиц, которое удаляет данные из двух или более таблиц с помощью одного оператора.
Основы DELETE
Самое простое использование DELETE — удалить все строки в таблице. Предположим, вы хотите очистить свою таблицу rental. Вы можете сделать это с помощью:
mysql> DELETE FROM rental;
Query OK, 16044 rows affected (2.41 sec)
Синтаксис DELETE не включает имена столбцов, поскольку он используется для удаления целых строк, а не только значений из строки. Чтобы сбросить или изменить значение в строке, вы используете оператор UPDATE, описанный в разделе «Оператор UPDATE». Обратите внимание, что оператор DELETE не удаляет саму таблицу. Например, удалив все строки в таблице rental, вы все равно можете запросить таблицу:
mysql> SELECT * FROM rental;
Empty set (0.00 sec)
Вы также можете продолжить изучение его структуры, используя DESCRIBE или SHOW CREATE TABLE, и вставлять новые строки, используя INSERT. Чтобы удалить таблицу, вы используете оператор DROP, описанный в главе 4.
Обратите внимание, что если таблица связана с другой таблицей, удаление может завершиться ошибкой из-за ограничения внешнего ключа:
mysql> DELETE FROM language;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key
constraint fails (`sakila`.`film`, CONSTRAINT `fk_film_language` FOREIGN KEY
(`language_id`) REFERENCES `language` (`language_id`) ON UPDATE CASCADE)
Использование WHERE, ORDER BY и LIMIT
Если вы удалили строки в предыдущем разделе, перезагрузите базу данных sakila сейчас, следуя инструкциям в «Примерах моделирования отношений сущностей». Вам потребуются восстановленные строки в таблице аренды для примеров в этом разделе.
Чтобы удалить одну или несколько строк, но не все строки в таблице, используйте предложение WHERE. Это работает так же, как и для SELECT. Например, предположим, что вы хотите удалить все строки из таблицы rental с rental_id меньше 10. Вы можете сделать это с помощью:
mysql> DELETE FROM rental WHERE rental_id < 10;
Query OK, 9 rows affected (0.01 sec)
В результате удаляются девять строк, соответствующих критерию.
Теперь предположим, что вы хотите удалить из базы данных все платежи от клиента по имени Мэри Смит. Сначала выполните SELECT с таблицами customer и payment, используя INNER JOIN (как описано в разделе «Объединение двух таблиц»):
mysql> SELECT first_name, last_name, customer.customer_id,
-> amount, payment_date FROM payment INNER JOIN customer
-> ON customer.customer_id=payment.customer_id
-> WHERE first_name like 'Mary'
-> AND last_name like 'Smith';
+------------+-----------+-------------+--------+---------------------+
| first_name | last_name | customer_id | amount | payment_date |
+------------+-----------+-------------+--------+---------------------+
| MARY | SMITH | 1 | 2.99 | 2005-05-25 11:30:37 |
| MARY | SMITH | 1 | 0.99 | 2005-05-28 10:35:23 |
| MARY | SMITH | 1 | 5.99 | 2005-06-15 00:54:12 |
| MARY | SMITH | 1 | 0.99 | 2005-06-15 18:02:53 |
...
| MARY | SMITH | 1 | 1.99 | 2005-08-22 01:27:57 |
| MARY | SMITH | 1 | 2.99 | 2005-08-22 19:41:37 |
| MARY | SMITH | 1 | 5.99 | 2005-08-22 20:03:46 |
+------------+-----------+-------------+--------+---------------------+
32 rows in set (0.00 sec)
Затем выполните следующую операцию DELETE, чтобы удалить строку с идентификатором customer_id, равным 1, из таблицы payment:
mysql> DELETE FROM payment where customer_id=1;
Query OK, 32 rows affected (0.01 sec)
Вы можете использовать предложения ORDER BY и LIMIT с DELETE. Обычно вы делаете это, когда хотите ограничить количество удаляемых строк. Например:
mysql> DELETE FROM payment ORDER BY customer_id LIMIT 10000;
Query OK, 10000 rows affected (0.22 sec)
Удаление всех строк с помощью TRUNCATE
Если вы хотите удалить все строки в таблице, есть более быстрый способ, чем их удаление с помощью DELETE. Когда вы используете оператор TRUNCATE TABLE, MySQL использует оптимизацию, удаляя таблицу, убирая структуры таблицы, а затем создавая их заново. Если в таблице много строк, это происходит намного быстрее.
Если вы хотите удалить все данные в таблице payment, вы можете выполнить это:
mysql> TRUNCATE TABLE payment;
Query OK, 0 rows affected (0.07 sec)
Обратите внимание, что количество затронутых строк отображается как ноль: для ускорения операции MySQL не считает количество удаленных строк, поэтому отображаемое число не отражает фактическое количество удаленных строк.
Оператор TRUNCATE TABLE во многом отличается от DELETE, стоит упомянуть некоторые из этих отличий:
-
Операции
TRUNCATEудаляют и воссоздают таблицу, что намного быстрее, чем удаление строк по одной, особенно для больших таблиц. -
Операции
TRUNCATEвызывают неявную фиксацию, поэтому их нельзя откатить. -
Вы не можете выполнять операции
TRUNCATE, если сеанс удерживает активную блокировку таблицы.
Типы таблиц, транзакции и блокировки обсуждаются в главе 5. Ни одно из этих ограничений не влияет на большинство практических приложений, и вы можете использовать TRUNCATE TABLE для ускорения обработки. Конечно, во время обычной работы не принято удалять целые таблицы. Исключением являются временные таблицы, используемые для временного хранения результатов запросов для конкретного сеанса пользователя, которые можно удалить без потери исходных данных.
Оператор UPDATE
Оператор UPDATE используется для изменения данных. В этом разделе мы покажем вам, как обновить одну или несколько строк в одной таблице. Многотабличные обновления обсуждаются в разделе «Обновления».
Если вы удалили строки из базы данных sakila, перезагрузите ее, прежде чем продолжить.
Примеры
Простейшее использование оператора UPDATE — изменение всех строк в таблице. Предположим, вам нужно обновить столбец amount в таблице payment, добавив 10% ко всем платежам. Вы можете сделать это, выполнив:
mysql> UPDATE payment SET amount=amount*1.1;
Query OK, 16025 rows affected, 16025 warnings (0.41 sec)
Rows matched: 16049 Changed: 16025 Warnings: 16025
Обратите внимание, что мы забыли обновить статус last_update. Чтобы сделать его согласованным с ожидаемой моделью базы данных, вы можете исправить это, выполнив следующую инструкцию:
mysql> UPDATE payment SET last_update='2021-02-28 17:53:00';
Query OK, 16049 rows affected (0.27 sec)
Rows matched: 16049 Changed: 16049 Warnings: 0
Вторая строка, сообщаемая оператором UPDATE, показывает общий эффект оператора. В нашем примере вы видите:
Rows matched: 16049 Changed: 16049 Warnings: 0В первом столбце указано количество строк, которые были найдены как совпадения; в этом случае, поскольку нет предложения WHERE или LIMIT, все строки в таблице соответствуют запросу. Во втором столбце сообщается, сколько строк необходимо изменить, что всегда равно или меньше числа совпадающих строк. Если вы повторите оператор, вы увидите другой результат:
mysql> UPDATE payment SET last_update='2021-02-28 17:53:00';
Query OK, 0 rows affected (0.07 sec)
Rows matched: 16049 Changed: 0 Warnings: 0
На этот раз, поскольку дата уже установлена на 2021-02-28 17:53:00 и условие WHERE отсутствует, все строки по-прежнему соответствуют запросу, но ни одна из них не изменяется. Также обратите внимание, что количество измененных строк всегда равно количеству затронутых строк, как указано в первой строке выходных данных.
Использование WHERE, ORDER BY и LIMIT
Часто вы не хотите изменять все строки в таблице. Вместо этого вы хотите обновить одну или несколько строк, соответствующих условию. Как и в случае с SELECT и DELETE, для задачи используется предложение WHERE. Кроме того, так же, как и с DELETE, вы можете использовать ORDER BY и LIMIT вместе, чтобы контролировать, сколько строк обновляется из упорядоченного списка.
Давайте попробуем пример, который изменяет одну строку в таблице. Предположим, что актриса Пенелопа Гиннес сменила фамилию. Чтобы обновить ее в таблице actor базы данных, нужно выполнить:
mysql> UPDATE actor SET last_name= UPPER('cruz')
-> WHERE first_name LIKE 'PENELOPE'
-> AND last_name LIKE 'GUINESS';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
Как и ожидалось, MySQL сопоставил одну строку и изменил одну строку.
Чтобы контролировать количество обновлений, вы можете использовать комбинацию ORDER BY и LIMIT:
mysql> UPDATE payment SET last_update=NOW() LIMIT 10;
Query OK, 10 rows affected (0.01 sec)
Rows matched: 10 Changed: 10 Warnings: 0
Как и в случае с DELETE, вы должны сделать это, потому что вы хотите либо выполнять операцию небольшими порциями, либо изменять только некоторые строки. Здесь вы можете видеть, что 10 строк были сопоставлены и изменены.
Предыдущий запрос также иллюстрирует важный аспект обновлений. Как вы видели, обновления состоят из двух фаз: фазы сопоставления, на которой находятся строки, соответствующие предложению WHERE, и фазы модификации, на которой обновляются строки, которые необходимо изменить.
Изучение баз данных и таблиц с помощью SHOW и mysqlshow
Мы уже объясняли, как можно использовать команду SHOW для получения информации о структуре базы данных, ее таблицах и столбцах таблицы. В этом разделе мы рассмотрим наиболее распространенные типы оператора SHOW с краткими примерами использования базы данных sakila. Программа командной строки mysqlshow выполняет те же функции, что и несколько вариантов команды SHOW, но без необходимости запуска клиента MySQL.
Оператор SHOW DATABASES перечисляет базы данных, к которым вы можете получить доступ. Если вы выполнили шаги по установке образца базы данных в разделе «Примеры моделирования отношений сущностей» и развернули модель банка в разделе «Создание модели ER базы данных банка», результат должен быть следующим:
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| bank_model |
| employees |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
+--------------------+
8 rows in set (0.01 sec)
Это базы данных, к которым вы можете получить доступ с помощью команды USE (обсуждается в главе 4); если у вас есть права доступа к другим базам данных на вашем сервере, они также будут перечислены. Вы можете видеть только те базы данных, для которых у вас есть некоторые привилегии, если только у вас нет глобальной привилегии SHOW DATABASES. Вы можете получить тот же эффект из командной строки, используя программу mysqlshow:
$ mysqlshow -uroot -pmsandbox -h 127.0.0.1 -P 3306Вы можете добавить предложение LIKE в SHOW DATABASES. Это полезно, если у вас много баз данных и вы хотите получить краткий список в качестве вывода. Например, чтобы просмотреть только базы данных, имена которых начинаются с буквы s, выполните:
mysql> SHOW DATABASES LIKE 's%';
+---------------+
| Database (s%) |
+---------------+
| sakila |
| sys |
+---------------+
2 rows in set (0.00 sec)
Синтаксис оператора LIKE идентичен его использованию в SELECT.
Чтобы просмотреть оператор, используемый для создания базы данных, вы можете использовать оператор SHOW CREATE DATABASE. Например, чтобы увидеть, как вы создали sakila, введите:
mysql> SHOW CREATE DATABASE sakila;
************************** 1. row ***************************
Database: sakila
Create Database: CREATE DATABASE `sakila` /*!40100 DEFAULT CHARACTER SET
utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
1 row in set (0.00 sec)
Это, пожалуй, наименее захватывающее выражение SHOW; он только отображает выражение. Обратите внимание, однако, что включены некоторые дополнительные комментарии, /*! и */:
40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci
80016 DEFAULT ENCRYPTION='N'
Эти комментарии содержат специфичные для MySQL ключевые слова, содержащие инструкции, которые вряд ли будут поняты другими программами баз данных. Сервер базы данных, отличный от MySQL, будет игнорировать этот текст комментария, поэтому синтаксис может использоваться как MySQL, так и другим программным обеспечением сервера баз данных. Необязательный номер в начале комментария указывает на минимальную версию MySQL, которая может обрабатывать эту конкретную инструкцию (например, 40100 указывает на версию 4.01.00); более старые версии MySQL игнорируют такие инструкции. Вы узнаете о создании баз данных в главе 4.
Оператор SHOW TABLES выводит список таблиц в базе данных. Чтобы проверить таблицы в sakila, введите:
mysql> SHOW TABLES FROM sakila;
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
| actor_info |
| address |
| category |
| city |
| country |
| customer |
| customer_list |
| film |
| film_actor |
| film_category |
| film_list |
| film_text |
| inventory |
| language |
| nicer_but_slower_film_list |
| payment |
| rental |
| sales_by_film_category |
| sales_by_store |
| staff |
| ... |
+----------------------------+
23 rows in set (0.01 sec)
Если вы уже выбрали базу данных sakila с помощью команды USE sakila, вы можете использовать команду:
mysql> SHOW TABLES;Аналогичный результат можно получить, указав имя базы данных программе mysqlshow:
$ mysqlshow -uroot -pmsandbox -h 127.0.0.1 -P 3306 sakilaКак и в случае с SHOW DATABASES, вы не можете видеть таблицы, для которых у вас нет прав. Это означает, что вы не можете видеть таблицы в базе данных, к которой у вас нет доступа, даже если у вас есть глобальная привилегия SHOW DATABASES.
Оператор SHOW COLUMNS выводит список столбцов в таблице. Например, чтобы проверить столбцы country, введите:
mysql> SHOW COLUMNS FROM country;
*************************** 1. row ***************************
Field: country_id
Type: smallint unsigned
Null: NO
Key: PRI
Default: NULL
Extra: auto_increment
*************************** 2. row ***************************
Field: country
Type: varchar(50)
Null: NO
Key:
Default: NULL
Extra:
*************************** 3. row ***************************
Field: last_update
Type: timestamp
Null: NO
Key:
Default: CURRENT_TIMESTAMP
Extra: DEFAULT_GENERATED on update CURRENT_TIMESTAMP
3 rows in set (0.00 sec)
Вывод сообщает имена всех столбцов, их типы и размеры, могут ли они быть NULL, являются ли они частью ключа, их значения по умолчанию и любую дополнительную информацию. Типы, ключи, значения NULL и значения по умолчанию обсуждаются далее в главе 4. Если вы еще не выбрали базу данных sakila с помощью команды USE, вы можете добавить имя базы данных перед именем таблицы, как в sakila.country. В отличие от предыдущих операторов SHOW, вы всегда можете увидеть все имена столбцов, если у вас есть доступ к таблице; не имеет значения, что у вас нет определенных привилегий для всех столбцов.
Вы можете получить аналогичный результат, используя mysqlshow с именем базы данных и таблицы:
$ mysqlshow -uroot -pmsandbox -h 127.0.0.1 -P 3306 sakila countryВы можете увидеть оператор, используемый для создания конкретной таблицы, используя оператор SHOW CREATE TABLE (мы также рассмотрим создание таблиц в главе 4). Некоторые пользователи предпочитают этот вывод выводу SHOW COLUMNS, поскольку он имеет знакомый формат оператора CREATE TABLE. Вот пример таблицы стран:
mysql> SHOW CREATE TABLE country\G
*************************** 1. row ***************************
Table: country
Create Table: CREATE TABLE `country` (
`country_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`country` varchar(50) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB AUTO_INCREMENT=110 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
Глава 4
Работа со структурами базы данных
В этой главе показано, как создавать собственные базы данных, добавлять и удалять такие структуры, как таблицы и индексы, а также выбирать типы столбцов в таблицах. Основное внимание уделяется синтаксису и особенностям SQL, а не семантике понимания, спецификации и уточнения структуры базы данных; вводное описание методов проектирования базы данных вы найдете в главе 2. Для работы с этой главой вам необходимо понимать, как работать с существующей базой данных и ее таблицами, как обсуждалось в главе 3.
В этой главе перечислены структуры в образце базы данных sakila. Если вы следовали инструкциям по загрузке базы данных в «Примеры моделирования отношений сущностей», у вас уже будет доступ к базе данных, и вы будете знать, как восстановить ее после изменения ее структуры.
Когда вы закончите эту главу, у вас будут все основы, необходимые для создания, изменения и удаления структур базы данных. Вместе с приемами, изученными вами в главе 3, вы приобретете навыки выполнения широкого круга основных операций. Главы 5 и 7 посвящены навыкам, позволяющим выполнять более сложные операции с MySQL.
Создание и использование баз данных
Когда вы закончили проектирование базы данных, первый практический шаг, который нужно сделать с MySQL, — это создать ее. Вы делаете это с помощью оператора CREATE DATABASE. Предположим, вы хотите создать базу данных с именем lucy. Вот выражение, которое вы должны ввести:
mysql> CREATE DATABASE lucy;
Query OK, 1 row affected (0.10 sec)
Здесь мы предполагаем, что вы знаете, как подключаться с помощью клиента MySQL, как описано в главе 1. Мы также предполагаем, что вы можете подключаться как пользователь root или как другой пользователь, который может создавать, удалять и изменять структуры (подробное обсуждение привилегий пользователей можно найти в главе 8). Обратите внимание, что когда вы создаете базу данных, MySQL сообщает, что была затронута одна строка. На самом деле это не обычная строка в какой-либо конкретной базе данных, а новая запись, добавленная в список, который вы видите с помощью команды SHOW DATABASES.
После того как вы создали базу данных, следующим шагом будет ее использование, то есть выбор ее в качестве базы данных, с которой вы работаете. Вы делаете это с помощью команды MySQL USE:
mysql> USE lucy;
Database changed
Эта команда должна быть введена в одну строку и ее не обязательно заканчивать точкой с запятой, хотя обычно мы делаем это автоматически по привычке. После того, как вы использовали (выбрали) базу данных, вы можете приступить к созданию таблиц, индексов и других структур, используя шаги, описанные в следующем разделе.
Прежде чем мы перейдем к созданию других структур, давайте обсудим некоторые особенности и ограничения создания баз данных. Во-первых, давайте посмотрим, что произойдет, если вы попытаетесь создать базу данных, которая уже существует:
mysql> CREATE DATABASE lucy;
ERROR 1007 (HY000): Can't create database 'lucy'; database exists
Вы можете избежать этой ошибки, добавив ключевую фразу IF NOT EXISTS в выражение:
mysql> CREATE DATABASE IF NOT EXISTS lucy;
Query OK, 0 rows affected (0.00 sec)
Вы можете видеть, что MySQL не пожаловался, но и ничего не сделал: сообщение 0 затронутых строк указывает на то, что никакие данные не были изменены. Это дополнение полезно, когда вы добавляете операторы SQL в сценарий: оно предотвращает прерывание сценария при ошибке.
Давайте посмотрим, как выбирать имена баз данных и использовать регистр символов. Имена баз данных определяют имена физических каталогов (или папок) на диске. В некоторых операционных системах имена каталогов вводятся с учетом регистра; на других регистр не имеет значения. Например, Unix-подобные системы, такие как Linux и macOS, обычно чувствительны к регистру, а Windows — нет. В результате имена баз данных имеют те же ограничения: если регистр имеет значение для операционной системы, он имеет значение и для MySQL. Например, на машине Linux LUCY, lucy и Lucy — это разные имена баз данных; в Windows они относятся только к одной базе данных. Использование неправильной заглавной буквы в Linux или macOS приведет к тому, что MySQL будет жаловаться:
mysql> SELECT SaKilA.AcTor_id FROM ACTor;
ERROR 1146 (42S02): Table 'sakila.ACTor' doesn't exist
Но под Windows это нормально работает.
Это поведение контролируется параметром lower_case_table_names. Если установлено значение 0, имена таблиц сохраняются, как было указано, а сравнения чувствительны к регистру. Если установлено значение 1, имена таблиц сохраняются на диске в нижнем регистре, а сравнения не чувствительны к регистру. Если для этого параметра установлено значение 2, имена таблиц сохраняются как были заданны, но сравниваются в нижнем регистре. В Windows значение по умолчанию — 1. В macOS значение по умолчанию — 2. В Linux значение 2 не поддерживается; вместо этого сервер устанавливает значение равным 0.
Существуют и другие ограничения на имена баз данных. Они могут иметь длину не более 64 символов. Вы также не должны использовать зарезервированные слова MySQL, такие как SELECT, FROM и USE, в качестве имен для структур; они могут запутать синтаксический анализатор MySQL, делая невозможным интерпретацию смысла ваших утверждений. Вы можете обойти это ограничение, заключив зарезервированное слово в обратные кавычки (`), но помнить об этом больше проблем, чем пользы. Кроме того, в именах нельзя использовать определенные символы, в частности, косую черту, обратную косую черту, точку с запятой и символы точки, а имя базы данных не может заканчиваться пробелом. Опять же, использование этих символов сбивает с толку анализатор MySQL и может привести к непредсказуемому поведению. Например, вот что происходит, когда вы вставляете точку с запятой в имя базы данных:
mysql> CREATE DATABASE IF NOT EXISTS lu;cy;
Query OK, 1 row affected (0.00 sec)
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'cy' at line 1
Поскольку в одной строке может находиться более одного оператора SQL, в результате создается база данных lu, а затем возникает ошибка из-за очень короткого и неожиданного оператора SQL cy;. Если вы действительно хотите создать базу данных с точкой с запятой в имени, вы можете сделать это с помощью обратных кавычек:
mysql> CREATE DATABASE IF NOT EXISTS `lu;cy`;
Query OK, 1 row affected (0.01 sec)
И вы можете видеть, что теперь у вас есть две новые базы данных:
mysql> SHOW DATABASES LIKE `lu%`;
+----------------+
| Database (lu%) |
+----------------+
| lu |
| lu;cy |
+----------------+
2 rows in set (0.01 sec)
Создание таблиц
В этом разделе рассматриваются темы по структурам таблиц. Мы покажем вам, как:
Создавать таблицы с помощью вводных примеров.
Выбирать имена для таблиц и структур, связанных с таблицами.
Понимать и выбирать типы столбцов.
Понимать и выбирать ключи и индексы.
Использовать проприетарную функцию MySQL
AUTO_INCREMENT.
Когда вы закончите этот раздел, вы получите весь основной материал по созданию структур базы данных; оставшаяся часть этой главы посвящена образцу базы данных sakila и тому, как изменять и удалять существующие структуры.
Основы
В примерах в этом разделе предполагается, что база данных sakila еще не создана. Если вы хотите следовать примерам и уже загрузили базу данных, вы можете оставить ее для этого раздела и перезагрузить позже; при ее удалении база данных, ее таблицы и все данные удаляются, но оригинал легко восстановить, выполнив действия, описанные в «Примерах моделирования отношений сущностей». Вот как вы временно удаляете ее:
mysql> DROP DATABASE sakila;
Query OK, 23 rows affected (0.06 sec)
Оператор DROP обсуждается далее в конце этой главы в разделе «Удаление структур».
Для начала создайте базу данных sakila с помощью инструкции:
mysql> CREATE DATABASE sakila;
Query OK, 1 row affected (0.00 sec)
Затем выберите базу данных с помощью:
mysql> USE sakila;
Database changed
Теперь мы готовы приступить к созданию таблиц, в которых будут храниться наши данные. Давайте создадим таблицу для хранения сведений об актерах. Сейчас у нас будет упрощенная структура, а позже мы добавим больше сложности. Вот выражение, которое мы используем:
mysql> CREATE TABLE actor (
-> actor_id SMALLINT UNSIGNED NOT NULL DEFAULT 0,
-> first_name VARCHAR(45) DEFAULT NULL,
-> last_name VARCHAR(45),
-> last_update TIMESTAMP,
-> PRIMARY KEY (actor_id)
-> );
Query OK, 0 rows affected (0.01 sec)
Не паникуйте — несмотря на то, что MySQL сообщает, что были затронуты ноль строк, она создала таблицу:
mysql> SHOW tables;
+------------------+
| Tables_in_sakila |
+------------------+
| actor |
+------------------+
1 row in set (0.01 sec)
Рассмотрим все это подробно. Команда CREATE TABLE состоит из трех основных разделов:
-
Оператор
CREATE TABLE, за которым следует имя создаваемой таблицы. В данном примере этоactor. -
Список из одного или нескольких столбцов, которые необходимо добавить в таблицу. В этом примере мы добавили довольно много:
actor_id SMALLINT UNSIGNED NOT NULL DEFAULT 0, first_name VARCHAR(45) DEFAULT NULL, last_name VARCHAR(45)иlast_update TIMESTAMP. Мы обсудим это через мгновение. -
Необязательные ключевые определения. В этом примере мы определили один ключ:
PRIMARY KEY (actor_id). Мы подробно обсудим ключи и индексы позже в этой главе.
Обратите внимание, что за компонентом CREATE TABLE следует открывающая скобка, которой соответствует закрывающая скобка в конце инструкции. Обратите также внимание на то, что остальные компоненты разделены запятыми. Есть и другие элементы, которые вы можете добавить в оператор CREATE TABLE, и мы обсудим некоторые из них чуть позже.
Давайте обсудим характеристики колонки. Основной синтаксис следующий: name type [NOT NULL | NULL] [DEFAULT value]. Поле name — это имя столбца, и оно имеет те же ограничения, что и имена баз данных, как обсуждалось в предыдущем разделе. Оно может содержать не более 64 символов, не допускаются обратная и прямая косая черта, не допускаются точки, оно не может заканчиваться пробелом, а чувствительность к регистру зависит от базовой операционной системы. Поле type определяет, как и что хранится в столбце; например, мы видели, что оно может быть установлено в VARCHAR для строк, SMALLINT для чисел или TIMESTAMP для даты и времени.
Если указать NOT NULL, строка недействительна без значения для столбца; если вы укажете NULL или опустите это предложение, строка может существовать без значения для столбца. Если вы укажете value в предложении DEFAULT, оно будет использовано для заполнения столбца, если вы не предоставите данные иным образом; это особенно полезно, когда вы часто повторно используете значение по умолчанию, такое как название страны. value должно быть константой (например, 0, "cat" или 20060812045623), за исключением случаев, когда столбец имеет тип TIMESTAMP. Типы подробно обсуждаются в разделе «Типы столбцов».
Функции NOT NULL и DEFAULT можно использовать вместе. Если вы укажете NOT NULL и добавите значение DEFAULT, будет использовано значение по умолчанию, если вы не укажете значение для столбца. Иногда это работает нормально:
mysql> INSERT INTO actor(first_name) VALUES ('John');
Query OK, 1 row affected (0.01 sec)
А иногда и нет:
mysql> INSERT INTO actor(first_name) VALUES ('Elisabeth');
ERROR 1062 (23000): Duplicate entry '0' for key 'actor.PRIMARY'
Работает это или нет, зависит от лежащих в его основе ограничений и условий базы данных: в этом примере, actor_id имеет значение по умолчанию 0, но это также первичный ключ. Наличие двух строк с одинаковым значением первичного ключа не допускается, поэтому вторая попытка вставить строку без значений (и результирующее значение первичного ключа равно 0) завершается неудачей. Мы подробно обсуждаем первичные ключи в разделе «Ключи и индексы».
Имена столбцов имеют меньше ограничений, чем имена баз данных и таблиц. Более того, имена нечувствительны к регистру и переносимы на все платформы. В именах столбцов разрешены все символы, однако, если вы хотите завершить их пробелами или включить точки или другие специальные символы, такие как точка с запятой или дефис, вам необходимо заключить имя в обратные кавычки (`). Опять же, мы рекомендуем вам последовательно выбирать имена в нижнем регистре для вариантов, определяемых разработчиком (таких как база данных, псевдонимы и имена таблиц), и избегать символов, которые требуют, чтобы вы не забывали использовать обратные апострофы.
Именование столбцов и других объектов базы данных является чем-то вроде личных предпочтений при запуске заново (вы можете получить вдохновение, просмотрев примеры баз данных) или вопросом соблюдения стандартов при работе с существующей кодовой базой. В общем, старайтесь избегать повторений: в таблице с именем actor используйте имя столбца first_name, а не actor_first_name, которое выглядело бы избыточным, если в сложном запросе ему предшествовало имя таблицы (actor.actor_first_name по сравнению с actor.first_name). Исключением является использование вездесущего имени столбца id; либо избегайте этого, либо добавляйте имя таблицы для ясности (например, actor_id). Хорошей практикой является использование символа подчеркивания для разделения слов. Вы можете использовать другой символ, например, тире или косую черту, но вы должны помнить, что должны заключать имена в обратные кавычки (например, actor-id). Вы также можете вообще опустить форматирование слов, но «ВерблюжийРегистр», возможно, труднее читать. Как и в случае с именами баз данных и таблиц, максимально допустимая длина имени столбца составляет 64 символа.
Сопоставление и наборы символов
Когда вы сравниваете или сортируете строки, то, как MySQL оценивает результат, зависит от используемого набора символов и сопоставления. Наборы символов определяют, какие символы могут быть сохранены; например, вам может понадобиться сохранить неанглийские символы, такие как ю или ü. Сопоставление определяет, как упорядочиваются строки, и для разных языков существуют разные сопоставления: например, положение символа ü в алфавите различается в двух порядках на немецком языке и снова различается в шведском и финском языках. Поскольку не все хотят хранить строки на английском языке, важно, чтобы сервер базы данных мог управлять неанглийскими символами и различными способами сортировки символов.
Мы понимаем, что обсуждение сопоставлений и кодировок может показаться слишком сложным, когда вы только начинаете изучать MySQL. Однако мы также считаем, что эти темы стоит осветить, поскольку несоответствие кодировок и параметров сортировки может привести к непредвиденным ситуациям, включая потерю данных и неверные результаты запроса. Если вы предпочитаете, вы можете пропустить этот раздел и некоторые последующие обсуждения в этой главе и вернуться к этим темам, когда захотите узнать о них конкретно. Это не повлияет на ваше понимание других материалов этой книги.
В наших предыдущих примерах сравнения строк мы проигнорировали проблему сортировки и кодировки и просто позволили MySQL использовать свои значения по умолчанию. В версиях MySQL до 8.0 набор символов по умолчанию — latin1, а сопоставление по умолчанию — latin1_swedish_ci. MySQL 8.0 изменил значения по умолчанию, и теперь кодировка по умолчанию — utf8mb4, а сопоставление по умолчанию — utf8mb4_0900_ai_ci. MySQL можно настроить для использования различных наборов символов и порядка сортировки на уровне соединения, базы данных, таблицы и столбца. Результаты, показанные здесь, относятся к MySQL 8.0.
Вы можете просмотреть наборы символов, доступные на вашем сервере, с помощью команды SHOW CHARACTER SET. Здесь показано краткое описание каждого набора символов, его сопоставление по умолчанию и максимальное количество байтов, используемых для каждого символа в этом наборе символов:
mysql> SHOW CHARACTER SET;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| binary | Binary pseudo charset | binary | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| ... |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)
Например, набор символов latin1 на самом деле является кодовой страницей Windows 1252, которая поддерживает западноевропейские языки. Параметр сортировки по умолчанию для этого набора символов — latin1_swedish_ci, который следует шведским соглашениям по сортировке символов с диакритическими знаками (английский язык обрабатывается так, как вы ожидаете). Это сопоставление нечувствительно к регистру, на что указывают буквы ci. Наконец, каждый символ занимает 1 байт. Для сравнения, если вы используете набор символов utf8mb4 по умолчанию, каждый символ будет занимать до 4 байт памяти. Иногда имеет смысл изменить значение по умолчанию. Например, нет смысла хранить данные, закодированные в base64 (которые по определению являются ASCII), в utf8mb4.
Точно так же вы можете перечислить порядок сопоставления и наборы символов, к которым они применяются:
mysql> SHOW COLLATION;
+---------------------+----------+-----+---------+...+---------------+
| Collation | Charset | Id | Default |...| Pad_attribute |
+---------------------+----------+-----+---------+...+---------------+
| armscii8_bin | armscii8 | 64 | |...| PAD SPACE |
| armscii8_general_ci | armscii8 | 32 | Yes |...| PAD SPACE |
| ascii_bin | ascii | 65 | |...| PAD SPACE |
| ascii_general_ci | ascii | 11 | Yes |...| PAD SPACE |
| ... |...| |
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes |...| NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | |...| NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | |...| NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | |...| NO PAD |
| ... |...| |
| utf8_unicode_ci | utf8 | 192 | |...| PAD SPACE |
| utf8_vietnamese_ci | utf8 | 215 | |...| PAD SPACE |
+---------------------+----------+-----+---------+...+---------------+
272 rows in set (0.02 sec)
Вы можете увидеть текущие значения по умолчанию на вашем сервере следующим образом:
mysql> SHOW VARIABLES LIKE 'c%';
+--------------------------+--------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------+
| ... |
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
| ... |
| collation_connection | utf8mb4_0900_ai_ci |
| collation_database | utf8mb4_0900_ai_ci |
| collation_server | utf8mb4_0900_ai_ci |
| ... |
+--------------------------+--------------------------------+
21 rows in set (0.00 sec)
При создании базы данных вы можете установить набор символов по умолчанию и порядок сортировки для базы данных и ее таблиц. Например, если вы хотите использовать набор символов utf8mb4 и порядок сопоставления utf8mb4_ru_0900_as_cs (с учетом регистра), вы должны написать:
mysql> CREATE DATABASE rose DEFAULT CHARACTER SET utf8mb4
-> COLLATE utf8mb4_ru_0900_as_cs;
Query OK, 1 row affected (0.00 sec)
Обычно в этом нет необходимости, если вы правильно установили MySQL для своего языка и региона и не планируете интернационализировать свое приложение. Поскольку utf8mb4 используется по умолчанию, начиная с MySQL 8.0, еще меньше необходимости менять кодировку. Вы также можете управлять набором символов и сопоставлением для отдельных таблиц или столбцов, но мы не будем здесь вдаваться в подробности того, как это сделать. Мы обсудим, как параметры сортировки влияют на типы строк, в разделе «Типы строк».
Другие особенности
В этом разделе кратко описаны другие возможности оператора CREATE TABLE. Он включает в себя пример использования функции IF NOT EXISTS, а также список расширенных функций и информацию о том, где можно найти о них больше в этой книге. Показанный оператор является полным представлением таблицы, взятой из базы данных sakila, в отличие от предыдущего упрощенного примера.
Вы можете использовать ключевую фразу IF NOT EXISTS при создании таблицы, и она работает так же, как и для баз данных. Вот пример, который не сообщит об ошибке, даже если таблица actor существует:
mysql> CREATE TABLE IF NOT EXISTS actor (
-> actor_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
-> first_name VARCHAR(45) NOT NULL,
-> last_name VARCHAR(45) NOT NULL,
-> last_update TIMESTAMP NOT NULL DEFAULT
-> CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> PRIMARY KEY (actor_id),
-> KEY idx_actor_last_name (last_name));
Query OK, 0 rows affected, 1 warning (0.01 sec)
Вы можете видеть, что затронуты ноль строк, и выдается предупреждение. Давайте взглянем:
mysql> SHOW WARNINGS;
+-------+------+------------------------------+
| Level | Code | Message |
+-------+------+------------------------------+
| Note | 1050 | Table 'actor' already exists |
+-------+------+------------------------------+
1 row in set (0.01 sec)
В инструкцию CREATE TABLE можно добавить множество дополнительных функций, но в этом примере представлены лишь некоторые из них. Многие из них являются продвинутыми и не обсуждаются в этой книге, но вы можете найти дополнительную информацию в Справочном руководстве по MySQL в разделе, посвященном оператору CREATE TABLE. Эти дополнительные функции включают следующее:
- Функция
AUTO_INCREMENTдля числовых столбцов -
Эта функция позволяет автоматически создавать уникальные идентификаторы для таблицы. Мы подробно обсуждаем это в разделе «Функция AUTO_INCREMENT».
- Комментарии столбца
-
Вы можете добавить комментарий к столбцу; это отображается, когда вы используете команду
SHOW CREATE TABLE, которую мы обсудим позже в этом разделе. - Ограничения внешнего ключа
-
Вы можете указать MySQL проверить, соответствуют ли данные в одном или нескольких столбцах данным в другой таблице. Например, база данных
sakilaимеет ограничение внешнего ключа для столбцаcity_idтаблицыaddress, ссылаясь на столбецcity_idтаблицыcity. Это означает, что невозможно иметь адрес в городе, которого нет в таблицеcity. Мы представили ограничения внешнего ключа в главе 2 и рассмотрим, какие механизмы поддерживают ограничения внешнего ключа в разделе «Альтернативные механизмы хранения». Не каждый механизм хранения в MySQL поддерживает внешние ключи. - Создание временных таблиц
-
Если вы создаете таблицу, используя ключевую фразу
CREATE TEMPORARY TABLE, она будет удалена (dropped) при закрытии соединения. Это полезно для копирования и переформатирования данных, поскольку вам не нужно помнить об очистке. Иногда временные таблицы также используются в качестве оптимизации для хранения некоторых промежуточных данных. - Дополнительные параметры таблицы
-
Вы можете управлять широким спектром функций таблицы с помощью параметров таблицы. К ним относятся начальное значение
AUTO_INCREMENT, способ хранения индексов и строк и параметры для переопределения информации, которую оптимизатор запросов MySQL собирает из таблицы. Также можно указать сгенерированные столбцы (generated columns), содержащие такие данные, как сумма двух других столбцов, а также индексы для таких столбцов. - Контроль над индексными структурами
-
Некоторые механизмы хранения в MySQL позволяют вам указывать и контролировать, какой тип внутренней структуры — например, B-дерево или хэш-таблица — MySQL использует для своих индексов. Вы также можете указать MySQL, что вам нужен полнотекстовый индекс или индекс пространственных данных для столбца, позволяющий выполнять специальные типы поиска.
- Разделение
-
MySQL поддерживает различные стратегии секционирования, которые вы можете выбрать во время создания таблицы или позже. Мы не будем рассматривать секционирование в этой книге.
Вы можете увидеть оператор, используемый для создания таблицы, используя оператор SHOW CREATE TABLE, представленный в главе 3. Он часто показывает вам вывод, который включает в себя некоторые из расширенных функций, которые мы только что обсуждали; вывод редко совпадает с тем, что вы на самом деле набрали для создания таблицы. Вот пример таблицы actor:
mysql> SHOW CREATE TABLE actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
Вы заметите, что выходные данные включают контент, добавленный MySQL, которого не было в нашем исходном операторе CREATE TABLE:
-
Имена таблиц и столбцов заключены в обратные кавычки. Это не обязательно, но позволяет избежать проблем с разбором, которые могут быть вызваны использованием зарезервированных слов и специальных символов, как обсуждалось ранее.
-
Включено дополнительное предложение ENGINE по умолчанию, в котором явно указывается тип таблицы, который следует использовать. Параметр установки MySQL по умолчанию — InnoDB, поэтому в этом примере он не действует.
-
Включено дополнительное предложение DEFAULT CHARSET, которое сообщает MySQL, какой набор символов используется столбцами в таблице. Опять же, это не влияет на установку по умолчанию.
Типы столбцов
В этом разделе описываются типы столбцов, которые вы можете использовать в MySQL. В нем объясняется, когда каждый из них следует использовать, и какие ограничения у него есть. Типы сгруппированы по назначению. Мы рассмотрим наиболее широко используемые типы данных и вскользь упомянем более продвинутые или менее используемые типы. Это не значит, что они бесполезны, но рассматривайте их изучение как упражнение. Скорее всего, вы не запомните каждый из типов данных и его особенности, но ничего страшного. Эту главу стоит перечитать позже и свериться с документацией по MySQL по этой теме, чтобы поддерживать свои знания в актуальном состоянии.
Целочисленные типы
Мы начнем с числовых типов данных, а точнее с целочисленных типов или типов, содержащих определенные целые числа. Во-первых, два самых популярных целочисленных типа:
INT[(width)] [UNSIGNED] [ZEROFILL]-
Это наиболее часто используемый числовой тип; он хранит целые числа в диапазоне от –2 147 483 648 до 2 147 483 647. Если добавлено необязательное ключевое слово
UNSIGNED, диапазон составляет от 0 до 4 294 967 295. Ключевое словоINTявляется сокращением отINTEGER, и они могут использоваться взаимозаменяемо. Для столбцаINTтребуется 4 байта дискового пространства.INT, как и другие целочисленные типы, имеет два свойства, специфичных для MySQL: необязательноеwidthи аргументыZEROFILL. Они не являются частью стандарта SQL и, начиная с MySQL 8.0, устарели. Тем не менее, вы наверняка заметите их во многих кодовых базах, поэтому мы кратко рассмотрим их оба.Параметр
widthуказывает ширину экрана, которую приложения могут считывать как часть метаданных столбца. В отличие от параметров в аналогичном положении для других типов данных, этот параметр не влияет на характеристики хранения конкретного целочисленного типа и не ограничивает используемый диапазон значений.INT(4)иINT(32)одинаковы для целей хранения данных.ZEROFILL— это дополнительный аргумент, который используется для заполнения слева значений нулями до длины, заданной параметром ширины. Если вы используетеZEROFILL, MySQL автоматически добавляетUNSIGNEDк объявлению (поскольку заполнение нулями имеет смысл только в контексте положительных чисел).В некоторых приложениях, где полезны
ZEROFILLиwidth, можно использовать функциюLPAD()или хранить числа в формате столбцовCHAR. BIGINT[(width)] [UNSIGNED] [ZEROFILL]-
В мире растущих объемов данных использование таблиц с количеством строк в миллиарды становится все более распространенным явлением. Даже для простых столбцов типа
idможет потребоваться более широкий диапазон, чем обеспечивает обычныйINT.BIGINTрешает эту проблему. Это большой целочисленный тип со знаком в диапазоне от –9 223 372 036 854 775 808 до 9 223 372 036 854 775 807.BIGINTбез знака может хранить числа от 0 до 18 446 744 073 709 551 615. Для столбцов этого типа потребуется 8 байт памяти.Внутри все вычисления в MySQL выполняются с использованием значений
BIGINTилиDOUBLEсо знаком. Важным следствием этого является то, что вы должны быть очень осторожны при работе с очень большими числами. Есть две проблемы, о которых следует знать. Во-первых, большие целые числа без знака, превышающие 9 223 372 036 854 775 807, следует использовать только с битовыми функциями. Во-вторых, если результат арифметической операции больше 9 223 372 036 854 775 807, могут наблюдаться неожиданные результаты.Например:
mysql> CREATE TABLE test_bigint (id BIGINT UNSIGNED); Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO test_bigint VALUES (18446744073709551615); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO test_bigint VALUES (18446744073709551615-1); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO test_bigint VALUES (184467440737095516*100); ERROR 1690 (22003): BIGINT value is out of range in '(184467440737095516 * 100)'Несмотря на то, что 18 446 744 073 709 551 600 меньше 18 446 744 073 709 551 615, поскольку для внутреннего умножения используется
BIGINTсо знаком, наблюдается ошибка выхода за диапазон.
Имейте в виду, что хотя и можно хранить каждое целое число как BIGINT, это расточительно с точки зрения места для хранения. Более того, как мы уже говорили, параметр ширины не ограничивает диапазон значений. Чтобы сэкономить место и наложить ограничения на хранимые значения, вы должны использовать разные целочисленные типы:
SMALLINT[(width)] [UNSIGNED] [ZEROFILL]-
Хранит небольшие целые числа в диапазоне от –32 768 до 32 767 со знаком и от 0 до 65 535 без знака. Занимает 2 байта памяти.
TINYINT[(width)] [UNSIGNED] [ZEROFILL]-
Наименьший числовой тип данных, хранящий еще меньшие целые числа. Диапазон этого типа составляет от –128 до 127 со знаком и от 0 до 255 без знака. Занимает всего 1 байт памяти.
BOOL[(width)]-
Сокращение от
BOOLEANи синонимTINYINT(1). Обычно логические типы принимают только два значения: true или false. Однако, посколькуBOOLв MySQL является целочисленным типом, вы можете хранить значения от –128 до 127 вBOOL. Значение 0 будет считаться ложным, а все ненулевые значения — истинными. Также можно использовать специальные истинные и ложные псевдонимы для 1 и 0 соответственно. Вот некоторые примеры:mysql> CREATE TABLE test_bool (i BOOL); Query OK, 0 rows affected (0.04 sec) mysql> INSERT INTO test_bool VALUES (true),(false); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> INSERT INTO test_bool VALUES (1),(0),(-128),(127); Query OK, 4 rows affected (0.02 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql> SELECT i, IF(i,'true','false') FROM test_bool; +------+----------------------+ | i | IF(i,'true','false') | +------+----------------------+ | 1 | true | | 0 | false | | 1 | true | | 0 | false | | -128 | true | | 127 | true | +------+----------------------+ 6 rows in set (0.01 sec) MEDIUMINT[(width)] [UNSIGNED] [ZEROFILL]-
Сохраняет значения в диапазоне от –8 388 608 до 8 388 607 со знаком и в диапазоне от 0 до 16 777 215 без знака. Занимает 3 байта памяти.
BIT[(M)]-
Специальный тип, используемый для хранения битовых значений.
Mуказывает количество битов на значение и по умолчанию равно 1, если этот аргумент опущен. MySQL использует синтаксисb'valueдля двоичных значений.
Типы с фиксированной запятой
Типы данных DECIMAL и NUMERIC в MySQL одинаковы, поэтому, хотя мы опишем здесь только DECIMAL, это описание также относится и к NUMERIC. Основное различие между типами с фиксированной и плавающей запятой заключается в точности. Для типов с фиксированной запятой извлекаемое значение идентично сохраненному значению; это не всегда относится к типам, содержащим десятичные точки, таким как типы FLOAT и DOUBLE, описанные ниже. Это наиболее важное свойство типа данных DECIMAL, который является широко используемым числовым типом в MySQL:
DECIMAL[(width[,decimals])] [UNSIGNED] [ZEROFILL]-
Хранит число с фиксированной запятой, такое как зарплата или расстояние, с общим числом разрядов
width, из которых некоторое меньшее число являетсяdecimals, следующими за десятичной запятой. Например, столбец, объявленный как ценаDECIMAL(6,2), может использоваться для хранения значений в диапазоне от –9 999,99 до 9 999,99. ценаDECIMAL(10,4)допускает такие значения, как 123 456,1234.До MySQL 5.7, если вы пытались сохранить значение за пределами этого диапазона, оно сохранялось как ближайшее значение в допустимом диапазоне. Например, 100 будет сохранено как 99,99, а –100 будет сохранено как –99,99. Однако, начиная с версии 5.7.5, режим SQL по умолчанию включает режим
STRICT_TRANS_TABLES, который запрещает это и другие небезопасные действия. Использование старого поведения возможно, но может привести к потере данных.Режимы SQL — это специальные настройки, управляющие поведением MySQL при выполнении запросов. Например, они могут ограничивать «небезопасное» поведение или влиять на интерпретацию запросов. В целях изучения MySQL мы рекомендуем вам придерживаться значений по умолчанию, поскольку они безопасны. Изменение режимов SQL может потребоваться для совместимости с устаревшими приложениями в выпусках MySQL.
Параметр
widthявляется необязательным, и если он опущен, предполагается значение 10. Количествоdecimalsтакже является необязательным, и если оно опущено, предполагается значение 0; максимальное значениеdecimalsне может превышать значениеwidth. Максимальное значениеwidth— 65, а максимальное значениеdecimals— 30.Если вы сохраняете только положительные значения, вы можете использовать ключевое слово
UNSIGNED, как описано дляINT. Если вы хотите заполнить нулями, используйте ключевое словоZEROFILLдля того же поведения, что и дляINT. Ключевое словоDECIMALимеет три идентичных взаимозаменяемых варианта:DEC,NUMERICиFIXED.Значения в столбцах
DECIMALхранятся в двоичном формате. Этот формат использует 4 байта для каждых девяти цифр.
Типы с плавающей запятой
В дополнение к типу DECIMAL с фиксированной запятой, описанному в предыдущем разделе, существуют два других типа, которые поддерживают десятичные точки: DOUBLE (также известный как REAL) и FLOAT. Они предназначены для хранения приблизительных числовых значений, а не точных значений, хранящихся в DECIMAL.
Зачем вам приблизительные значения? Ответ заключается в том, что многие числа с десятичной точкой являются приближениями реальных величин. Например, предположим, что вы зарабатываете 50 000 долларов в год и хотите хранить их как ежемесячную заработную плату. Если перевести это в месячную сумму, получится 4166 долларов плюс 66 и 2/3 цента. Если вы сохраните это как 4 166,67 доллара, этого недостаточно для преобразования в годовую заработную плату (поскольку 12, умноженное на 4 166,67 доллара, равно 50 000,04 доллара). Однако, если вы храните 2/3 с достаточным количеством знаков после запятой, это более близкое приближение. Вы обнаружите, что это достаточно точно, чтобы правильно умножить, чтобы получить исходное значение в высокоточной среде, такой как MySQL, используя только небольшое округление. Вот где полезны DOUBLE и FLOAT: они позволяют хранить такие значения, как 2/3 или число пи, с большим количеством знаков после запятой, позволяя точное приближенное представление точных величин. Позже вы можете использовать функцию ROUND() для восстановления результатов с заданной точностью.
Давайте продолжим предыдущий пример, используя DOUBLE. Предположим, вы создаете таблицу следующим образом:
mysql> CREATE TABLE wage (monthly DOUBLE);
Query OK, 0 rows affected (0.09 sec)
Теперь вы можете вставить месячную заработную плату, используя:
mysql> INSERT INTO wage VALUES (50000/12);
Query OK, 1 row affected (0.00 sec)
И посмотрите, что хранится:
mysql> SELECT * FROM wage;
+----------------+
| monthly |
+----------------+
| 4166.666666666 |
+----------------+
1 row in set (0.00 sec)
Однако, когда вы умножаете это значение, чтобы получить годовое значение, вы получаете высокоточное приближение:
mysql> SELECT monthly*12 FROM wage;
+--------------------+
| monthly*12 |
+--------------------+
| 49999.999999992004 |
+--------------------+
1 row in set (0.00 sec)
Чтобы вернуть исходное значение, вам все равно нужно выполнить округление с нужной точностью. Например, для вашего бизнеса может потребоваться точность до пяти знаков после запятой. В этом случае вы можете восстановить исходное значение с помощью:
mysql> SELECT ROUND(monthly*12,5) FROM wage;
+---------------------+
| ROUND(monthly*12,5) |
+---------------------+
| 50000.00000 |
+---------------------+
1 row in set (0.00 sec)
Но точность до восьми знаков после запятой не приведет к исходному значению:
mysql> SELECT ROUND(monthly*12,8) FROM wage;
+---------------------+
| ROUND(monthly*12,8) |
+---------------------+
| 49999.99999999 |
+---------------------+
1 row in set (0.00 sec)
Важно понимать неточный и приблизительный характер типов данных с плавающей запятой.
Вот подробности типов FLOAT и DOUBLE:
FLOAT[(width, decimals)] [UNSIGNED] [ZEROFILL]илиFLOAT[(precision)] [UNSIGNED] [ZEROFILL]-
Сохраняет числа с плавающей запятой. Имеет два необязательных синтаксиса: первый допускает необязательное количество
decimalsи необязательнуюwidthотображения, а второй допускает необязательнуюprecision, которая контролирует точность приближения, измеренного в битах. Без параметров (типичное использование) этот тип хранит небольшие 4-байтовые значения с плавающей запятой одинарной точности. Когдаprecisionнаходится в диапазоне от 0 до 24, происходит поведение по умолчанию. Когдаprecisionнаходится в диапазоне от 25 до 53, тип ведет себя какDOUBLE. Параметрwidthне влияет на то, что хранится, только на то, что отображается. ПараметрыUNSIGNEDиZEROFILLведут себя какINT. DOUBLE[(width, decimals)] [UNSIGNED] [ZEROFILL]-
Сохраняет числа с плавающей запятой. Это позволяет указать необязательное количество
decimalsи необязательнуюwidthотображения. Без параметров (типичное использование) этот тип хранит обычные 8-байтовые значения с плавающей запятой двойной точности. Параметрwidthне влияет на то, что хранится, только на то, что отображается. ПараметрыUNSIGNEDиZEROFILLведут себя какINT. ТипDOUBLEимеет два идентичных синонима:REALиDOUBLE PRECISION.
Типы строк
Строковые типы данных используются для хранения текста и, что менее очевидно, двоичных данных. MySQL поддерживает следующие типы строк:
[NATIONAL] VARCHAR(width) [CHARACTER SET charset_name] [COLLATE collation_name]-
Вероятно, это наиболее часто используемый тип строки.
VARCHARхранит строки переменной длины до максимальнойwidth. Максимальное значениеwidthсоставляет 65 535 символов. Большая часть информации, применимой к этому типу, применима и к другим типам строк.Типы
CHARиVARCHARочень похожи, но есть несколько важных отличий.VARCHARберет на себя один или два дополнительных байта служебных данных для хранения значения строки, в зависимости от того, меньше или больше значение, чем 255 байтов. Обратите внимание, что этот размер отличается от длины строки в символах, так как для некоторых символов может потребоваться до 4 байтов пространства. Тогда может показаться очевидным, чтоVARCHARменее эффективен. Однако это не всегда так. ПосколькуVARCHARможет хранить строки произвольной длины (вплоть до определеннойwidth), для более коротких строк потребуется меньше места для хранения, чем дляCHARаналогичной длины.Другое различие между
CHARиVARCHARзаключается в обработке завершающих пробелов.VARCHARсохраняет конечные пробелы до указанной ширины столбца и обрезает лишнее, выдавая предупреждение. Как будет показано позже, значенияCHARдополняются справа до ширины столбца, а конечные пробелы не сохраняются. ДляVARCHARконечные пробелы имеют значение, если они не обрезаны и будут считаться уникальными значениями. Давайте продемонстрируем:mysql> CREATE TABLE test_varchar_trailing(d VARCHAR(2) UNIQUE); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO test_varchar_trailing VALUES ('a'), ('a '); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT d, LENGTH(d) FROM test_varchar_trailing; +------+-----------+ | d | LENGTH(d) | +------+-----------+ | a | 1 | | a | 2 | +------+-----------+ 2 rows in set (0.00 sec)Вторая строка, которую мы вставили, имеет завершающий пробел, и, поскольку
widthстолбцаdравна 2, этот пробел учитывается при определении уникальности строки. Однако если мы попытаемся вставить строку с двумя завершающими пробелами:mysql> INSERT INTO test_varchar_trailing VALUES ('a '); ERROR 1062 (23000): Duplicate entry 'a ' for key 'test_varchar_trailing.d'MySQL отказывается принимать новую строку.
VARCHAR(2)неявно обрезает конечные пробелы за пределами установленнойwidth, поэтому сохраняемое значение меняется с"a "(с двойным пробелом после a) на"a "(с одинарным пробелом после a). Поскольку у нас уже есть строка с таким значением, сообщается об ошибке дублирования записи. Это поведение дляVARCHARиTEXTможно контролировать, изменив параметры сортировки столбцов. Некоторые сопоставления, такие какlatin1_bin, имеют атрибутPAD SPACE, означающий, что при извлечении они дополняются пробелами по ширинеwidth. Это не влияет на хранение, но влияет на проверки уникальности, а также на работу операторовGROUP BYиDISTINCT, которые мы обсудим в главе 5. Вы можете проверить, является ли параметр сортировкиPAD SPACEилиNO PAD, запустив командуSHOW COLLATION, как мы показали в разделе «Сопоставление и наборы символов». Давайте посмотрим на эффект в действии, создав таблицу с параметрами сортировкиPAD SPACE:mysql> CREATE TABLE test_varchar_pad_collation( -> data VARCHAR(5) CHARACTER SET latin1 -> COLLATE latin1_bin UNIQUE); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO test_varchar_pad_collation VALUES ('a'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO test_varchar_pad_collation VALUES ('a '); ERROR 1062 (23000): Duplicate entry 'a ' for key 'test_varchar_pad_collation.data'Сопоставление
NO PAD— это новое дополнение MySQL 8.0. В предыдущих выпусках MySQL, которые вы все еще можете часто видеть в использовании, каждая сортировка неявно имеет атрибутPAD SPACE. Таким образом, в MySQL 5.7 и более ранних версиях единственным вариантом сохранения конечных пробелов является использование двоичного типа:VARBINARYилиBLOB.Сортировка и сравнение типов
VARCHAR,CHARиTEXTпроисходит в соответствии с сопоставлением назначенного набора символов. Вы видите, что можно указать набор символов, а также параметры сортировки для каждого отдельного столбца строкового типа. Также можно указать двоичный набор символов, который эффективно преобразуетVARCHARвVARBINARY. Не путайте двоичную кодировку с атрибутомBINARYдля кодировки; последний является сокращением только для MySQL для указания двоичного (_bin) сопоставления.Более того, можно указать параметры сортировки непосредственно в предложении
ORDER BY. Доступные сопоставления будут зависеть от набора символов столбца. Продолжая работу с таблицейtest_varchar_pad_collation, можно сохранить там символ ä, а затем посмотреть, как сопоставления влияют на порядок строк:mysql> INSERT INTO test_varchar_pad_collation VALUES ('ä'), ('z'); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM test_varchar_pad_collation -> ORDER BY data COLLATE latin1_german1_ci; +------+ | data | +------+ | a | | ä | | z | +------+ 3 rows in set (0.00 sec) mysql> SELECT * FROM test_varchar_pad_collation -> ORDER BY data COLLATE latin1_swedish_ci; +------+ | data | +------+ | a | | z | | ä | +------+ 3 rows in set (0.00 sec)Атрибут
NATIONAL(или эквивалентная ему короткая формаNCHAR) — это стандартный способ SQL указать, что столбец строкового типа должен использовать предопределенный набор символов. MySQL используетutf8в качестве этой кодировки. Однако важно отметить, что MySQL 5.7 и 8.0 расходятся во мнениях относительно того, что такоеutf8: первая использует его как псевдоним дляutf8mb3, а вторая — дляutf8mb4. Таким образом, лучше не использовать атрибутNATIONAL, а также неоднозначные псевдонимы. Лучшая практика с любыми столбцами и данными, связанными с текстом, — быть максимально однозначными и конкретными. [NATIONAL] CHAR(width) [CHARACTER SET charset_name] [COLLATE collation_name]-
CHARхранит строку фиксированной длины (например, имя, адрес или город) длинойwidth. Еслиwidthне указана, предполагаетсяCHAR(1). Максимальное значениеwidthравно 255. Как и в случае сVARCHAR, значения в столбцахCHARвсегда сохраняются с указанной длиной. Одна буква, хранящаяся в столбцеCHAR(255), будет занимать 255 байт (в кодировкеlatin1) и будет дополнена пробелами. Заполнение удаляется при чтении данных, если не включен режим SQLPAD_CHAR_TO_FULL_LENGTH. Стоит еще раз упомянуть, что это означает, что строки, хранящиеся в столбцахCHAR, потеряют все свои конечные пробелы.В прошлом
widthстолбцаCHARчасто ассоциировалась с размером в байтах. Это не всегда так сейчас, и это определенно не так по умолчанию. Многобайтовые наборы символов, такие какutf8mb4по умолчанию в MySQL 8.0, могут привести к гораздо большим значениям. InnoDB фактически кодирует столбцы фиксированной длины как столбцы переменной длины, если их максимальный размер превышает 768 байт. Таким образом, в MySQL 8.0 InnoDB по умолчанию будет хранить столбецCHAR(255)так же, как и столбецVARCHAR. Вот пример:mysql> CREATE TABLE test_char_length( -> utf8char CHAR(10) CHARACTER SET utf8mb4 -> , asciichar CHAR(10) CHARACTER SET binary -> ); Query OK, 0 rows affected (0.04 sec) mysql> INSERT INTO test_char_length VALUES ('Plain text', 'Plain text'); Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO test_char_length VALUES ('的開源軟體', 'Plain text'); Query OK, 1 row affected (0.00 sec) mysql> SELECT LENGTH(utf8char), LENGTH(asciichar) FROM test_char_length; +------------------+-------------------+ | LENGTH(utf8char) | LENGTH(asciichar) | +------------------+-------------------+ | 10 | 10 | | 15 | 10 | +------------------+-------------------+ 2 rows in set (0.00 sec)Поскольку значения выровнены по левому краю и дополнены пробелами по правому краю, а любые конечные пробелы вообще не учитываются для
CHAR, невозможно сравнивать строки, состоящие только из пробелов. Если вы окажетесь в ситуации, в которой это важно, используйте тип данныхVARCHAR. BINARY[(width)]иVARBINARY(width)-
Эти типы очень похожи на
CHARиVARCHAR, но хранят двоичные строки. Двоичные строки имеют специальный набор двоичных символов и сопоставление, и их сортировка зависит от числовых значений байтов в хранимых значениях. Вместо строк символов хранятся строки байтов. В более раннем обсужденииVARCHARмы описали двоичную кодировку и атрибутBINARY. Только двоичная кодировка «преобразует»VARCHARилиCHARв соответствующую двоичную форму. Применение атрибутаBINARYк набору символов не изменит того факта, что строки символов сохраняются. В отличие отVARCHARиCHAR, здесьwidthравна количеству байтов. Когдаwidthне указана дляBINARY, по умолчанию она равна 1.Как и в случае с
CHAR, данные в столбцеBINARYдополняются справа. Однако, будучи двоичными данными, они дополняются нулевыми байтами, обычно записываемыми как0x00или\0.BINARYрассматривает пробел как значимый символ, а не как заполнение. Если вам нужно хранить важные для вас данные, которые могут заканчиваться нулевыми байтами, используйте типыVARBINARYилиBLOB.При работе с обоими этими типами данных важно помнить о концепции двоичных строк. Несмотря на то, что они принимают строки, они не являются синонимами типов данных, использующих текстовые строки. Например, вы не можете изменить регистр хранимых букв, так как эта концепция на самом деле не применима к двоичным данным. Это становится совершенно ясно, когда вы рассматриваете фактические сохраненные данные. Давайте посмотрим на пример:
mysql> CREATE TABLE test_binary_data ( -> d1 BINARY(16) -> , d2 VARBINARY(16) -> , d3 CHAR(16) -> , d4 VARCHAR(16) -> ); Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO test_binary_data VALUES ( -> 'something' -> , 'something' -> , 'something' -> , 'something'); Query OK, 1 row affected (0.00 sec) mysql> SELECT d1, d2, d3, d4 FROM test_binary_data; *************************** 1. row *************************** d1: 0x736F6D657468696E6700000000000000 d2: 0x736F6D657468696E67 d3: something d4: something 1 row in set (0.00 sec) mysql> SELECT UPPER(d2), UPPER(d4) FROM test_binary_data; *************************** 1. row *************************** UPPER(d2): 0x736F6D657468696E67 UPPER(d4): SOMETHING 1 row in set (0.01 sec)Обратите внимание, как клиент командной строки MySQL на самом деле показывает значения двоичных типов в шестнадцатеричном формате. Мы считаем, что это намного лучше, чем тихие преобразования, которые выполнялись до MySQL 8.0, что могло привести к недопониманию. Чтобы вернуть фактические текстовые данные, вы должны явно преобразовать двоичные данные в текст:
mysql> SELECT CAST(d1 AS CHAR) d1t, CAST(d2 AS CHAR) d2t -> FROM test_binary_data; +------------------+-----------+ | d1t | d2t | +------------------+-----------+ | something | something | +------------------+-----------+ 1 row in set (0.00 sec)Вы также можете видеть, что заполнение
BINARYбыло преобразовано в пробелы при выполнении приведения. BLOB[(width)]иTEXT[(width)] [CHARACTER SET charset_name] [COLLATE collation_name]TINYBLOBиTINYTEXT [CHARACTER SET charset_name] [COLLATE collation_name]-
Идентичны
BLOBиTEXTсоответственно, за исключением того, что можно сохранить максимум 255 байтов или символов. MEDIUMBLOBиMEDIUMTEXT [CHARACTER SET charset_name] [COLLATE collation_name]-
Идентичны
BLOBиTEXTсоответственно, за исключением того, что можно сохранить максимум 16 777 215 байтов или символов. ТипыLONGиLONG VARCHARсопоставляются с типом данныхMEDIUMTEXTдля совместимости. LONGBLOBиLONGTEXT [CHARACTER SET charset_name] [COLLATE collation_name]-
Они идентичны
BLOBиTEXTсоответственно, за исключением того, что можно хранить максимум 4 ГБ данных. Обратите внимание, что это жесткое ограничение даже в случаеLONGTEXT, поэтому количество символов в многобайтовых кодировках может быть меньше 4 294 967 295. Эффективный максимальный размер данных, которые может хранить клиент, будет ограничен объемом доступной памяти, а также значением переменнойmax_packet_size, которая по умолчанию равна 64 МБ. ENUM(value1[,value2[, ...]]) [CHARACTER SET charset_name] [COLLATE collation_name]-
Этот тип хранит список или перечисление (enumeration) строковых значений. Для столбца типа
ENUMможно задать значение из спискаvalue1,value2и т. д., максимум до 65 535 различных значений. Хотя значения хранятся и извлекаются в виде строк, в базе данных хранится целочисленное представление. СтолбецENUMможет содержать значенияNULL(сохраненные какNULL), пустую строку''(сохраненную как0) или любые допустимые элементы (сохраненные как1,2,3и т. д.). Вы можете предотвратить принятие значенийNULL, объявив столбец какNOT NULLпри создании таблицы.Этот тип предлагает компактный способ хранения значений из списка предопределенных значений, таких как названия штатов или стран. Рассмотрим этот пример, используя названия фруктов; имя может быть любым из предопределенных значений
Apple,OrangeилиPear(в дополнение кNULLи пустой строке):mysql> CREATE TABLE fruits_enum -> (fruit_name ENUM('Apple', 'Orange', 'Pear')); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO fruits_enum VALUES ('Apple'); Query OK, 1 row affected (0.00 sec)Если вы попытаетесь вставить значение, которого нет в списке, MySQL выдаст ошибку, чтобы сообщить вам, что он не сохранил запрошенные вами данные:
mysql> INSERT INTO fruits_enum VALUES ('Banana'); ERROR 1265 (01000): Data truncated for column 'fruit_name' at row 1Также не принимается список из нескольких допустимых значений:
mysql> INSERT INTO fruits_enum VALUES ('Apple,Orange'); ERROR 1265 (01000): Data truncated for column 'fruit_name' at row 1Отобразив содержимое таблицы, можно увидеть, что недопустимые значения не сохранились:
mysql> SELECT * FROM fruits_enum; +------------+ | fruit_name | +------------+ | Apple | +------------+ 1 row in set (0.00 sec)Более ранние версии MySQL выдавали предупреждение вместо ошибки и сохраняли пустую строку вместо недопустимого значения. Это поведение можно включить, отключив строгий режим SQL по умолчанию. Также можно указать значение по умолчанию, отличное от пустой строки:
mysql> CREATE TABLE new_fruits_enum -> (fruit_name ENUM('Apple', 'Orange', 'Pear') -> DEFAULT 'Pear'); Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO new_fruits_enum VALUES(); Query OK, 1 row affected (0.02 sec) mysql> SELECT * FROM new_fruits_enum; +------------+ | fruit_name | +------------+ | Pear | +------------+ 1 row in set (0.00 sec)Здесь не указание значения приводит к сохранению значения по умолчанию
Pear. SET( value1 [, value2 [, ...]]) [CHARACTER SET charset_name] [COLLATE collation_name]-
Этот тип хранит набор строковых значений. Столбец типа
SETможет содержать ноль или более значений из спискаvalue1,value2и т. д., максимум до 64 различных значений. Хотя значения являются строками, то, что хранится в базе данных, представляет собой целочисленное представление. SET отличается от ENUM тем, что каждая строка может хранить только одно значение ENUM в столбце, но может хранить несколько значений SET. Этот тип полезен для хранения выбора вариантов из списка, например пользовательских настроек. Рассмотрим этот пример, используя названия фруктов; имя может быть любой комбинацией предопределенных значений:mysql> CREATE TABLE fruits_set -> ( fruit_name SET('Apple', 'Orange', 'Pear') ); Query OK, 0 rows affected (0.08 sec) mysql> INSERT INTO fruits_set VALUES ('Apple'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO fruits_set VALUES ('Banana'); ERROR 1265 (01000): Data truncated for column 'fruit_name' at row 1 mysql> INSERT INTO fruits_set VALUES ('Apple,Orange'); Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM fruits_set; +--------------+ | fruit_name | +--------------+ | Apple | | Apple,Orange | +--------------+ 2 rows in set (0.00 sec)Опять же, обратите внимание, что мы можем хранить несколько значений из набора в одном поле и что пустая строка сохраняется для недопустимого ввода.
BLOB и TEXT обычно используются для хранения больших данных. Вы можете думать о BLOB как о VARBINARY, содержащей столько данных, сколько вам нужно, и то же самое для TEXT и VARCHAR. Типы BLOB и TEXT могут хранить до 65 535 байтов или символов соответственно. Как обычно, обратите внимание, что существуют многобайтовые кодировки. Атрибут width является необязательным, и когда он указан, MySQL фактически изменит тип данных BLOB или TEXT на любой наименьший тип, способный хранить такое количество данных. Например, BLOB(128) приведет к использованию TINYBLOB:
mysql> CREATE TABLE test_blob(data BLOB(128));
Query OK, 0 rows affected (0.07 sec)
mysql> DESC test_blob;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| data | tinyblob | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
1 row in set (0.00 sec)
Для типа BLOB и родственных типов данные обрабатываются точно так же, как и в случае VARBINARY. То есть набор символов не предполагается, а сравнение и сортировка основаны на числовых значениях фактически сохраненных байтов. Для TEXT вы можете точно указать желаемую кодировку и сопоставление. Для обоих типов и их вариантов при INSERT не выполняется заполнение, а при SELECT не выполняется обрезка, что делает их идеальными для хранения данных в том виде, в котором они есть. Кроме того, предложение DEFAULT не разрешено, и когда индекс создается для столбца BLOB или TEXT, необходимо определить префикс, ограничивающий длину индексируемых значений. Подробнее об этом мы поговорим в разделе «Ключи и индексы».
Одно потенциальное различие между BLOB и TEXT заключается в их обработке конечных пробелов. Как мы уже показали, VARCHAR и TEXT могут дополнять строки в зависимости от используемой сортировки. BLOB и VARBINARY используют двоичный набор символов с одной двоичной сортировкой без заполнения и невосприимчивы к путанице сортировки и связанным с этим проблемам. Иногда может быть хорошим выбором использовать эти типы для дополнительной безопасности. Кроме того, до MySQL 8.0 это были единственные типы, которые сохраняли конечные пробелы.
Как и в случае с числовыми типами, мы рекомендуем всегда выбирать наименьший возможный тип для хранения значений. Например, если вы сохраняете название города, используйте тип CHAR или VARCHAR, а не, скажем, тип TEXT. Наличие более коротких столбцов помогает уменьшить размер таблицы, что, в свою очередь, повышает производительность, когда серверу приходится выполнять поиск в таблице.
Использование фиксированного размера с типом CHAR часто быстрее, чем использование переменного размера с VARCHAR, поскольку сервер MySQL знает, где начинается и заканчивается каждая строка, и может быстро пропустить строки, чтобы найти ту, которая ему нужна. Однако с полями фиксированной длины любое неиспользуемое пространство тратится впустую. Например, если вы разрешаете использовать до 40 символов в названии города, то CHAR(40) всегда будет использовать 40 символов, независимо от того, насколько длинным является название города. Если вы объявите название города как VARCHAR(40), то вы израсходуете ровно столько места, сколько вам нужно, плюс 1 байт для хранения длины имени. Если среднее название города состоит из 10 символов, это означает, что использование поля переменной длины займет в среднем на 29 байт меньше на запись. Это может иметь большое значение, если вы храните миллионы адресов.
В общем, если место для хранения дорого или вы ожидаете большие различия в длине строк, которые должны быть сохранены, используйте поле переменной длины; если производительность является приоритетом, используйте поле фиксированной длины.
Типы даты и времени
Эти типы служат для хранения определенных меток времени, дат или диапазонов времени. Особое внимание следует уделить работе с часовыми поясами. Мы постараемся объяснить детали, но этот раздел и документацию стоит перечитать позже, когда вам действительно понадобится работать с часовыми поясами. Типы даты и времени в MySQL:
DATE-
Сохраняет и отображает дату в формате
YYYY-MM-DDдля диапазона от 1000-01-01 до 9999-12-31. Даты всегда должны вводиться в виде тройки год, месяц, день, но формат ввода может варьироваться, как показано в следующих примерах:YYYY-MM-DD or YY-MM-DD- Можно указывать год с двумя или с четырьмя цифрами. Мы настоятельно рекомендуем вам использовать четырехзначную версию, чтобы избежать путаницы с веком. На практике, если вы используете двузначную версию, вы обнаружите, что от 70 до 99 интерпретируются как от 1970 до 1999, а от 00 до 69 интерпретируются как от 2000 до 2069.
YYYY/MM/DD, YYYY:MM:DD, YY-MM-DD, или другие форматы с пунктуацией- MySQL позволяет использовать любые знаки препинания для разделения компонентов даты. Мы рекомендуем использовать тире и, опять же, избегать двузначных чисел года.
YYYY-M-D, YYYY-MM-D, or YYYY-M-DD- Когда используется пунктуация (опять же, разрешены любые знаки препинания), дни и месяцы могут быть указаны как таковые. Например, 2 февраля 2006 г. можно указать как
2006-2-2. Двузначные эквиваленты года доступны, но не рекомендуются.
YYYYMMDD or YYMMDD- Пунктуация может быть опущена в обоих стилях даты, но последовательность цифр должна состоять из шести или восьми цифр.
Вы также можете ввести дату, указав дату и время в форматах, описанных ниже для
DATETIMEиTIMESTAMP, но в столбцеDATEхранится только компонент даты. Независимо от типа ввода, тип хранения и отображения всегдаYYYY-MM-DD. Нулевая дата0000-00-00разрешена во всех версиях и может использоваться для представления неизвестного или фиктивного значения. Если введенная дата выходит за пределы допустимого диапазона, сохраняется нулевая дата. Однако только версии MySQL до 5.6 включительно позволяют это по умолчанию. И 5.7, и 8.0 по умолчанию устанавливают режимы SQL, запрещающие такое поведение:STRICT_TRANS_TABLES,NO_ZERO_DATEиNO_ZERO_IN_DATE.Если вы используете более старую версию MySQL, мы рекомендуем вам добавить эти режимы в текущий сеанс:
mysql> SET sql_mode=CONCAT(@@sql_mode, -> ',STRICT_TRANS_TABLES', -> ',NO_ZERO_DATE', ',NO_ZERO_IN_DATE');Вот несколько примеров вставки дат на сервере MySQL 8.0 с настройками по умолчанию:
mysql> CREATE TABLE testdate (mydate DATE); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO testdate VALUES ('2020/02/0'); ERROR 1292 (22007): Incorrect date value: '2020/02/0' for column 'mydate' at row 1 mysql> INSERT INTO testdate VALUES ('2020/02/1'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO testdate VALUES ('2020/02/31'); ERROR 1292 (22007): Incorrect date value: '2020/02/31' for column 'mydate' at row 1 mysql> INSERT INTO testdate VALUES ('2020/02/100'); ERROR 1292 (22007): Incorrect date value: '2020/02/100' for column 'mydate' at row 1После выполнения операторов
INSERTв таблице будут следующие данные:mysql> SELECT * FROM testdate; +------------+ | mydate | +------------+ | 2020-02-01 | +------------+ 1 row in set (0.00 sec)MySQL защитил вас от «плохих» данных, хранящихся в вашей таблице. Иногда вам может понадобиться сохранить фактический ввод и вручную обработать его позже. Вы можете сделать это, удалив вышеупомянутые режимы SQL из списка режимов в переменной
sql_mode. В этом случае после выполнения предыдущих операторовINSERTвы получите следующие данные:mysql> SELECT * FROM testdate; +------------+ | mydate | +------------+ | 2020-02-00 | | 2020-02-01 | | 0000-00-00 | | 0000-00-00 | +------------+ 4 rows in set (0.01 sec)Еще раз обратите внимание, что дата отображается в формате
YYYY-MM-DD, независимо от того, как она была введена. TIME [fraction]-
Сохраняет время в формате
HHH:MM:SSв диапазоне от –838:59:59 до 838:59:59. Это полезно для хранения продолжительности некоторых действий. Значения, которые можно сохранить, находятся за пределами диапазона 24-часового формата, что позволяет вычислять и сохранять большие различия между значениями времени (до 34 дней, 22 часов, 59 минут и 59 секунд).fractionвTIMEи других связанных типах данных задает точность долей секунды в диапазоне от 0 до 6. Значение по умолчанию равно 0, что означает, что дробные секунды не сохраняются.Время всегда необходимо вводить в порядке дни, часы, минуты, секунды, используя следующие форматы:
DD HH:MM:SS[.fraction], HH:MM:SS[.fraction], DD HH:MM, HH:MM, DD HH, илиSS[.fraction]-
DDпредставляет собой однозначное или двузначное значение дней в диапазоне от 0 до 34. ЗначениеDDотделяется от значения часа,HH, пробелом, а остальные компоненты разделяются двоеточием. Обратите внимание, чтоMM:SSне является допустимой комбинацией, так как ее нельзя отличить отHH:MM. Если в определенииTIMEне указанаfractionили установлено значение 0, вставка доли секунды приведет к округлению значений до ближайшей секунды.Например, если вы вставите
2 13:25:58.999999в столбецTIMEсfraction0, значение61:25:59будет сохранено, поскольку сумма 2 дня (48 часов) и 13 часов составляет 61 час. Начиная с MySQL 5.7, установленный по умолчанию режим SQL запрещает вставку неправильных значений. Однако можно включить старое поведение. Затем, если вы попытаетесь вставить значение, выходящее за пределы, будет сгенерировано предупреждение, и значение будет ограничено максимальным доступным временем. Точно так же, если вы попытаетесь вставить недопустимое значение, генерируется предупреждение, и значение устанавливается равным нулю. Вы можете использовать командуSHOW WARNINGS, чтобы сообщить подробности предупреждения, сгенерированного предыдущим оператором SQL. Мы рекомендуем придерживаться строгого режима SQL по умолчанию. В отличие от типаDATE, по-видимому, нет смысла разрешать неверные записиTIME, помимо упрощения управления ошибками на стороне приложения и поддержания устаревшего поведения.Давайте попробуем все это на практике:
mysql> CREATE TABLE test_time(id SMALLINT, mytime TIME); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO test_time VALUES(1, "2 13:25:59"); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO test_time VALUES(2, "35 13:25:59"); ERROR 1292 (22007): Incorrect time value: '35 13:25:59' for column 'mytime' at row 1 mysql> INSERT INTO test_time VALUES(3, "900.32"); Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM test_time; +------+----------+ | id | mytime | +------+----------+ | 1 | 61:25:59 | | 3 | 00:09:00 | +------+----------+ 2 rows in set (0.00 sec) H:M:S, а также одно-, двух- и трехзначные комбинации-
Вы можете использовать различные комбинации цифр при вставке или обновлении данных; MySQL преобразует их во внутренний формат времени и последовательно отображает. Например,
1:1:3эквивалентно01:01:03. Разное количество цифр можно смешивать; например,1:12:3эквивалентно01:12:03. Рассмотрим эти примеры:mysql> CREATE TABLE mytime (testtime TIME); Query OK, 0 rows affected (0.12 sec) mysql> INSERT INTO mytime VALUES -> ('-1:1:1'), ('1:1:1'), -> ('1:23:45'), ('123:4:5'), -> ('123:45:6'), ('-123:45:6'); Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM mytime; +------------+ | testtime | +------------+ | -01:01:01 | | 01:01:01 | | 01:23:45 | | 123:04:05 | | 123:45:06 | | -123:45:06 | +------------+ 5 rows in set (0.01 sec)Обратите внимание, что часы отображаются двумя цифрами для значений в диапазоне от –99 до 99.
HHMMSS, MMSS, иSS-
Знаки препинания можно опустить, но последовательность цифр должна состоять из двух, четырех или шести цифр. Обратите внимание, что крайняя правая пара цифр всегда интерпретируется как значение
SS(секунды), вторая крайняя правая пара (если присутствует) какMM(минуты), а третья крайняя правая пара (если присутствует) какHH(часы). В результате такое значение, как1222, интерпретируется как 12 минут и 22 секунды, а не как 12 часов и 22 минуты.Вы также можете ввести время, указав дату и время в форматах, описанных для
DATETIMEиTIMESTAMP, но в столбцеTIMEсохраняется только компонент времени. Независимо от типа ввода, тип хранения и отображения всегдаHH:MM:SS. Нулевое время00:00:00может использоваться для представления неизвестного или фиктивного значения.
TIMESTAMP[(fraction)]-
Сохраняет и отображает пару даты и времени в формате
YYYY-MM-DD HH:MM:SS[.fraction][time zone offset]для диапазона от1970-01-01 00:00:01.000000до2038-01-19 03:14:07.999999. Этот тип очень похож на типDATETIME, но есть несколько отличий. Оба типа принимают модификатор часового пояса для входного значения MySQL 8.0, и оба типа будут хранить и представлять данные одинаково любому клиенту в том же часовом поясе. Однако значения в столбцахTIMESTAMPвнутренне всегда хранятся в часовом поясе UTC, что позволяет автоматически получать локальный часовой пояс для клиентов в разных часовых поясах. Это само по себе является очень важным различием, о котором следует помнить. Возможно,TIMESTAMPудобнее использовать при работе с разными часовыми поясами.До MySQL 5.6 только тип
TIMESTAMPподдерживал автоматическую инициализацию и обновление. Более того, это мог сделать только один такой столбец в данной таблице. Однако, начиная с версии 5.6, иTIMESTAMP, иDATETIMEподдерживают поведение, и это может делать любое количество столбцов.Значения, хранящиеся в столбце
TIMESTAMP, всегда соответствуют шаблонуYYYY-MM-DD HH:MM:SS[.fraction][time zone offset], но значения могут быть предоставлены в широком диапазоне форматов:YYYY-MM-DD HH:MM:SSилиYY-MM-DD HH:MM:SS- Компоненты даты и времени подчиняются тем же смягченным ограничениям, что и компоненты
DATEиTIME, описанные ранее. Это включает в себя допустимость любых знаков препинания, включая (в отличие отTIME) гибкость пунктуации, используемой в компоненте времени. Например,0– допустимо. YYYYMMDDHHMMSSилиYYMMDDHHMMSS- Знаки препинания можно не ставить, но длина строки должна быть 12 или 14 цифр. Мы рекомендуем использовать только однозначную 14-значную версию по причинам, описанным для типа
DATE. Вы можете указать значения другой длины без разделителей, но мы не рекомендуем этого делать.
Рассмотрим подробнее функцию автоматического обновления. Вы контролируете это, добавляя следующие атрибуты в определение столбца при создании таблицы или позже, как мы объясним в разделе «Изменение структур»:
-
Если вы хотите, чтобы метка времени устанавливалась только при вставке новой строки в таблицу, добавьте
DEFAULT CURRENT_TIMESTAMPв конец объявления столбца. -
Если вам не нужна отметка времени по умолчанию, но вы хотите, чтобы текущее время использовалось при каждом обновлении данных в строке, добавьте
ON UPDATE CURRENT_TIMESTAMPв конец объявления столбца. -
Если вам нужны оба вышеперечисленных пункта, то есть вы хотите, чтобы отметка времени устанавливалась на текущее время в каждой новой строке и всякий раз, когда изменяется существующая строка, добавьте
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMPв конец объявления столбца.
Если вы не укажете DEFAULT NULL или NULL для столбца TIMESTAMP, он будет иметь 0 в качестве значения по умолчанию.
YEAR[(4)]-
Сохраняет четырехзначный год в диапазоне от 1901 до 2155, а также нулевой год, 0000. Недопустимые значения преобразуются в нулевой год. Вы можете вводить значения года в виде строк (например,
'2005') или целых чисел (например,2005). Для типаYEARтребуется 1 байт дискового пространства.В более ранних версиях MySQL можно было указать параметр
digits, передав либо2, либо4. Двухзначная версия хранила значения от 70 до 69, представляющие 1970–2069 годы. MySQL 8.0 не поддерживает двузначный типYEAR, а указание параметраdigitsдля целей отображения устарело. DATETIME[(fraction)]-
Сохраняет и отображает пару даты и времени в формате
YYYY-MM-DD HH:MM:SS[.fraction][time zone offset]для диапазона от1000-01-01 00:00:00 до 9999-12-31 23:59:59. Что касаетсяTIMESTAMP, сохраняемое значение всегда соответствует шаблонуYYYY-MM-DD HH:MM:SS, но значение можно вводить в тех же форматах, которые указаны в описанииTIMESTAMP. Если вы назначаете только дату столбцуDATETIME, предполагается нулевое время00:00:00. Если вы назначаете только время столбцуDATETIME, предполагается нулевая дата0000-00-00. Этот тип имеет те же функции автоматического обновления, что иTIMESTAMP. Если для столбцаDATETIMEне указан атрибутNOT NULL, по умолчанию используется значениеNULL; в противном случае по умолчанию используется значение0. В отличие отTIMESTAMP, значенияDATETIMEне преобразуются в часовой пояс UTC для хранения.
Другие типы
В настоящее время, начиная с MySQL 8.0, пространственные типы данных и типы данных JSON подпадают под эту широкую категорию. Их использование — довольно сложная тема, и мы не будем подробно их рассматривать.
Типы пространственных данных связаны с хранением геометрических объектов, а в MySQL есть типы, соответствующие классам OpenGIS. Работа с этими типами — тема, достойная отдельной книги.
Тип данных JSON обеспечивает встроенное хранилище действительных документов JSON. До MySQL 5.7 JSON обычно хранился в столбце TEXT или аналогичном столбце. Однако у этого есть много недостатков: например, документы не проверяются и не выполняется оптимизация хранилища (весь JSON просто хранится в текстовом виде). С собственным типом JSON он хранится в двоичном формате. Если бы мы резюмировали одним предложением: используйте тип данных JSON для JSON, дорогой читатель.
Ключи и индексы
Вы обнаружите, что почти все используемые вами таблицы будут иметь предложение PRIMARY KEY, объявленное в операторе CREATE TABLE, а иногда и несколько предложений KEY. Причины, по которым вам нужны первичный ключ и вторичные ключи, обсуждались в главе 2. В этом разделе обсуждается, как объявляются первичные ключи, что происходит за кулисами, когда вы это делаете, и почему вы, возможно, захотите также создать другие ключи и индексы для ваших данных.
Первичный ключ (primary key) однозначно идентифицирует каждую строку в таблице. Что еще более важно, для механизма хранения InnoDB по умолчанию первичный ключ также используется в качестве кластеризованного индекса (clustered index). Это означает, что все фактические данные таблицы хранятся в структуре индекса. Это отличается от MyISAM, который хранит данные и индексы отдельно. Когда таблица использует кластеризованный индекс, она называется кластеризованной таблицей. Как мы уже говорили, в кластеризованной таблице каждая строка хранится в индексе, а не в том, что обычно называется кучей (heap). Кластеризация таблицы приводит к тому, что ее строки сортируются в соответствии с порядком кластеризованного индекса и фактически физически сохраняются на листовых страницах этого индекса. Для каждой таблицы не может быть более одного кластеризованного индекса. Для таких таблиц вторичные индексы ссылаются на записи в кластеризованном индексе, а не на фактические строки таблицы. Как правило, это приводит к повышению производительности запросов, хотя может отрицательно сказаться на записи. InnoDB не позволяет выбирать между кластеризованными и некластеризованными таблицами; это дизайнерское решение, которое вы не можете изменить.
Первичные ключи, как правило, являются рекомендуемой частью любой структуры базы данных, но для InnoDB они необходимы. На самом деле, если вы не укажете предложение PRIMARY KEY при создании таблицы InnoDB, MySQL будет использовать первый столбец UNIQUE NOT NULL в качестве основы для кластеризованного индекса. Если такой столбец недоступен, создается скрытый кластеризованный индекс на основе значений ID, присвоенных InnoDB каждой строке.
Учитывая, что InnoDB является механизмом хранения MySQL по умолчанию и стандартом де-факто в настоящее время, мы сосредоточимся на его поведении в этой главе. Альтернативные механизмы хранения, такие как MyISAM, MEMORY или MyRocks, будут обсуждаться в разделе «Альтернативные механизмы хранения».
Как упоминалось ранее, когда первичный ключ определен, он становится кластеризованным индексом, и все данные в таблице хранятся в листовых блоках этого индекса. InnoDB использует индексы B-дерева (точнее, вариант B+tree), за исключением индексов пространственных типов данных, которые используют структуру R-дерева. Другие механизмы хранения могут реализовывать другие типы индексов, но если механизм хранения таблицы не указан, можно предположить, что все индексы являются B-деревьями.
Наличие кластеризованного индекса или, другими словами, таблиц, организованных по индексу, ускоряет выполнение запросов и сортировку с использованием столбцов первичного ключа. Однако недостатком является дороговизна изменения столбцов в первичном ключе. Таким образом, хороший дизайн потребует первичного ключа на основе столбцов, которые часто используются для фильтрации в запросах, но редко изменяются. Помните, что полное отсутствие первичного ключа приведет к тому, что InnoDB будет использовать неявный индекс кластера; таким образом, если вы не уверены, какие столбцы выбрать для первичного ключа, рассмотрите возможность использования столбца, подобного синтетическому идентификатору. Например, в этом случае хорошо подойдет тип данных SERIAL.
Отойдя от внутренних деталей InnoDB, когда вы объявляете первичный ключ для таблицы в MySQL, создается структура, в которой хранится информация о том, где хранятся данные из каждой строки в таблице. Эта информация называется индексом, и ее цель — ускорить поиск, использующий первичный ключ. Например, когда вы объявляете PRIMARY KEY (actor_id) в таблице actor в базе данных sakila, MySQL создает структуру, которая позволяет очень быстро находить строки, соответствующие определенному actor_id (или диапазону идентификаторов).
Это полезно, например, для сопоставления актеров с фильмами или фильмов с категориями. Вы можете отобразить индексы, доступные в таблице, с помощью команды SHOW INDEX (или SHOW INDEXES):
mysql> SHOW INDEX FROM category\G
*************************** 1. row ***************************
Table: category
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: category_id
Collation: A
Cardinality: 16
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.00 sec)
Кардинальность (cardinality) — это количество уникальных значений в индексе; для индекса по первичному ключу это то же самое, что и количество строк в таблице.
Обратите внимание, что все столбцы, являющиеся частью первичного ключа, должны быть объявлены как NOT NULL, поскольку они должны иметь значение, чтобы строка была действительной. Без индекса единственный способ найти строки в таблице — прочитать каждую с диска и проверить, соответствует ли она искомому category_id. Для таблиц с большим количеством строк такой исчерпывающий последовательный поиск выполняется очень медленно. Однако вы не можете просто проиндексировать все; мы вернемся к этому вопросу в конце этого раздела.
Вы можете создать другие индексы для данных в таблице. Вы делаете это для того, чтобы другие поиски (в других столбцах или комбинациях столбцов) выполнялись быстро и чтобы избежать последовательного сканирования. Например, снова возьмем таблицу actor. Помимо первичного ключа на actor_id, у него также есть вторичный ключ на last_name для улучшения поиска по фамилии актера:
mysql> SHOW CREATE TABLE actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
...
`last_name` varchar(45) NOT NULL,
...
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ...
1 row in set (0.00 sec)
Вы можете видеть, что ключевое слово KEY используется, чтобы сообщить MySQL, что необходим дополнительный индекс. В качестве альтернативы вы можете использовать слово INDEX вместо KEY. За этим ключевым словом следует имя индекса, а затем индексируемый столбец заключен в круглые скобки. Вы также можете добавлять индексы после того, как таблицы созданы — фактически, вы можете практически что-либо изменить в таблице после ее создания. Это обсуждается в разделе «Изменение структур».
Вы можете построить индекс более чем по одному столбцу. Например, рассмотрим следующую таблицу, которая является модифицированной таблицей от sakila:
mysql> CREATE TABLE customer_mod (
-> customer_id smallint unsigned NOT NULL AUTO_INCREMENT,
-> first_name varchar(45) NOT NULL,
-> last_name varchar(45) NOT NULL,
-> email varchar(50) DEFAULT NULL,
-> PRIMARY KEY (customer_id),
-> KEY idx_names_email (first_name, last_name, email));
Query OK, 0 rows affected (0.06 sec)
Вы можете видеть, что мы добавили индекс первичного ключа в столбец идентификатора customer_id, а также добавили еще один индекс, называемый idx_names_email, который включает столбцы first_name, last_name и email в указанном порядке. Давайте теперь рассмотрим, как вы можете использовать этот дополнительный индекс.
Вы можете использовать индекс idx_names_email для быстрого поиска по комбинациям трех столбцов имени. Например, это полезно в следующем запросе:
mysql> SELECT * FROM customer_mod WHERE
-> first_name = 'Rose' AND
-> last_name = 'Williams' AND
-> email = 'rose.w@nonexistent.edu';
Мы знаем, что это помогает поиску, потому что все столбцы, перечисленные в индексе, используются в запросе. Вы можете использовать оператор EXPLAIN, чтобы проверить, действительно ли происходит то, что, по вашему мнению, должно произойти:
mysql> EXPLAIN SELECT * FROM customer_mod WHERE
-> first_name = 'Rose' AND
-> last_name = 'Williams' AND
-> email = 'rose.w@nonexistent.edu'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer_mod
partitions: NULL
type: ref
possible_keys: idx_names_email
key: idx_names_email
key_len: 567
ref: const,const,const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
Вы можете видеть, что MySQL сообщает, что possible_keys — это idx_names_email (это означает, что индекс может быть использован для этого запроса) и что ключ, который было решено использовать, — это idx_names_email. Итак, то, что вы ожидаете, и то, что происходит, совпадают, и это хорошая новость! Вы узнаете больше об операторе EXPLAIN в главе 7.
Созданный нами индекс также полезен для запросов только по столбцу first_name. Например, его можно использовать в следующем запросе:
mysql> SELECT * FROM customer_mod WHERE
-> first_name = 'Rose';
Вы можете снова использовать EXPLAIN, чтобы проверить, используется ли индекс. Причина, по которой его можно использовать, заключается в том, что столбец first_name является первым в индексе. На практике это означает, что индекс группирует или хранит вместе информацию о строках для всех людей с одинаковым именем, и поэтому индекс можно использовать для поиска любого человека с совпадающим именем.
Индекс можно также использовать для поиска, включающего комбинации имени и фамилии, точно по тем же причинам, которые мы только что обсуждали. Индекс группирует людей с одинаковыми именами и группирует людей с одинаковыми именами по фамилиям. Итак, его можно использовать для этого запроса:
mysql> SELECT * FROM customer_mod WHERE
-> first_name = 'Rose' AND
-> last_name = 'Williams';
Однако индекс нельзя использовать для этого запроса, так как крайний левый столбец индекса, first_name, не отображается в запросе:
mysql> SELECT * FROM customer_mod WHERE
-> last_name = 'Williams' AND
-> email = 'rose.w@nonexistent.edu';
Индекс должен помочь сузить набор строк до меньшего набора возможных ответов. Чтобы MySQL мог использовать индекс, запрос должен соответствовать обоим следующим условиям:
-
Крайний левый столбец, указанный в предложении
KEY(илиPRIMARY KEY), должен быть в запросе. -
Запрос не должен содержать предложений
ORдля неиндексированных столбцов.
Опять же, вы всегда можете использовать оператор EXPLAIN, чтобы проверить, можно ли использовать индекс для конкретного запроса.
Прежде чем мы закончим этот раздел, вот несколько идей о том, как выбирать и разрабатывать индексы. Когда вы планируете добавить индекс, подумайте о следующем:
-
Индексы требуют места на диске, и их необходимо обновлять при каждом изменении данных. Если ваши данные часто меняются или изменяется много данных, когда вы вносите изменения, индексы замедлят процесс. Однако на практике, поскольку операторы
SELECT(чтение данных) обычно встречаются гораздо чаще, чем другие операторы (модификации данных), индексы обычно выгодны. -
Добавляйте только тот индекс, который будет часто использоваться. Не утруждайте себя индексированием столбцов, пока не увидите, какие запросы нужны вашим пользователям и вашим приложениям. Вы всегда можете добавить индексы позже.
-
Если все столбцы в индексе используются во всех запросах, перечислите столбец с наибольшим количеством дубликатов слева от предложения
KEY. Это минимизирует размер индекса. -
Чем меньше индекс, тем быстрее это будет. Если вы индексируете большие столбцы, вы получите больший индекс. Это хорошая причина для того, чтобы ваши столбцы были как можно меньше, когда вы проектируете свои таблицы.
-
Для длинных столбцов вы можете использовать только префикс значений из столбца для создания индекса. Вы можете сделать это, добавив значение в круглых скобках после определения столбца, например
KEY idx_names_email (first_name(3), last_name(2), email(10)). Это означает, что индексируются только первые 3 символаfirst_name, затем первые 2 символаlast_name, а затем 10 символов изemail. Это значительная экономия по сравнению с индексацией 140 символов из трех столбцов! Когда вы сделаете это, ваш индекс будет менее способен однозначно идентифицировать строки, но он будет намного меньше и все еще будет достаточно хорошо находить совпадающие строки. Использование префикса обязательно для длинных типов, таких какTEXT.
Чтобы завершить этот раздел, нам нужно обсудить некоторые особенности, касающиеся вторичных ключей в InnoDB. Помните, что все данные таблицы хранятся в листьях кластеризованного индекса. Это означает, что, используя пример с actor, если нам нужно получить данные first_name при фильтрации по last_name, даже если мы можем использовать idx_actor_last_name для быстрой фильтрации, нам нужно будет получить доступ к данным по первичному ключу. Как следствие, каждый вторичный ключ в InnoDB имеет все столбцы первичного ключа, неявно добавленные к его определению. Таким образом, наличие излишне длинных первичных ключей в InnoDB приводит к значительному раздуванию вторичных ключей.
Это также можно увидеть в выводе EXPLAIN (обратите внимание на Extra: Using index в первом выводе первой команды):
mysql> EXPLAIN SELECT actor_id, last_name FROM actor WHERE last_name = 'Smith'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 182
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT first_name FROM actor WHERE last_name = 'Smith'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len: 182
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
По сути, idx_actor_last_name является покрывающим индексом (covering index) для первого запроса, а это означает, что InnoDB может извлечь все необходимые данные только из этого индекса. Однако для второго запроса InnoDB придется выполнить дополнительный поиск кластеризованного индекса, чтобы получить значение для столбца first_name.
Функция AUTO_INCREMENT
Собственная функция MySQL AUTO_INCREMENT позволяет вам создать уникальный идентификатор для строки без выполнения запроса SELECT. Вот как это работает. Возьмем снова упрощенную таблицу actor:
mysql> CREATE TABLE actor (
-> actor_id smallint unsigned NOT NULL AUTO_INCREMENT,
-> first_name varchar(45) NOT NULL,
-> last_name varchar(45) NOT NULL,
-> PRIMARY KEY (actor_id)
-> );
Query OK, 0 rows affected (0.03 sec)
В эту таблицу можно вставлять строки без указания actor_id:
mysql> INSERT INTO actor VALUES (NULL, 'Alexander', 'Kaidanovsky');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO actor VALUES (NULL, 'Anatoly', 'Solonitsyn');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO actor VALUES (NULL, 'Nikolai', 'Grinko');
Query OK, 1 row affected (0.00 sec)
Когда вы просматриваете данные в этой таблице, вы можете видеть, что каждая строка имеет значение, присвоенное столбцу actor_id:
mysql> SELECT * FROM actor;
+----------+------------+-------------+
| actor_id | first_name | last_name |
+----------+------------+-------------+
| 1 | Alexander | Kaidanovsky |
| 2 | Anatoly | Solonitsyn |
| 3 | Nikolai | Grinko |
+----------+------------+-------------+
3 rows in set (0.00 sec)
Каждый раз, когда вставляется новая строка, для этой новой строки создается уникальное значение столбца actor_id.
Рассмотрим, как работает эта функция. Вы можете видеть, что столбец actor_id объявлен как целое число с предложениями NOT NULL AUTO_INCREMENT. AUTO_INCREMENT сообщает MySQL, что, когда значение для этого столбца не указано, выделенное значение должно быть на единицу больше, чем максимальное значение, хранящееся в настоящее время в таблице. Последовательность AUTO_INCREMENT начинается с 1 для пустой таблицы.
Предложение NOT NULL требуется для столбцов AUTO_INCREMENT; когда вы вставляете NULL (или 0, хотя это не рекомендуется), сервер MySQL автоматически находит следующий доступный идентификатор и присваивает его новой строке. Вы можете вручную вставить отрицательные значения, если столбец не был определен как UNSIGNED; однако для следующего автоматического приращения MySQL просто использует наибольшее (положительное) значение в столбце или начинает с 1, если положительных значений нет.
Функция AUTO_INCREMENT имеет следующие требования:
-
Столбец, в котором она используется, должен быть проиндексирован.
-
Столбец, в котором она используется, не может иметь значение
DEFAULT. -
В таблице может быть только один столбец
AUTO_INCREMENT.
MySQL поддерживает различные механизмы хранения; мы поговорим об этом подробнее в разделе «Альтернативные механизмы хранения». При использовании типа таблицы MyISAM, отличного от используемого по умолчанию, вы можете использовать функцию AUTO_INCREMENT для ключей, состоящих из нескольких столбцов. По сути, вы можете иметь несколько независимых счетчиков в одном столбце AUTO_INCREMENT. Однако это невозможно с InnoDB.
Хотя функция AUTO_INCREMENT полезна, ее нельзя перенести в другие среды баз данных, и она скрывает логические шаги по созданию новых идентификаторов. Это также может привести к двусмысленности; например, удаление или усечение таблицы приведет к сбросу счетчика, но удаление выбранных строк (с предложением WHERE) не сбрасывает счетчик. Более того, если в транзакцию вставляется строка, а затем эта транзакция откатывается, идентификатор все равно будет израсходован. В качестве примера создадим таблицу count, содержащую автоматически увеличивающееся поле counter:
mysql> CREATE TABLE count (counter INT AUTO_INCREMENT KEY);
Query OK, 0 rows affected (0.13 sec)
mysql> INSERT INTO count VALUES (),(),(),(),(),();
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM count;
+---------+
| counter |
+---------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
+---------+
6 rows in set (0.00 sec)
Вставка нескольких значений работает должным образом. Теперь давайте удалим несколько строк, а затем добавим шесть новых строк:
mysql> DELETE FROM count WHERE counter > 4;
Query OK, 2 rows affected (0.00 sec)
mysql> INSERT INTO count VALUES (),(),(),(),(),();
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM count;
+---------+
| counter |
+---------+
| 1 |
| 2 |
| 3 |
| 4 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
+---------+
10 rows in set (0.00 sec)
Здесь мы видим, что счетчик не сбрасывается и продолжается с 7. Однако если мы усекаем таблицу, таким образом удаляя все данные, счетчик сбрасывается до 1:
mysql> TRUNCATE TABLE count;
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO count VALUES (),(),(),(),(),();
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM count;
+---------+
| counter |
+---------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
+---------+
6 rows in set (0.00 sec)
Подводя итог: AUTO_INCREMENT гарантирует последовательность транзакционных и монотонно возрастающих значений. Однако это никоим образом не гарантирует, что каждый предоставленный индивидуальный идентификатор будет точно следовать предыдущему. Обычно такое поведение AUTO_INCREMENT достаточно понятно и не должно быть проблемой. Однако, если для вашего конкретного варианта использования требуется счетчик, гарантирующий отсутствие пробелов, вам следует рассмотреть возможность использования какого-либо обходного пути. К сожалению, скорее всего, это будет реализовано на стороне приложения.
Изменение структур
Мы показали вам все основы, необходимые для создания баз данных, таблиц, индексов и столбцов. В этом разделе вы узнаете, как добавлять, удалять и изменять столбцы, базы данных, таблицы и индексы в уже существующих структурах.
Добавление, удаление и изменение столбцов
Вы можете использовать оператор ALTER TABLE для добавления новых столбцов в таблицу, удаления существующих столбцов и изменения имен, типов и длины столбцов.
Давайте начнем с рассмотрения того, как вы изменяете существующие столбцы. Рассмотрим пример, в котором мы переименовываем столбец таблицы. В таблице language есть столбец с именем last_update, который содержит время изменения записи. Чтобы изменить имя этого столбца на last_updated_time, вы должны написать:
mysql> ALTER TABLE language RENAME COLUMN last_update TO last_updated_time;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
В этом конкретном примере используется онлайн-функция DDL MySQL. Что на самом деле происходит за кулисами, так это то, что MySQL изменяет только метаданные, и ему не нужно каким-либо образом переписывать таблицу. Это видно по отсутствию затронутых строк. Не все операторы DDL можно выполнять в режиме онлайн, так что это не относится ко многим изменениям, которые вы вносите.
Выполнение операторов DDL требует специальных внутренних механизмов, включая специальную блокировку — это хорошо, так как вы, вероятно, не хотели бы, чтобы таблицы изменялись во время выполнения ваших запросов! Эти специальные блокировки называются блокировками метаданных в MySQL, и мы даем подробный обзор того, как они работают в разделе «Блокировки метаданных».
Обратите внимание, что все операторы DDL, в том числе те, которые выполняются через интерактивный DDL, требуют получения блокировки метаданных. В этом смысле оперативные операторы DDL не являются такими уж «онлайновыми», но они не будут полностью блокировать целевую таблицу во время выполнения. Выполнение операторов DDL на работающей системе под нагрузкой — рискованное предприятие: даже оператор, который должен выполняться почти мгновенно, может нанести ущерб. Мы рекомендуем вам внимательно прочитать о блокировке метаданных в главе 6 и в ссылке на документацию MySQL, а также поэкспериментировать с выполнением различных операторов DDL с одновременной загрузкой и без нее. Это может быть не слишком важно, пока вы изучаете MySQL, но мы считаем, что стоит предупредить вас заранее. После этого давайте вернемся к нашему ALTER таблицы language.
Вы можете проверить результат с помощью оператора SHOW COLUMNS:
mysql> SHOW COLUMNS FROM language;
+-------------------+------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------------+------------------+------+-----+-------------------+...
| language_id | tinyint unsigned | NO | PRI | NULL |...
| name | char(20) | NO | | NULL |...
| last_updated_time | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------------+------------------+------+-----+-------------------+...
3 rows in set (0.01 sec)
В предыдущем примере мы использовали оператор ALTER TABLE с ключевым словом RENAME COLUMN. Это функция MySQL 8.0. В качестве альтернативы мы могли бы использовать ALTER TABLE с ключевым словом CHANGE для совместимости:
mysql> ALTER TABLE language CHANGE last_update last_updated_time TIMESTAMP
-> NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
В этом примере вы можете видеть, что мы предоставили оператору ALTER TABLE четыре параметра с ключевым словом CHANGE:
-
Название таблицы,
language -
Исходное имя столбца,
last_update -
Имя нового столбца,
last_updated_time -
Тип столбца
TIMESTAMPс множеством дополнительных атрибутов, которые необходимы, чтобы избежать изменения исходного определения.
Вы должны предоставить все четыре; это означает, что вам нужно повторно указать тип и любые предложения, которые сопровождают его. В этом примере, поскольку мы используем MySQL 8.0 с настройками по умолчанию, TIMESTAMP больше не имеет явных значений по умолчанию. Как видите, использовать RENAME COLUMN намного проще, чем CHANGE.
Если вы хотите изменить тип и предложения столбца, но не его имя, вы можете использовать ключевое слово MODIFY:
mysql> ALTER TABLE language MODIFY name CHAR(20) DEFAULT 'n/a';
Query OK, 0 rows affected (0.14 sec)
Records: 0 Duplicates: 0 Warnings: 0
Вы также можете сделать это с помощью ключевого слова CHANGE, но дважды указав одно и то же имя столбца:
mysql> ALTER TABLE language CHANGE name name CHAR(20) DEFAULT 'n/a';
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
Будьте осторожны при изменении типов:
-
Не используйте несовместимые типы, так как вы полагаетесь на MySQL для успешного преобразования данных из одного формата в другой (например, преобразование столбца
INTв столбецDATETIMEвряд ли даст то, на что вы рассчитывали). -
Не усекайте данные, если это не то, что вам нужно. Если вы уменьшите размер типа, значения будут отредактированы в соответствии с новой шириной, и вы можете потерять данные.
Предположим, вы хотите добавить дополнительный столбец в существующую таблицу. Вот как это сделать с помощью инструкции ALTER TABLE:
mysql> ALTER TABLE language ADD native_name CHAR(20);
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
Вы должны указать ключевое слово ADD, новое имя столбца, а также тип столбца и условия. В этом примере новый столбец, native_name, добавляется в качестве последнего столбца в таблице, как показано с помощью инструкции SHOW COLUMNS:
mysql> SHOW COLUMNS FROM artist;
+-------------------+------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------------+------------------+------+-----+-------------------+...
| language_id | tinyint unsigned | NO | PRI | NULL |...
| name | char(20) | YES | | n/a |...
| last_updated_time | timestamp | NO | | CURRENT_TIMESTAMP |...
| native_name | char(20) | YES | | NULL |...
+-------------------+------------------+------+-----+-------------------+...
4 rows in set (0.00 sec)
Если вы хотите, чтобы это был первый столбец, используйте ключевое слово FIRST следующим образом:
mysql> ALTER TABLE language ADD native_name CHAR(20) FIRST;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW COLUMNS FROM language;
+-------------------+------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------------+------------------+------+-----+-------------------+...
| native_name | char(20) | YES | | NULL |...
| language_id | tinyint unsigned | NO | PRI | NULL |...
| name | char(20) | YES | | n/a |...
| last_updated_time | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------------+------------------+------+-----+-------------------+...
4 rows in set (0.01 sec)
Если вы хотите добавить его в определенную позицию, используйте ключевое слово AFTER:
mysql> ALTER TABLE language ADD native_name CHAR(20) AFTER name;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW COLUMNS FROM language;
+-------------------+------------------+------+-----+-------------------+...
| Field | Type | Null | Key | Default |...
+-------------------+------------------+------+-----+-------------------+...
| language_id | tinyint unsigned | NO | PRI | NULL |...
| name | char(20) | YES | | n/a |...
| native_name | char(20) | YES | | NULL |...
| last_updated_time | timestamp | NO | | CURRENT_TIMESTAMP |...
+-------------------+------------------+------+-----+-------------------+...
4 rows in set (0.00 sec)
Чтобы удалить столбец, используйте ключевое слово DROP, за которым следует имя столбца. Вот как можно избавиться от недавно добавленного столбца native_name:
mysql> ALTER TABLE language DROP native_name;
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
При этом удаляется как структура столбца, так и любые данные, содержащиеся в этом столбце. Также удаляется столбец из всех индексов, в которых он находился; если это единственный столбец в индексе, индекс тоже удаляется. Вы не можете удалить столбец, если он единственный в таблице; для этого вместо этого вы удаляете таблицу, как описано в разделе «Удаление структур». Будьте осторожны при удалении столбцов, потому что при изменении структуры таблицы вам, как правило, придется модифицировать любые операторы INSERT, которые вы используете для вставки значений в определенном порядке. Подробнее об этом см. в разделе «Инструкция INSERT».
MySQL позволяет указать несколько изменений в одном операторе ALTER TABLE, разделяя их запятыми. Вот пример, который добавляет новый столбец и корректирует другой:
mysql> ALTER TABLE language ADD native_name CHAR(255), MODIFY name CHAR(255);
Query OK, 6 rows affected (0.06 sec)
Records: 6 Duplicates: 0 Warnings: 0
Обратите внимание, что на этот раз вы видите, что шесть записей были изменены. В предыдущих командах ALTER TABLE MySQL сообщал, что никакие строки не были затронуты. Разница в том, что на этот раз мы не выполняем онлайн-операцию DDL, поскольку изменение любого типа столбца всегда приводит к перестроению таблицы. Мы рекомендуем прочитать об онлайн-операциях DDL в Справочном руководстве при планировании изменений. Объединение онлайн- и офлайн-операций приведет к офлайн-операции.
Когда не используется интерактивный DDL или когда какая-либо из модификаций находится «в автономном режиме», очень эффективно объединять несколько модификаций в одну операцию. Это потенциально снижает затраты на создание новой таблицы, копирование данных из старой таблицы в новую, удаление старой таблицы и переименование новой таблицы с использованием имени старой таблицы для каждой модификации отдельно.
Добавление, удаление и изменение индексов
Как мы обсуждали ранее, часто трудно понять, какие индексы полезны, до того, как будет использовано приложение, которое вы создаете. Вы можете обнаружить, что конкретная функция приложения намного популярнее, чем вы ожидали, что заставит вас задуматься о том, как повысить производительность связанных запросов. Поэтому вам будет полезно иметь возможность добавлять, изменять и удалять индексы на лету после развертывания приложения. В этом разделе показано, как это сделать. Обратите внимание, что изменение индексов не влияет на данные, хранящиеся в таблице.
Начнем с добавления нового индекса. Представьте, что таблица language часто запрашивается с использованием предложения WHERE, в котором указывается name. Чтобы ускорить эти запросы, вы решили добавить новый индекс, который вы назвали idx_name. Вот как вы добавляете его после создания таблицы:
mysql> ALTER TABLE language ADD INDEX idx_name (name);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
Опять же, вы можете использовать термины KEY и INDEX взаимозаменяемо. Вы можете проверить результаты с помощью оператора SHOW CREATE TABLE:
mysql> SHOW CREATE TABLE language\G
*************************** 1. row ***************************
Table: language
Create Table: CREATE TABLE `language` (
`language_id` tinyint unsigned NOT NULL AUTO_INCREMENT,
`name` char(255) DEFAULT NULL,
`last_updated_time` timestamp NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`language_id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8
DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
Как и ожидалось, новый индекс является частью структуры таблицы. Вы также можете указать первичный ключ для таблицы после ее создания:
mysql> CREATE TABLE no_pk (id INT);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO no_pk VALUES (1),(2),(3);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE no_pk ADD PRIMARY KEY (id);
Query OK, 0 rows affected (0.13 sec)
Records: 0 Duplicates: 0 Warnings: 0
Теперь давайте рассмотрим, как удалить index. Чтобы удалить индекс, не являющийся первичным ключом, выполните следующие действия:
mysql> ALTER TABLE language DROP INDEX idx_name;
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
Вы можете удалить индекс первичного ключа следующим образом:
mysql> ALTER TABLE no_pk DROP PRIMARY KEY;
Query OK, 3 rows affected (0.07 sec)
Records: 3 Duplicates: 0 Warnings: 0
MySQL не позволит вам иметь несколько первичных ключей в таблице. Если вы хотите изменить первичный ключ, вам придется удалить существующий индекс перед добавлением нового. Однако мы знаем, что операции DDL можно группировать. Рассмотрим этот пример:
mysql> ALTER TABLE language DROP PRIMARY KEY,
-> ADD PRIMARY KEY (language_id, name);
Query OK, 0 rows affected (0.09 sec)
Records: 0 Duplicates: 0 Warnings: 0
Вы не можете изменить индекс после его создания. Однако иногда вам захочется это сделать; например, вы можете уменьшить количество символов, индексируемых в столбце, или добавить другой столбец в индекс. Лучший способ сделать это — удалить индекс, а затем создать его снова с новой спецификацией. Например, предположим, вы решили, что хотите, чтобы индекс idx_name включал только первые 10 символов artist_name. Просто сделайте следующее:
mysql> ALTER TABLE language DROP INDEX idx_name,
-> ADD INDEX idx_name (name(10));
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
Переименование таблиц и изменение других структур
Мы видели, как изменять столбцы и индексы в таблице; теперь давайте посмотрим, как модифицировать сами таблицы. Таблицу легко переименовать. Предположим, вы хотите переименовать language в languages. Используйте следующую команду:
mysql> ALTER TABLE language RENAME TO languages;
Query OK, 0 rows affected (0.04 sec)
Ключевое слово TO является необязательным.
Есть еще несколько вещей, которые вы можете делать с операторами ALTER, в том числе:
-
Изменение набора символов по умолчанию и порядка сортировки для базы данных, таблицы или столбца.
-
Управление и изменение ограничений. Например, вы можете добавлять и удалять внешние ключи.
-
Добавление секционирования в таблицу или изменение текущее определения секционирования.
-
Изменение механизма хранения таблицы.
Вы можете найти больше об этих операциях в Справочном руководстве по MySQL, в разделах, посвященных операторам ALTER DATABASE и ALTER TABLE. Альтернативная более короткая запись для того же оператора — RENAME TABLE:
mysql> RENAME TABLE languages TO language;
Query OK, 0 rows affected (0.04 sec)
Одна вещь, которую невозможно изменить, — это имя конкретной базы данных. Однако, если вы используете движок InnoDB, вы можете использовать RENAME для перемещения таблиц между базами данных:
mysql> CREATE DATABASE sakila_new;
Query OK, 1 row affected (0.05 sec)
mysql> RENAME TABLE sakila.language TO sakila_new.language;
Query OK, 0 rows affected (0.05 sec)
mysql> USE sakila;
Database changed
mysql> SHOW TABLES LIKE 'lang%';
Empty set (0.00 sec)
mysql> USE sakila_new;
Database changed
mysql> SHOW TABLES LIKE 'lang%';
+------------------------------+
| Tables_in_sakila_new (lang%) |
+------------------------------+
| language |
+------------------------------+
1 row in set (0.00 sec)
Удаление структур
В предыдущем разделе мы показали, как можно удалять столбцы и строки из базы данных; теперь мы опишем, как удалить базы данных и таблицы.
Удаление баз данных
Удалить или dropping базу данных очень просто. Вот как вы удаляете базу данных sakila:
mysql> DROP DATABASE sakila;
Query OK, 25 rows affected (0.16 sec)
Количество строк, возвращаемых в ответе, равно количеству удаленных таблиц. Вы должны быть осторожны при удалении базы данных, так как все ее таблицы, индексы и столбцы удаляются, как и все связанные файлы и каталоги на диске, которые MySQL использует для их обслуживания.
Если база данных не существует, попытка удалить ее приведет к тому, что MySQL сообщит об ошибке. Давайте попробуем снова удалить базу данных sakila:
mysql> DROP DATABASE sakila;
ERROR 1008 (HY000): Can't drop database 'sakila'; database doesn't exist
Вы можете избежать ошибки, которая полезна при включении оператора в сценарий, используя фразу IF EXISTS:
mysql> DROP DATABASE IF EXISTS sakila;
Query OK, 0 rows affected, 1 warning (0.00 sec)
Вы можете видеть, что выдается предупреждение, так как база данных sakila уже удалена.
Удаление таблиц
Удаление таблиц так же просто, как удаление базы данных. Давайте создадим и удалим таблицу из базы данных sakila:
mysql> CREATE TABLE temp (id SERIAL PRIMARY KEY);
Query OK, 0 rows affected (0.05 sec)
mysql> DROP TABLE temp;
Query OK, 0 rows affected (0.03 sec)
Не беспокойтесь: сообщение 0 rows affected вводит в заблуждение. Вы обнаружите, что таблица определенно исчезла.
Вы можете использовать фразу IF EXISTS для предотвращения ошибок. Попробуем снова удалить таблицу temp:
mysql> DROP TABLE IF EXISTS temp;
Query OK, 0 rows affected, 1 warning (0.01 sec)
Как обычно, вы можете изучить предупреждение с помощью инструкции SHOW WARNINGS:
mysql> SHOW WARNINGS;
+-------+------+-----------------------------+
| Level | Code | Message |
+-------+------+-----------------------------+
| Note | 1051 | Unknown table 'sakila.temp' |
+-------+------+-----------------------------+
1 row in set (0.00 sec)
Вы можете удалить более одной таблицы в одном выражении, разделив имена таблиц запятыми:
mysql> DROP TABLE IF EXISTS temp, temp1, temp2;
Query OK, 0 rows affected, 3 warnings (0.00 sec)
В этом случае есть три предупреждения, потому что ни одна из этих таблиц не существовала.
Глава 5
Расширенные запросы
В предыдущих двух главах вы ознакомились с основными функциями запросов и изменения баз данных с помощью SQL. Теперь вы должны иметь возможность создавать, изменять и удалять структуры базы данных, а также работать с данными при чтении, вставке, удалении и обновлении записей. В этой и следующих двух главах мы рассмотрим более сложные концепции, а затем перейдем к более административному и ориентированному на операции содержимому. Вы можете просмотреть эти главы и вернуться к ним, чтобы полностью прочитать их, когда освоитесь с MySQL.
В этой главе вы узнаете больше о запросах и получите навыки, необходимые для решения сложных информационных задач. Вы узнаете, как сделать следующее:
-
Использовать псевдонимы или алиасы в запросах, чтобы сократить ввод и разрешить многократное использование таблицы в запросе.
-
Объединять данные в группы, чтобы вы могли находить суммы, средние значения и подсчеты.
-
Объединять таблицы разными способами.
-
Использовать вложенные запросы.
-
Сохранять результаты запроса в переменных, чтобы их можно было повторно использовать в других запросах.
Псевдонимы (Aliases)
Псевдонимы — это прозвища. Они дают вам сокращенный способ выражения имени столбца, таблицы или функции, позволяя вам:
-
Пишсать короткие запросы.
-
Выражать свои вопросы более четко.
-
Использовать одну таблицу двумя или более способами в одном запросе.
-
Использовать более легкий доступ к данным из программ.
-
Использовать специальные типы вложенных запросов, описанные в разделе «Вложенные запросы».
Псевдонимы столбцов
Псевдонимы столбцов полезны для улучшения выражений ваших запросов, уменьшения количества символов, которые необходимо ввести, и упрощения работы с такими языками программирования, как Python или PHP. Рассмотрим простой, не очень полезный пример:
mysql> SELECT first_name AS 'First Name', last_name AS 'Last Name'
-> FROM actor LIMIT 5;
+------------+--------------+
| First Name | Last Name |
+------------+--------------+
| PENELOPE | GUINESS |
| NICK | WAHLBERG |
| ED | CHASE |
| JENNIFER | DAVIS |
| JOHNNY | LOLLOBRIGIDA |
+------------+--------------+
5 rows in set (0.00 sec)
Столбец first_name имеет псевдоним First Name, а столбец last_name — Last Name. Вы можете видеть, что в выводе обычные заголовки столбцов, first_name и last_name, заменены псевдонимами First Name и Last Name. Преимущество состоит в том, что псевдонимы могут быть более значимыми для пользователей. В этом случае, по крайней мере, они более удобочитаемы. Кроме этого, это не очень полезно, но иллюстрирует идею о том, что для столбца вы добавляете ключевое слово AS, а затем строку, представляющую то, как вы хотите, чтобы столбец назывался. Указание ключевого слова AS не требуется, но делает ситуацию более понятной.
Теперь давайте посмотрим, как псевдонимы столбцов делают что-то полезное. Вот пример, в котором используется функция MySQL и предложение ORDER BY:
mysql> SELECT CONCAT(first_name, ' ', last_name, ' played in ', title) AS movie
-> FROM actor JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> ORDER BY movie LIMIT 20;
+--------------------------------------------+
| movie |
+--------------------------------------------+
| ADAM GRANT played in ANNIE IDENTITY |
| ADAM GRANT played in BALLROOM MOCKINGBIRD |
| ... |
| ADAM GRANT played in TWISTED PIRATES |
| ADAM GRANT played in WANDA CHAMBER |
| ADAM HOPPER played in BLINDNESS GUN |
| ADAM HOPPER played in BLOOD ARGONAUTS |
+--------------------------------------------+
20 rows in set (0.03 sec)
MySQL-функция CONCAT() объединяет (concatenates) строки, которые являются параметрами — в данном случае first_name, константная строка с пробелом, last_name, константная строка played in, и title — для получения вывода, такого как ZERO CAGE played in CAN YON STOCK. Мы добавили к функции псевдоним AS movie, чтобы мы могли легко ссылаться на нее как на фильм во всем запросе. Вы можете видеть, что мы делаем это в предложении ORDER BY, где мы просим MySQL отсортировать вывод по возрастанию значения фильма. Это намного лучше, чем альтернатива без псевдонимов, которая требует повторного написания функции CONCAT():
mysql> SELECT CONCAT(first_name, ' ', last_name, ' played in ', title) AS movie
-> FROM actor JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> ORDER BY CONCAT(first_name, ' ', last_name, ' played in ', title)
-> LIMIT 20;
+--------------------------------------------+
| movie |
+--------------------------------------------+
| ADAM GRANT played in ANNIE IDENTITY |
| ADAM GRANT played in BALLROOM MOCKINGBIRD |
| ... |
| ADAM GRANT played in TWISTED PIRATES |
| ADAM GRANT played in WANDA CHAMBER |
| ADAM HOPPER played in BLINDNESS GUN |
| ADAM HOPPER played in BLOOD ARGONAUTS |
+--------------------------------------------+
20 rows in set (0.03 sec)
Альтернатива громоздка, и, что еще хуже, вы рискуете ошибиться в какой-то части предложения ORDER BY и получить результат, отличный от ожидаемого. (Обратите внимание, что мы использовали AS movie в первой строке, чтобы отображаемый столбец имел метку movie.)
Существуют ограничения на то, где вы можете использовать псевдонимы столбцов. Вы не можете использовать их в предложении WHERE или в предложениях USING и ON, которые мы обсудим позже в этой главе. Это означает, что вы не можете написать такой запрос:
mysql> SELECT first_name AS name FROM actor WHERE name = 'ZERO CAGE';
ERROR 1054 (42S22): Unknown column 'name' in 'where clause'
Вы не можете этого сделать, потому что MySQL не всегда знает значения столбцов до того, как выполнит предложение WHERE. Однако вы можете использовать псевдонимы столбцов в предложении ORDER BY, а также в предложениях GROUP BY и HAVING, обсуждаемых далее в этой главе.
Как мы уже упоминали, ключевое слово AS является необязательным. Из-за этого следующие два запроса эквивалентны:
mysql> SELECT actor_id AS id FROM actor WHERE first_name = 'ZERO';
+----+
| id |
+----+
| 11 |
+----+
1 row in set (0.00 sec)
mysql> SELECT actor_id id FROM actor WHERE first_name = 'ZERO';
+----+
| id |
+----+
| 11 |
+----+
1 row in set (0.00 sec)
Мы рекомендуем использовать ключевое слово AS, так как оно помогает четко отличить столбец с псевдонимом, особенно когда вы выбираете несколько столбцов из списка столбцов, разделенных запятыми.
Псевдонимы имеют несколько ограничений. Они могут иметь длину не более 255 символов и могут содержать любой символ. Псевдонимы не всегда нужно заключать в кавычки, и они подчиняются тем же правилам, что и имена таблиц и столбцов, которые мы описали в главе 4. Если псевдоним представляет собой одно слово и не содержит специальных символов, таких как тире, знак плюс или пробел, например, и не является ключевым словом, как USE, то вам не нужно заключать его в кавычки. В противном случае вам нужно указать псевдоним, что вы можете сделать, используя двойные кавычки, одинарные кавычки или обратные кавычки. Мы рекомендуем использовать строчные буквенно-цифровые строки для псевдонимов и использовать согласованный выбор символов, таких как подчеркивание, для разделения слов. Псевдонимы нечувствительны к регистру на всех платформах.
Псевдонимы таблиц
Псевдонимы таблиц полезны по тем же причинам, что и псевдонимы столбцов, но иногда они являются единственным способом выражения запроса. В этом разделе показано, как использовать псевдонимы таблиц, а в разделе «Вложенные запросы» показаны некоторые другие примеры запросов, в которых необходимы псевдонимы таблиц.
Вот простой пример псевдонима таблицы, который показывает вам, как сэкономить на вводе:
mysql> SELECT ac.actor_id, ac.first_name, ac.last_name, fl.title FROM
-> actor AS ac INNER JOIN film_actor AS fla USING (actor_id)
-> INNER JOIN film AS fl USING (film_id)
-> WHERE fl.title = 'AFFAIR PREJUDICE';
+----------+------------+-----------+------------------+
| actor_id | first_name | last_name | title |
+----------+------------+-----------+------------------+
| 41 | JODIE | DEGENERES | AFFAIR PREJUDICE |
| 81 | SCARLETT | DAMON | AFFAIR PREJUDICE |
| 88 | KENNETH | PESCI | AFFAIR PREJUDICE |
| 147 | FAY | WINSLET | AFFAIR PREJUDICE |
| 162 | OPRAH | KILMER | AFFAIR PREJUDICE |
+----------+------------+-----------+------------------+
5 rows in set (0.00 sec)
Вы можете видеть, что таблицы film и actor имеют псевдонимы fl и ac соответственно с использованием ключевого слова AS. Это позволяет более компактно выражать имена столбцов, например, fl.title. Заметьте также, что вы можете использовать псевдонимы таблиц в предложении WHERE; в отличие от псевдонимов столбцов, нет никаких ограничений на использование псевдонимов таблиц в запросах. Из нашего примера видно, что мы ссылаемся на псевдонимы таблиц в SELECT до того, как они были определены в FROM. Однако с псевдонимами таблиц есть одна загвоздка: если для таблицы был использован псевдоним, невозможно обратиться к этой таблице, не используя ее новый псевдоним. Например, следующий оператор выдаст ошибку, как если бы мы упомянули film в предложении SELECT:
mysql> SELECT ac.actor_id, ac.first_name, ac.last_name, fl.title FROM
-> actor AS ac INNER JOIN film_actor AS fla USING (actor_id)
-> INNER JOIN film AS fl USING (film_id)
-> WHERE film.title = 'AFFAIR PREJUDICE';
ERROR 1054 (42S22): Unknown column 'film.title' in 'where clause'
Как и в случае псевдонимов столбцов, ключевое слово AS является необязательным. Это значит, что запрос:
actor AS ac INNER JOIN film_actor AS flaтакой же как
actor ac INNER JOIN film_actor flaОпять же, мы предпочитаем стиль AS, потому что он понятнее любому, кто просматривает ваши запросы, чем альтернативный вариант. Ограничения по длине и содержимому для псевдонимов таблиц такие же, как и для псевдонимов столбцов, и наши рекомендации по их выбору такие же.
Как обсуждалось во введении к этому разделу, псевдонимы таблиц позволяют вам писать запросы, которые вы не можете легко выразить иначе. Рассмотрим пример: предположим, вы хотите знать, имеют ли два или более фильма в нашей коллекции одинаковое название, и если да, то что это за фильмы. Давайте подумаем об основном требовании: вы хотите знать, имеют ли два фильма одинаковые названия. Чтобы получить это, вы можете попробовать такой запрос:
mysql> SELECT * FROM film WHERE title = title;Но это не имеет смысла — каждый фильм имеет то же название, что и он сам, поэтому запрос просто выдает все фильмы в качестве вывода:
+---------+------------------...
| film_id | title ...
+---------+------------------...
| 1 | ACADEMY DINOSAUR ...
| 2 | ACE GOLDFINGER ...
| 3 | ADAPTATION HOLES ...
| ... ...
| 1000 | ZORRO ARK ...
+---------+------------------...
1000 rows in set (0.01 sec)
Что вам действительно нужно, так это знать, имеют ли два разных фильма из таблицы film одно и то же имя. Но как это сделать в одном запросе? Ответ состоит в том, чтобы дать таблице два разных псевдонима; затем вы проверяете, соответствует ли одна строка в первой таблице с псевдонимами строке во второй:
mysql> SELECT m1.film_id, m2.title
-> FROM film AS m1, film AS m2
-> WHERE m1.title = m2.title;
+---------+-------------------+
| film_id | title |
+---------+-------------------+
| 1 | ACADEMY DINOSAUR |
| 2 | ACE GOLDFINGER |
| 3 | ADAPTATION HOLES |
| ... |
| 1000 | ZORRO ARK |
+---------+-------------------+
1000 rows in set (0.02 sec)
Но это все еще не работает! Мы получаем все 1000 фильмов в качестве ответов. Причина в том, что снова каждый фильм соответствует самому себе, потому что он встречается в обеих таблицах псевдонимов.
Чтобы запрос работал, нам нужно убедиться, что фильм из одной таблицы с псевдонимами не совпадает с самим собой в другой таблице с псевдонимами. Это можно сделать, указав, что фильмы в каждой таблице не должны иметь одинаковый идентификатор:
mysql> SELECT m1.film_id, m2.title
-> FROM film AS m1, film AS m2
-> WHERE m1.title = m2.title
-> AND m1.film_id <> m2.film_id;
Empty set (0.00 sec)
Теперь вы можете видеть, что в базе данных нет двух фильмов с одинаковым названием. Дополнительный оператор AND m1.film_id != m2.film_id предотвращает вывод ответов, если идентификатор фильма одинаков в обеих таблицах.
Псевдонимы таблиц также полезны во вложенных запросах, использующих предложения EXISTS и ON. Мы покажем вам примеры позже в этой главе, когда будем знакомиться с вложенными запросами.
Объединение данных
Агрегатные функции позволяют обнаружить свойства группы строк. Вы используете их для таких целей, как определение количества строк в таблице, количества строк в таблице, имеющих общее свойство (например, наличие одинакового имени или даты рождения), нахождение средних значений (например, средней температуры в ноябре), или нахождение максимальных или минимальных значений строк, удовлетворяющих некоторому условию (например, нахождению самого холодного дня в августе).
В этом разделе объясняются предложения GROUP BY и HAVING, два наиболее часто используемых оператора SQL для агрегирования. Но сначала объясняется предложение DISTINCT, которое используется для сообщения уникальных результатов вывода запроса. Если ни предложение DISTINCT, ни предложение GROUP BY не указаны, возвращенные необработанные данные все равно могут быть обработаны с помощью агрегатных функций, которые мы описываем в этом разделе.
Предложение DISTINCT
Чтобы начать обсуждение агрегатных функций, мы сосредоточимся на предложении DISTINCT. На самом деле это не агрегатная функция, а скорее фильтр постобработки, позволяющий удалять дубликаты. Мы добавили его в этот раздел, потому что, как и агрегатные функции, он связан с выбором примеров из вывода запроса, а не с обработкой отдельных строк.
Пример — лучший способ понять DISTINCT. Рассмотрим этот запрос:
mysql> SELECT DISTINCT first_name
-> FROM actor JOIN film_actor USING (actor_id);
+-------------+
| first_name |
+-------------+
| PENELOPE |
| NICK |
| ... |
| GREGORY |
| JOHN |
| BELA |
| THORA |
+-------------+
128 rows in set (0.00 sec)
Запрос находит все имена всех актеров, перечисленных в нашей базе данных, которые участвовали в фильме, и сообщает по одному примеру каждого имени. Если вы удалите предложение DISTINCT, вы получите одну строку вывода для каждой роли в каждом фильме, который есть в нашей базе данных, или 5462 строки. Это большой объем вывода, поэтому мы ограничили его пятью строками, но вы можете сразу заметить разницу с повторяющимися именами:
mysql> SELECT first_name
-> FROM actor JOIN film_actor USING (actor_id)
-> LIMIT 5;
+------------+
| first_name |
+------------+
| PENELOPE |
| PENELOPE |
| PENELOPE |
| PENELOPE |
| PENELOPE |
+------------+
5 rows in set (0.00 sec)
Таким образом, предложение DISTINCT помогает вам получить сводку.
Предложение DISTINCT применяется к выходным данным запроса и удаляет строки с одинаковыми значениями в столбцах, выбранных для вывода в запросе. Если вы перефразируете предыдущий запрос для вывода как first_name, так и last_name (но в противном случае не изменяйте предложение JOIN и по-прежнему используете DISTINCT), вы получите 199 строк на выходе (поэтому мы используем фамилии):
mysql> SELECT DISTINCT first_name, last_name
-> FROM actor JOIN film_actor USING (actor_id);
+-------------+--------------+
| first_name | last_name |
+-------------+--------------+
| PENELOPE | GUINESS |
| NICK | WAHLBERG |
| ... |
| JULIA | FAWCETT |
| THORA | TEMPLE |
+-------------+--------------+
199 rows in set (0.00 sec)
К сожалению, имена людей, даже если добавлены фамилии, по-прежнему являются плохим уникальным ключом. В таблице actor в базе данных sakila 200 строк, и нам не хватает одной из них. Вы должны помнить об этой проблеме, так как использование DISTINCT без разбора может привести к неверным результатам запроса.
Чтобы удалить дубликаты, MySQL необходимо отсортировать вывод. Если доступны индексы, расположенные в том же порядке, который требуется для сортировки, или сами данные расположены в удобном для использования порядке, этот процесс требует очень мало накладных расходов. Однако для больших таблиц и без простого способа доступа к данным в правильном порядке сортировка может быть очень медленной. Вы должны использовать DISTINCT (и другие агрегатные функции) с осторожностью для больших наборов данных. Если вы его используете, вы можете проверить его поведение с помощью оператора EXPLAIN, который обсуждался в главе 7.
Предложение GROUP BY
Предложение GROUP BY группирует выходные данные для агрегирования. В частности, это позволяет нам использовать агрегатные функции (описанные в разделе «Агрегатные функции») для наших данных, когда наша проекция (то есть содержимое предложения SELECT) содержит столбцы, отличные от тех, которые входят в агрегатную функцию. GROUP BY похож на ORDER BY тем, что в качестве аргумента принимает список столбцов. Однако эти пункты оцениваются в разное время и похожи только тем, как они выглядят, а не тем, как они работают.
Давайте рассмотрим несколько примеров GROUP BY, которые продемонстрируют, для чего ее можно использовать. В самой простой форме, когда мы перечисляем каждый столбец, который мы SELECT в GROUP BY, мы получаем эквивалент DISTINCT. Мы уже установили, что имя не является уникальным идентификатором актера:
mysql> SELECT first_name FROM actor
-> WHERE first_name IN ('GENE', 'MERYL');
+------------+
| first_name |
+------------+
| GENE |
| GENE |
| MERYL |
| GENE |
| MERYL |
+------------+
5 rows in set (0.00 sec)
Мы можем указать MySQL сгруппировать вывод по заданному столбцу, чтобы избавиться от дубликатов. В данном случае мы выбрали только один столбец, поэтому воспользуемся им:
mysql> SELECT first_name FROM actor
-> WHERE first_name IN ('GENE', 'MERYL')
-> GROUP BY first_name;
+------------+
| first_name |
+------------+
| GENE |
| MERYL |
+------------+
2 rows in set (0.00 sec)
Вы можете видеть, что исходные пять строк были свернуты — или, точнее, сгруппированы — всего в две результирующие строки. Это не очень полезно, так как DISTINCT может сделать то же самое. Однако стоит отметить, что так будет не всегда. DISTINCT и GROUP BY оцениваются и выполняются на разных этапах выполнения запроса, поэтому не следует их путать, даже если иногда эффекты схожи.
В соответствии со стандартом SQL каждый столбец, спроецированный в предложении SELECT, который не является частью агрегатной функции, должен быть указан в предложении GROUP BY. Единственный случай, когда это правило может быть нарушено, — это когда результирующие группы имеют только одну строку в каждой. Если подумать, то это логично: если из таблицы actor выбрать first_name и last_name и сгруппировать только по first_name, то как должна вести себя база данных? Он не может выводить более одной строки с одним и тем же именем, так как это противоречит правилам группировки, но для данного имени может быть более одной фамилии.
В течение долгого времени MySQL расширял стандарт, позволяя выполнять GROUP BY на основе меньшего количества столбцов, чем определено в SELECT. Что он сделал с дополнительными столбцами? Ну, он выводит какое-то значение недетерминированным образом. Например, если вы сгруппировали по имени, но не по фамилии, вы можете получить любую из двух строк GENE, WILLIS и GENE, HOPKINS. Это нестандартное и опасное поведение. Представьте, что на год вы получили Хопкинса, как будто результаты были упорядочены по алфавиту, и стали полагаться на это, но потом таблица была реорганизована, и порядок изменился. Мы твердо верим, что стандарт SQL правильно ограничивает такое поведение, чтобы избежать непредсказуемости.
Также обратите внимание, что хотя каждый столбец в SELECT должен использоваться либо в GROUP BY, либо в агрегатной функции, вы можете GROUP BY столбцы, которые не являются частью SELECT. Вы увидите некоторые примеры этого позже.
Теперь давайте создадим более полезный пример. Актер обычно принимает участие во многих фильмах на протяжении всей своей карьеры. Мы можем захотеть узнать, в скольких фильмах сыграл конкретный актер, или сделать расчет для каждого известного нам актера и получить рейтинг по продуктивности. Для начала мы можем использовать методы, которые мы изучили до сих пор, и выполнить INNER JOIN между таблицами actor и film_actor. Таблица film нам не нужна, так как мы не ищем никаких подробностей о самих фильмах. Затем мы можем упорядочить вывод по имени актера, что упрощает подсчет того, что мы хотим:
mysql> SELECT first_name, last_name, film_id
-> FROM actor INNER JOIN film_actor USING (actor_id)
-> ORDER BY first_name, last_name LIMIT 20;
+------------+-----------+---------+
| first_name | last_name | film_id |
+------------+-----------+---------+
| ADAM | GRANT | 26 |
| ADAM | GRANT | 52 |
| ADAM | GRANT | 233 |
| ADAM | GRANT | 317 |
| ADAM | GRANT | 359 |
| ADAM | GRANT | 362 |
| ADAM | GRANT | 385 |
| ADAM | GRANT | 399 |
| ADAM | GRANT | 450 |
| ADAM | GRANT | 532 |
| ADAM | GRANT | 560 |
| ADAM | GRANT | 574 |
| ADAM | GRANT | 638 |
| ADAM | GRANT | 773 |
| ADAM | GRANT | 833 |
| ADAM | GRANT | 874 |
| ADAM | GRANT | 918 |
| ADAM | GRANT | 956 |
| ADAM | HOPPER | 81 |
| ADAM | HOPPER | 82 |
+------------+-----------+---------+
20 rows in set (0.01 sec)
Пробегая по списку, легко подсчитать, сколько фильмов у нас есть для каждого актера или, по крайней мере, для Адама Гранта. Однако без LIMIT запрос вернет 5462 различных строки, и расчет количества вручную займет много времени. Предложение GROUP BY может помочь автоматизировать этот процесс, группируя фильмы по актерам; затем мы можем использовать функцию COUNT() для подсчета количества фильмов в каждой группе. Наконец, мы можем использовать ORDER BY и LIMIT, чтобы получить 10 лучших актеров по количеству фильмов, в которых они снялись. Вот запрос, который делает то, что нам нужно:
mysql> SELECT first_name, last_name, COUNT(film_id) AS num_films FROM
-> actor INNER JOIN film_actor USING (actor_id)
-> GROUP BY first_name, last_name
-> ORDER BY num_films DESC LIMIT 10;
+------------+-------------+-----------+
| first_name | last_name | num_films |
+------------+-------------+-----------+
| SUSAN | DAVIS | 54 |
| GINA | DEGENERES | 42 |
| WALTER | TORN | 41 |
| MARY | KEITEL | 40 |
| MATTHEW | CARREY | 39 |
| SANDRA | KILMER | 37 |
| SCARLETT | DAMON | 36 |
| VAL | BOLGER | 35 |
| ANGELA | WITHERSPOON | 35 |
| UMA | WOOD | 35 |
+------------+-------------+-----------+
10 rows in set (0.01 sec)
Вы можете видеть, что результат, который мы запросили, это first_name, last_name, COUNT(film_id) как num_films, и это говорит нам именно то, что мы хотели знать. Мы группируем наши данные по столбцам first_name и last_name, запуская в процессе агрегатную функцию COUNT(). Для каждого «сегмента» строк, которые мы получили в предыдущем запросе, теперь мы получаем только одну строку, хотя и дающую нужную нам информацию. Обратите внимание, как мы объединили GROUP BY и ORDER BY, чтобы получить нужный порядок: по количеству фильмов, от большего к меньшему. GROUP BY не гарантирует упорядочение, только группировку. Наконец, мы ограничиваем вывод (LIMIT) до 10 строк, представляющих наших наиболее продуктивных участников, иначе мы получили бы 199 строк вывода.
Рассмотрим запрос дальше. Мы начнем с предложения GROUP BY. Это говорит нам, как объединять строки в группы: в этом примере мы сообщаем MySQL, что способ группировки строк — это first_name, last_name. В результате строки для субъектов с одинаковыми именами образуют кластер или корзину, то есть каждое отдельное имя становится одной группой. Как только строки сгруппированы, они обрабатываются в остальной части запроса, как если бы они были одной строкой. Так, например, когда мы пишем SELECT first_name, last_name, мы получаем только одну строку для каждой группы. Это то же самое, что и DISTINCT, как мы уже обсуждали. Функция COUNT() сообщает нам о свойствах группы. В частности, она сообщает нам количество строк, образующих каждую группу; вы можете посчитать любой столбец в группе, и вы получите тот же ответ, поэтому COUNT(film_id) почти всегда совпадает с COUNT(*) или COUNT(first_name). (Подробнее о том, почему мы говорим почти, см. в разделе «Агрегатные функции».) Мы также могли бы просто выполнить COUNT(1) или указать любой литерал. Думайте об этом как о выполнении SELECT 1 из таблицы и последующем подсчете результатов. Значение 1 будет выведено для каждой строки в таблице, а COUNT() сделает подсчет. Единственным исключением является NULL: хотя вполне приемлемо и законно указывать COUNT(NULL), результат всегда будет нулевым, поскольку COUNT() отбрасывает значения NULL. Конечно, вы можете использовать псевдоним столбца для столбца COUNT().
Давайте попробуем другой пример. Предположим, вы хотите узнать, сколько разных актеров сыграло в каждом фильме, а также название фильма и его категорию, и получить пять фильмов с самой большой съемочной группой. Вот запрос:
mysql> SELECT title, name AS category_name, COUNT(*) AS cnt
-> FROM film INNER JOIN film_actor USING (film_id)
-> INNER JOIN film_category USING (film_id)
-> INNER JOIN category USING (category_id)
-> GROUP BY film_id, category_id
-> ORDER BY cnt DESC LIMIT 5;
+------------------+---------------+-----+
| title | category_name | cnt |
+------------------+---------------+-----+
| LAMBS CINCINATTI | Games | 15 |
| CRAZY HOME | Comedy | 13 |
| CHITTY LOCK | Drama | 13 |
| RANDOM GO | Sci-Fi | 13 |
| DRACULA CRYSTAL | Classics | 13 |
+------------------+---------------+-----+
5 rows in set (0.03 sec)
Прежде чем мы обсудим, что нового, подумайте об общей функции запроса. Мы объединяем четыре таблицы с помощью INNER JOIN, используя столбцы их идентификаторов: film, film_actor, film_category и category. Забудем на мгновение об агрегировании, результат этого запроса — одна строка для комбинации фильма и актера.
Предложение GROUP BY объединяет строки в кластеры. В этом запросе мы хотим, чтобы фильмы были сгруппированы по категориям. Предложение GROUP BY использует для этого film_id и category_id. Вы можете использовать столбец film_id из любой из трех таблиц; film.film_id, film_actor.film_id и film_category.film_id для этой цели одинаковы. Неважно, какой из них вы используете; INNER JOIN гарантирует, что они все равно совпадают. То же самое относится и к category_id.
Как упоминалось ранее, несмотря на то, что требуется перечислить каждый неагрегированный столбец в GROUP BY, вы можете группировать по столбцам за пределами SELECT. В предыдущем примере запроса мы используем функцию COUNT(), чтобы сообщить нам, сколько строк находится в каждой группе. Например, вы можете видеть, что COUNT(*) говорит нам, что в комедии CRAZY HOME задействовано 13 актеров. Опять же, не имеет значения, какой столбец или столбцы вы считаете в запросе: например, COUNT(*) имеет тот же эффект, что и COUNT(film.film_id) или COUNT(category.name).
Затем мы упорядочиваем выходные данные по столбцу COUNT(*) с псевдонимом cnt в порядке убывания и выбираем первые пять строк. Обратите внимание, что есть несколько строк с cnt, равным 13. На самом деле их даже больше (всего шесть) в базе данных, что делает этот порядок немного несправедливым, поскольку фильмы с одинаковым количеством актеров будут отсортированы случайным образом. Вы можете добавить еще один столбец в предложение ORDER BY, например title, чтобы сделать сортировку более предсказуемой.
Давайте попробуем другой пример. База данных sakila касается не только фильмов и актеров: в конце концов, она основана на прокате фильмов. У нас есть, в том числе, информация о клиентах, в том числе данные о том, какие фильмы они брали напрокат. Скажем, мы хотим знать, какие клиенты склонны брать напрокат фильмы из той же категории. Например, мы можем настроить нашу рекламу в зависимости от того, нравятся ли человеку разные категории фильмов или большую часть времени он придерживается какой-то одной. Нам нужно тщательно продумать нашу группировку: мы не хотим группировать по фильмам, так как это просто даст нам количество раз, когда клиент брал его напрокат. Полученный запрос довольно сложен, хотя он по-прежнему основан на INNER JOIN и GROUP BY:
mysql> SELECT email, name AS category_name, COUNT(category_id) AS cnt
-> FROM customer cs INNER JOIN rental USING (customer_id)
-> INNER JOIN inventory USING (inventory_id)
-> INNER JOIN film_category USING (film_id)
-> INNER JOIN category cat USING (category_id)
-> GROUP BY 1, 2
-> ORDER BY 3 DESC LIMIT 5;
+----------------------------------+---------------+-----+
| email | category_name | cnt |
+----------------------------------+---------------+-----+
| WESLEY.BULL@sakilacustomer.org | Games | 9 |
| ALMA.AUSTIN@sakilacustomer.org | Animation | 8 |
| KARL.SEAL@sakilacustomer.org | Animation | 8 |
| LYDIA.BURKE@sakilacustomer.org | Documentary | 8 |
| NATHAN.RUNYON@sakilacustomer.org | Animation | 7 |
+----------------------------------+---------------+-----+
5 rows in set (0.08 sec)
Эти клиенты повторно арендуют фильмы из одной и той же категории. Чего мы не знаем, так это того, брал ли кто-нибудь из них один и тот же фильм несколько раз, или это были разные фильмы в одной категории. Предложение GROUP BY скрывает детали. Опять же, мы используем COUNT(*) для подсчета строк в группах, и вы можете видеть, что INNER JOIN распределяется по строкам со 2 по 5 в запросе.
В этом запросе интересно то, что мы не указали явно имена столбцов для предложений GROUP BY или ORDER BY. Вместо этого мы использовали номера позиций столбцов (отсчитываемые от 1), как они появляются в предложении SELECT. Этот метод экономит время ввода, но может быть проблематичным, если вы позже решите добавить еще один столбец в SELECT, что нарушит порядок.
Как и в случае с DISTINCT, в GROUP BY есть опасность, о которой следует упомянуть. Рассмотрим следующий запрос:
mysql> SELECT COUNT(*) FROM actor GROUP BY first_name, last_name;
+----------+
| COUNT(*) |
+----------+
| 1 |
| 1 |
| ... |
| 1 |
| 1 |
+----------+
199 rows in set (0.00 sec)
Он выглядит достаточно просто и выдает количество раз, когда комбинация заданного имени и фамилии встречалась в таблице actor. Вы можете предположить, что он просто выводит 199 строк цифры 1. Однако, если мы выполним COUNT(*) в таблице actor, мы получим 200 строк. В чем подвох? Судя по всему, у двух актеров одинаковые имя и фамилия. Такие вещи случаются, и вы должны помнить о них. При группировании на основе столбцов, которые не образуют уникальный идентификатор, вы можете случайно сгруппировать несвязанные строки, что приведет к вводящим в заблуждение данным. Чтобы найти дубликаты, мы можем изменить запрос, который мы создали в «Псевдонимы таблицы», для поиска фильмов с таким же именем:
mysql> SELECT a1.actor_id, a1.first_name, a1.last_name
-> FROM actor AS a1, actor AS a2
-> WHERE a1.first_name = a2.first_name
-> AND a1.last_name = a2.last_name
-> AND a1.actor_id <> a2.actor_id;
+----------+------------+-----------+
| actor_id | first_name | last_name |
+----------+------------+-----------+
| 101 | SUSAN | DAVIS |
| 110 | SUSAN | DAVIS |
+----------+------------+-----------+
2 rows in set (0.00 sec)
Прежде чем мы закончим этот раздел, давайте еще раз коснемся того, как MySQL расширяет стандарт SQL вокруг предложения GROUP BY. До MySQL 5.7 можно было по умолчанию указывать неполный список столбцов в предложении GROUP BY, и, как мы объясняли, это приводило к тому, что в группах для несгруппированных зависимых столбцов выводились случайные строки. По причинам поддержки устаревшего программного обеспечения и MySQL 5.7, и My SQL 8.0 продолжают обеспечивать это поведение, хотя оно должно быть включено явно. Поведение управляется режимом SQL ONLY_FULL_GROUP_BY, который установлен по умолчанию. Если вы окажетесь в ситуации, когда вам нужно перенести программу, основанную на устаревшем поведении GROUP BY, мы рекомендуем вам не прибегать к изменению режима SQL. Обычно есть два способа справиться с этой проблемой. Во-первых, нужно понять, требует ли вообще логика запроса неполной группировки, что случается редко. Во-вторых, существует поддержка поведения случайных данных для несгруппированных столбцов с помощью либо агрегатной функции, такой как MIN() или MAX(), либо специальной агрегатной функции ANY_VALUE(), которая, что неудивительно, просто создает случайное значение внутри группы. Далее мы более подробно рассмотрим агрегатные функции.
Агрегатные функции
Мы видели примеры того, как функция COUNT() может использоваться для определения количества строк в группе. Здесь мы рассмотрим некоторые другие функции, обычно используемые для изучения свойств агрегированных строк. Мы также немного расширим функцию COUNT(), так как она часто используется:
COUNT()-
Возвращает количество строк или количество значений в столбце. Помните, мы упоминали, что
COUNT(*)почти всегда эквивалентенCOUNT(<column>). Проблема сNULL.COUNT(*)будет подсчитывать возвращенные строки, независимо от того, является ли столбец в этих строкахNULLили нет. Однако при выполненииCOUNT(<column>)будут учитываться только значения, отличные отNULL. Например, в базе данныхsakilaадрес электронной почты клиента может бытьNULL, и мы можем наблюдать влияние:mysql> SELECT COUNT(*) FROM customer; +----------+ | count(*) | +----------+ | 599 | +----------+ 1 row in set (0.00 sec) mysql> SELECT COUNT(email) FROM customer; +--------------+ | count(email) | +--------------+ | 598 | +--------------+ 1 row in set (0.00 sec)Мы также должны добавить, что
COUNT()может быть запущен с внутренним предложениемDISTINCT, как вCOUNT(DISTINCT <column>), и в этом случае будет возвращать количество различных значений вместо всех значений. AVG()-
Возвращает среднее (среднее) значений в указанном столбце для всех строк в группе. Например, вы можете использовать его, чтобы найти среднюю стоимость дома в городе, когда дома сгруппированы по городам:
SELECT AVG(cost) FROM house_prices GROUP BY city; MAX()-
Возвращает максимальное значение из строк в группе. Например, вы можете использовать его для поиска самого теплого дня в месяце, когда строки сгруппированы по месяцам.
MIN()-
Возвращает минимальное значение из строк в группе. Например, вы можете использовать его для поиска самого младшего ученика в классе, когда строки сгруппированы по классам.
STD(), STDDEV(),иSTDDEV_POP()-
Возвращают стандартное отклонение значений из строк в группе. Например, вы можете использовать их, чтобы понять разброс результатов тестов, когда строки сгруппированы по университетским курсам. Все три из них являются синонимами.
STD()— это расширение MySQL,STDDEV()добавлено для совместимости с Oracle, аSTDDEV_POP()— стандартная функция SQL. SUM()-
Возвращает сумму значений из строк в группе. Например, вы можете использовать ее для вычисления суммы продаж в долларах в данном месяце, когда строки сгруппированы по месяцам.
Есть и другие функции, доступные для использования с GROUP BY, но они используются реже, чем те, которые мы представили здесь. Вы можете найти более подробную информацию о них в разделе описания агрегатных функций в Справочном руководстве по MySQL.
Предложение HAVING
Теперь вы знакомы с предложением GROUP BY, которое позволяет сортировать и группировать данные. Вы должны быть в состоянии использовать его, чтобы найти количество, средние значения, минимумы и максимумы. В этом разделе показано, как можно использовать предложение HAVING, чтобы получить дополнительный контроль над агрегированием строк в операции GROUP BY.
Предположим, вы хотите узнать, сколько популярных актеров есть в нашей базе данных. Вы решили считать актера популярным, если он снялся не менее чем в 40 фильмах. В предыдущем разделе мы попробовали почти идентичный запрос, но без ограничения популярности. Мы также обнаружили, что когда мы группировали актеров по имени и фамилии, мы теряли одну запись, поэтому мы добавим группировку в столбец actor_id, который, как мы знаем, уникален. Вот новый запрос с дополнительным предложением HAVING, которое добавляет ограничение:
mysql> SELECT first_name, last_name, COUNT(film_id)
-> FROM actor INNER JOIN film_actor USING (actor_id)
-> GROUP BY actor_id, first_name, last_name
-> HAVING COUNT(film_id) > 40
-> ORDER BY COUNT(film_id) DESC;
+------------+-----------+----------------+
| first_name | last_name | COUNT(film_id) |
+------------+-----------+----------------+
| GINA | DEGENERES | 42 |
| WALTER | TORN | 41 |
+------------+-----------+----------------+
2 rows in set (0.01 sec)
Вы видите, что только два актера соответствуют новым критериям.
Предложение HAVING должно содержать выражение или столбец, указанные в предложении SELECT. В этом примере мы использовали HAVING COUNT(film_id) >= 40, и вы можете видеть, что COUNT(film_id) является частью предложения SELECT. Как правило, выражение в предложении HAVING использует агрегатную функцию, такую как COUNT(), SUM(), MIN() или MAX(). Если вы обнаружите, что хотите написать предложение HAVING, в котором используется столбец или выражение, которых нет в предложении SELECT, скорее всего, вместо этого вам следует использовать предложение WHERE. Предложение HAVING предназначено только для принятия решения о том, как формировать каждую группу или кластер, а не для выбора строк в выходных данных. Позже мы покажем вам пример, иллюстрирующий, когда не следует использовать HAVING.
Давайте попробуем другой пример. Предположим, вам нужен список из 5 лучших фильмов, которые брали напрокат более 30 раз, вместе с количеством раз, которые они брали напрокат, в порядке популярности в обратном порядке. Вот запрос, который вы бы использовали:
mysql> SELECT title, COUNT(rental_id) AS num_rented FROM
-> film INNER JOIN inventory USING (film_id)
-> INNER JOIN rental USING (inventory_id)
-> GROUP BY title
-> HAVING num_rented > 30
-> ORDER BY num_rented DESC LIMIT 5;
+--------------------+------------+
| title | num_rented |
+--------------------+------------+
| BUCKET BROTHERHOOD | 34 |
| ROCKETEER MOTHER | 33 |
| FORWARD TEMPLE | 32 |
| GRIT CLOCKWORK | 32 |
| JUGGLER HARDLY | 32 |
+--------------------+------------+
5 rows in set (0.04 sec)
Вы снова можете видеть, что выражение COUNT() используется как в предложениях SELECT, так и в предложениях HAVING. Однако на этот раз мы присвоили функции COUNT(rental_id) псевдоним num_rented и использовали псевдоним в предложениях HAVING и ORDER BY.
Теперь давайте рассмотрим пример, в котором вам не следует использовать HAVING. Вы хотите узнать, в скольких фильмах сыграл тот или иной актер. Вот запрос, который вам не следует использовать:
mysql> SELECT first_name, last_name, COUNT(film_id) AS film_cnt FROM
-> actor INNER JOIN film_actor USING (actor_id)
-> GROUP BY actor_id, first_name, last_name
-> HAVING first_name = 'EMILY' AND last_name = 'DEE';
+------------+-----------+----------+
| first_name | last_name | film_cnt |
+------------+-----------+----------+
| EMILY | DEE | 14 |
+------------+-----------+----------+
1 row in set (0.02 sec)
Он получает правильный ответ, но неправильным — и, для больших объемов данных, гораздо более медленным — способом. Это неправильный способ написания запроса, потому что предложение HAVING не используется для определения того, какие строки должны формировать каждую группу, а вместо этого неправильно используется для фильтрации ответов для отображения. Для этого запроса мы действительно должны использовать предложение WHERE, как показано ниже:
mysql> SELECT first_name, last_name, COUNT(film_id) AS film_cnt FROM
-> actor INNER JOIN film_actor USING (actor_id)
-> WHERE first_name = 'EMILY' AND last_name = 'DEE'
-> GROUP BY actor_id, first_name, last_name;
+------------+-----------+----------+
| first_name | last_name | film_cnt |
+------------+-----------+----------+
| EMILY | DEE | 14 |
+------------+-----------+----------+
1 row in set (0.00 sec)
Этот правильный запрос формирует группы, а затем выбирает группы для отображения на основе предложения WHERE.
Расширенные соединения
До сих пор в книге мы использовали предложение INNER JOIN для объединения строк из двух или более таблиц. В этом разделе мы объясним внутреннее соединение более подробно, сравнивая его с другими типами соединений, которые мы обсуждаем: объединением, левым и правым соединениями и естественными соединениями. По завершении этого раздела вы сможете ответить на сложные информационные запросы и ознакомиться с правильным выбором соединения для выполнения поставленной задачи.
Внутреннее соединение
Предложение INNER JOIN сопоставляет строки между двумя таблицами на основе критериев, указанных в предложении USING. Например, теперь вы хорошо знакомы с внутренним соединением таблиц actor и film_actor:
mysql> SELECT first_name, last_name, film_id FROM
-> actor INNER JOIN film_actor USING (actor_id)
-> LIMIT 20;
+------------+-----------+---------+
| first_name | last_name | film_id |
+------------+-----------+---------+
| PENELOPE | GUINESS | 1 |
| PENELOPE | GUINESS | 23 |
| ... |
| PENELOPE | GUINESS | 980 |
| NICK | WAHLBERG | 3 |
+------------+-----------+---------+
20 rows in set (0.00 sec)
Давайте рассмотрим ключевые особенности INNER JOIN:
-
Две таблицы (или результаты предыдущего соединения) перечислены по обе стороны от ключевой фразы
INNER JOIN. -
Предложение
USINGопределяет один или несколько столбцов, которые находятся как в таблицах, так и в результатах и используются для соединения или сопоставления строк. -
Строки, которые не совпадают, не возвращаются. Например, если у вас есть строка в таблице
actor, для которой нет соответствующих фильмов в таблицеfilm_actor, она не будет включена в выходные данные.
На самом деле вы можете писать запросы внутреннего соединения с предложением WHERE без использования ключевой фразы INNER JOIN. Вот переписанная версия предыдущего запроса, которая дает тот же результат:
mysql> SELECT first_name, last_name, film_id
-> FROM actor, film_actor
-> WHERE actor.actor_id = film_actor.actor_id
-> LIMIT 20;
+------------+-----------+---------+
| first_name | last_name | film_id |
+------------+-----------+---------+
| PENELOPE | GUINESS | 1 |
| PENELOPE | GUINESS | 23 |
| ... |
| PENELOPE | GUINESS | 980 |
| NICK | WAHLBERG | 3 |
+------------+-----------+---------+
20 rows in set (0.00 sec)
Вы можете видеть, что мы не расписали внутреннее соединение: мы выбираем из таблиц actor и film_actor строки, в которых идентификаторы совпадают между таблицами.
Вы можете изменить синтаксис INNER JOIN, чтобы выразить критерии соединения способом, аналогичным использованию предложения WHERE. Это полезно, если имена идентификаторов в таблицах не совпадают, хотя в данном примере это не так. Вот предыдущий запрос, переписанный в таком стиле:
mysql> SELECT first_name, last_name, film_id FROM
-> actor INNER JOIN film_actor
-> ON actor.actor_id = film_actor.actor_id
-> LIMIT 20;
+------------+-----------+---------+
| first_name | last_name | film_id |
+------------+-----------+---------+
| PENELOPE | GUINESS | 1 |
| PENELOPE | GUINESS | 23 |
| ... |
| PENELOPE | GUINESS | 980 |
| NICK | WAHLBERG | 3 |
+------------+-----------+---------+
20 rows in set (0.00 sec)
Вы можете видеть, что предложение ON заменяет предложение USING и что следующие за ним столбцы полностью определены и включают имена таблиц и столбцов. Если бы столбцы были названы по-разному и уникально между двумя таблицами, вы могли бы опустить имена таблиц. Нет никаких реальных преимуществ или недостатков в использовании предложения ON или WHERE; это просто дело вкуса. Как правило, в наши дни вы обнаружите, что большинство специалистов по SQL используют INNER JOIN с предложением ON, а не WHERE, но это не универсально.
Прежде чем мы двинемся дальше, давайте рассмотрим, для чего служат предложения WHERE, ON и USING. Если вы опустите предложение WHERE в запросе, который мы вам только что показали, вы получите совсем другой результат. Вот запрос и первые несколько строк вывода:
mysql> SELECT first_name, last_name, film_id
-> FROM actor, film_actor LIMIT 20;
+------------+-------------+---------+
| first_name | last_name | film_id |
+------------+-------------+---------+
| THORA | TEMPLE | 1 |
| JULIA | FAWCETT | 1 |
| ... |
| DEBBIE | AKROYD | 1 |
| MATTHEW | CARREY | 1 |
+------------+-------------+---------+
20 rows in set (0.00 sec)
Вывод не имеет смысла: произошло то, что каждая строка из таблицы actor была выведена вместе с каждой строкой из таблицы film_actor для всех возможных комбинаций. Поскольку в таблице film_actor 200 актеров и 5 462 записи, в выводе 200 × 5 462 = 1 092 400 строк, и мы знаем, что только 5 462 из этих комбинаций действительно имеют смысл (всего 5 462 записи для актеров, сыгравших в фильмах). Мы можем увидеть количество строк, которые мы получили бы без LIMIT, с помощью следующего запроса:
mysql> SELECT COUNT(*) FROM actor, film_actor;
+----------+
| COUNT(*) |
+----------+
| 1092400 |
+----------+
1 row in set (0.00 sec)
Этот тип запроса без предложения, которое соответствует строкам, известен как декартово произведение. Между прочим, вы также получите декартово произведение, если выполните внутреннее соединение без указания столбца с предложением USING или ON, как в этом запросе:
SELECT first_name, last_name, film_id
FROM actor INNER JOIN film_actor;
В разделе «Естественное соединение» мы представим естественное соединение, которое представляет собой внутреннее соединение столбцов с одинаковыми именами. Хотя естественное соединение не использует явно указанные столбцы, оно по-прежнему создает внутреннее соединение, а не декартово произведение.
Ключевую фразу INNER JOIN можно заменить на JOIN или STRAIGHT JOIN; все они делают одно и то же. Однако STRAIGHT JOIN заставляет MySQL всегда читать таблицу слева, прежде чем читать таблицу справа. Мы рассмотрим, как MySQL обрабатывает запросы за кулисами, в главе 7. Ключевая фраза JOIN используется чаще всего: это стандартное сокращение для INNER JOIN, используемое многими другими системами баз данных, помимо MySQL, и мы будет использовать его в большинстве наших примеров внутреннего соединения.
Объединение (UNION)
Оператор UNION на самом деле не является оператором соединения. Скорее, он позволяет вам комбинировать вывод более чем одного оператора SELECT, чтобы получить объединенный набор результатов. Это полезно в тех случаях, когда вы хотите создать один список из более чем одного источника или хотите создать списки из одного источника, которые трудно выразить в одном запросе.
Давайте посмотрим на пример. Если вы хотите вывести имена всех актеров и фильмов и клиентов в базе данных sakila, вы можете сделать это с помощью оператора UNION. Это надуманный пример, но вы можете сделать это только для того, чтобы перечислить все текстовые фрагменты, а не для осмысленного представления взаимосвязей в данных. В столбцах actor.first_name, film.title и customer.first_name есть текст. Вот как это отобразить:
mysql> SELECT first_name FROM actor
-> UNION
-> SELECT first_name FROM customer
-> UNION
-> SELECT title FROM film;
+-----------------------------+
| first_name |
+-----------------------------+
| PENELOPE |
| NICK |
| ED |
| ... |
| ZHIVAGO CORE |
| ZOOLANDER FICTION |
| ZORRO ARK |
+-----------------------------+
1647 rows in set (0.00 sec)
Мы показали только несколько строк из 1647. Оператор UNION выводит результаты всех запросов вместе под заголовком, соответствующим первому запросу.
Чуть менее надуманный пример — создать список из пяти наиболее и наименее продаваемых фильмов в нашей базе данных. Вы можете легко сделать это с помощью оператора UNION:
mysql> (SELECT title, COUNT(rental_id) AS num_rented
-> FROM film JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> GROUP BY title ORDER BY num_rented DESC LIMIT 5)
-> UNION
-> (SELECT title, COUNT(rental_id) AS num_rented
-> FROM film JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> GROUP BY title ORDER BY num_rented ASC LIMIT 5);
+--------------------+------------+
| title | num_rented |
+--------------------+------------+
| BUCKET BROTHERHOOD | 34 |
| ROCKETEER MOTHER | 33 |
| FORWARD TEMPLE | 32 |
| GRIT CLOCKWORK | 32 |
| JUGGLER HARDLY | 32 |
| TRAIN BUNCH | 4 |
| HARDLY ROBBERS | 4 |
| MIXED DOORS | 4 |
| BUNCH MINDS | 5 |
| BRAVEHEART HUMAN | 5 |
+--------------------+------------+
10 rows in set (0.04 sec)
Первый запрос использует ORDER BY с модификатором DESC (по убыванию) и предложением LIMIT 5, чтобы найти пять самых популярных фильмов. Второй запрос использует ORDER BY с модификатором ASC (по возрастанию) и предложением LIMIT 5, чтобы найти пять фильмов, которые берут напрокат меньше всего. UNION объединяет наборы результатов. Обратите внимание, что существует несколько заголовков с одинаковым значением num_rented, и не гарантируется, что порядок заголовков с одинаковым значением будет определен. Вы можете увидеть различные заголовки, перечисленные для значений num_rented 32 и 5 на вашей стороне.
Оператор UNION имеет несколько ограничений:
-
Выходные данные помечаются именами столбцов или выражений из первого запроса. Используйте псевдонимы столбцов, чтобы изменить это поведение.
-
Запросы должны выводить одинаковое количество столбцов. Если вы попытаетесь использовать другое количество столбцов, MySQL сообщит об ошибке.
-
Все соответствующие столбцы должны иметь один и тот же тип. Так, например, если первый столбец, выводимый из первого запроса, является датой, первый столбец, выводимый из любого другого запроса, также должен быть датой.
-
Возвращаемые результаты уникальны, как если бы вы применили
DISTINCTко всему набору результатов. Чтобы увидеть это в действии, давайте рассмотрим простой пример. Помните, у нас были проблемы с именами актеров — имя — плохой уникальный идентификатор. Если мы выберем двух актеров с одинаковым именем и объединим (UNION) два запроса, мы получим только одну строку. Неявная операцияDISTINCTскрывает повторяющиеся (дляUNION) строки:mysql> SELECT first_name FROM actor WHERE actor_id = 88 -> UNION -> SELECT first_name FROM actor WHERE actor_id = 169; +------------+ | first_name | +------------+ | KENNETH | +------------+ 1 row in set (0.01 sec)Если вы хотите показать дубликаты, замените UNION на UNION ALL:
mysql> SELECT first_name FROM actor WHERE actor_id = 88 -> UNION ALL -> SELECT first_name FROM actor WHERE actor_id = 169; +------------+ | first_name | +------------+ | KENNETH | | KENNETH | +------------+ 2 rows in set (0.00 sec)Здесь имя
КЕННЕТвстречается дважды.Неявный
DISTINCT, который выполняетUNION, имеет ненулевую стоимость с точки зрения производительности. Всякий раз, когда вы используетеUNION, смотрите, подходит лиUNION ALLлогически и может ли он улучшить производительность запросов. -
Если вы хотите применить
LIMITилиORDER BYк отдельному запросу, являющемуся частью оператораUNION, заключите этот запрос в круглые скобки (как показано в предыдущем примере). В любом случае полезно использовать круглые скобки, чтобы упростить понимание запроса.Операция
UNIONпросто объединяет результаты запросов компонентов без учета порядка, поэтому нет особого смысла использоватьORDER BYв одном из подзапросов. Единственный случай, когда имеет смысл заказать подзапрос в операцииUNION, — это когда вы хотите выбрать подмножество результатов. В нашем примере мы упорядочили фильмы по количеству прокатов, а затем выбрали только первые пять (в первом подзапросе) и последние пять (во втором подзапросе).Для эффективности MySQL фактически игнорирует предложение
ORDER BYв подзапросе, если оно используется безLIMIT. Давайте рассмотрим несколько примеров, чтобы увидеть, как именно это работает.Во-первых, давайте запустим простой запрос, чтобы вывести информацию о прокате для определенного фильма, а также время проката. Мы заключили запрос в круглые скобки для согласованности с другими нашими примерами — круглые скобки здесь фактически не имеют никакого значения — и не использовали предложение
ORDER BYилиLIMIT:mysql> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998); +--------------+---------------------+---------------------+ | title | rental_date | return_date | +--------------+---------------------+---------------------+ | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-27 14:53:55 | 2005-07-31 19:48:55 | | ZHIVAGO CORE | 2005-08-20 17:18:48 | 2005-08-26 15:31:48 | | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | | ZHIVAGO CORE | 2005-08-02 02:05:04 | 2005-08-10 21:58:04 | | ZHIVAGO CORE | 2006-02-14 15:16:03 | NULL | +--------------+---------------------+---------------------+ 9 rows in set (0.00 sec)Запрос возвращает все случаи проката фильма в произвольном порядке (см. четвертую и пятую записи).
Теперь давайте добавим в этот запрос предложение
ORDER BY:mysql> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC); +--------------+---------------------+---------------------+ | title | rental_date | return_date | +--------------+---------------------+---------------------+ | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | | ZHIVAGO CORE | 2005-07-27 14:53:55 | 2005-07-31 19:48:55 | | ZHIVAGO CORE | 2005-08-02 02:05:04 | 2005-08-10 21:58:04 | | ZHIVAGO CORE | 2005-08-20 17:18:48 | 2005-08-26 15:31:48 | | ZHIVAGO CORE | 2006-02-14 15:16:03 | NULL | +--------------+---------------------+---------------------+ 9 rows in set (0.00 sec)Как и ожидалось, мы получаем все случаи проката фильма в порядке даты проката.
Добавление предложения
LIMITк предыдущему запросу выбирает первые пять арендных плат в хронологическом порядке — здесь никаких сюрпризов:mysql> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC LIMIT 5); +--------------+---------------------+---------------------+ | title | rental_date | return_date | +--------------+---------------------+---------------------+ | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | +--------------+---------------------+---------------------+ 5 rows in set (0.01 sec)Теперь давайте посмотрим, что произойдет, когда мы выполним операцию
UNION. В этом примере мы используем два подзапроса, каждый с предложениемORDER BY. Мы использовали предложениеLIMITдля второго подзапроса, но не для первого:mysql> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC) -> UNION ALL -> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC LIMIT 5); +--------------+---------------------+---------------------+ | title | rental_date | return_date | +--------------+---------------------+---------------------+ | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-27 14:53:55 | 2005-07-31 19:48:55 | | ZHIVAGO CORE | 2005-08-20 17:18:48 | 2005-08-26 15:31:48 | | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | | ZHIVAGO CORE | 2005-08-02 02:05:04 | 2005-08-10 21:58:04 | | ZHIVAGO CORE | 2006-02-14 15:16:03 | NULL | | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | +--------------+---------------------+---------------------+ 14 rows in set (0.01 sec)Как и ожидалось, первый подзапрос возвращает все случаи проката фильма (первые девять строк этого вывода), а второй подзапрос возвращает первые пять прокатов (последние пять строк этого вывода). Обратите внимание, что первые девять строк расположены не по порядку (см. четвертую и пятую строки), хотя в первом подзапросе есть предложение
ORDER BY. Поскольку мы выполняем операциюUNION, сервер MySQL решил, что нет смысла сортировать результаты подзапроса. Второй подзапрос включает операциюLIMIT, поэтому результаты этого подзапроса сортируются.Не гарантируется, что выходные данные операции
UNIONбудут упорядочены, даже если упорядочены подзапросы, поэтому, если вы хотите, чтобы окончательный вывод был упорядоченным, вы должны добавить предложениеORDER BYв конце всего запроса. Обратите внимание, что это может быть в другом порядке от подзапросов. См. следующее:mysql> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC) -> UNION ALL -> (SELECT title, rental_date, return_date -> FROM film JOIN inventory USING (film_id) -> JOIN rental USING (inventory_id) -> WHERE film_id = 998 -> ORDER BY rental_date ASC LIMIT 5) -> ORDER BY rental_date DESC; +--------------+---------------------+---------------------+ | title | rental_date | return_date | +--------------+---------------------+---------------------+ | ZHIVAGO CORE | 2006-02-14 15:16:03 | NULL | | ZHIVAGO CORE | 2005-08-20 17:18:48 | 2005-08-26 15:31:48 | | ZHIVAGO CORE | 2005-08-02 02:05:04 | 2005-08-10 21:58:04 | | ZHIVAGO CORE | 2005-07-27 14:53:55 | 2005-07-31 19:48:55 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | | ZHIVAGO CORE | 2005-07-12 05:24:02 | 2005-07-16 03:43:02 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-07-07 12:18:57 | 2005-07-12 09:47:57 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-06-18 06:46:54 | 2005-06-26 09:48:54 | | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-06-17 03:19:20 | 2005-06-21 00:19:20 | | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | | ZHIVAGO CORE | 2005-05-30 05:15:20 | 2005-06-07 00:49:20 | +--------------+---------------------+---------------------+ 14 rows in set (0.00 sec)Вот еще один пример сортировки окончательных результатов, включая ограничение на количество возвращаемых результатов:
mysql> (SELECT first_name, last_name FROM actor WHERE actor_id < 5) -> UNION -> (SELECT first_name, last_name FROM actor WHERE actor_id > 190) -> ORDER BY first_name LIMIT 4; +------------+-----------+ | first_name | last_name | +------------+-----------+ | BELA | WALKEN | | BURT | TEMPLE | | ED | CHASE | | GREGORY | GOODING | +------------+-----------+ 4 rows in set (0.00 sec)Операция
UNIONнесколько громоздка, и обычно существуют альтернативные способы получения того же результата. Например, предыдущий запрос можно было бы написать проще:mysql> SELECT first_name, last_name FROM actor -> WHERE actor_id < 5 OR actor_id > 190 -> ORDER BY first_name LIMIT 4; +------------+-----------+ | first_name | last_name | +------------+-----------+ | BELA | WALKEN | | BURT | TEMPLE | | ED | CHASE | | GREGORY | GOODING | +------------+-----------+ 4 rows in set (0.00 sec)
Левое и правое соединение
Соединения, которые мы обсуждали до сих пор, выводят только те строки, которые совпадают между таблицами. Например, когда вы объединяете таблицы film и rental через таблицу inventory, вы видите только те фильмы, которые были взяты напрокат. Строки для фильмов, которые не были взяты напрокат, игнорируются. Во многих случаях это имеет смысл, но это не единственный способ объединения данных. В этом разделе объясняются другие варианты, которые у вас есть.
Предположим, вам нужен исчерпывающий список всех фильмов и количество раз, когда они были взяты напрокат. В отличие от примера, приведенного ранее в этой главе, включенного в список, вы хотите видеть ноль рядом с фильмами, которые не были взяты в прокат. Вы можете сделать это с помощью левого соединения (left join), другого типа соединения, которое управляется одной из двух таблиц, участвующих в объединении. В левом объединении каждая строка в левой таблице — та, которая выполняет роль управляющей — обрабатывается и выводится с соответствующими данными из второй таблицы, если она существует, и значениями NULL, если во второй таблице нет соответствующих данных. Позже в этом разделе мы покажем вам, как написать этот тип запроса, но начнем с более простого примера.
Вот простой пример LEFT JOIN. Вы хотите перечислить все фильмы и рядом с каждым фильмом, который вы хотите показать, когда он был взят напрокат. Если фильм никогда не брали напрокат, вы хотите его посмотреть. Если его много раз сдавали в аренду, вы тоже хотите это увидеть. Вот запрос:
mysql> SELECT title, rental_date
-> FROM film LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id);
+-----------------------------+---------------------+
| title | rental_date |
+-----------------------------+---------------------+
| ACADEMY DINOSAUR | 2005-07-08 19:03:15 |
| ACADEMY DINOSAUR | 2005-08-02 20:13:10 |
| ACADEMY DINOSAUR | 2005-08-21 21:27:43 |
| ... |
| WAKE JAWS | NULL |
| WALLS ARTIST | NULL |
| ... |
| ZORRO ARK | 2005-07-31 07:32:21 |
| ZORRO ARK | 2005-08-19 03:49:28 |
+-----------------------------+---------------------+
16087 rows in set (0.06 sec)
Вы можете видеть, что происходит: фильмы, которые были взяты напрокат, имеют дату и время, а те, которые не были взяты напрокат, — нет (значение rental_date равно NULL). Обратите также внимание, что в этом примере мы дважды использовали LEFT JOIN. Сначала мы соединяем film и inventory, и мы хотим убедиться, что даже если фильм не находится в нашем списке (и, следовательно, не может быть взят напрокат по определению), мы все равно выводим его. Затем мы соединяем таблицу rental с набором данных, полученным в результате предыдущего соединения. Мы снова используем LEFT JOIN, так как у нас могут быть фильмы, которых нет в нашем списке, и у них не будет строк в таблице rental. Однако у нас также могут быть фильмы, перечисленные в нашем списке, которые просто не были взяты напрокат. Вот почему нам нужно соединение LEFT JOIN обеих таблиц здесь.
Порядок таблиц в LEFT JOIN важен. Если вы измените порядок в предыдущем запросе, вы получите совсем другой результат:
mysql> SELECT title, rental_date
-> FROM rental LEFT JOIN inventory USING (inventory_id)
-> LEFT JOIN film USING (film_id)
-> ORDER BY rental_date DESC;
+-----------------------------+---------------------+
| title | rental_date |
+-----------------------------+---------------------+
| ... |
| LOVE SUICIDES | 2005-05-24 23:04:41 |
| GRADUATE LORD | 2005-05-24 23:03:39 |
| FREAKY POCUS | 2005-05-24 22:54:33 |
| BLANKET BEVERLY | 2005-05-24 22:53:30 |
+-----------------------------+---------------------+
16044 rows in set (0.06 sec)
В этой версии запрос управляется таблицей rental, поэтому все строки из нее сопоставляются с таблицей inventory, а затем с film. Поскольку все строки в таблице rental по определению основаны на таблице inventory, которая связана с таблицей film, в выводе нет значений NULL. Не может быть проката фильма, которого не существует. Мы скорректировали запрос с помощью ORDER BY rent_date DESC, чтобы показать, что мы действительно не получили никаких значений NULL (они были бы последними).
Теперь вы можете видеть, что левое соединение полезно, когда мы уверены, что в левой таблице есть какие-то важные данные, но мы не уверены, есть ли они в правой таблице. Мы хотим получить строки из левой с соответствующими строками из правой или без них. Давайте попробуем применить это к запросу, который мы написали в «Предложении GROUP BY», который показал, что клиенты арендуют участки одной и той же категории. Вот запрос, как напоминание:
mysql> SELECT email, name AS category_name, COUNT(cat.category_id) AS cnt
-> FROM customer cs INNER JOIN rental USING (customer_id)
-> INNER JOIN inventory USING (inventory_id)
-> INNER JOIN film_category USING (film_id)
-> INNER JOIN category cat USING (category_id)
-> GROUP BY email, category_name
-> ORDER BY cnt DESC LIMIT 5;
+----------------------------------+---------------+-----+
| email | category_name | cnt |
+----------------------------------+---------------+-----+
| WESLEY.BULL@sakilacustomer.org | Games | 9 |
| ALMA.AUSTIN@sakilacustomer.org | Animation | 8 |
| KARL.SEAL@sakilacustomer.org | Animation | 8 |
| LYDIA.BURKE@sakilacustomer.org | Documentary | 8 |
| NATHAN.RUNYON@sakilacustomer.org | Animation | 7 |
+----------------------------------+---------------+-----+
5 rows in set (0.06 sec)
Что, если мы теперь хотим узнать, берет ли клиент, которого мы таким образом нашли, фильмы из какой-либо другой категории, кроме своей любимой? Оказывается, это довольно сложно!
Рассмотрим эту задачу. Нам нужно начать с таблицы category, так как в ней будут все категории для наших фильмов. Затем нам нужно начать строить целую цепочку левых соединений. Сначала мы делаем левое соединение category с film_category, так как у нас могут быть категории без фильмов. Затем мы левое соединение результата с таблицей inventory, так как некоторые фильмы, о которых мы знаем, могут отсутствовать в нашем каталоге. Затем делаем левое соединение этого результата к таблице rental, поскольку клиенты могли не брать напрокат некоторые фильмы в категории. Наконец, нам нужно левое соединение этого результата с нашей таблицей customer. Несмотря на то, что не может быть связанной записи о клиенте без аренды, пропуск левого соединения здесь приведет к тому, что MySQL отбросит строки для категорий, которые заканчиваются без записей о клиентах.
Теперь, после всего этого длинного объяснения, можем ли мы, наконец, продолжить фильтрацию по адресу электронной почты и получить наши данные? Нет! К сожалению, добавляя к таблице условие WHERE, которого нет в нашем отношении левого соединения, мы ломаем идею этого соединения. Посмотрите, что происходит:
mysql> SELECT COUNT(*) FROM category;
+----------+
| COUNT(*) |
+----------+
| 16 |
+----------+
1 row in set (0.00 sec)
mysql> SELECT email, name AS category_name, COUNT(category_id) AS cnt
-> FROM category cat LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> JOIN customer cs ON rental.customer_id = cs.customer_id
-> WHERE cs.email = 'WESLEY.BULL@sakilacustomer.org'
-> GROUP BY email, category_name
-> ORDER BY cnt DESC;
+--------------------------------+---------------+-----+
| email | category_name | cnt |
+--------------------------------+---------------+-----+
| WESLEY.BULL@sakilacustomer.org | Games | 9 |
| WESLEY.BULL@sakilacustomer.org | Foreign | 6 |
| ... |
| WESLEY.BULL@sakilacustomer.org | Comedy | 1 |
| WESLEY.BULL@sakilacustomer.org | Sports | 1 |
+--------------------------------+---------------+-----+
14 rows in set (0.00 sec)
Мы получили 14 категорий для нашего клиента, а всего их 16. На самом деле, MySQL оптимизирует все левые соединения в этом запросе, так как понимает, что они бессмысленны в таком виде. Нет простого способа ответить на вопрос, который у нас есть, используя только соединения — мы вернемся к этому примеру в разделе «Вложенные запросы в соединениях».
Тем не менее, запрос, который мы написали, по-прежнему полезен. Хотя по умолчанию у sakila нет категории фильмов, в которой нет фильмов, взятых напрокат, если мы немного расширим нашу базу данных, мы увидим эффективность левых соединений:
mysql> INSERT INTO category(name) VALUES ('Thriller');
Query OK, 1 row affected (0.01 sec)
mysql> SELECT cat.name, COUNT(rental_id) cnt
-> FROM category cat LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> LEFT JOIN customer cs ON rental.customer_id = cs.customer_id
-> GROUP BY 1
-> ORDER BY 2 DESC;
+---------------+------+
| category_name | cnt |
+---------------+------+
| Sports | 1179 |
| Animation | 1166 |
| ... |
| Music | 830 |
| Thriller | 0 |
+---------------+------+
17 rows in set (0.07 sec)
Если бы мы использовали здесь обычное INNER JOIN (или просто JOIN, его синоним), мы не получили бы информацию для категории Thriller, и мы могли бы получить другие значения для других категорий. Поскольку category — наша самая левая таблица, она управляет процессом запроса, и каждая строка из этой таблицы присутствует в выводе.
Мы показали вам, что имеет значение то, что идет до и после ключевой фразы LEFT JOIN. То, что находится слева, управляет процессом, отсюда и название «left join». Если вы действительно не хотите реорганизовывать свой запрос, чтобы он соответствовал этому шаблону, вы можете использовать RIGHT JOIN. Это точно то же самое, за исключением того, что то, что находится справа, управляет процессом.
Ранее мы показали важность порядка таблиц в левом соединении, используя два запроса информации о прокате фильмов. Перепишем второй из них (который показывал неверные данные), используя правое соединение:
mysql> SELECT title, rental_date
-> FROM rental RIGHT JOIN inventory USING (inventory_id)
-> RIGHT JOIN film USING (film_id)
-> ORDER BY rental_date DESC;
...
| SUICIDES SILENCE | NULL |
| TADPOLE PARK | NULL |
| TREASURE COMMAND | NULL |
| VILLAIN DESPERATE | NULL |
| VOLUME HOUSE | NULL |
| WAKE JAWS | NULL |
| WALLS ARTIST | NULL |
+-----------------------------+---------------------+
16087 rows in set (0.06 sec)
Мы получили такое же количество строк, и мы видим, что значения NULL такие же, как те, которые дал нам «правильный» запрос. Правое соединение иногда полезно, потому что оно позволяет написать запрос более естественно, выражая его более интуитивно. Тем не менее, вы не часто увидите его использование, и мы рекомендуем избегать его, где это возможно.
Как левое, так и правое соединение могут использовать предложения USING и ON, описанные в разделе «Внутреннее соединение». Вы должны использовать один или другой: без них вы получите декартово произведение, как обсуждалось в этом разделе.
Также есть дополнительное ключевое слово OUTER, которое вы можете при желании использовать в левом и правом соединениях, чтобы они читались как LEFT OUTER JOIN и RIGHT OUTER JOIN. Это просто альтернативный синтаксис, который не делает ничего другого, и вы не часто увидите его использование. В этой книге мы придерживаемся основных версий.
Естественное соединение
Мы не большие поклонники естественного соединения, которое мы описываем в этом разделе. Оно включено сюда только для полноты, а также потому, что вы увидите, что оно иногда используется в операторах SQL, с которыми вы столкнетесь. Наш совет — по возможности избегать его использования.
Естественное соединение должно быть волшебным образом естественным. Это означает, что вы сообщаете MySQL, к каким таблицам вы хотите присоединиться, и она выясняет, как это сделать, и выдает вам набор результатов INNER JOIN. Вот пример для таблиц actor_info и film_actor:
mysql> SELECT first_name, last_name, film_id
-> FROM actor_info NATURAL JOIN film_actor
-> LIMIT 20;
+------------+-----------+---------+
| first_name | last_name | film_id |
+------------+-----------+---------+
| PENELOPE | GUINESS | 1 |
| PENELOPE | GUINESS | 23 |
| ... |
| PENELOPE | GUINESS | 980 |
| NICK | WAHLBERG | 3 |
+------------+-----------+---------+
20 rows in set (0.28 sec)
На самом деле это не совсем волшебство: все, что MySQL делает, это ищет столбцы с одинаковыми именами и незаметно добавляет их во внутреннее соединение с условиями соединения, записанными в предложении WHERE. Итак, предыдущий запрос на самом деле переводится примерно так:
mysql> SELECT first_name, last_name, film_id FROM
-> actor_info JOIN film_actor
-> WHERE (actor_info.actor_id = film_actor.actor_id)
-> LIMIT 20;
Если столбцы идентификаторов не имеют одинаковых имен, естественные соединения не будут работать. Кроме того, что более опасно, если столбцы с одинаковыми именами не являются идентификаторами, они все равно попадут в закулисное предложение USING. Вы можете очень легко увидеть это в базе данных sakila. На самом деле, именно поэтому мы прибегли к показу предыдущего примера с actor_info, который даже не является таблицей: это представление. Давайте посмотрим, что было бы, если бы мы использовали обычные таблицы actor и film_actor:
mysql> SELECT first_name, last_name, film_id FROM actor NATURAL JOIN film_actor;
Empty set (0.01 sec)
Но как? Проблема в том, что NATURAL JOIN действительно учитывает все столбцы. С базой данных sakila это огромное препятствие, так как в каждой таблице есть столбец last_update. Если бы вы выполнили оператор EXPLAIN для предыдущего запроса, а затем выполнили бы SHOW WARNINGS, вы бы увидели, что результирующий запрос бессмысленен:
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `sakila`.`customer`.`email` AS `email`,
`sakila`.`rental`.`rental_date` AS `rental_date`
from `sakila`.`customer` join `sakila`.`rental`
where ((`sakila`.`rental`.`last_update` = `sakila`.`customer`.`last_update`)
and (`sakila`.`rental`.`customer_id` = `sakila`.`customer`.`customer_id`))
1 row in set (0.00 sec)
Иногда вы будете видеть естественное соединение, смешанное с левым и правым соединением. Допустимы следующие синтаксисы соединения: NATURAL LEFT JOIN, NATURAL LEFT OUTER JOIN, NATURAL RIGHT JOIN и NATURAL RIGHT OUTER JOIN. Первые два являются левыми соединениями без предложений ON или USING, а последние два являются правыми соединениями. Опять же, по возможности избегайте их написания, но вы должны понимать, что они означают, если видите, что они используются.
Константные выражения в соединениях
Во всех приведенных нами примерах соединений мы использовали идентификаторы столбцов для определения условия соединения. Когда вы используете предложение USING, это единственный возможный путь. Когда вы определяете условия соединения в предложении WHERE, это единственное, что будет работать. Однако, когда вы используете предложение ON, вы можете добавлять константные выражения.
Рассмотрим пример, перечислив все фильмы для конкретного актера:
mysql> SELECT first_name, last_name, title
-> FROM actor JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> WHERE actor_id = 11;
+------------+-----------+--------------------+
| first_name | last_name | title |
+------------+-----------+--------------------+
| ZERO | CAGE | CANYON STOCK |
| ZERO | CAGE | DANCES NONE |
| ... |
| ZERO | CAGE | WEST LION |
| ZERO | CAGE | WORKER TARZAN |
+------------+-----------+--------------------+
25 rows in set (0.00 sec)
Мы можем переместить предложение actor_id в соединение следующим образом:
mysql> SELECT first_name, last_name, title
-> FROM actor JOIN film_actor
-> ON actor.actor_id = film_actor.actor_id
-> AND actor.actor_id = 11
-> JOIN film USING (film_id);
+------------+-----------+--------------------+
| first_name | last_name | title |
+------------+-----------+--------------------+
| ZERO | CAGE | CANYON STOCK |
| ZERO | CAGE | DANCES NONE |
| ... |
| ZERO | CAGE | WEST LION |
| ZERO | CAGE | WORKER TARZAN |
+------------+-----------+--------------------+
25 rows in set (0.00 sec)
Ну, красиво, конечно, но зачем? Является ли это более выразительным, чем правильное предложение WHERE? Ответ на оба вопроса заключается в том, что постоянные условия в соединениях оцениваются и разрешаются иначе, чем условия в предложении WHERE. Легче показать это на примере, но предыдущий запрос неудачный. Влияние постоянных условий в соединениях лучше всего видно на примере левого соединения.
Помните этот запрос из раздела о левых соединениях:
mysql> SELECT email, name AS category_name, COUNT(rental_id) AS cnt
-> FROM category cat LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> LEFT JOIN customer cs USING (customer_id)
-> WHERE cs.email = 'WESLEY.BULL@sakilacustomer.org'
-> GROUP BY email, category_name
-> ORDER BY cnt DESC;
+--------------------------------+---------------+-----+
| email | category_name | cnt |
+--------------------------------+---------------+-----+
| WESLEY.BULL@sakilacustomer.org | Games | 9 |
| WESLEY.BULL@sakilacustomer.org | Foreign | 6 |
| ... |
| WESLEY.BULL@sakilacustomer.org | Comedy | 1 |
| WESLEY.BULL@sakilacustomer.org | Sports | 1 |
+--------------------------------+---------------+-----+
14 rows in set (0.01 sec)
Если мы продолжим и переместим предложение cs.email в часть LEFT JOIN customer cs, мы увидим совершенно другие результаты:
mysql> SELECT email, name AS category_name, COUNT(rental_id) AS cnt
-> FROM category cat LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> LEFT JOIN customer cs ON rental.customer_id = cs.customer_id
-> AND cs.email = 'WESLEY.BULL@sakilacustomer.org'
-> GROUP BY email, category_name
-> ORDER BY cnt DESC;
+--------------------------------+-------------+------+
| email | name | cnt |
+--------------------------------+-------------+------+
| NULL | Sports | 1178 |
| NULL | Animation | 1164 |
| ... |
| NULL | Travel | 834 |
| NULL | Music | 829 |
| WESLEY.BULL@sakilacustomer.org | Games | 9 |
| WESLEY.BULL@sakilacustomer.org | Foreign | 6 |
| ... |
| WESLEY.BULL@sakilacustomer.org | Comedy | 1 |
| NULL | Thriller | 0 |
+--------------------------------+-------------+------+
31 rows in set (0.07 sec)
Это интересно! Вместо того, чтобы получать количество арендной платы только для Wesley по категориям, мы также получаем количество арендных платежей для всех остальных с разбивкой по категориям. Сюда входит даже наша новая и пока пустая категория Thriller. Попробуем понять, что здесь происходит.
Содержимое предложения WHERE применяется логически после разрешения и выполнения объединений. Мы сообщаем MySQL, что нам нужны только строки из того, к чему мы присоединяемся, где столбец cs.email равен 'WESLEY.BULL@sakilacustomer.org'. На самом деле MySQL достаточно умен, чтобы оптимизировать эту ситуацию, и фактически начнет выполнение плана, как если бы использовались обычные внутренние соединения. Когда у нас есть условие cs.email в предложении клиента LEFT JOIN, мы сообщаем MySQL, что хотим добавить столбцы из таблицы customer в наш набор результатов (который включает в себя таблицы category, inventory и rental), но только когда определенное значение присутствует в столбце email. Поскольку это LEFT JOIN, мы получаем NULL в каждом столбце клиента в строках, которые не совпадают.
Важно знать об этом поведении.
Вложенные запросы
Вложенные запросы, поддерживаемые MySQL начиная с версии 4.1, наиболее сложны для изучения. Однако они обеспечивают мощный, полезный и лаконичный способ выражения сложных информационных потребностей в коротких операторах SQL. В этом разделе они объясняются, начиная с простых примеров и заканчивая более сложными функциями операторов EXISTS и IN. К концу этого раздела вы изучите все, что содержится в этой книге о запросах данных, и поймете практически любой SQL-запрос, с которым столкнетесь.
Основы вложенных запросов
Вы знаете, как найти имена всех актеров, сыгравших в определенном фильме, с помощью INNER JOIN:
mysql> SELECT first_name, last_name FROM
-> actor JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> WHERE title = 'ZHIVAGO CORE';
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| UMA | WOOD |
| NICK | STALLONE |
| GARY | PENN |
| SALMA | NOLTE |
| KENNETH | HOFFMAN |
| WILLIAM | HACKMAN |
+------------+-----------+
6 rows in set (0.00 sec)
Но есть и другой способ, используя вложенный запрос (nested query):
mysql> SELECT first_name, last_name FROM
-> actor JOIN film_actor USING (actor_id)
-> WHERE film_id = (SELECT film_id FROM film
-> WHERE title = 'ZHIVAGO CORE');
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| UMA | WOOD |
| NICK | STALLONE |
| GARY | PENN |
| SALMA | NOLTE |
| KENNETH | HOFFMAN |
| WILLIAM | HACKMAN |
+------------+-----------+
6 rows in set (0.00 sec)
Он называется вложенным запросом, потому что один запрос находится внутри другого. Внутренний запрос (inner query), или подзапрос (subquery) — тот, который является вложенным, — написан в скобках, и вы можете видеть, что он определяет film_id для фильма с названием ZHIVAGO CORE. Скобки необходимы для внутренних запросов. Внешний запрос (outer query) указан первым и здесь не заключен в скобки: вы можете видеть, что он находит first_name и last_name актеров из JOIN с film_actor с film_id, которые соответствуют результату подзапроса. Таким образом, внутренний запрос находит film_id, а внешний запрос использует его для поиска имен актеров. Всякий раз, когда используются вложенные запросы, их можно переписать как несколько отдельных запросов. Давайте сделаем это с предыдущим примером, так как это может помочь вам понять, что происходит:
mysql> SELECT film_id FROM film WHERE title = 'ZHIVAGO CORE';
+---------+
| film_id |
+---------+
| 998 |
+---------+
1 row in set (0.03 sec)
mysql> SELECT first_name, last_name
-> FROM actor JOIN film_actor USING (actor_id)
-> WHERE film_id = 998;
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| UMA | WOOD |
| NICK | STALLONE |
| GARY | PENN |
| SALMA | NOLTE |
| KENNETH | HOFFMAN |
| WILLIAM | HACKMAN |
+------------+-----------+
6 rows in set (0.00 sec)
Итак, какой подход предпочтительнее: вложенный или не вложенный? Ответ не прост. С точки зрения производительности ответ обычно нет: вложенные запросы трудно оптимизировать, поэтому они почти всегда выполняются медленнее, чем невложенные альтернативы.
Означает ли это, что вам следует избегать вложенности? Ответ — нет: иногда это ваш единственный выбор, если вы хотите написать один запрос, а иногда вложенные запросы могут удовлетворить информационные потребности, которые не могут быть легко решены иначе. Более того, вложенные запросы выразительны. Как только вы освоитесь с идеей, они станут очень удобочитаемым способом показать, как оценивается запрос. На самом деле, многие разработчики SQL выступают за обучение вложенным запросам перед альтернативами, основанными на соединении, которые мы показали вам в последних нескольких разделах. В этом разделе мы покажем вам примеры, где вложенность удобочитаема и мощна.
Прежде чем мы начнем рассматривать ключевые слова, которые можно использовать во вложенных запросах, давайте рассмотрим пример, который не может быть легко выполнен в одном запросе — по крайней мере, без нестандартного, хотя и повсеместного предложения LIMIT в MySQL! Предположим, вы хотите узнать, какой фильм клиент брал напрокат в последний раз. Для этого, следуя методам, которые мы изучили ранее, вы можете найти дату и время самой последней сохраненной строки в таблице аренды для этого клиента:
mysql> SELECT MAX(rental_date) FROM rental
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org';
+---------------------+
| MAX(rental_date) |
+---------------------+
| 2005-08-23 15:46:33 |
+---------------------+
1 row in set (0.01 sec)
Затем вы можете использовать выходные данные в качестве входных данных для другого запроса, чтобы найти название фильма:
mysql> SELECT title FROM film
-> JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org'
-> AND rental_date = '2005-08-23 15:46:33';
+-------------+
| title |
+-------------+
| KARATE MOON |
+-------------+
1 row in set (0.00 sec)
С помощью вложенного запроса вы можете выполнить оба шага за один раз:
mysql> SELECT title FROM film JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> WHERE rental_date = (SELECT MAX(rental_date) FROM rental
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org');
+-------------+
| title |
+-------------+
| KARATE MOON |
+-------------+
1 row in set (0.01 sec)
Вы можете видеть, что вложенный запрос объединяет два предыдущих запроса. Вместо использования постоянных значений даты и времени, обнаруженных в предыдущем запросе, он выполняет запрос непосредственно как подзапрос. Это самый простой тип вложенного запроса, который возвращает скалярный операнд (scalar operand), то есть одно значение.
Предложения ANY, SOME, ALL, IN и NOT IN
Прежде чем мы начнем показывать некоторые более продвинутые функции вложенных запросов, нам нужно переключиться на новую базу данных в наших примерах. К сожалению, база данных sakila слишком хорошо нормализована, чтобы эффективно продемонстрировать всю мощь вложенных запросов. Итак, давайте добавим новую базу данных, чтобы было с чем поиграть.
База данных, которую мы установим, — это образец базы данных employees. Вы можете найти инструкции по установке в документации MySQL или в репозитории базы данных GitHub. Либо клонируйте репозиторий с помощью git, либо загрузите последнюю версию (1.0.7 на момент написания статьи). Когда у вас будут готовы необходимые файлы, вам нужно запустить две команды.
Первая команда создает необходимые структуры и загружает данные:
$ mysql -uroot -p < employees.sql
INFO
CREATING DATABASE STRUCTURE
INFO
storage engine: InnoDB
INFO
LOADING departments
INFO
LOADING employees
INFO
LOADING dept_emp
INFO
LOADING dept_manager
INFO
LOADING titles
INFO
LOADING salaries
data_load_time_diff
00:00:28
Вторая команда проверяет установку:
$ mysql -uroot -p < test_employees_md5.sql
INFO
TESTING INSTALLATION
table_name expected_records expected_crc
departments 9 d1af5e170d2d1591d776d5638d71fc5f
dept_emp 331603 ccf6fe516f990bdaa49713fc478701b7
dept_manager 24 8720e2f0853ac9096b689c14664f847e
employees 300024 4ec56ab5ba37218d187cf6ab09ce1aa1
salaries 2844047 fd220654e95aea1b169624ffe3fca934
titles 443308 bfa016c472df68e70a03facafa1bc0a8
table_name found_records found_crc
departments 9 d1af5e170d2d1591d776d5638d71fc5f
dept_emp 331603 ccf6fe516f990bdaa49713fc478701b7
dept_manager 24 8720e2f0853ac9096b689c14664f847e
employees 300024 4ec56ab5ba37218d187cf6ab09ce1aa1
salaries 2844047 fd220654e95aea1b169624ffe3fca934
titles 443308 bfa016c472df68e70a03facafa1bc0a8
table_name records_match crc_match
departments OK ok
dept_emp OK ok
dept_manager OK ok
employees OK ok
salaries OK ok
titles OK ok
computation_time
00:00:25
summary result
CRC OK
count OK
Как только это будет сделано, вы можете приступить к работе с примерами, которые мы предоставим дальше.
Чтобы подключиться к новой базе данных, либо запустите mysql из командной строки следующим образом (или укажите employees в качестве цели для выбранного клиента MySQL):
$ mysql employeesИли выполните следующее в командной строке mysql, чтобы изменить базу данных по умолчанию:
mysql> USE employeesТеперь вы готовы двигаться вперед.
Использование ANY и IN
Теперь, когда вы создали примеры таблиц, вы можете попробовать пример с использованием ANY. Предположим, вы ищете помощников инженеров, которые проработали дольше, чем наименее опытный менеджер. Вы можете выразить эту потребность в информации следующим образом:
mysql> SELECT emp_no, first_name, last_name, hire_date
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Assistant Engineer'
-> AND hire_date < ANY (SELECT hire_date FROM
-> employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager');
+--------+----------------+------------------+------------+
| emp_no | first_name | last_name | hire_date |
+--------+----------------+------------------+------------+
| 10009 | Sumant | Peac | 1985-02-18 |
| 10066 | Kwee | Schusler | 1986-02-26 |
| ... |
| ... |
| 499958 | Srinidhi | Theuretzbacher | 1989-12-17 |
| 499974 | Shuichi | Piazza | 1989-09-16 |
+--------+----------------+------------------+------------+
10747 rows in set (0.20 sec)
Оказывается, есть много людей, которые соответствуют этим критериям! Подзапрос находит даты найма менеджеров:
mysql> SELECT hire_date FROM
-> employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager';
+------------+
| hire_date |
+------------+
| 1985-01-01 |
| 1986-04-12 |
| ... |
| 1991-08-17 |
| 1989-07-10 |
+------------+
24 rows in set (0.10 sec)
Внешний запрос проходит через каждого сотрудника со званием Associate Engineer, возвращая инженера, если его дата найма ниже (старее), чем любое из значений в наборе, возвращаемом подзапросом. Так, например, Sumant Peac выводится, потому что 1985-02-18 старше по крайней мере одного значения в наборе (как вы можете видеть, вторая дата найма, возвращенная для менеджеров, — 1986-04-12). Ключевое слово ANY означает именно это: оно истинно, если предшествующий ему столбец или выражение истинно для любого (any) из значений в наборе, возвращаемом подзапросом. Используемый таким образом, ANY имеет псевдоним SOME, который был включен для того, чтобы некоторые запросы можно было более четко читать как английские выражения; он не делает ничего другого, и вы редко увидите, как он используется.
Ключевое слово ANY дает вам больше возможностей для выражения вложенных запросов. Действительно, предыдущий запрос является первым вложенным запросом в этом разделе с подзапросом столбца (column subquery), то есть результаты, возвращаемые подзапросом, представляют собой одно или несколько значений из столбца, а не одно скалярное значение, как в предыдущем разделе. Теперь вы можете сравнить значение столбца из внешнего запроса с набором значений, возвращенных из подзапроса.
Рассмотрим другой пример с использованием ANY. Предположим, вы хотите узнать менеджеров, которые также имеют какую-либо другую должность. Вы можете сделать это с помощью следующего вложенного запроса:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no = ANY (SELECT emp_no FROM employees
-> JOIN titles USING (emp_no) WHERE
-> title <> 'Manager');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.11 sec)
= ANY приводит к тому, что внешний запрос возвращает менеджера, когда emp_no равно любому из номеров сотрудников инженера, возвращенных подзапросом. Ключевая фраза = ANY имеет псевдоним IN, который часто используется во вложенных запросах. Используя IN, предыдущий пример можно переписать так:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no IN (SELECT emp_no FROM employees
-> JOIN titles USING (emp_no) WHERE
-> title <> 'Manager');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.11 sec)
Конечно, для этого конкретного примера вы могли бы также использовать запрос соединения. Обратите внимание, что здесь мы должны использовать DISTINCT, потому что в противном случае мы получим 30 возвращаемых строк. Некоторые люди имеют более одного звания, не являющегося инженером:
mysql> SELECT DISTINCT emp_no, first_name, last_name
-> FROM employees JOIN titles mgr USING (emp_no)
-> JOIN titles nonmgr USING (emp_no)
-> WHERE mgr.title = 'Manager'
-> AND nonmgr.title <> 'Manager';
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.11 sec)
Опять же, вложенные запросы выразительны, но обычно медленны в MySQL, поэтому используйте объединение там, где это возможно.
Использование ALL
Предположим, вы хотите найти помощников инженеров, которые более опытны, чем все менеджеры, то есть более опытны, чем самый опытный менеджер. Вы можете сделать это с помощью ключевого слова ALL вместо ANY:
mysql> SELECT emp_no, first_name, last_name, hire_date
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Assistant Engineer'
-> AND hire_date < ALL (SELECT hire_date FROM
-> employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager');
Empty set (0.18 sec)
Вы видите, что ответов нет. Мы можем дополнительно изучить данные, чтобы проверить, какая самая старая дата найма менеджера и помощника инженера:
mysql> (SELECT 'Assistant Engineer' AS title,
-> MIN(hire_date) AS mhd FROM employees
-> JOIN titles USING (emp_no)
-> WHERE title = 'Assistant Engineer')
-> UNION
-> (SELECT 'Manager' title, MIN(hire_date) mhd FROM employees
-> JOIN titles USING (emp_no)
-> WHERE title = 'Manager');
+--------------------+------------+
| title | mhd |
+--------------------+------------+
| Assistant Engineer | 1985-02-01 |
| Manager | 1985-01-01 |
+--------------------+------------+
2 rows in set (0.26 sec)
Глядя на данные, мы видим, что первый менеджер был принят на работу 1 января 1985 года, а первый помощник инженера только 1 февраля того же года. В то время как ключевое слово ANY возвращает значения, удовлетворяющие хотя бы одному условию (логическое ИЛИ), ключевое слово ALL возвращает значения, только если выполняются все условия (логическое И).
Мы можем использовать псевдоним NOT IN вместо <> ANY или != ANY. Найдем всех менеджеров, не являющихся старшими сотрудниками:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager' AND emp_no NOT IN
-> (SELECT emp_no FROM titles
-> WHERE title = 'Senior Staff');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110183 | Shirish | Ossenbruggen |
| 110303 | Krassimir | Wegerle |
| ... |
| 111400 | Arie | Staelin |
| 111692 | Tonny | Butterworth |
+--------+-------------+--------------+
15 rows in set (0.09 sec)
В качестве упражнения попробуйте написать этот запрос, используя синтаксис ANY и как запрос соединения.
У ключевого слова ALL есть несколько уловок и ловушек:
-
Если оно ложно для любого значения, оно ложно. Предположим, что таблица
aсодержит строку со значением 14, а таблицаbсодержит значения 16, 1 иNULL. Если вы проверите, больше ли значение вa, чемALLзначения вb, вы получитеfalse, поскольку 14 не больше 16. Неважно, что другие значения равны 1 иNULL. -
Если оно не является ложным ни для одного значения, оно не будет истинным, если оно не будет истинным для всех значений. Предположим, что таблица
aснова содержит 14, аbсодержит 1 иNULL. Если вы проверите, больше ли значение вa, чемALLзначения вb, вы получитеUNKNOWN(ни true, ни false), потому что невозможно определить, является лиNULLбольше или меньше 14. -
Если таблица в подзапросе пуста, результат всегда истинен. Следовательно, если
aсодержит 14, аbпусто, вы получите истину, когда проверите, больше ли значение вa, чемALLзначения вb.
При использовании ключевого слова ALL будьте очень осторожны с таблицами, которые могут иметь значения NULL в столбцах; рассмотрите возможность запрета значений NULL в таких случаях. Также будьте осторожны с пустыми таблицами.
Написание подзапросов строки
В предыдущих примерах подзапрос возвращал одно скалярное значение (например, actor_id) или набор значений из одного столбца (например, все значения emp_no). В этом разделе описывается другой тип подзапроса, подзапрос строки (row subquery), который работает с несколькими столбцами из нескольких строк.
Предположим, вас интересует, занимал ли менеджер другую должность в том же календарном году. Чтобы ответить на этот вопрос, вы должны сопоставить как номер сотрудника, так и дату присвоения звания, а точнее год. Вы можете написать это как объединение:
mysql> SELECT mgr.emp_no, YEAR(mgr.from_date) AS fd
-> FROM titles AS mgr, titles AS other
-> WHERE mgr.emp_no = other.emp_no
-> AND mgr.title = 'Manager'
-> AND mgr.title <> other.title
-> AND YEAR(mgr.from_date) = YEAR(other.from_date);
+--------+------+
| emp_no | fd |
+--------+------+
| 110765 | 1989 |
| 111784 | 1988 |
+--------+------+
2 rows in set (0.11 sec)
Но вы также можете написать это как вложенный запрос:
mysql> SELECT emp_no, YEAR(from_date) AS fd
-> FROM titles WHERE title = 'Manager' AND
-> (emp_no, YEAR(from_date)) IN
-> (SELECT emp_no, YEAR(from_date)
-> FROM titles WHERE title <> 'Manager');
+--------+------+
| emp_no | fd |
+--------+------+
| 110765 | 1989 |
| 111784 | 1988 |
+--------+------+
2 rows in set (0.12 sec)
Вы можете видеть, что в этом вложенном запросе используется другой синтаксис: список из двух имен столбцов в круглых скобках следует за оператором WHERE, а внутренний запрос возвращает два столбца. Далее мы объясним этот синтаксис.
Синтаксис подзапроса строки позволяет сравнивать несколько значений в строке. Выражение (emp_no, YEAR(from_date)) означает, что два значения в строке сравниваются с выходными данными подзапроса. После ключевого слова IN видно, что подзапрос возвращает два значения: emp_no и YEAR(from_date). Итак, фрагмент:
(emp_no, YEAR(from_date)) IN (SELECT emp_no, YEAR(from_date)
FROM titles WHERE title <> 'Manager')
сопоставляет номера менеджеров и начальные годы с номерами не-менеджеров и начальными годами и возвращает истинное значение, когда совпадение найдено. В результате, если найдена совпадающая пара, общий запрос выводит результат. Это типичный подзапрос строки: он находит строки, существующие в двух таблицах.
Чтобы лучше объяснить синтаксис, давайте рассмотрим другой пример. Предположим, вы хотите узнать, является ли конкретный сотрудник старшим сотрудником. Вы можете сделать это с помощью следующего запроса:
mysql> SELECT first_name, last_name
-> FROM employees, titles
-> WHERE (employees.emp_no, first_name, last_name, title) =
-> (titles.emp_no, 'Marjo', 'Giarratana', 'Senior Staff');
+------------+------------+
| first_name | last_name |
+------------+------------+
| Marjo | Giarratana |
+------------+------------+
1 row in set (0.09 sec)
Это не вложенный запрос, но он показывает, как работает новый синтаксис подзапроса строки. Вы можете видеть, что запрос сопоставляет список столбцов перед знаком равенства (employees.emp_no, first_name, last_name, title) со списком столбцов и значений после знака равенства (titles.emp_no, 'Marjo', 'Giarratana', 'Senior Staff'). Таким образом, когда значения emp_no совпадают, полное имя сотрудника — Marjo Giarratana, а должность — Senior Staff, мы получаем результат запроса. Мы не рекомендуем писать подобные запросы — вместо этого используйте обычное предложение WHERE с несколькими условиями AND, — но это точно иллюстрирует, что происходит. В качестве упражнения попробуйте написать этот запрос, используя соединение.
Подзапросы строк требуют, чтобы число, порядок и тип значений в столбцах совпадали. Так, например, в нашем предыдущем примере INT сопоставляется с INT, а две строки символов — с двумя строками символов.
Предложения EXISTS и NOT EXISTS
Вы познакомились с тремя типами подзапросов: скалярные подзапросы, подзапросы столбцов и подзапросы строк. В этом разделе вы узнаете о четвертом типе, коррелированном подзапросе (correlated subquery), где таблица, используемая во внешнем запросе, упоминается в подзапросе. Коррелированные подзапросы часто используются с оператором IN, который мы уже обсуждали, и почти всегда используются с предложениями EXISTS и NOT EXISTS, которым посвящен этот раздел.
Основы EXISTS и NOT EXISTS
Прежде чем мы начнем обсуждение коррелированных подзапросов, давайте рассмотрим, что делает предложение EXISTS. Нам понадобится простой, но странный пример, чтобы представить предложение, так как мы пока не обсуждаем коррелированные подзапросы. Итак, приступим: предположим, вы хотите найти количество всех фильмов в базе данных, но только в том случае, если база данных активна, что, как вы определили, означает, что хотя бы один фильм из любого филиала был взят напрокат. Вот запрос, который это делает (не забудьте снова подключиться к базе данных sakila перед запуском этого запроса — подсказка: используйте команду <db>):
mysql> SELECT COUNT(*) FROM film
-> WHERE EXISTS (SELECT * FROM rental);
+----------+
| COUNT(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.01 sec)
Подзапрос возвращает все строки из таблицы аренды. Однако важно то, что он возвращает хотя бы одну строку; не имеет значения, что находится в строке, сколько строк в ней или содержит ли строка только значения NULL. Таким образом, вы можете думать о подзапросе как об истинном или ложном, и в этом случае это истинно, потому что он производит некоторый вывод. Если подзапрос истинен, внешний запрос, использующий предложение EXISTS, возвращает строку. Общий результат заключается в том, что подсчитываются все строки в таблице film, потому что для каждой из них подзапрос верен.
Давайте попробуем запрос, где подзапрос не соответствует действительности. Опять же, давайте придумаем запрос: на этот раз мы будем выводить названия всех фильмов в базе данных, но только если конкретный фильм существует. Вот запрос:
mysql> SELECT title FROM film
-> WHERE EXISTS (SELECT * FROM film
-> WHERE title = 'IS THIS A MOVIE?');
Empty set (0.00 sec)
Поскольку подзапрос неверен, строки не возвращаются, потому что IS THIS A MOVIE? отсутствует в нашей базе данных — внешний запрос не возвращает никаких результатов.
Предложение NOT EXISTS делает обратное. Представьте, что вам нужен список всех актеров, если в базе данных нет определенного фильма. Вот:
mysql> SELECT * FROM actor WHERE NOT EXISTS
-> (SELECT * FROM film WHERE title = 'ZHIVAGO CORE');
Empty set (0.00 sec)
На этот раз внутренний запрос верен, но предложение NOT EXISTS отрицает его, чтобы дать false. Поскольку оно ложно, внешний запрос не дает результатов.
Вы заметите, что подзапрос начинается с SELECT * FROM film. На самом деле не имеет значения, что вы выбираете во внутреннем запросе, когда используете предложение EXISTS, так как оно все равно не используется внешним запросом. Вы можете выбрать один столбец, все или даже константу (как в SELECT 'cat' from film), и это будет иметь тот же эффект. Однако традиционно вы увидите, что большинство авторов SQL пишут SELECT * по соглашению.
Коррелированные подзапросы
До сих пор, вероятно, трудно представить, что вы будете делать с предложениями EXISTS и NOT EXISTS. В этом разделе показано, как они используются на самом деле, иллюстрируя самый продвинутый тип вложенного запроса, который вы обычно видите в действии.
Давайте подумаем о реалистичных видах информации, которые вам могут понадобиться из базы данных sakila. Предположим, вам нужен список всех сотрудников, которые арендовали что-то у нашей компании или являются просто клиентами. Вы можете легко сделать это с помощью запроса с соединением, о котором мы рекомендуем вам подумать, прежде чем продолжить. Вы также можете сделать это с помощью следующего вложенного запроса, который использует коррелированный подзапрос:
mysql> SELECT first_name, last_name FROM staff
-> WHERE EXISTS (SELECT * FROM customer
-> WHERE customer.first_name = staff.first_name
-> AND customer.last_name = staff.last_name);
Empty set (0.01 sec)
Выхода нет, потому что никто из персонала не является также и заказчиком (или это запрещено, но мы нарушим правила). Давайте добавим клиента с теми же данными, что и у одного из сотрудников:
mysql> INSERT INTO customer(store_id, first_name, last_name,
-> email, address_id, create_date)
-> VALUES (1, 'Mike', 'Hillyer',
-> 'Mike.Hillyer@sakilastaff.com', 3, NOW());
Query OK, 1 row affected (0.02 sec)
И повторите запрос:
mysql> SELECT first_name, last_name FROM staff
-> WHERE EXISTS (SELECT * FROM customer
-> WHERE customer.first_name = staff.first_name
-> AND customer.last_name = staff.last_name);
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| Mike | Hillyer |
+------------+-----------+
1 row in set (0.00 sec)
Итак, запрос работает; теперь нам просто нужно понять, как!
Давайте рассмотрим подзапрос в нашем предыдущем примере. Вы можете видеть, что в предложении FROM указана только таблица клиентов, но в предложении WHERE используется столбец из таблицы staff. Если вы запустите его изолированно, вы увидите, что это не разрешено:
mysql> SELECT * FROM customer WHERE customer.first_name = staff.first_name;
ERROR 1054 (42S22): Unknown column 'staff.first_name' in 'where clause'
Однако это допустимо при выполнении в качестве подзапроса, поскольку доступ к таблицам, перечисленным во внешнем запросе, разрешен в подзапросе. Таким образом, в этом примере текущее значение staff.first_name и staff.last_name во внешнем запросе передается в подзапрос как постоянное скалярное значение и сравнивается с именем и фамилией клиента. Если имя клиента совпадает с именем сотрудника, подзапрос верен, и поэтому внешний запрос выводит строку. Рассмотрим два случая, иллюстрирующие это более наглядно:
-
Когда
first_nameиlast_name, обрабатываемые внешним запросом, являютсяJonиStephens, подзапрос будет ложным, посколькуSELECT * FROM customer WHERE first_name = 'Jon' and last_name = 'Stephens';не возвращает никаких строк, поэтому строка персонала для Jon Stephens не выводится в качестве ответа. -
Когда
first_nameиlast_name, обрабатываемые внешним запросом, являютсяMikeиHillyer, подзапрос верен, потому чтоSELECT * FROM customer WHERE first_name = 'Mike' and last_name = 'Hillyer';возвращает хотя бы одну строку. В целом, строка сотрудника для Mike Hillyer возвращена.
Видите ли вы силу коррелированных подзапросов? Вы можете использовать значения из внешнего запроса во внутреннем запросе для оценки сложных информационных потребностей.
Теперь мы рассмотрим другой пример с использованием EXISTS. Попробуем найти количество всех фильмов, у которых есть хотя бы две копии. Чтобы сделать это с помощью EXISTS, нам нужно продумать, что должны делать внутренние и внешние запросы. Внутренний запрос должен давать результат только тогда, когда условие, которое мы проверяем, истинно; в этом случае он должен производить вывод, когда в списке есть как минимум две строки для одного и того же фильма. Внешний запрос должен увеличивать счетчик всякий раз, когда внутренний запрос имеет значение true. Вот запрос:
mysql> SELECT COUNT(*) FROM film WHERE EXISTS
-> (SELECT film_id FROM inventory
-> WHERE inventory.film_id = film.film_id
-> GROUP BY film_id HAVING COUNT(*) >= 2);
+----------+
| COUNT(*) |
+----------+
| 958 |
+----------+
1 row in set (0.00 sec)
Это еще один запрос, в котором нет необходимости вложенности и достаточно объединения, но давайте остановимся на этой версии в целях объяснения. Взгляните на внутренний запрос: вы можете видеть, что предложение WHERE гарантирует, что фильмы совпадают по уникальному film_id, и подзапрос рассматривает только совпадающие строки для текущего фильма. Предложение GROUP BY группирует строки для этого фильма, но только если в списке есть как минимум две записи. Поэтому внутренний запрос выдает результат только тогда, когда в нашем списке есть как минимум две строки для текущего фильма. Внешний запрос прост: его можно рассматривать как увеличение счетчика, когда подзапрос производит вывод.
Вот еще один пример, прежде чем мы двинемся дальше и обсудим другие вопросы. Этот пример будет в базе данных сотрудников, поэтому переключите свой клиент. Мы уже показывали вам запрос, который использует IN и находит менеджеров, у которых также была какая-то другая должность:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no IN (SELECT emp_no FROM employees
-> JOIN titles USING (emp_no) WHERE
-> title <> 'Manager');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.11 sec)
Давайте перепишем запрос, чтобы использовать EXISTS. Во-первых, подумайте о подзапросе: он должен выдавать результат, когда есть запись о должности для сотрудника с тем же именем, что и у менеджера.
Во-вторых, подумайте о внешнем запросе: он должен возвращать имя сотрудника, когда внутренний запрос производит вывод. Вот переписанный запрос:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND EXISTS (SELECT emp_no FROM titles
-> WHERE titles.emp_no = employees.emp_no
-> AND title <> 'Manager');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.09 sec)
Опять же, вы можете видеть, что подзапрос ссылается на столбец emp_no, полученный из внешнего запроса.
Коррелированные подзапросы можно использовать с любым вложенным запросом. Вот предыдущий запрос IN, переписанный с внешней ссылкой:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no IN (SELECT emp_no FROM titles
-> WHERE titles.emp_no = employees.emp_no
-> AND title <> 'Manager');
+--------+-------------+--------------+
| emp_no | first_name | last_name |
+--------+-------------+--------------+
| 110022 | Margareta | Markovitch |
| 110039 | Vishwani | Minakawa |
| ... |
| 111877 | Xiaobin | Spinelli |
| 111939 | Yuchang | Weedman |
+--------+-------------+--------------+
24 rows in set (0.09 sec)
Запрос более запутан, чем должен быть, но он иллюстрирует идею. Вы можете видеть, что emp_no в подзапросе ссылается на таблицу employees из внешнего запроса.
Если запрос будет возвращать одну строку, его также можно переписать так, чтобы вместо IN использовалось равенство:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no = (SELECT emp_no FROM titles
-> WHERE titles.emp_no = employees.emp_no
-> AND title <> 'Manager');
ERROR 1242 (21000): Subquery returns more than 1 row
В данном случае это не работает, поскольку подзапрос возвращает более одного скалярного значения. Давайте сузим его:
mysql> SELECT emp_no, first_name, last_name
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager'
-> AND emp_no = (SELECT emp_no FROM titles
-> WHERE titles.emp_no = employees.emp_no
-> AND title = 'Senior Engineer');
+--------+------------+-----------+
| emp_no | first_name | last_name |
+--------+------------+-----------+
| 110344 | Rosine | Cools |
| 110420 | Oscar | Ghazalie |
| 110800 | Sanjoy | Quadeer |
+--------+------------+-----------+
3 rows in set (0.10 sec)
Теперь это работает — для каждого имени указан только один титул менеджера и старшего инженера, — поэтому оператор подзапроса столбца IN не нужен. Конечно, если заголовки дублируются (например, если человек переключается между позициями), вам нужно вместо этого использовать IN, ANY или ALL.
Вложенные запросы в предложении FROM
Все показанные нами методы используют вложенные запросы в предложении WHERE. В этом разделе показано, как они могут альтернативно использоваться в предложении FROM. Это полезно, когда вы хотите манипулировать источником данных, которые вы используете в запросе.
В базе данных employees в таблице salaries хранится годовая заработная плата вместе с ID сотрудника. Например, если вы хотите найти месячную ставку, вы можете выполнить некоторую математику в запросе. Один из вариантов в этом случае — сделать это с помощью подзапроса:
mysql> SELECT emp_no, monthly_salary FROM
-> (SELECT emp_no, salary/12 AS monthly_salary FROM salaries) AS ms
-> LIMIT 5;
+--------+----------------+
| emp_no | monthly_salary |
+--------+----------------+
| 10001 | 5009.7500 |
| 10001 | 5175.1667 |
| 10001 | 5506.1667 |
| 10001 | 5549.6667 |
| 10001 | 5580.0833 |
+--------+----------------+
5 rows in set (0.00 sec)
Сосредоточьтесь на том, что следует за предложением FROM. Подзапрос использует таблицу salaries и возвращает два столбца: первый столбец — emp_no; второй столбец имеет псевдоним month_salary и представляет собой значение salary, деленное на 12. Внешний запрос прост: он просто возвращает значения emp_no и month_salary, созданные с помощью подзапроса. Обратите внимание, что мы добавили псевдоним таблицы ms для подзапроса. Когда мы используем подзапрос в качестве таблицы, то есть применяем к нему операцию SELECT FROM, эта «производная таблица» должна иметь псевдоним, даже если мы не используем псевдоним в нашем запросе. MySQL жалуется, если мы опускаем псевдоним:
mysql> SELECT emp_no, monthly_salary FROM
-> (SELECT emp_no, salary/12 AS monthly_salary FROM salaries)
-> LIMIT 5;
ERROR 1248 (42000): Every derived table must have its own alias
Вот еще один пример, теперь уже в базе данных sakila. Предположим, мы хотим узнать среднюю сумму, которую фильм приносит нам за счет проката, или среднюю валовую прибыль, как мы ее назовем. Начнем с рассмотрения подзапроса. Он должен вернуть сумму платежей, которые у нас есть для каждого фильма. Затем внешний запрос должен усреднить значения, чтобы дать ответ. Вот запрос:
mysql> SELECT AVG(gross) FROM
-> (SELECT SUM(amount) AS gross
-> FROM payment JOIN rental USING (rental_id)
-> JOIN inventory USING (inventory_id)
-> JOIN film USING (film_id)
-> GROUP BY film_id) AS gross_amount;
+------------+
| AVG(gross) |
+------------+
| 70.361754 |
+------------+
1 row in set (0.05 sec)
Вы можете видеть, что внутренний запрос объединяет payment, rental, inventory и film, а также группирует продажи по фильмам, чтобы вы могли получить сумму для каждого фильма. Если вы запустите его изолированно, вот что произойдет:
mysql> SELECT SUM(amount) AS gross
-> FROM payment JOIN rental USING (rental_id)
-> JOIN inventory USING (inventory_id)
-> JOIN film USING (film_id)
-> GROUP BY film_id;
+--------+
| gross |
+--------+
| 36.77 |
| 52.93 |
| 37.88 |
| ... |
| 14.91 |
| 73.83 |
| 214.69 |
+--------+
958 rows in set (0.08 sec)
Теперь внешний запрос берет эти суммы, которые обозначены как gross, и усредняет их, чтобы получить окончательный результат. Этот запрос представляет собой типичный способ применения двух агрегатных функций к одному набору данных. Вы не можете применять агрегатные функции в каскаде, как в AVG(SUM(amount)):
mysql> SELECT AVG(SUM(amount)) AS avg_gross
-> FROM payment JOIN rental USING (rental_id)
-> JOIN inventory USING (inventory_id)
-> JOIN film USING (film_id) GROUP BY film_id;
ERROR 1111 (HY000): Invalid use of group function
С подзапросами в предложениях FROM вы можете вернуть скалярное значение, набор значений столбца, более одной строки или даже целую таблицу. Однако вы не можете использовать коррелированные подзапросы, то есть вы не можете ссылаться на таблицы или столбцы из таблиц, которые явно не указаны в подзапросе. Обратите также внимание, что вы должны создать псевдоним для всего подзапроса, используя ключевое слово AS, и дать ему имя, даже если вы не используете это имя нигде в запросе.
Вложенные запросы в JOIN
Последнее применение вложенных запросов, которое мы покажем, но не менее полезное, — это их использование в соединениях. В этом случае результаты подзапроса в основном формируют новую таблицу и могут использоваться в любом из типов соединений, которые мы обсуждали.
В качестве примера давайте вернемся к запросу, в котором перечислялось количество фильмов из каждой категории, взятых напрокат конкретным покупателем. Помните, у нас возникла проблема при написании этого запроса с использованием только соединений: мы не получили нулевое количество для категорий, из которых наш клиент не арендовал. Это был запрос:
mysql> SELECT cat.name AS category_name, COUNT(cat.category_id) AS cnt
-> FROM category AS cat LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> JOIN customer AS cs ON rental.customer_id = cs.customer_id
-> WHERE cs.email = 'WESLEY.BULL@sakilacustomer.org'
-> GROUP BY category_name ORDER BY cnt DESC;
+-------------+-----+
| name | cnt |
+-------------+-----+
| Games | 9 |
| Foreign | 6 |
| ... |
| ... |
| Comedy | 1 |
| Sports | 1 |
+-------------+-----+
14 rows in set (0.00 sec)
Теперь, когда мы знаем о подзапросах и соединениях, а также о том, что подзапросы могут использоваться в соединениях, мы можем легко завершить задачу. Это наш новый запрос:
mysql> SELECT cat.name AS category_name, cnt
-> FROM category AS cat
-> LEFT JOIN (SELECT cat.name, COUNT(cat.category_id) AS cnt
-> FROM category AS cat
-> LEFT JOIN film_category USING (category_id)
-> LEFT JOIN inventory USING (film_id)
-> LEFT JOIN rental USING (inventory_id)
-> JOIN customer cs ON rental.customer_id = cs.customer_id
-> WHERE cs.email = 'WESLEY.BULL@sakilacustomer.org'
-> GROUP BY cat.name) customer_cat USING (name)
-> ORDER BY cnt DESC;
+-------------+------+
| name | cnt |
+-------------+------+
| Games | 9 |
| Foreign | 6 |
| ... |
| Children | 1 |
| Sports | 1 |
| Sci-Fi | NULL |
| Action | NULL |
| Thriller | NULL |
+-------------+------+
17 rows in set (0.01 sec)
Наконец, мы получаем все отображаемые категории и получаем значения NULL для тех категорий, в которых аренда не производилась. Давайте посмотрим, что происходит в нашем новом запросе. Подзапрос, который мы назвали customer_cat, является нашим предыдущим запросом без предложения ORDER BY. Таким образом, мы знаем, что он вернет: 14 строк для категорий, в которых Wesley что-то арендовал, и количество аренд в каждой. Затем используйте LEFT JOIN, чтобы соединить эту информацию с полным списком категорий из таблицы category. Таблица category управляет объединением, поэтому в ней будут выбраны все строки. Мы присоединяемся к подзапросу, используя столбец имени, который совпадает между выходными данными подзапроса и столбцом таблицы category.
Техника, которую мы показали здесь, очень мощная; однако, как всегда с подзапросами, за это приходится платить. MySQL не может эффективно оптимизировать весь запрос, если в предложении соединения присутствует подзапрос.
Пользовательские переменные
Часто вам нужно сохранять значения, которые возвращаются из запросов. Возможно, вы захотите сделать это, чтобы можно было легко использовать значение в последующем запросе. Вы также можете просто сохранить результат для последующего отображения. В обоих случаях проблему решают пользовательские переменные: они позволяют сохранить результат и использовать его позже.
Проиллюстрируем пользовательские переменные на простом примере. Следующий запрос находит название фильма и сохраняет результат в пользовательской переменной:
mysql> SELECT @film:=title FROM film WHERE film_id = 1;
+------------------+
| @film:=title |
+------------------+
| ACADEMY DINOSAUR |
+------------------+
1 row in set, 1 warning (0.00 sec)
Пользовательская переменная называется film и обозначается как пользовательская переменная символом @, который предшествует ей. Значение присваивается с помощью оператора :=. Вы можете распечатать содержимое пользовательской переменной с помощью следующего очень короткого запроса:
mysql> SELECT @film;
+------------------+
| @film |
+------------------+
| ACADEMY DINOSAUR |
+------------------+
1 row in set (0.00 sec)
Возможно, вы заметили предупреждение — о чем это было?
mysql> SELECT @film:=title FROM film WHERE film_id = 1;
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Warning
Code: 1287
Message: Setting user variables within expressions is deprecated
and will be removed in a future release. Consider alternatives:
'SET variable=expression, ...', or
'SELECT expression(s) INTO variables(s)'.
1 row in set (0.00 sec)
Давайте рассмотрим две предложенные альтернативы. Во-первых, мы все еще можем выполнить вложенный запрос в операторе SET:
mysql> SET @film := (SELECT title FROM film WHERE film_id = 1);
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @film;
+------------------+
| @film |
+------------------+
| ACADEMY DINOSAUR |
+------------------+
1 row in set (0.00 sec)
Во-вторых, мы можем использовать оператор SELECT INTO:
mysql> SELECT title INTO @film FROM film WHERE film_id = 1;
Query OK, 1 row affected (0.00 sec)
mysql> SELECT @film;
+------------------+
| @film |
+------------------+
| ACADEMY DINOSAUR |
+------------------+
1 row in set (0.00 sec)
Вы можете явно установить переменную с помощью оператора SET без SELECT. Предположим, вы хотите обнулить счетчик:
mysql> SET @counter := 0;
Query OK, 0 rows affected (0.00 sec)
Знак := необязателен, вместо него можно написать = и перепутать их. Вы должны разделить несколько присвоений запятой или поместить каждое в отдельное утверждение:
mysql> SET @counter = 0, @age := 23;
Query OK, 0 rows affected (0.00 sec)
Альтернативный синтаксис для SET — SELECT INTO. Вы можете инициализировать одну переменную:
mysql> SELECT 0 INTO @counter;
Query OK, 1 row affected (0.00 sec)
Или несколько переменных одновременно:
mysql> SELECT 0, 23 INTO @counter, @age;
Query OK, 1 row affected (0.00 sec)
Чаще всего пользовательские переменные используются для сохранения результата и использования его позже. Вы помните следующий пример из предыдущей главы, который мы использовали для обоснования вложенных запросов (которые, безусловно, являются лучшим решением этой проблемы). Здесь мы хотим найти название фильма, который последний раз брал напрокат конкретный покупатель:
mysql> SELECT MAX(rental_date) FROM rental
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org';
+---------------------+
| MAX(rental_date) |
+---------------------+
| 2005-08-23 15:46:33 |
+---------------------+
1 row in set (0.01 sec)
mysql> SELECT title FROM film
-> JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org'
-> AND rental_date = '2005-08-23 15:46:33';
+-------------+
| title |
+-------------+
| KARATE MOON |
+-------------+
1 row in set (0.00 sec)
Вы можете использовать пользовательскую переменную, чтобы сохранить результат для ввода в следующий запрос. Вот та же пара запросов, переписанная с использованием этого подхода:
mysql> SELECT MAX(rental_date) INTO @recent FROM rental
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org';
1 row in set (0.01 sec)
mysql> SELECT title FROM film
-> JOIN inventory USING (film_id)
-> JOIN rental USING (inventory_id)
-> JOIN customer USING (customer_id)
-> WHERE email = 'WESLEY.BULL@sakilacustomer.org'
-> AND rental_date = @recent;
+-------------+
| title |
+-------------+
| KARATE MOON |
+-------------+
1 row in set (0.00 sec)
Это может избавить вас от вырезания и вставки, и это, безусловно, поможет вам избежать ошибок при наборе текста.
Вот несколько рекомендаций по использованию пользовательских переменных:
-
Пользовательские переменные уникальны для соединения: созданные вами переменные не видны никому другому, и два разных соединения могут иметь две разные переменные с одинаковыми именами.
-
Имена переменных могут быть буквенно-цифровыми строками, а также могут включать символы точки (
.), подчеркивания (_) и знака доллара ($). -
Имена переменных чувствительны к регистру в версиях MySQL до версии 5 и нечувствительны к регистру, начиная с версии 5.
-
Любая переменная, которая не инициализирована, имеет значение
NULL; вы также можете вручную установить переменную вNULL. -
Переменные уничтожаются при закрытии соединения.
-
Вам следует избегать одновременно попыток присвоить значение переменной и использовать эту переменную как часть запроса
SELECT. Две причины этого заключаются в том, что новое значение может быть недоступно для немедленного использования в том же операторе, и тип переменной устанавливается, когда она впервые присваивается в запросе; попытка использовать его позже в качестве другого типа в том же операторе SQL может привести к неожиданным результатам.
Давайте рассмотрим первую проблему более подробно, используя новую переменную @fid. Поскольку мы ранее не использовали эту переменную, она пуста. Теперь давайте покажем film_id для фильмов, у которых есть запись в таблице inventory. Вместо того, чтобы показывать его напрямую, мы назначим film_id переменной @fid. Наш запрос покажет переменную три раза — один раз перед операцией присваивания, один раз как часть операции присваивания и один раз после нее:
mysql> SELECT @fid, @fid:=film.film_id, @fid FROM film, inventory
-> WHERE inventory.film_id = @fid;
Empty set, 1 warning (0.16 sec)
Это ничего не возвращает, кроме предупреждения об устаревании; поскольку в переменной нет ничего, с чего можно было бы начать, предложение WHERE пытается найти пустые значения inventory.film_id. Если мы изменим запрос, чтобы использовать film.film_id как часть предложения WHERE, все будет работать так, как ожидалось:
mysql> SELECT @fid, @fid:=film.film_id, @fid FROM film, inventory
-> WHERE inventory.film_id = film.film_id LIMIT 20;
+------+--------------------+------+
| @fid | @fid:=film.film_id | @fid |
+------+--------------------+------+
| NULL | 1 | 1 |
| 1 | 1 | 1 |
| 1 | 1 | 1 |
| ... |
| 4 | 4 | 4 |
| 4 | 4 | 4 |
+------+--------------------+------+
20 rows in set, 1 warning (0.00 sec)
Теперь, если @fid не пуст, первоначальный запрос даст некоторые результаты:
mysql> SELECT @fid, @fid:=film.film_id, @fid FROM film, inventory
-> WHERE inventory.film_id = film.film_id LIMIT 20;
+------+--------------------+------+
| @fid | @fid:=film.film_id | @fid |
+------+--------------------+------+
| 4 | 1 | 1 |
| 1 | 1 | 1 |
| ... |
| 4 | 4 | 4 |
| 4 | 4 | 4 |
+------+--------------------+------+
20 rows in set, 1 warning (0.00 sec)
Лучше избегать таких обстоятельств, когда поведение не гарантировано и, следовательно, непредсказуемо.
Глава 6
Транзакции и блокировки
Использование блокировок для изоляции транзакций является основой баз данных SQL, но это также область, которая может вызвать много путаницы, особенно у новичков. Разработчики часто думают, что блокировка — это проблема базы данных и относится к области администраторов баз данных. Администраторы баз данных, в свою очередь, считают, что это проблема приложения и, следовательно, ответственность разработчиков. В этой главе поясняется, что происходит в ситуациях, когда разные процессы одновременно пытаются записывать в одну и ту же строку. Это также прольет свет на поведение запросов на чтение внутри транзакции с различными типами уровней изоляции, доступных в MySQL.
Во-первых, давайте определимся с ключевыми понятиями. Транзакция (transaction) — это операция, выполняемая (с использованием одного или нескольких операторов SQL) в базе данных как единая логическая единица работы. Все изменения операторов SQL в транзакции либо фиксируются (применяются к базе данных), либо откатываются (отменяются из базы данных) как единое целое, а не только частично. Транзакция базы данных должна быть атомарной, согласованной, изолированной и надежной (известная аббревиатура ACID (atomic, consistent, isolated, durable)).
Блокировки (locks) — это механизмы, используемые для обеспечения целостности данных, хранящихся в базе данных, пока приложения и пользователи взаимодействуют с ней. Мы увидим, что существуют разные типы блокировки, и некоторые из них более строгие, чем другие.
Базам данных не понадобились бы транзакции и блокировки, если бы запросы выдавались последовательно и обрабатывались по порядку, один за другим (SELECT, затем INSERT, затем UPDATE и т. д.). Мы иллюстрируем это поведение на рисунке 6-1.

Рисунок 6-1. Серийное выполнение операторов SQL
Однако реальность (к счастью!) такова, что MySQL может обрабатывать тысячи запросов в секунду и обрабатывать их параллельно, а не последовательно. В этой главе обсуждается, что делает MySQL для достижения такого параллелизма, например, когда запросы на SELECT и UPDATE в одной и той же строке поступают одновременно или когда один поступает, а другой все еще выполняется. На рис. 6-2 показано, как это выглядит.

Рисунок 6-2. Параллельное выполнение операторов SQL
В этой главе нас особенно интересует, как MySQL изолирует (isolates) транзакции (I в ACID). Мы покажем вам распространенные ситуации, когда происходит блокировка, исследуем их и обсудим параметры MySQL, которые определяют, сколько времени транзакция может ждать предоставления блокировки.
Уровни изоляции
Уровень изоляции (isolation level) — это параметр, который уравновешивает производительность, надежность, согласованность и воспроизводимость результатов, когда несколько транзакций вносят изменения и выполняют запросы одновременно.
Стандарт SQL:1992 определяет четыре классических уровня изоляции, и MySQL поддерживает их все. InnoDB поддерживает каждый из описанных здесь уровней изоляции транзакций, используя разные стратегии блокировки. Пользователь также может изменить уровень изоляции для одного сеанса или всех последующих соединений с помощью инструкции SET [GLOBAL/SESSION] TRANSACTION.
Мы можем обеспечить высокую степень согласованности с уровнем изоляции REPEATABLE READ по умолчанию для операций с данными, где важно соответствие ACID, и мы можем ослабить правила согласованности с помощью изоляции READ COMMITTED или даже READ UNCOMMITTED в таких ситуациях, как массовые отчеты, где требуется точная согласованность и воспроизводимые результаты менее важны, чем минимизация накладных расходов на блокировку. Изоляция SERIALIZABLE применяет еще более строгие правила, чем REPEATABLE READ, и используется в основном для особых ситуаций, таких как устранение неполадок. Прежде чем углубиться в детали, давайте взглянем еще на некоторые термины:
- Dirty reads (Грязное чтение)
-
Это происходит, когда транзакция может прочитать данные из строки, которая была изменена другой транзакцией, которая еще не выполнила
COMMIT. Если транзакция, внесшая изменения, будет отброшена, другая транзакция увидит неверные результаты, не отражающие состояние базы данных. Целостность данных нарушена. - Non-repeatable reads (Неповторяющееся чтение)
-
Это происходит, когда два запроса в транзакции выполняют
SELECT, и возвращаемые значения различаются между чтениями из-за изменений, сделанных другой транзакцией в промежутке (если вы читаете строку в момент времени T1, а затем пытаетесь прочитать ее снова в момент времени T2, строка могла быть обновлена). Отличие от грязного чтения в том, что в этом случае естьCOMMIT. Первоначальный запросSELECTнельзя повторить, поскольку он возвращает другие значения при повторном выполнении. - Phantom reads (Фантомное чтение)
-
Это происходит, когда транзакция выполняется, а другая транзакция добавляет строки или удаляет их из читаемых записей (опять же, в этом случае транзакция, изменяющая данные, выполняет
COMMIT). Это означает, что если тот же запрос будет выполнен еще раз в той же транзакции, он вернет другое количество строк. Фантомные чтения могут происходить, когда нет блокировок диапазона, гарантирующих непротиворечивость данных.
Имея в виду эти концепции, давайте подробнее рассмотрим различные уровни изоляции в MySQL.
REPEATABLE READ
REPEATABLE READ — это уровень изоляции по умолчанию для InnoDB. Он обеспечивает согласованное чтение в рамках одной и той же транзакции, то есть все запросы в рамках транзакции будут видеть один и тот же моментальный снимок данных, созданный при первом чтении. В этом режиме InnoDB блокирует отсканированный диапазон индексов, используя блокировки промежутков или блокировки следующего ключа (описанные в разделе «Блокировка»), чтобы блокировать вставки другими сеансами в любые промежутки в этом диапазоне.
Например, предположим, что в одном сеансе (сеанс 1) мы выполняем следующий SELECT:
session1> SELECT * FROM person WHERE i BETWEEN 1 AND 4;
+---+----------+
| i | name |
+---+----------+
| 1 | Vinicius |
| 2 | Sergey |
| 3 | Iwo |
| 4 | Peter |
+---+----------+
4 rows in set (0.00 sec)
И в другом сеансе (сеанс 2) мы обновляем имя во второй строке:
session2> UPDATE person SET name = 'Kuzmichev' WHERE i=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session2 > COMMIT;
Query OK, 0 rows affected (0.00 sec)
Мы можем подтвердить изменение в сеансе 2:
session2> SELECT * FROM person WHERE i BETWEEN 1 AND 4;
+---+-----------+
| i | name |
+---+-----------+
| 1 | Vinicius |
| 2 | Kuzmichev |
| 3 | Iwo |
| 4 | Peter |
+---+-----------+
4 rows in set (0.00 sec)
Но сеанс 1 по-прежнему показывает старое значение из исходного снимка данных:
session1> SELECT * FROM person WHERE i BETWEEN 1 AND 4;
+---+----------+
| i | name |
+---+----------+
| 1 | Vinicius |
| 2 | Sergey |
| 3 | Iwo |
| 4 | Peter |
+---+----------+
Таким образом, при уровне изоляции REPEATABLE READ отсутствуют грязные и/или неповторяемые чтения. Каждая транзакция считывает моментальный снимок, созданный при первом чтении.
READ COMMITTED
Любопытно, что уровень изоляции READ COMMITTED используется по умолчанию для многих баз данных, таких как Postgres, Oracle и SQL Server, но не для MySQL. Таким образом, те, кто переходит на MySQL, должны знать об этой разнице в поведении по умолчанию.
Основное различие между READ COMMITTED и REPEATABLE READ заключается в том, что при READ COMMITTED каждое согласованное чтение, даже в рамках одной и той же транзакции, создает и считывает свой собственный свежий снимок. Такое поведение может привести к фантомному чтению при выполнении нескольких запросов внутри транзакции. Давайте посмотрим на пример. В сеансе 1 строка 1 выглядит так:
session1> SELECT * FROM person WHERE i = 1;
+---+----------+
| i | name |
+---+----------+
| 1 | Vinicius |
+---+----------+
1 row in set (0.00 sec)
Теперь предположим, что в сеансе 2 мы обновляем первую строку таблицы person и фиксируем транзакцию:
session2> UPDATE person SET name = 'Grippa' WHERE i = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session2 > COMMIT;
Query OK, 0 rows affected (0.00 sec)
Если мы снова проверим сеанс 1, мы увидим, что значение первой строки изменилось:
session1> SELECT * FROM person WHERE i = 1;
+---+--------+
| i | name |
+---+--------+
| 1 | Grippa |
+---+--------+
Существенным преимуществом READ COMMITTED является отсутствие блокировок промежутков, что позволяет свободно вставлять новые записи рядом с заблокированными записями.
READ UNCOMMITTED
С уровнем изоляции READ UNCOMMITTED MySQL выполняет операторы SELECT неблокирующим образом, что означает, что два оператора SELECT в одной и той же транзакции могут не читать одну и ту же версию строки. Как мы видели ранее, это явление называется грязным чтением. Подумайте, как предыдущий пример будет воспроизводиться с использованием READ UNCOMMITTED. Основное отличие состоит в том, что сеанс 1 может видеть результаты обновления сеанса 2 до фиксации. Давайте рассмотрим еще один пример. Предположим, что в сеансе 1 мы выполняем следующий оператор SELECT:
session1> SELECT * FROM person WHERE i = 5;
+---+---------+
| i | name |
+---+---------+
| 5 | Marcelo |
+---+---------+
1 row in set (0.00 sec)
И в сеансе 2 мы выполняем это обновление без фиксации:
session2> UPDATE person SET name = 'Altmann' WHERE i = 5;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
Если теперь мы снова выполним SELECT в сеансе 1, вот что мы увидим:
session1> SELECT * FROM person WHERE i = 5;
+---+---------+
| i | name |
+---+---------+
| 5 | Altmann |
+---+---------+
1 row in set (0.00 sec)
Мы видим, что сеанс 1 может читать измененные данные, даже если они находятся в переходном состоянии, и это изменение может в конечном итоге быть отменено и не зафиксировано.
SERIALIZABLE
Самый ограниченный уровень изоляции, доступный в MySQL, — SERIALIZABLE. Он похож на REPEATABLE READ, но имеет дополнительное ограничение, заключающееся в том, что одна транзакция не может мешать другой. Таким образом, с этим механизмом блокировки сценарий противоречивых данных больше невозможен.
Чтобы было понятнее, представьте финансовую базу данных, в которой мы регистрируем остатки на счетах клиентов в таблице accounts. Что произойдет, если две транзакции попытаются одновременно обновить баланс счета клиента? Следующий пример иллюстрирует этот сценарий. Предположим, что мы запустили два сеанса, используя уровень изоляции по умолчанию, REPEATABLE READ, и явно открыли транзакцию в каждом с помощью BEGIN. В сеансе 1 мы выбираем все учетные записи в таблице accounts:
session1> SELECT * FROM accounts;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 80 | USD | 2021-07-13 20:39:27 |
| 2 | Sergey | 100 | USD | 2021-07-13 20:39:32 |
| 3 | Markus | 100 | USD | 2021-07-13 20:39:39 |
+----+--------+---------+----------+---------------------+
3 rows in set (0.00 sec)
Затем в сеансе 2 мы выбираем все счета с балансом не менее 80 долларов США:
session2> SELECT * FROM accounts WHERE balance >= 80;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 80 | USD | 2021-07-13 20:39:27 |
| 2 | Sergey | 100 | USD | 2021-07-13 20:39:32 |
| 3 | Markus | 100 | USD | 2021-07-13 20:39:39 |
+----+--------+---------+----------+---------------------+
3 rows in set (0.00 sec)
Теперь в сессии 1 вычитаем 10 USD со счета 1 и проверяем результат:
session1> UPDATE accounts SET balance = balance - 10 WHERE id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session1> SELECT * FROM accounts;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 70 | USD | 2021-07-13 20:39:27 |
| 2 | Sergey | 100 | USD | 2021-07-13 20:39:32 |
| 3 | Markus | 100 | USD | 2021-07-13 20:39:39 |
+----+--------+---------+----------+---------------------+
3 rows in set (0.00 sec)
Мы видим, что баланс счета 1 уменьшился до 70 долларов США. Итак, мы фиксируем сеанс 1, а затем переходим к сеансу 2, чтобы посмотреть, сможет ли он прочитать новые изменения, сделанные сеансом 1:
session1> COMMIT;
Query OK, 0 rows affected (0.01 sec)
session2> SELECT * FROM accounts WHERE id = 1;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 80 | USD | 2021-07-13 20:39:27 |
+----+--------+---------+----------+---------------------+
1 row in set (0.01 sec)
Этот запрос SELECT по-прежнему возвращает старые данные для учетной записи 1 с балансом 80 долларов США, даже несмотря на то, что транзакция 1 изменила его на 70 долларов США и была успешно зафиксирована. Это связано с тем, что уровень изоляции REPEATABLE READ гарантирует, что все запросы на чтение в транзакции являются повторяемыми, что означает, что они всегда возвращают один и тот же результат, даже если изменения были внесены другими зафиксированными транзакциями.
Но что произойдет, если мы также запустим запрос UPDATE, чтобы вычесть 10 долларов США из баланса счета 1 во время сеанса 2? Изменится ли баланс на 70 USD или 60 USD или выдаст ошибку? Давайте посмотрим:
session2> UPDATE accounts SET balance = balance - 10 WHERE id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session2> SELECT * FROM accounts WHERE id = 1;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 60 | USD | 2021-07-13 20:39:27 |
+----+--------+---------+----------+---------------------+
1 row in set (0.01 sec)
Ошибки нет, и остаток на счете теперь составляет 60 долларов США, что является правильным значением, поскольку транзакция 1 уже зафиксировала изменение, изменившее баланс на 70 долларов США.
Однако с точки зрения транзакции 2 это не имеет смысла: в последнем SELECT-запросе она видела баланс 80 USD, а после вычитания 10 USD со счета теперь видит остаток 60 USD. Математика здесь не работает, потому что на эту транзакцию все еще влияют параллельные обновления от других транзакций.
Это сценарий, в котором может помочь использование SERIALIZABLE. Давайте вернемся к моменту до внесения каких-либо изменений. На этот раз мы явно установим уровень изоляции обоих сеансов в SERIALIZABLE с помощью SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE перед запуском транзакций с помощью BEGIN. Опять же, в сеансе 1 мы выбираем все учетные записи:
session1> SELECT * FROM accounts;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 80 | USD | 2021-07-13 20:39:27 |
| 2 | Sergey | 100 | USD | 2021-07-13 20:39:32 |
| 3 | Markus | 100 | USD | 2021-07-13 20:39:39 |
+----+--------+---------+----------+---------------------+
3 rows in set (0.00 sec)
И в сеансе 2 мы выбираем все счета с балансом больше 80 долларов США:
session2> SELECT * FROM accounts WHERE balance >= 80;
+----+--------+---------+----------+---------------------+
| id | owner | balance | currency | created_at |
+----+--------+---------+----------+---------------------+
| 1 | Vinnie | 80 | USD | 2021-07-13 20:39:27 |
| 2 | Sergey | 100 | USD | 2021-07-13 20:39:32 |
| 3 | Markus | 100 | USD | 2021-07-13 20:39:39 |
+----+--------+---------+----------+---------------------+
3 rows in set (0.00 sec)
Теперь в сеансе 1 мы вычитаем 10 долларов США со счета 1:
session1> UPDATE accounts SET balance = balance - 10 WHERE id = 1;И… ничего не происходит. На этот раз запрос UPDATE заблокирован — запрос SELECT в сеансе 1 заблокировал эти строки и препятствует успешному выполнению UPDATE в сеансе 2. Поскольку мы явно начали наши транзакции с BEGIN (что имеет тот же эффект, что и отключение автоматической фиксации), InnoDB неявно преобразует все простые операторы SELECT в каждой транзакции в SELECT ... FOR SHARE. Он не знает заранее, будет ли транзакция выполнять только чтение или будет изменять строки, поэтому InnoDB необходимо заблокировать ее, чтобы избежать проблемы, которую мы продемонстрировали в предыдущем примере. В этом примере, если бы автофиксация была включена, запрос SELECT в сеансе 2 не блокировал бы обновление, которое мы пытаемся выполнить в сеансе 1: MySQL распознал бы, что запрос является простым SELECT и не должен блокировать другие запросы, поскольку он не собирается изменять строки.
Однако обновление в сеансе 2 не будет зависать навсегда; эта блокировка имеет время ожидания, которое контролируется параметром innodb_lock_wait_timeout. Таким образом, если сеанс 1 не фиксирует или не откатывает свою транзакцию для снятия блокировки, по истечении времени ожидания сеанса MySQL выдает следующую ошибку:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionБлокировка
Теперь, когда мы увидели, как работает каждый уровень изоляции, давайте рассмотрим различные стратегии блокировки, используемые InnoDB для их реализации.
Блокировки используются в базах данных для защиты общих ресурсов или объектов. Они могут действовать на разных уровнях, например:
Блокировка таблицы
Блокировка метаданных
Блокировка строки
Блокировка на уровне приложения
MySQL использует блокировку метаданных для управления одновременным доступом к объектам базы данных и обеспечения согласованности данных. Когда в таблице есть активная транзакция (явная или неявная), MySQL не разрешает запись метаданных (операторы DDL, например, обновляют метаданные таблицы). Это делается для обеспечения согласованности метаданных в параллельной среде.
Если существует активная транзакция (выполняется, незафиксирована или откатывается), когда сеанс выполняет одну из операций, упомянутых в следующем списке, сеанс, запрашивающий запись данных, будет удерживаться в состоянии Waiting for table metadata lock. Ожидание блокировки метаданных может произойти в любом из следующих сценариев:
-
Когда вы создаете или удаляете индекс
-
При изменении структуры таблицы
-
При выполнении операций обслуживания таблицы (
OPTIMIZE TABLE REPAIR TABLEи т. д.) -
Когда вы удаляете таблицу
-
При попытке получить блокировку записи на уровне таблицы (
LOCK TABLE table_name WRITE)
Чтобы обеспечить одновременный доступ для записи несколькими сеансами, InnoDB поддерживает блокировку на уровне строк.
Блокировки уровня приложения или пользователя, такие как предоставляемые GET_LOCK(), могут использоваться для имитации блокировок базы данных, таких как блокировки записей.
В этой книге основное внимание уделяется метаданным и блокировкам строк, поскольку именно они влияют на большинство пользователей и являются наиболее распространенными.
Блокировки метаданных
Документация MySQL дает лучшее определение блокировок метаданных:
Чтобы обеспечить сериализуемость транзакций, сервер не должен позволять одному сеансу выполнять оператор языка определения данных (DDL) для таблицы, которая используется в незавершенной явно или неявно запущенной транзакции в другом сеансе. Сервер достигает этого, захватывая блокировки метаданных для таблиц, используемых в транзакции, и откладывая освобождение блокировок до завершения транзакции. Блокировка метаданных в таблице предотвращает изменения в структуре таблицы. Такой подход к блокировке означает, что таблица, используемая транзакцией в рамках одного сеанса, не может использоваться в операторах DDL другими сеансами до тех пор, пока транзакция не завершится.
Имея в виду это определение, давайте посмотрим на блокировку метаданных в действии. Сначала мы создадим фиктивную таблицу и загрузим в нее несколько строк:
USE test;
DROP TABLE IF EXISTS `joinit`;
CREATE TABLE `joinit` (
`i` int(11) NOT NULL AUTO_INCREMENT,
`s` varchar(64) DEFAULT NULL,
`t` time NOT NULL,
`g` int(11) NOT NULL,
PRIMARY KEY (`i`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
INSERT INTO joinit VALUES (NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )));
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
INSERT INTO joinit SELECT NULL, uuid(), time(now()), (FLOOR( 1 + RAND( ) *60 )) FROM joinit;
Теперь, когда у нас есть фиктивные данные, мы откроем один сеанс (сеанс 1) и выполним UPDATE:
session1> UPDATE joinit SET t=now();Затем во втором сеансе мы попытаемся добавить новый столбец в эту таблицу, пока выполняется UPDATE:
session2> ALTER TABLE joinit ADD COLUMN b INT;И в третьем сеансе мы можем выполнить команду SHOW PROCESSLIST, чтобы визуализировать блокировку метаданных:
session3> SHOW PROCESSLIST;
+----+----------+-----------+------+---------+------+...
| Id | User | Host | db | Command | Time |...
+----+----------+-----------+------+---------+------+...
| 10 | msandbox | localhost | test | Query | 3 |...
| 11 | msandbox | localhost | test | Query | 1 |...
| 12 | msandbox | localhost | NULL | Query | 0 |...
+----+----------+-----------+------+---------+------+...
...+---------------------------------+-------------------------------------+...
...| State | Info |...
...+---------------------------------+-------------------------------------+...
...| updating | UPDATE joinit SET t=now() |...
...| Waiting for table metadata lock | ALTER TABLE joinit ADD COLUMN b INT |...
...| starting | SHOW PROCESSLIST |...
...+---------------------------------+-------------------------------------+...
...+-----------+---------------+
...| Rows_sent | Rows_examined |
...+-----------+---------------+
...| 0 | 179987 |
...| 0 | 0 |
...| 0 | 0 |
...+-----------+---------------+
Обратите внимание, что длительный запрос или запрос, не использующий автофиксацию, будет иметь тот же эффект. Например, предположим, что у нас есть UPDATE, работающий в сеансе 1:
mysql> SET SESSION autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> UPDATE joinit SET t=NOW() LIMIT 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
И мы выполняем оператор DML в сеансе 2:
mysql> ALTER TABLE joinit ADD COLUMN b INT;Если мы проверим список процессов в сеансе 3, то увидим, что DDL ожидает блокировки метаданных (поток 11), в то время как поток 10 бездействует с момента выполнения UPDATE (все еще не зафиксирован):
mysql> SHOW PROCESSLIST;Прежде чем мы начнем использовать схему sys, необходимо включить инструменты MySQL для мониторинга этих блокировок. Для этого выполните следующую команду:
mysql> UPDATE performance_schema.setup_instruments SET enabled = 'YES'
-> WHERE NAME = 'wait/lock/metadata/sql/mdl';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
Следующий запрос использует представление schema_table_lock_waits из схемы sys, чтобы проиллюстрировать, как отслеживать блокировки метаданных в базе данных MySQL:
mysql> SELECT * FROM sys.schema_table_lock_waits;В этом представлении показано, какие сеансы заблокированы в ожидании блокировки метаданных и что их блокирует. Вместо выбора всех полей в следующем примере показано более компактное представление:
mysql> SELECT object_name, waiting_thread_id, waiting_lock_type,
-> waiting_query, sql_kill_blocking_query, blocking_thread_id
-> FROM sys.schema_table_lock_waits;
+-------------+-------------------+-------------------+...
| object_name | waiting_thread_id | waiting_lock_type |...
+-------------+-------------------+-------------------+...
| joinit | 29 | EXCLUSIVE |...
| joinit | 29 | EXCLUSIVE |...
+-------------+-------------------+-------------------+...
...+-------------------------------------------------------------------+...
...| waiting_query |...
...+-------------------------------------------------------------------+...
...| ALTER TABLE joinit ADD COLUMN ... CHAR(32) DEFAULT 'dummy_text' |...
...| ALTER TABLE joinit ADD COLUMN ... CHAR(32) DEFAULT 'dummy_text' |...
...|-------------------------------------------------------------------+...
...+-------------------------+--------------------+
...| sql_kill_blocking_query | blocking_thread_id |
...+-------------------------+--------------------+
...| KILL QUERY 3 | 29 |
...| KILL QUERY 5 | 31 |
...+-------------------------+--------------------+
2 rows in set (0.00 sec)
Давайте посмотрим, что происходит, когда мы запрашиваем таблицу metadata_locks:
mysql> SELECT * FROM performance_schema.metadata_locks\G
*************************** 1. row ***************************
OBJECT_TYPE: GLOBAL
OBJECT_SCHEMA: NULL
OBJECT_NAME: NULL
OBJECT_INSTANCE_BEGIN: 140089691017472
LOCK_TYPE: INTENTION_EXCLUSIVE
LOCK_DURATION: STATEMENT
LOCK_STATUS: GRANTED
SOURCE:
OWNER_THREAD_ID: 97
OWNER_EVENT_ID: 34
...
*************************** 6. row ***************************
OBJECT_TYPE: TABLE
OBJECT_SCHEMA: performance_schema
OBJECT_NAME: metadata_locks
OBJECT_INSTANCE_BEGIN: 140089640911984
LOCK_TYPE: SHARED_READ
LOCK_DURATION: TRANSACTION
LOCK_STATUS: GRANTED
SOURCE:
OWNER_THREAD_ID: 98
OWNER_EVENT_ID: 10
6 rows in set (0.00 sec)
Обратите внимание, что для объединенной таблицы установлена блокировка SHARED_UPGRADABLE, а для той же таблицы ожидается блокировка EXCLUSIVE.
Мы можем получить хороший обзор всех блокировок метаданных из других сеансов, за исключением нашего текущего, с помощью следующего запроса:
mysql> SELECT object_type, object_schema, object_name, lock_type,
-> lock_status, thread_id, processlist_id, processlist_info FROM
-> performance_schema.metadata_locks INNER JOIN performance_schema.threads
-> ON thread_id = owner_thread_id WHERE processlist_id <> connection_id();
+-------------+---------------+-------------+---------------------+...
| OBJECT_TYPE | OBJECT_SCHEMA | OBJECT_NAME | LOCK_TYPE |...
+-------------+---------------+-------------+---------------------+...
| GLOBAL | NULL | NULL | INTENTION_EXCLUSIVE |...
| SCHEMA | test | NULL | INTENTION_EXCLUSIVE |...
| TABLE | test | joinit | SHARED_UPGRADABLE |...
| BACKUP | NULL | NULL | INTENTION_EXCLUSIVE |...
| TABLE | test | joinit | EXCLUSIVE |...
+-------------+---------------+-------------+---------------------+...
...+-------------+-----------+----------------+...
...| LOCK_STATUS | THREAD_ID | PROCESSLIST_ID |...
...+-------------+-----------+----------------+...
...| GRANTED | 97 | 71 |...
...| GRANTED | 97 | 71 |...
...| GRANTED | 97 | 71 |...
...| GRANTED | 97 | 71 |...
...| PENDING | 97 | 71 |...
...+-------------+-----------+----------------+...
...+-------------------------------------+
...| PROCESSLIST_INFO |
...+-------------------------------------+
...| alter table joinit add column b int |
...| alter table joinit add column b int |
...| alter table joinit add column b int |
...| alter table joinit add column b int |
...| alter table joinit add column b int |
...+-------------------------------------+
5 rows in set (0.00 sec)
Если мы посмотрим внимательно, оператор DDL, ожидающий запроса сам по себе, не является проблемой: ему придется ждать, пока он не сможет получить блокировку метаданных, что и ожидается. Проблема в том, что во время ожидания он блокирует доступ к ресурсу для всех остальных запросов.
Мы рекомендуем следующие действия, чтобы избежать длительных блокировок метаданных:
-
Выполнение операций DDL в нерабочее время. Таким образом вы уменьшаете параллелизм в базе данных между обычной рабочей нагрузкой приложения и дополнительной рабочей нагрузкой, которую несет операция.
-
Всегда используйте автофиксацию. В MySQL автофиксация включена по умолчанию. Это позволит избежать транзакций с ожидающими коммитами.
-
При выполнении операции DDL установите низкое значение для
lock_wait_timeoutна уровне сеанса. Затем, если блокировка метаданных не может быть получена, она не будет блокироваться в течение длительного времени ожидания. Например:mysql> SET lock_wait_timeout = 3; mysql> CREATE INDEX idx_1 ON example (col1);
Вы также можете рассмотреть возможность использования инструмента pt-kill для уничтожения запросов, которые выполнялись в течение длительного времени. Например, чтобы убить запросы, которые выполнялись более 60 секунд, введите следующую команду:
$ pt-kill --busy-time 60 --killБлокировка строк
InnoDB реализует стандартную блокировку на уровне строк. Это означает, что в общих чертах существует два типа блокировок:
-
Общая (shared) (S) блокировка позволяет транзакции, удерживающей блокировку, читать строку.
-
Монопольная (exclusive) (X) блокировка позволяет транзакции, удерживающей блокировку, обновлять или удалять строку.
Названия говорят сами за себя: монопольные блокировки не позволяют нескольким транзакциям получить монопольную блокировку в одной и той же строке при совместном использовании общей блокировки. Вот почему для одной и той же строки возможно параллельное чтение, а параллельная запись не разрешена.
InnoDB также поддерживает множественную блокировку детализации, что позволяет сосуществовать блокировкам строк и блокировкам таблиц. Детализированная блокировка возможна из-за существования блокировок по намерению (intention locks), которые являются блокировками на уровне таблицы и указывают, какой тип блокировки (общая или монопольная) транзакция потребует позже для строки в таблице. Есть два типа блокировки намерения:
-
Преднамеренная общая (intention shared) блокировка (IS) указывает, что транзакция намеревается установить общую блокировку для отдельных строк в таблице.
-
Исключительная блокировка по намерению (intention exclusive) (IX) указывает на то, что транзакция намерена установить монопольную блокировку для отдельных строк в таблице.
Прежде чем транзакция сможет получить общую или монопольную блокировку, необходимо получить соответствующую блокировку намерения (IS или IX).
Чтобы немного упростить понимание, взгляните на Таблицу 6-1.
| X | IX | S | IS | |
|---|---|---|---|---|
| X | Конфликт | Конфликт | Конфликт | Конфликт |
| IX | Конфликт | Совместимы | Конфликт | Совместимы |
| S | Конфликт | Конфликт | Совместимы | Совместимы |
| IS | Конфликт | Совместимы | Совместимы | Совместимы |
Другой важной концепцией является блокировка промежутка (gap lock), которая представляет собой блокировку промежутка между записями индекса. Блокировки промежутка гарантируют, что новые строки не будут добавлены в интервале, заданном запросом; это означает, что когда вы запускаете один и тот же запрос дважды, вы получаете одинаковое количество строк, независимо от модификаций этой таблицы другими сеансами. Они делают чтения согласованными и, следовательно, обеспечивают согласованность репликации между серверами. Если вы выполните SELECT * FROM example_table WHERE id > 1000 FOR UPDATE дважды, вы ожидаете дважды получить один и тот же результат. Для этого InnoDB блокирует все записи индекса, найденные предложением WHERE, монопольной блокировкой, а промежутки между ними — общей блокировкой промежутка.
Давайте посмотрим на пример блокировку промежутка в действии. Сначала мы выполним оператор SELECT для таблицы person:
mysql> SELECT * FROM PERSON;
+----+-----------+
| i | name |
+----+-----------+
| 1 | Vinicius |
| 2 | Kuzmichev |
| 3 | Iwo |
| 4 | Peter |
| 5 | Marcelo |
| 6 | Guli |
| 7 | Nando |
| 10 | Jobin |
| 15 | Rafa |
| 18 | Leo |
+----+-----------+
10 rows in set (0.00 sec)
Теперь в сессии 1 мы выполним операцию удаления, но не будем фиксировать:
session1> DELETE FROM person WHERE name LIKE 'Jobin';
Query OK, 1 row affected (0.00 sec)
И если мы проверим сеанс 2, мы все еще можем увидеть строку с Jobin:
session2> SELECT * FROM person;
+----+-----------+
| i | name |
+----+-----------+
| 1 | Vinicius |
| 2 | Kuzmichev |
| 3 | Iwo |
| 4 | Peter |
| 5 | Marcelo |
| 6 | Guli |
| 7 | Nando |
| 10 | Jobin |
| 15 | Rafa |
| 18 | Leo |
+----+-----------+
10 rows in set (0.00 sec)
Результаты показывают, что в значениях столбца первичного ключа есть промежутки, которые теоретически можно использовать для вставки новых записей. Так что же произойдет, если мы попытаемся вставить новую строку со значением 11? Вставка будет заблокирована и завершится ошибкой:
transaction2 > INSERT INTO person VALUES (11, 'Bennie');
ERROR 1205 (HY000): Lockwait timeout exceeded; try restarting transaction
Если мы запустим SHOW ENGINE INNODB STATUS, мы увидим заблокированную транзакцию в разделе TRANSACTIONS:
------- TRX HAS BEEN WAITING 17 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 28 page no 3 n bits 80 index PRIMARY of table `test`.`person` trx id 4773 lock_mode X locks gap before rec insert intention waiting
Обратите внимание, что MySQL не нуждается в блокировке промежутков для операторов, которые блокируют строки, используя уникальный индекс для поиска уникальной строки. (Это не включает случай, когда условие поиска включает только некоторые столбцы уникального индекса с несколькими столбцами; в этом случае происходит блокировка промежутка.) Например, если столбец name имеет уникальный индекс, следующая инструкция DELETE использует только блокировку индексной записи:
mysql> CREATE UNIQUE INDEX idx ON PERSON (name);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> DELETE FROM person WHERE name LIKE 'Jobin';
Query OK, 1 row affected (0.00 sec)
Взаимная блокировка (deadlock)
Взаимная блокировка — это ситуация, когда два (или более) конкурирующих действия ожидают завершения другого. Как следствие, ни один из них ничего не делает. В компьютерных науках этот термин относится к определенному состоянию, когда каждый из двух или более процессов ожидает освобождения ресурса другим. В этом разделе мы поговорим конкретно о взаимоблокировках транзакций и о том, как InnoDB решает эту проблему.
Для возникновения взаимоблокировки должны существовать четыре условия (известные как условия Коффмана (Coffman conditions)):
-
Взаимное исключение. Процесс должен содержать хотя бы один ресурс в неразделяемом режиме. В противном случае MySQL не помешает процессу использовать ресурс, когда это необходимо. Только один процесс может использовать ресурс в любой момент времени.
-
Удержание и ожидание или удержание ресурсов. В настоящее время процесс удерживает по крайней мере один ресурс и запрашивает дополнительные ресурсы, удерживаемые другими процессами.
-
Нет преимущественного права. Ресурс может быть освобожден только добровольно удерживающим его процессом.
-
Круговое ожидание. Каждый процесс должен ожидать ресурса, удерживаемого другим процессом, который, в свою очередь, ожидает освобождения ресурса первым процессом.
Прежде чем перейти к примеру, есть некоторые неправильные представления, которые вы можете услышать, и которые необходимо прояснить. Вот они:
- Уровни изоляции транзакций ответственны за взаимоблокировки.
-
Уровень изоляции не влияет на вероятность взаимоблокировок. Уровень изоляции
READ COMMITTEDустанавливает меньшее количество блокировок и, следовательно, может помочь вам избежать определенных типов блокировок (например, блокировки пробелов), но не полностью предотвращает взаимоблокировки. - Небольшие транзакции не подвержены взаимным блокировкам.
-
Небольшие транзакции менее подвержены взаимоблокировкам, потому что они выполняются быстро, поэтому вероятность возникновения конфликта меньше, чем при более продолжительных операциях. Однако это все же может произойти, если транзакции используют другой порядок операций.
- Взаимные блокировки — ужасная вещь.
-
Взаимоблокировки в базе данных проблематичны, но InnoDB может разрешить их автоматически, если не отключено обнаружение взаимоблокировок (путем изменения значения
innodb_deadlock_detect). Взаимная блокировка — это плохая ситуация, но ее разрешение посредством завершения одной из транзакций гарантирует, что процессы не смогут удерживать ресурсы в течение длительного времени, замедляя или полностью останавливая базу данных до тех пор, пока вызывающий нарушение запрос не будет отменен с помощью параметраinnodb_lock_wait_timeout.
Чтобы проиллюстрировать взаимоблокировки, мы будем использовать базу данных world. Если вам нужно импортировать его, вы можете сделать это сейчас, следуя инструкциям в «Примерах моделирования отношений сущностей».
Начнем с получения списка итальянских городов в провинции Тоскана:
mysql> SELECT * FROM city WHERE CountryCode = 'ITA' AND District='Toscana';
+------+---------+-------------+----------+------------+
| ID | Name | CountryCode | District | Population |
+------+---------+-------------+----------+------------+
| 1471 | Firenze | ITA | Toscana | 376662 |
| 1483 | Prato | ITA | Toscana | 172473 |
| 1486 | Livorno | ITA | Toscana | 161673 |
| 1516 | Pisa | ITA | Toscana | 92379 |
| 1518 | Arezzo | ITA | Toscana | 91729 |
+------+---------+-------------+----------+------------+
5 rows in set (0.00 sec)
Теперь предположим, что у нас есть две транзакции, пытающиеся одновременно обновить население одних и тех же двух городов в Тоскане, но в разном порядке:
session1> UPDATE city SET Population=Population + 1 WHERE ID = 1471;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session2> UPDATE city SET Population=Population + 1 WHERE ID =1516;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
session1> UPDATE city SET Population=Population + 1 WHERE ID =1516;
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
session2> UPDATE city SET Population=Population + 1 WHERE ID = 1471;
Query OK, 1 row affected (5.15 sec)
Rows matched: 1 Changed: 1 Warnings: 0
И у нас была взаимоблокировка в сеансе 1. Важно отметить, что не всегда вторая транзакция завершается ошибкой. В этом примере сеанс 1 прервал MySQL. Мы можем получить информацию о последней взаимоблокировке, которая произошла в базе данных MySQL, запустив SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
------------------------
LATEST DETECTED DEADLOCK
------------------------
2020-12-05 16:08:19 0x7f6949359700
*** (1) TRANSACTION:
TRANSACTION 10502342, ACTIVE 34 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log
entries 1
MySQL thread id 71, OS thread handle 140090386671360, query id 5979282
localhost msandbox updating
update city set Population=Population + 1 where ID = 1471
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 6041 page no 15 n bits 248 index PRIMARY of table
`world`.`city` trx id 10502342 lock_mode X locks rec but not gap waiting
*** (2) TRANSACTION:
TRANSACTION 10502341, ACTIVE 62 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 75, OS thread handle 140090176542464, query id 5979283
localhost msandbox updating
update city set Population=Population + 1 where ID =1516
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 6041 page no 15 n bits 248 index PRIMARY of table
`world`.`city` trx id 10502341 lock_mode X locks rec but not gap
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 6041 page no 16 n bits 248 index PRIMARY of table
`world`.`city` trx id 10502341 lock_mode X locks rec but not gap waiting
*** WE ROLL BACK TRANSACTION (2)
...
Если вы хотите, вы можете регистрировать все взаимоблокировки, которые происходят в MySQL, в журнале ошибок MySQL. Используя параметр innodb_print_all_deadlocks, MySQL записывает всю информацию о взаимоблокировках из пользовательских транзакций InnoDB в журнал ошибок. В противном случае вы увидите информацию только о последней взаимоблокировке с помощью команды SHOW ENGINE INNODB STATUS.
Параметры MySQL, относящиеся к изоляции и блокировкам
Чтобы завершить эту главу, давайте взглянем на несколько параметров MySQL, которые связаны с поведением изоляции и длительностью блокировки:
transaction_isolation-
Устанавливает уровень изоляции транзакции. Этот параметр может изменить поведение на уровне
GLOBAL,SESSIONилиNEXT_TRANSACTION:mysql> SET SESSION transaction_isolation='READ-COMMITTED'; Query OK, 0 rows affected (0.00 sec) mysql> SHOW SESSION VARIABLES LIKE '%isol%'; +-----------------------+----------------+ | Variable_name | Value | +-----------------------+----------------+ | transaction_isolation | READ-COMMITTED | | tx_isolation | READ-COMMITTED | +-----------------------+----------------+ innodb_lock_wait_timeout-
Указывает количество времени в секундах, в течение которого транзакция InnoDB ожидает блокировки строки, прежде чем сдаться. Значение по умолчанию — 50 секунд. Транзакция вызывает следующую ошибку, если время ожидания блокировки превышает значение
innodb_lock_wait_timeout:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction innodb_print_all_deadlocks-
Заставляет MySQL записывать информацию обо всех взаимоблокировках, возникающих в результате пользовательских транзакций InnoDB, в журнал ошибок MySQL. Мы можем включить это динамически с помощью следующей команды:
mysql> SET GLOBAL innodb_print_all_deadlocks = 1; lock_wait_timeout-
Задает время ожидания в секундах для попыток получения блокировки метаданных. Чтобы избежать зависания базы данных из-за длинных блокировок метаданных, мы можем установить
lock_wait_timeout=1на уровне сеанса перед выполнением оператора DDL. В этом случае, если операция не может получить блокировку, она откажется и позволит выполнять другие запросы. Например:mysql> SET SESSION lock_wait_timeout=1; mysql> CREATE TABLE t1(i INT NOT NULL AUTO_INCREMENT PRIMARY KEY) -> ENGINE=InnoDB; innodb_deadlock_detect-
Отключает мониторинг взаимоблокировок. Обратите внимание, что это означает только то, что MySQL не будет убивать запрос, чтобы развязать узел взаимоблокировки. Отключение обнаружения взаимоблокировок не предотвратит возникновение взаимоблокировок, но заставит MySQL полагаться на настройку
innodb_lock_wait_timeoutдля отката транзакции при возникновении взаимоблокировки.
Глава 7
Дополнительные возможности MySQL
MySQL многофункциональна. В последних трех главах вы познакомились с широким спектром методов, которые можно использовать для запросов, изменения и управления данными. Тем не менее, MySQL может делать гораздо больше, и некоторые из этих дополнительных возможностей являются предметом рассмотрения в этой главе.
В этой главе вы узнаете, как:
-
Вставлять данные в базу данных из других источников, в том числе с помощью запросов и из текстовых файлов.
-
Выполнять обновления и удаления, используя несколько таблиц в одном операторе.
-
Заменять данные.
-
Использовать функции MySQL в запросах для удовлетворения более сложных информационных потребностей.
-
Анализировать запросы с помощью инструкции
EXPLAIN, а затем улучшать их производительность с помощью простых методов оптимизации. -
Использовать альтернативные механизмы хранения для изменения свойств таблицы.
Вставка данных с помощью запросов
Большую часть времени вы будете создавать таблицы, используя данные из другого источника. Таким образом, примеры, которые вы видели в главе 3, иллюстрируют только часть проблемы: они показывают, как вставлять данные, которые уже находятся в нужной вам форме (то есть отформатированы как инструкция SQL INSERT). Другие способы вставки данных включают использование операторов SQL SELECT в других таблицах или базах данных и чтение файлов из других источников. В этом разделе показано, как использовать прежний метод вставки данных; вы узнаете, как вставлять данные из файла значений, разделенных запятыми, в следующем разделе «Загрузка данных из файлов, разделенных запятыми».
Предположим, мы решили создать новую таблицу в базе данных sakila. Он будет хранить случайный список фильмов, которые мы хотим более активно рекламировать. В реальном мире вы, вероятно, захотите использовать науку о данных, чтобы узнать, какие фильмы выделить, но мы будем придерживаться основ. Этот список фильмов позволит покупателям ознакомиться с различными разделами каталога, заново открыть для себя некоторые старые любимые фильмы и узнать о скрытых сокровищах, которые они еще не исследовали. Мы решили структурировать таблицу следующим образом:
mysql> CREATE TABLE recommend
-> film_id SMALLINT UNSIGNED,
-> language_id TINYINT UNSIGNED,
-> release_year YEAR,
-> title VARCHAR(128),
-> length SMALLINT UNSIGNED,
-> sequence_id SMALLINT AUTO_INCREMENT,
-> PRIMARY KEY (sequence_id)
-> );
Query OK, 0 rows affected (0.05 sec)
В этой таблице хранится информация о каждом фильме, позволяющая найти актера, категорию и другую информацию с помощью простых запросов к другим таблицам. Она также хранит sequence_id, который является уникальным числом, перечисляющим, где фильм находится в нашем шорт-листе. Когда вы начнете использовать функцию рекомендаций, вы сначала увидите фильм с sequence_id равным 1, затем 2 и так далее. Вы можете видеть, что мы используем функцию MySQL AUTO_INCREMENT для выделения значений sequence_id.
Теперь нам нужно заполнить нашу новую таблицу рекомендаций случайным выбором фильмов. Важно отметить, что мы собираемся выполнять SELECT и INSERT вместе в одном операторе. Вот так:
mysql> INSERT INTO recommend (film_id, language_id, release_year, title, length)
-> SELECT film_id, language_id, release_year, title, length
-> FROM film ORDER BY RAND() LIMIT 10;
Query OK, 10 rows affected (0.02 sec)
Records: 10 Duplicates: 0 Warnings: 0
Теперь давайте разберемся, что произошло, прежде чем объяснять, как работает эта команда:
mysql> SELECT * FROM recommend;
+---------+-----+--------------------+--------+-------------+
| film_id | ... | title | length | sequence_id |
+---------+-----+--------------------+--------+-------------+
| 542 | ... | LUST LOCK | 52 | 1 |
| 661 | ... | PAST SUICIDES | 157 | 2 |
| 613 | ... | MYSTIC TRUMAN | 92 | 3 |
| 757 | ... | SAGEBRUSH CLUELESS | 106 | 4 |
| 940 | ... | VICTORY ACADEMY | 64 | 5 |
| 917 | ... | TUXEDO MILE | 152 | 6 |
| 709 | ... | RACER EGG | 147 | 7 |
| 524 | ... | LION UNCUT | 50 | 8 |
| 30 | ... | ANYTHING SAVANNAH | 82 | 9 |
| 602 | ... | MOURNING PURPLE | 146 | 10 |
+---------+-----+--------------------+--------+-------------+
10 rows in set (0.00 sec)
Как видите, в нашем списке рекомендаций 10 фильмов, пронумерованных значениями sequence_id от 1 до 10. Мы готовы начать рекомендовать случайный выбор фильмов. Не волнуйтесь, если ваши результаты отличаются; это следствие того, как работает функция RAND().
Оператор SQL, который мы использовали для заполнения таблицы, состоит из двух частей: INSERT INTO и SELECT. Оператор INSERT INTO перечисляет целевую таблицу, в которой будут храниться данные, за которой следует необязательный список имен столбцов в круглых скобках; если вы опустите имена столбцов, предполагается, что все столбцы в целевой таблице будут отображаться в том порядке, в котором они появляются в выходных данных оператора DESCRIBE TABLE или SHOW CREATE TABLE. Оператор SELECT выводит столбцы, которые должны соответствовать типу и порядку списка, предоставленного для оператора INSERT INTO (или неявного полного списка, если он не указан). Общий эффект заключается в том, что строки, выводимые оператором SELECT, вставляются в целевую таблицу с помощью оператора INSERT INTO. В нашем примере, film_id, language_id, release_year, title, и значения length из таблицы film вставляются в пять столбцов с теми же именами и типами в таблице recommend; sequence_id автоматически создается с помощью функции MySQL AUTO_INCREMENT, поэтому он не указывается в операторах.
Наш пример включает предложение ORDER BY RAND(); оно упорядочивает результаты в соответствии с функцией MySQL RAND(). Функция RAND() возвращает псевдослучайное число в диапазоне от 0 до 1:
mysql> SELECT RAND();
+--------------------+
| RAND() |
+--------------------+
| 0.4593397513584604 |
+--------------------+
1 row in set (0.00 sec)
Генератор псевдослучайных чисел не генерирует действительно случайные числа, а генерирует числа на основе некоторых свойств системы, таких как время суток. Это достаточно случайно для большинства приложений; заметным исключением являются криптографические приложения, безопасность которых зависит от истинной случайности чисел.
Если вы запросите значение RAND() в операции SELECT, вы получите случайное значение для каждой возвращаемой строки:
mysql> SELECT title, RAND() FROM film LIMIT 5;
+------------------+---------------------+
| title | RAND() |
+------------------+---------------------+
| ACADEMY DINOSAUR | 0.5514843506286706 |
| ACE GOLDFINGER | 0.37940252980161693 |
| ADAPTATION HOLES | 0.2425596278557178 |
| AFFAIR PREJUDICE | 0.07459058060738312 |
| AFRICAN EGG | 0.6452740502034072 |
+------------------+---------------------+
5 rows in set (0.00 sec)
Поскольку значения фактически случайны, вы почти наверняка увидите результаты, отличные от показанных здесь. Более того, если вы повторите оператор, вы также увидите разные возвращаемые значения. Можно передать RAND() целочисленный аргумент, называемый начальным числом. Это приведет к тому, что функция RAND() будет генерировать одни и те же значения для одних и тех же входных данных каждый раз, когда используется начальное значение — это не очень полезно для того, чего мы пытаемся достичь здесь, но, тем не менее, возможность. Вы можете попробовать запустить следующую инструкцию столько раз, сколько захотите, и результаты не изменятся:
SELECT title, RAND(1) FROM film LIMIT 5;Вернемся к операции INSERT. Когда мы просим упорядочить результаты с помощью RAND(), результаты оператора SELECT сортируются в псевдослучайном порядке. LIMIT 10 предназначен для ограничения количества строк, возвращаемых SELECT; мы ограничили в этом примере просто для удобства чтения.
Оператор SELECT в операторе INSERT INTO может использовать все обычные функции операторов SELECT. Вы можете использовать объединения, агрегацию, функции и любые другие возможности по вашему выбору. Вы также можете запрашивать данные из одной базы данных в другой, указав перед именами таблиц имя базы данных, за которым следует символ точки (.). Например, если вы хотите вставить таблицу actor из базы данных film в новую базу данных произведений искусства, вы можете сделать следующее:
mysql> CREATE DATABASE art;
Query OK, 1 row affected (0.01 sec)
mysql> USE art;
Database changed
mysql> CREATE TABLE people
-> person_id SMALLINT UNSIGNED,
-> first_name VARCHAR(45),
-> last_name VARCHAR(45),
-> PRIMARY KEY (person_id)
-> );
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO art.people (person_id, first_name, last_name)
-> SELECT actor_id, first_name, last_name FROM sakila.actor;
Query OK, 200 rows affected (0.01 sec)
Records: 200 Duplicates: 0 Warnings: 0
Вы можете видеть, что новая таблица people называется art.people (хотя это и не обязательно, так как art — это база данных, которая в настоящее время используется), а таблица actor называется sakila.actor (как и должно быть, поскольку это база данных не используется). Также обратите внимание, что имена столбцов не обязательно должны совпадать для SELECT и INSERT.
Иногда вы сталкиваетесь с проблемами дублирования при вставке с помощью оператора SELECT. Если вы попытаетесь вставить одно и то же значение первичного ключа дважды, работа MySQL прервется. Этого не произойдет в таблице recommend, если вы автоматически выделяете новый sequence_id с помощью функции AUTO_INCREMENT. Однако мы можем принудительно добавить дубликат в таблицу, чтобы показать поведение:
mysql> USE sakila;
Database changed
mysql> INSERT INTO recommend (film_id, language_id, release_year,
-> title, length, sequence_id )
-> SELECT film_id, language_id, release_year, title, length, 1
-> FROM film LIMIT 1;
ERROR 1062 (23000): Duplicate entry '1' for key 'recommend.PRIMARY'
Если вы хотите, чтобы MySQL игнорировал это и продолжал работать, добавьте ключевое слово IGNORE после INSERT:
mysql> INSERT IGNORE INTO recommend (film_id, language_id, release_year,
-> title, length, sequence_id )
-> SELECT film_id, language_id, release_year, title, length, 1
-> FROM film LIMIT 1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
Records: 1 Duplicates: 1 Warnings: 1
MySQL не жалуется, но сообщает, что обнаружил дубликат. Обратите внимание, что данные не изменяются; все, что мы сделали, это проигнорировали ошибку. Это полезно в операциях массовой загрузки, когда вы не хотите, чтобы произошел сбой на полпути к выполнению сценария, вставляющего миллион строк. Теперь мы можем проверить предупреждение, чтобы увидеть ошибку Duplicate entry в качестве предупреждения:
mysql> SHOW WARNINGS;
+---------+------+-------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------+
| Warning | 1062 | Duplicate entry '1' for key 'recommend.PRIMARY' |
+---------+------+-------------------------------------------------+
1 row in set (0.00 sec)
Наконец, обратите внимание, что можно выполнять вставку в таблицу, указанную в операторе SELECT, но вам все равно нужно избегать дублирования первичных ключей:
mysql> INSERT INTO actor SELECT
-> actor_id, first_name, last_name, NOW() FROM actor;
ERROR 1062 (23000): Duplicate entry '1' for key 'actor.PRIMARY'
Есть два способа избежать ошибки. Во-первых, в таблице actor включено AUTO_INCREMENT для actor_id, поэтому, если вы полностью пропустите этот столбец в INSERT, вы не получите ошибку, так как новые значения будут сгенерированы автоматически. (Синтаксис оператора INSERT объясняется в разделе «Альтернативный синтаксис».) Вот пример, в котором будет только одна запись (из-за предложения LIMIT):
INSERT INTO actor(first_name, last_name, last_update)
SELECT first_name, last_name, NOW() FROM actor LIMIT 1;
Второй способ — изменить actor_id в запросе SELECT таким образом, чтобы предотвратить коллизии. Давайте попробуем это:
mysql> INSERT INTO actor SELECT
-> actor_id+200, first_name, last_name, NOW() FROM actor;
Query OK, 200 rows affected (0.01 sec)
Records: 200 Duplicates: 0 Warnings: 0
Здесь мы копируем строки, но перед их вставкой увеличиваем их значения actor_id на 200, потому что мы помним, что изначально было 200 строк. Вот результат:
mysql> SELECT * FROM actor;
+----------+-------------+--------------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+-------------+--------------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
| ... |
| 198 | MARY | KEITEL | 2006-02-15 04:34:33 |
| 199 | JULIA | FAWCETT | 2006-02-15 04:34:33 |
| 200 | THORA | TEMPLE | 2006-02-15 04:34:33 |
| 201 | PENELOPE | GUINESS | 2021-02-28 10:24:49 |
| 202 | NICK | WAHLBERG | 2021-02-28 10:24:49 |
| ... |
| 398 | MARY | KEITEL | 2021-02-28 10:24:49 |
| 399 | JULIA | FAWCETT | 2021-02-28 10:24:49 |
| 400 | THORA | TEMPLE | 2021-02-28 10:24:49 |
+----------+-------------+--------------+---------------------+
400 rows in set (0.00 sec)
Вы можете видеть, как имена, фамилии и значения last_update начинают повторяться, начиная с actor_id 201.
Также можно использовать подзапросы в операторах INSERT SELECT. Например, верно следующее утверждение:
*INSERT INTO actor SELECT * FROM*
*(SELECT actor_id+400, first_name, last_name, NOW() FROM actor) foo;*
Загрузка данных из файлов с разделителями-запятыми
В наши дни базы данных обычно не являются чем-то второстепенным. Они вездесущи и просты в использовании, и большинство ИТ-специалистов знают о них. Тем не менее, конечные пользователи находят их сложными, и, если не созданы специализированные пользовательские интерфейсы, ввод и анализ большого количества данных вместо этого выполняется в различных программах для работы с электронными таблицами. Эти программы обычно имеют уникальные форматы файлов, открытые или закрытые, но большинство из них позволяют экспортировать данные в виде строк значений, разделенных запятыми (CSV), также называемых форматом с разделителями-запятыми (comma-delimited). Вы можете импортировать такие данные с небольшими усилиями в MySQL.
Еще одна распространенная задача, которую можно решить при работе с CSV, — это передача данных в гетерогенной среде. Если в вашей установке запущено различное программное обеспечение баз данных, и особенно если вы используете DBaaS в облаке, перемещение данных между этими системами может быть сложной задачей. Однако базовые данные CSV могут быть для них наименьшим общим знаменателем. Обратите внимание, что в случае любой передачи данных вы всегда должны помнить, что CSV не имеет понятий схем, типов данных или ограничений. Но в качестве плоского формата файла данных он работает хорошо.
Если вы не используете программу для работы с электронными таблицами, вы все равно можете часто использовать инструменты командной строки, такие как sed и awk — очень старые и мощные утилиты Unix — для преобразования текстовых данных в формат CSV, пригодный для импорта MySQL. Некоторые облачные базы данных позволяют экспортировать свои данные напрямую в CSV. В некоторых других случаях приходится писать небольшие программы, которые считывают данные и создают CSV-файл. В этом разделе показаны основы того, как импортировать данные CSV в MySQL.
Давайте поработаем на примере. У нас есть список объектов НАСА с их адресами и контактной информацией, которые мы хотим сохранить в базе данных. В настоящее время он хранится в файле CSV с именем NASA_Facilities.csv и имеет формат, показанный на рис. 7-1.

Рисунок 7-1. Список объектов НАСА, хранящийся в файле электронной таблицы
Вы можете видеть, что каждый объект связан с центром, и может указывать дату, когда он был занят, и, возможно, его статус. Полный список столбцов выглядит следующим образом:
Center
Center Search Status
Facility
FacilityURL
Occupied
Status
URL Link
Record Date
Last Update
Country
Contact
Phone
Location
City
State
Zipcode
Этот пример взят непосредственно с общедоступного Open Data Portal НАСА, а файл доступен в репозитории книги на GitHub. Поскольку это уже файл CSV, нам не нужно преобразовывать его из другого формата файла (например, XLS). Однако, если вам нужно сделать это в вашем собственном проекте, обычно это так же просто, как использовать команду «Сохранить как» в программе для работы с электронными таблицами; только не забудьте выбрать CSV в качестве выходного формата.
Если вы откроете файл NASA_facilities.csv с помощью текстового редактора, вы увидите, что в нем есть одна строка на строку электронной таблицы со значениями для каждого столбца, разделенными запятыми. Если вы работаете на платформе, отличной от Windows, вы можете обнаружить, что в некоторых CSV-файлах каждая строка заканчивается знаком ^M, но не беспокойтесь об этом; это артефакт происхождения Windows. Данные в этом формате часто называют форматом DOS, и большинство программных приложений могут работать с ним без проблем. В нашем случае данные в формате Unix, поэтому в Windows вы можете увидеть, что все строки объединены. Вы можете попробовать использовать другой текстовый редактор, если это так. Вот несколько усеченных по ширине строк, выбранных из NASA_Facilities.csv:
Center,Center Search Status,Facility,FacilityURL,Occupied,Status,...
Kennedy Space Center,Public,Control Room 2/1726/HGR-S ,,...
Langley Research Center,Public,Micometeroid/LDEF Analysis Laboratory,,...
Kennedy Space Center,Public,SRM Rotation and Processing Facility/K6-0494 ,...
Marshall Space Flight Center,..."35812(34.729538, -86.585283)",Huntsville,...
Если внутри значений есть запятые или другие специальные символы, все значение заключается в кавычки, как в последней строке, показанной здесь.
Давайте импортируем эти данные в MySQL. Сначала создайте новую базу данных nasa:
mysql> CREATE DATABASE nasa;
Query OK, 1 row affected (0.01 sec)
Выберите ее в качестве активной базы данных:
mysql> USE nasa;
Database changed
Теперь создайте таблицу facilities для хранения данных. Она должна обрабатывать все поля, которые мы видим в файле CSV, который удобно имеет заголовок:
mysql> CREATE TABLE facilities (
-> center TEXT,
-> center_search_status TEXT,
-> facility TEXT,
-> facility_url TEXT,
-> occupied TEXT,
-> status TEXT,
-> url_link TEXT,
-> record_date DATETIME,
-> last_update TIMESTAMP NULL,
-> country TEXT,
-> contact TEXT,
-> phone TEXT,
-> location TEXT,
-> city TEXT,
-> state TEXT,
-> zipcode TEXT
-> );
Query OK, 0 rows affected (0.03 sec)
Здесь мы немного жульничаем с типами данных. НАСА предоставляет схему набора данных, но для большинства полей тип задается как «Plain Text», и мы также не можем хранить «Website URL» как что-либо, кроме текста. Однако мы не знаем, сколько данных будет храниться в каждом столбце. Таким образом, мы по умолчанию используем тип TEXT, что похоже на определение столбца как VARCHAR(65535). Между этими двумя типами есть некоторые различия, как вы, наверное, помните из раздела «Строковые типы», но в данном примере они не важны. Мы не определяем никаких индексов и не накладываем никаких ограничений на нашу таблицу. Если вы загружаете совершенно новый набор данных, который довольно мал, может быть полезно сначала загрузить его, а затем проанализировать. Для больших наборов данных убедитесь, что таблица структурирована как можно лучше, иначе вы потратите значительное количество времени на ее изменение позже.
Теперь, когда мы настроили таблицу базы данных, мы можем импортировать данные из файла с помощью команды LOAD DATA INFILE:
mysql> LOAD DATA INFILE 'NASA_Facilities.csv' INTO TABLE facilities
-> FIELDS TERMINATED BY ',';
ERROR 1290 (HY000): The MySQL server is running with
the --secure-file-priv option so it cannot execute this statement
О, нет! Мы получили ошибку. По умолчанию MySQL не позволяет вам загружать какие-либо данные с помощью команды LOAD DATA INFILE. Поведение управляется системной переменной secure_file_priv. Если для переменной задан путь, загружаемый файл должен находиться по этому конкретному пути и быть доступным для чтения сервером MySQL. Если переменная не установлена, что считается небезопасным, то загружаемый файл должен быть доступен для чтения только серверу MySQL. По умолчанию MySQL 8.0 в Linux устанавливает эту переменную следующим образом:
mysql> SELECT @@secure_file_priv;
+-----------------------+
| @@secure_file_priv |
+-----------------------+
| /var/lib/mysql-files/ |
+-----------------------+
1 row in set (0.00 sec)
И в Windows:
mysql> SELECT @@secure_file_priv;
+------------------------------------------------+
| @@secure_file_priv |
+------------------------------------------------+
| C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\ |
+------------------------------------------------+
1 row in set (0.00 sec)
В Linux или других Unix-подобных системах вам необходимо скопировать файл в этот каталог, возможно, используя sudo, чтобы разрешить операцию, а затем изменить его разрешения, чтобы программа mysqld могла получить доступ к файлу. В Windows вам нужно только скопировать файл в правильное место назначения.
Давай сделаем это. В Linux или аналогичных системах вы можете запускать такие команды:
$ ls -lh $HOME/Downloads/NASA_Facilities.csv
-rw-r--r--. 1 skuzmichev skuzmichev 114K
Feb 28 14:19 /home/skuzmichev/Downloads/NASA_Facilities.csv
$ sudo cp -vip ~/Downloads/NASA_Facilities.csv /var/lib/mysql-files
[sudo] password for skuzmichev:
'/home/skuzmichev/Downloads/NASA_Facilities.csv'
-> '/var/lib/mysql-files/NASA_Facilities.csv'
$ sudo chown mysql:mysql /var/lib/mysql-files/NASA_Facilities.csv
$ sudo ls -lh /var/lib/mysql-files/NASA_Facilities.csv
-rw-r--r--. 1 mysql mysql 114K
Feb 28 14:19 /var/lib/mysql-files/NASA_Facilities.csv
В Windows вы можете использовать файловый менеджер для копирования или перемещения файла.
Теперь мы готовы повторить попытку загрузки. Когда наш целевой файл не находится в текущем каталоге, нам нужно передать полный путь команде:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ',';
ERROR 1292 (22007): Incorrect datetime value:
'Record Date' for column 'record_date' at row 1
Что ж, это выглядит неправильно: Record Date — это действительно не дата, а имя столбца. Мы сделали глупую, но распространенную ошибку, загрузив файл CSV с заголовком. Нам нужно указать MySQL опустить его:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ','
-> IGNORE 1 LINES;
ERROR 1292 (22007): Incorrect datetime value:
'03/01/1996 12:00:00 AM' for column 'record_date' at row 1
Оказывается, этот формат даты не соответствует ожиданиям MySQL. Это чрезвычайно распространенная проблема. Есть пара выходов. Во-первых, мы можем просто изменить наш столбец record_date на тип TEXT. Мы потеряем тонкости правильного типа данных даты и времени, но сможем получить данные в нашу базу данных. Во-вторых, мы можем конвертировать данные, полученные из файла, на лету. Чтобы продемонстрировать разницу в результатах, мы указали занятый столбец (который является полем даты) как ТЕКСТ. Прежде чем мы перейдем к сложностям преобразования, давайте попробуем запустить ту же команду в Windows:
mysql> LOAD DATA INFILE
-> 'C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ',';
ERROR 1290 (HY000): The MySQL server is running with
the --secure-file-priv option so it cannot execute this statement
Даже если файл присутствует в этом каталоге, выдается ошибка LOAD DATA INFILE. Причина этого в том, как MySQL работает с путями в Windows. Мы не можем просто использовать обычные пути в стиле Windows с этой или другими командами MySQL. Нам нужно экранировать каждую обратную косую черту (\) другой обратной косой чертой или изменить наш путь, чтобы использовать прямую косую черту (/). Оба варианта будут работать… или, скорее, в этом случае оба выдадут ошибку из-за ожидаемой проблемы с преобразованием record_date:
mysql> LOAD DATA INFILE
-> 'C:\\ProgramData\\MySQL\\MySQL Server 8.0\\Uploads\\NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ',';
ERROR 1292 (22007): Incorrect datetime value:
'Record Date' for column 'record_date' at row 1
mysql> LOAD DATA INFILE
-> 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ',';
ERROR 1292 (22007): Incorrect datetime value:
'Record Date' for column 'record_date' at row 1
После этого давайте вернемся к нашей проблеме преобразования даты. Как мы уже упоминали, это чрезвычайно распространенная проблема. Вы неизбежно столкнетесь с проблемами преобразования типов, потому что CSV не имеет типов, а разные базы данных предъявляют разные требования к разным типам. В этом случае открытый набор данных, который мы получили, имеет даты в следующем формате: 01.03.1996 00:00:00. Хотя это сделает нашу операцию более сложной, мы считаем, что преобразование значений дат из нашего CSV-файла является хорошим упражнением. Чтобы преобразовать произвольную строку в дату или хотя бы попытаться сделать такое преобразование, мы можем использовать функцию STR_TO_DATE(). Изучив документацию, мы пришли к следующему решению:
mysql> SELECT STR_TO_DATE('03/01/1996 12:00:00 AM',
-> '%m/%d/%Y %h:%i:%s %p') converted;
+---------------------+
| converted |
+---------------------+
| 1996-03-01 00:00:00 |
+---------------------+
1 row in set (0.01 sec)
Поскольку функция возвращает NULL при неудачном приведении, мы знаем, что нам удалось найти правильный вызов. Теперь нам нужно выяснить, как использовать функцию в команде LOAD DATA INFILE. Гораздо более длинная версия с использованием функции выглядит так:
mysql> LOAD DATA INFILE '/var/lib/mysql-files/NASA_Facilities.csv'
-> INTO TABLE facilities FIELDS TERMINATED BY ','
-> OPTIONALLY ENCLOSED BY '"'
-> IGNORE 1 LINES
-> (center, center_search_status, facility, facility_url,
-> occupied, status, url_link, @var_record_date, @var_last_update,
-> country, contact, phone, location, city, state, zipcode)
-> SET record_date = IF(
-> CHAR_LENGTH(@var_record_date)=0, NULL,
-> STR_TO_DATE(@var_record_date, '%m/%d/%Y %h:%i:%s %p')
-> ),
-> last_update = IF(
-> CHAR_LENGTH(@var_last_update)=0, NULL,
-> STR_TO_DATE(@var_last_update, '%m/%d/%Y %h:%i:%s %p')
-> );
Query OK, 485 rows affected (0.05 sec)
Records: 485 Deleted: 0 Skipped: 0 Warnings: 0
Это слишком много для команды команды! Давайте сломаем это. Первая строка указывает нашу команду LOAD DATA INFILE и путь к файлу. Во второй строке указывается целевая таблица и начинается спецификация FIELDS, начиная с TERMINATED BY ',', что означает, что наши поля разделены запятыми, как и ожидается для CSV. Третья строка добавляет еще один параметр в спецификацию FIELDS и сообщает MySQL, что некоторые поля (но не все) заключены в символ ". Это важно, потому что в нашем наборе данных есть некоторые записи с запятыми внутри полей "...". В четвертой строке мы указываем, что пропускаем первую строку файла, где, как мы знаем, находится заголовок.
Строки с 5 по 7 содержат спецификацию списка столбцов. Нам нужно преобразовать два столбца даты и времени, а для этого нам нужно прочитать их значения в переменные, которые затем устанавливаются в значения столбцов таблицы nasa.facilities. Однако мы не можем сказать это MySQL, не указав также все остальные столбцы. Если бы мы исключили некоторые столбцы из списка или указали их в неправильном порядке, MySQL не присвоил бы значения правильно. CSV по своей сути является позиционно-ориентированным форматом. По умолчанию, когда спецификация FIELDS не указана, MySQL будет читать каждую строку CSV и будет ожидать, что каждое поле во всех строках будет сопоставлено со столбцом в целевой таблице (в порядке столбцов, который дает команда DESCRIBE или SHOW CREATE TABLE) . Изменив порядок столбцов в этой спецификации, мы можем заполнить таблицу из CSV-файла, поля которого расположены не на месте.
Строки с 8 по 15 — это вызовы наших функций для преобразования значений даты и времени. В предыдущей спецификации столбца мы определили, что поле 8 считывается в переменную @var_record_date, а поле 9 — в @var_last_update. Мы знаем, что поля 8 и 9 — это наши проблемные поля даты и времени. С заполненными переменными мы можем определить параметр SET, который позволяет изменять значения столбца целевой таблицы на основе полей, считанных из файла CSV. В этом очень простом примере вы можете умножить конкретное значение на два. В нашем случае мы используем две функции: сначала мы проверяем, что переменная не пуста (,, в CSV), оценивая количество символов, считанных из файла, а затем мы вызываем фактическое преобразование, если предыдущая проверка не возвращает результат. нуль. Если мы обнаружили, что длина равна нулю, мы устанавливаем значение NULL.
Наконец, когда команда выполнена, можно проверить результаты:
mysql> SELECT facility, occupied, last_update
-> FROM facilities
-> ORDER BY last_update DESC LIMIT 5;
+---------------------...+------------------------+---------------------+
| facility ...| occupied | last_update |
+---------------------...+------------------------+---------------------+
| Turn Basin/K7-1005 ...| 01/01/1963 12:00:00 AM | 2015-06-22 00:00:00 |
| RPSF Surge Building ...| 01/01/1984 12:00:00 AM | 2015-06-22 00:00:00 |
| Thermal Protection S...| 01/01/1988 12:00:00 AM | 2015-06-22 00:00:00 |
| Intermediate Bay/M7-...| 01/01/1995 12:00:00 AM | 2015-06-22 00:00:00 |
| Orbiter Processing F...| 01/01/1987 12:00:00 AM | 2015-06-22 00:00:00 |
+---------------------...+------------------------+---------------------+
5 rows in set (0.00 sec)
Помните, мы упоминали, что occupied останется как TEXT. Вы можете увидеть это здесь. Хотя его можно использовать для сортировки, никакие функции даты не будут работать со значениями в этом столбце, если они явно не приведены к DATETIME.
Это был сложный пример, но он показывает неожиданную сложность загрузки данных и мощь команды LOAD DATA INFILE.
Запись данных в файлы с разделителями-запятыми
Вы можете использовать оператор SELECT INTO OUTFILE, чтобы записать результат запроса в файл CSV, который можно открыть в электронной таблице или другой программе.
Давайте экспортируем список текущих менеджеров из нашей базы employees в файл CSV. Запрос, используемый для перечисления всех текущих менеджеров, показан здесь:
mysql> USE employees;
Database changed
mysql> SELECT emp_no, first_name, last_name, title, from_date
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager' AND to_date = '9999-01-01';
+--------+------------+------------+---------+------------+
| emp_no | first_name | last_name | title | from_date |
+--------+------------+------------+---------+------------+
| 110039 | Vishwani | Minakawa | Manager | 1991-10-01 |
| 110114 | Isamu | Legleitner | Manager | 1989-12-17 |
| 110228 | Karsten | Sigstam | Manager | 1992-03-21 |
| 110420 | Oscar | Ghazalie | Manager | 1996-08-30 |
| 110567 | Leon | DasSarma | Manager | 1992-04-25 |
| 110854 | Dung | Pesch | Manager | 1994-06-28 |
| 111133 | Hauke | Zhang | Manager | 1991-03-07 |
| 111534 | Hilary | Kambil | Manager | 1991-04-08 |
| 111939 | Yuchang | Weedman | Manager | 1996-01-03 |
+--------+------------+------------+---------+------------+
9 rows in set (0.13 sec)
Мы можем немного изменить этот запрос SELECT, чтобы записать эти данные в выходной файл в виде значений, разделенных запятыми. INTO OUTFILE подчиняется тем же правилам опции --secure-file-priv, что и LOAD DATA INFILE. Путь к файлу по умолчанию ограничен, и мы перечислили параметры по умолчанию в разделе «Загрузка данных из файлов с разделителями-запятыми»:
mysql> SELECT emp_no, first_name, last_name, title, from_date
-> FROM employees JOIN titles USING (emp_no)
-> WHERE title = 'Manager' AND to_date = '9999-01-01'
-> INTO OUTFILE '/var/lib/mysql-files/managers.csv'
-> FIELDS TERMINATED BY ',';
Query OK, 9 rows affected (0.14 sec)
Здесь мы сохранили результаты в файле manager.csv в каталоге /var/lib/mysql-files; сервер MySQL должен иметь возможность записи в указанный вами каталог, и он должен быть указан в системной переменной secure_file_priv (если она установлена). В системе Windows вместо этого укажите путь, например C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\managers.csv. Если вы опустите предложение FIELDS TERMINATED BY, сервер будет использовать табуляцию в качестве разделителя по умолчанию между значениями данных.
Вы можете просмотреть содержимое файла manager.csv в текстовом редакторе или импортировать его в программу для работы с электронными таблицами:
110039,Vishwani,Minakawa,Manager,1991-10-01
110114,Isamu,Legleitner,Manager,1989-12-17
110228,Karsten,Sigstam,Manager,1992-03-21
110420,Oscar,Ghazalie,Manager,1996-08-30
110567,Leon,DasSarma,Manager,1992-04-25
110854,Dung,Pesch,Manager,1994-06-28
111133,Hauke,Zhang,Manager,1991-03-07
111534,Hilary,Kambil,Manager,1991-04-08
111939,Yuchang,Weedman,Manager,1996-01-03
Когда наши поля данных содержат запятые или другой разделитель по нашему выбору, MySQL по умолчанию будет экранировать разделители внутри полей. Давайте переключимся на базу данных sakila и проверим это:
mysql> USE sakila;
Database changed
mysql> SELECT title, special_features FROM film LIMIT 10
-> INTO OUTFILE '/var/lib/mysql-files/film.csv'
-> FIELDS TERMINATED BY ',';
Query OK, 10 rows affected (0.00 sec)
Если вы сейчас посмотрите на данные в файле film.csv (опять же, не стесняйтесь использовать текстовый редактор, программу для работы с электронными таблицами или утилиту командной строки, например, head в Linux), вот что вы увидите:
ACADEMY DINOSAUR,Deleted Scenes\,Behind the Scenes
ACE GOLDFINGER,Trailers\,Deleted Scenes
ADAPTATION HOLES,Trailers\,Deleted Scenes
AFFAIR PREJUDICE,Commentaries\,Behind the Scenes
AFRICAN EGG,Deleted Scenes
AGENT TRUMAN,Deleted Scenes
AIRPLANE SIERRA,Trailers\,Deleted Scenes
AIRPORT POLLOCK,Trailers
ALABAMA DEVIL,Trailers\,Deleted Scenes
ALADDIN CALENDAR,Trailers\,Deleted Scenes
Обратите внимание, что в строках, где второе поле содержит запятую, она автоматически экранируется обратной косой чертой, чтобы отличить ее от разделителя. Некоторые программы для работы с электронными таблицами могут понимать это и удалять обратную косую черту при импорте файла, а некоторые нет. MySQL будет уважать экранирование и не будет рассматривать такие запятые как разделители. Обратите внимание, что если мы укажем FIELDS TERMINATED BY '^', все символы ^ в полях будут экранированы; это не относится к запятым.
Так как не все программы могут изящно обрабатывать escape-последовательности, мы можем попросить MySQL явно определить поля, используя опцию ENCLOSED:
mysql> SELECT title, special_features FROM film LIMIT 10
-> INTO OUTFILE '/var/lib/mysql-files/film_quoted.csv'
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"';
Query OK, 10 rows affected (0.00 sec)
Мы использовали эту опцию раньше при загрузке данных. Взгляните на результаты в файле film_quoted.csv:
"ACADEMY DINOSAUR","Deleted Scenes,Behind the Scenes"
"ACE GOLDFINGER","Trailers,Deleted Scenes"
"ADAPTATION HOLES","Trailers,Deleted Scenes"
"AFFAIR PREJUDICE","Commentaries,Behind the Scenes"
"AFRICAN EGG","Deleted Scenes"
"AGENT TRUMAN","Deleted Scenes"
"AIRPLANE SIERRA","Trailers,Deleted Scenes"
"AIRPORT POLLOCK","Trailers"
"ALABAMA DEVIL","Trailers,Deleted Scenes"
"ALADDIN CALENDAR","Trailers,Deleted Scenes"
Наши разделители — запятые — теперь не экранируются, что может лучше работать с современными программами для работы с электронными таблицами. Вы можете задаться вопросом, что произойдет, если в экспортируемых полях будут двойные кавычки: MySQL будет экранировать их вместо запятых, что опять же может вызвать проблемы. Выполняя экспорт данных, не забудьте убедиться, что полученный результат будет работать для ваших потребителей.
Создание таблиц с запросами
Вы можете создать таблицу или легко создать копию таблицы с помощью запроса. Это полезно, когда вы хотите создать новую базу данных, используя существующие данные — например, вы можете скопировать список стран — или когда вы хотите реорганизовать данные по какой-либо причине. Реорганизация данных распространена при создании отчетов, объединении данных из двух или более таблиц и изменении дизайна на лету. В этом коротком разделе показано, как это делается.
В MySQL вы можете легко продублировать структуру таблицы, используя вариант синтаксиса CREATE TABLE:
mysql> USE sakila;
Database changed
mysql> CREATE TABLE actor_2 LIKE actor;
Query OK, 0 rows affected (0.24 sec)
mysql> DESCRIBE actor_2;
+-------------+-------------------+------+-----+...
| Field | Type | Null | Key |...
+-------------+-------------------+------+-----+...
| actor_id | smallint unsigned | NO | PRI |...
| first_name | varchar(45) | NO | |...
| last_name | varchar(45) | NO | MUL |...
| last_update | timestamp | NO | |...
+-------------+-------------------+------+-----+...
...+-------------------+-----------------------------------------------+
...| Default | Extra |
...+-------------------+-----------------------------------------------+
...| NULL | auto_increment |
...| NULL | |
...| NULL | |
...| CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-------------------+-----------------------------------------------+
4 rows in set (0.01 sec)
mysql> SELECT * FROM actor_2;
Empty set (0.00 sec)
Синтаксис LIKE позволяет создать новую таблицу с точно такой же структурой, как и другая, включая ключи. Вы можете видеть, что он не копирует данные. Вы также можете использовать функции IF NOT EXISTS и TEMPORARY с этим синтаксисом.
Если вы хотите создать таблицу и скопировать некоторые данные, вы можете сделать это с помощью комбинации операторов CREATE TABLE и SELECT. Давайте удалим таблицу actor_2 и создадим ее заново, используя этот новый подход:
mysql> DROP TABLE actor_2;
Query OK, 0 rows affected (0.08 sec)
mysql> CREATE TABLE actor_2 AS SELECT * from actor;
Query OK, 200 rows affected (0.03 sec)
Records: 200 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM actor_2 LIMIT 5;
+----------+------------+--------------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+--------------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
| 3 | ED | CHASE | 2006-02-15 04:34:33 |
| 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 |
| 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33 |
+----------+------------+--------------+---------------------+
5 rows in set (0.01 sec)
Создается идентичная таблица, actor_2, и все данные копируются оператором SELECT. CREATE TABLE AS SELECT или CTAS — это обычное название для этого действия, но на самом деле не обязательно указывать часть AS, и мы опустим ее позже.
Это мощная техника. Вы можете создавать новые таблицы с новой структурой и использовать мощные запросы для их заполнения данными. Например, вот таблица отчета, которая содержит названия фильмов в нашей базе данных и их категории:
mysql> CREATE TABLE report (title VARCHAR(128), category VARCHAR(25))
-> SELECT title, name AS category FROM
-> film JOIN film_category USING (film_id)
-> JOIN category USING (category_id);
Query OK, 1000 rows affected (0.06 sec)
Records: 1000 Duplicates: 0 Warnings: 0
Вы можете видеть, что синтаксис немного отличается от предыдущего примера. В этом примере за новым именем таблицы, report, следует список имен и типов столбцов в круглых скобках; это необходимо, потому что мы не дублируем структуру существующей таблицы. Более того, мы фактически меняем название name на category. Затем следует оператор SELECT, вывод которого соответствует новым столбцам в новой таблице. Вы можете проверить содержимое новой таблицы, чтобы увидеть результат:
mysql> SELECT * FROM report LIMIT 5;
+---------------------+----------+
| title | category |
+---------------------+----------+
| AMADEUS HOLY | Action |
| AMERICAN CIRCUS | Action |
| ANTITRUST TOMATOES | Action |
| ARK RIDGEMONT | Action |
| BAREFOOT MANCHURIAN | Action |
+---------------------+----------+
5 rows in set (0.00 sec)
Таким образом, в этом примере значения title и name из инструкции SELECT используются для заполнения новых столбцов title и category в таблице report.
Создание таблиц с помощью запроса имеет важное предостережение, с которым вам нужно быть осторожным: оно не копирует индексы (или внешние ключи, если вы их используете). Это возможность, она дает вам большую гибкость, но это может быть ловушкой, если вы забудете о ее особенности. Взгляните на наш пример actor_2:
mysql> DESCRIBE actor_2;
+-------------+-------------------+------+-----+...
| Field | Type | Null | Key |...
+-------------+-------------------+------+-----+...
| actor_id | smallint unsigned | NO | |...
| first_name | varchar(45) | NO | |...
| last_name | varchar(45) | NO | |...
| last_update | timestamp | NO | |...
+-------------+-------------------+------+-----+...
...+-------------------+-----------------------------------------------+
...| Default | Extra |
...+-------------------+-----------------------------------------------+
...| 0 | |
...| NULL | |
...| NULL | |
...| CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-------------------+-----------------------------------------------+
4 rows in set (0.00 sec)
mysql> SHOW CREATE TABLE actor_2\G
*************************** 1. row ***************************
Table: actor_2
Create Table: CREATE TABLE `actor_2` (
`actor_id` smallint unsigned NOT NULL DEFAULT '0',
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL
DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
Вы можете видеть, что первичного ключа нет; ключ idx_actor_last_name также отсутствует, как и свойство AUTO_INCREMENT столбца actor_id.
Чтобы скопировать индексы в новую таблицу, вы можете сделать как минимум три вещи. Первый — использовать оператор LIKE для создания пустой таблицы с индексами, как описано ранее, а затем скопировать данные с помощью оператора INSERT с оператором SELECT, как описано в разделе «Вставка данных с помощью запросов».
Второе, что вы можете сделать, это использовать CREATE TABLE с оператором SELECT, а затем добавить индексы с помощью ALTER TABLE, как описано в главе 4.
Третий вариант — использовать ключевое слово UNIQUE (или PRIMARY KEY или KEY) в сочетании с CREATE TABLE и SELECT для добавления индекса первичного ключа. Вот пример такого подхода:
mysql> DROP TABLE actor_2;
Query OK, 0 rows affected (0.04 sec)
mysql> CREATE TABLE actor_2 (UNIQUE(actor_id))
-> AS SELECT * from actor;
Query OK, 200 rows affected (0.05 sec)
Records: 200 Duplicates: 0 Warnings: 0
mysql> DESCRIBE actor_2;
+-------------+-------------------+------+-----+...
| Field | Type | Null | Key |...
+-------------+-------------------+------+-----+...
| actor_id | smallint unsigned | NO | PRI |...
| first_name | varchar(45) | NO | |...
| last_name | varchar(45) | NO | |...
| last_update | timestamp | NO | |...
+-------------+-------------------+------+-----+...
...+-------------------+-----------------------------------------------+
...| Default | Extra |
...+-------------------+-----------------------------------------------+
...| 0 | |
...| NULL | |
...| NULL | |
...| CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |
...+-------------------+-----------------------------------------------+
4 rows in set (0.01 sec)
Ключевое слово UNIQUE применяется к столбцу actor_id, что делает его первичным ключом во вновь созданной таблице. Ключевые слова UNIQUE и PRIMARY KEY можно поменять местами.
Вы можете использовать различные модификаторы при создании таблиц с использованием этих методов. Например, вот таблица, созданная со значениями по умолчанию и другими настройками:
mysql> CREATE TABLE actor_3 (
-> actor_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
-> first_name VARCHAR(45) NOT NULL,
-> last_name VARCHAR(45) NOT NULL,
-> last_update TIMESTAMP NOT NULL
-> DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
-> PRIMARY KEY (actor_id),
-> KEY idx_actor_last_name (last_name)
-> ) SELECT * FROM actor;
Query OK, 200 rows affected (0.05 sec)
Records: 200 Duplicates: 0 Warnings: 0
Здесь мы установили NOT NULL для новых столбцов, использовали функцию AUTO_INCREMENT для actor_id и создали два ключа. Все, что вы можете сделать в обычном операторе CREATE TABLE, можно сделать и в этом варианте; просто не забудьте добавить эти индексы явно!
Выполнение обновлений и удалений с несколькими таблицами
В главе 3 мы показали вам, как обновлять и удалять данные. В приведенных примерах каждое обновление и удаление затрагивало одну таблицу и использовало свойства этой таблицы, чтобы решить, что изменить. В этом разделе показаны более сложные обновления и удаления. Как вы увидите, вы можете удалять или обновлять строки более чем из одной таблицы в одном операторе, и вы можете использовать те или иные таблицы, чтобы решить, какие строки следует изменить.
Удаление
Представьте, что вы очищаете базу данных, возможно, из-за нехватки места. Одним из способов решения этой проблемы является удаление некоторых данных. Например, в базе данных sakila может иметь смысл удалить фильмы, которые есть в нашем инвентаре, но никогда не брались напрокат. К сожалению, это означает, что вам нужно удалить данные из таблицы inventory, используя информацию из таблицы rental.
С методами, которые мы описали до сих пор в книге, невозможно сделать это без создания таблицы, объединяющей две таблицы (возможно, с помощью INSERT с SELECT), удаления ненужных строк и копирования данных обратно в источник. В этом разделе показано, как можно более элегантно выполнить эту процедуру и другие более сложные типы удаления.
Рассмотрим запрос, который вам нужно написать, чтобы найти в таблице inventory фильмы, которые никогда не брались напрокат. Один из способов сделать это — использовать вложенный запрос, используя методы, которые мы показали вам в главе 5, с предложением NOT EXISTS. Вот запрос:
mysql> SELECT * FROM inventory WHERE NOT EXISTS
-> (SELECT 1 FROM rental WHERE
-> rental.inventory_id = inventory.inventory_id);
+--------------+---------+----------+---------------------+
| inventory_id | film_id | store_id | last_update |
+--------------+---------+----------+---------------------+
| 5 | 1 | 2 | 2006-02-15 05:09:17 |
+--------------+---------+----------+---------------------+
1 row in set (0.01 sec)
Вы, вероятно, видите, как это работает, но давайте кратко обсудим это, прежде чем двигаться дальше. Вы можете видеть, что этот запрос использует коррелированный подзапрос, где текущая строка, обрабатываемая во внешнем запросе, ссылается на подзапрос; вы можете сказать это, потому что имеется ссылка на столбец inventory_id из inventory, но таблица inventory не указана в предложении FROM подзапроса. Подзапрос выдает выходные данные, когда в таблице rental есть строка, совпадающая с текущей строкой во внешнем запросе (и поэтому фильм из этой записи брался напрокат). Однако, поскольку в запросе используется NOT EXISTS, внешний запрос не выдает вывода в этом случае, и поэтому общий результат состоит в том, что выводятся строки для записей фильмов, которые не были взяты напрокат.
Теперь давайте возьмем наш запрос и превратим его в инструкцию DELETE. Вот:
mysql> DELETE FROM inventory WHERE NOT EXISTS
-> (SELECT 1 FROM rental WHERE
-> rental.inventory_id = inventory.inventory_id);
Query OK, 1 row affected (0.04 sec)
Вы можете видеть, что подзапрос остается прежним, но внешний запрос SELECT заменяется оператором DELETE. Здесь мы следуем стандартному синтаксису DELETE: за ключевым словом DELETE следует FROM и спецификация таблицы или таблиц, из которых должны быть удалены строки, затем предложение WHERE (и любые другие предложения запроса, такие как GROUP BY или HAVING ). В этом запросе строки удаляются из таблицы инвентаризации, но в предложении WHERE подзапрос указывается в операторе NOT EXISTS.
Хотя этот оператор действительно удаляет строки из одной таблицы на основе данных из другой таблицы, в основном это разновидность обычного оператора DELETE. Чтобы преобразовать этот конкретный оператор в многотабличный DELETE, мы должны переключиться с вложенного подзапроса на LEFT JOIN, например:
DELETE inventory FROM inventory LEFT JOIN rental
USING (inventory_id) WHERE rental.inventory_id IS NULL;
Обратите внимание, как меняется синтаксис, чтобы включить конкретную таблицу (или таблицы), в которой мы хотим удалить найденные строки. Эти таблицы указываются после DELETE, но перед спецификацией FROM и запроса. Однако есть и другой способ написать этот запрос, и мы предпочитаем именно его:
DELETE FROM inventory USING inventory
LEFT JOIN rental USING (inventory_id)
WHERE rental.inventory_id IS NULL;
Этот запрос представляет собой смесь двух предыдущих. Мы не указываем цели удаления между DELETE и FROM, а записываем их так, как если бы это было обычное удаление. Вместо этого мы используем специальное предложение USING, которое указывает, что последует фильтрующий запрос (объединение или что-то другое). На наш взгляд, это немного понятнее, чем предыдущий пример DELETE table FROM table. Одним из недостатков использования ключевого слова USING является то, что его можно перепутать с ключевым словом USING оператора JOIN. Однако с некоторой практикой вы никогда не совершите эту ошибку.
Теперь, когда мы знаем оба варианта многотабличного синтаксиса, мы можем построить запрос, который на самом деле требует удаления нескольких таблиц. Одним из примеров ситуации, в которой может потребоваться такой оператор, является удаление записей из таблиц, участвующих в отношениях внешнего ключа. В базе данных sakila есть записи для фильмов в таблице film, которые не имеют связанных записей в таблице inventory. То есть есть фильмы, о которых есть информация, но которые нельзя взять напрокат. Предположим, что в рамках операции по очистке базы данных нам поручили удалить такие оборванные данные. Сначала это кажется достаточно простым:
mysql> DELETE FROM film WHERE NOT EXISTS
-> (SELECT 1 FROM inventory WHERE
-> film.film_id = inventory.film_id);
ERROR 1451 (23000): Cannot delete or update a parent row:
a foreign key constraint fails (
`sakila`.`film_actor`, CONSTRAINT `fk_film_actor_film`
FOREIGN KEY (`film_id`) REFERENCES `film` (`film_id`)
ON DELETE RESTRICT ON UPDATE CASCADE)
Увы, ограничение целостности препятствует этому удалению. Нам придется снимать не только фильмы, но и отношения между этими фильмами и актерами. Это может привести к созданию актеров-сирот, которые затем могут быть удалены. Мы могли бы попробовать удалить фильмы и ссылки на актеров за один раз, например:
DELETE FROM film_actor, film USING
film JOIN film_actor USING (film_id)
LEFT JOIN inventory USING (film_id)
WHERE inventory.film_id IS NULL;
К сожалению, несмотря на то, что таблица film_actor указана перед таблицей film, удаление из film все равно не удается. Невозможно указать оптимизатору обрабатывать таблицы в определенном порядке. Даже если бы этот пример выполнился успешно, полагаться на такое поведение не рекомендуется, так как оптимизатор может впоследствии непредсказуемо изменить порядок таблиц, что приведет к сбоям. Этот пример подчеркивает разницу между MySQL и стандартом SQL: стандарт указывает, что внешние ключи проверяются при фиксации транзакции, тогда как MySQL проверяет их немедленно, предотвращая успешное выполнение этого оператора. Даже если бы мы смогли решить эту проблему, фильмы также связаны с категориями, так что об этом тоже придется позаботиться.
MySQL допускает несколько выходов из этой ситуации. Первый заключается в выполнении серии операторов DELETE в рамках одной транзакции (подробнее о транзакциях мы говорили в главе 6):
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> DELETE FROM film_actor USING
-> film JOIN film_actor USING (film_id)
-> LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 216 rows affected (0.01 sec)
mysql> DELETE FROM film_category USING
-> film JOIN film_category USING (film_id)
-> LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 42 rows affected (0.00 sec)
mysql> DELETE FROM film USING
-> film LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 42 rows affected (0.00 sec)
mysql> ROLLBACK;
Query OK, 0 rows affected (0.02 sec)
Вы можете видеть, что мы выполнили ROLLBACK вместо COMMIT, чтобы сохранить строки. В действительности вы, конечно, использовали бы COMMIT для «сохранения» результатов вашей операции.
Второй вариант опасен. Можно приостановить ограничения внешнего ключа, временно установив для системной переменной foreign_key_checks значение 0 на уровне сеанса. Мы не рекомендуем эту практику, но это единственный способ удалить все три таблицы одновременно:
mysql> SET foreign_key_checks=0;
Query OK, 0 rows affected (0.00 sec)
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> DELETE FROM film, film_actor, film_category
-> USING film JOIN film_actor USING (film_id)
-> JOIN film_category USING (film_id)
-> LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 300 rows affected (0.03 sec)
mysql> ROLLBACK;
Query OK, 0 rows affected (0.00 sec)
mysql> SET foreign_key_checks=1;
Query OK, 0 rows affected (0.00 sec)
Хотя мы не рекомендуем отключать проверки внешнего ключа, это позволяет нам продемонстрировать силу многотабличных удалений. Здесь с помощью одного запроса можно было добиться того, что в предыдущем примере требовало трех запросов.
Разберем этот запрос. Таблицы, из которых будут удалены строки (при совпадении), — это film, film_actor и film_category. Мы указали их между терминами DELETE FROM и USING для ясности. USING запускает наш запрос, фильтрующую часть оператора DELETE. В этом примере мы создали объединение четырех таблиц. Мы соединили film, film_actor и film_category с помощью INNER JOIN, так как нам нужны только совпадающие строки. Для этих объединений мы выполнили LEFT JOIN таблицы inventory. В этом контексте использование левого соединения чрезвычайно важно, потому что на самом деле нас интересуют только строки, в которых в inventory не будет записей. Мы выражаем это с помощью WHERE inventory.film_id IS NULL. Результатом этого запроса является то, что мы получаем все фильмы, которых нет в inventory, а затем все отношения актеров и актеров для этих фильмов, а также все отношения категорий для фильмов.
Можно ли сделать этот запрос безопасным для использования с внешними ключами? К сожалению, не без разбора, но мы можем сделать лучше, чем запускать три запроса:
mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)
mysql> DELETE FROM film_actor, film_category USING
-> film JOIN film_actor USING (film_id)
-> JOIN film_category USING (film_id)
-> LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 258 rows affected (0.02 sec)
mysql> DELETE FROM film USING
-> film LEFT JOIN inventory USING (film_id)
-> WHERE inventory.film_id IS NULL;
Query OK, 42 rows affected (0.01 sec)
mysql> ROLLBACK;
Query OK, 0 rows affected (0.01 sec)
Здесь мы объединили удаление из таблиц film_actor и film_category в один оператор DELETE, что позволяет выполнять удаление из film без ошибок. Отличие от предыдущего примера в том, что мы с DELETE FROM делаем две таблицы вместо трех.
Давайте поговорим о количестве затронутых строк. В первом примере мы удалили 42 строки из film, 42 строки из film_category и 216 строк из таблицы film_actor. Во втором примере наш единственный запрос DELETE удалил 300 строк. В последнем примере мы удалили 258 строк из таблиц film_category и film_actor и 42 строки из таблицы film. Вы, наверное, уже догадались, что для удаления нескольких таблиц MySQL выведет общее количество удаленных строк без разбивки на отдельные таблицы. Это затрудняет точное отслеживание того, сколько строк было затронуто в каждой таблице.
Кроме того, при удалении нескольких таблиц нельзя использовать предложения ORDER BY или LIMIT.
Обновления
Теперь мы придумаем пример, используя базу данных sakila, чтобы проиллюстрировать обновление нескольких таблиц. Мы решили изменить рейтинг всех фильмов ужасов на R, независимо от первоначального рейтинга. Для начала выведем фильмы ужасов и их рейтинги:
mysql> SELECT name category, title, rating
-> FROM film JOIN film_category USING (film_id)
-> JOIN category USING (category_id)
-> WHERE name = 'Horror';
+----------+-----------------------------+--------+
| category | title | rating |
+----------+-----------------------------+--------+
| Horror | ACE GOLDFINGER | G |
| Horror | AFFAIR PREJUDICE | G |
| Horror | AIRPORT POLLOCK | R |
| Horror | ALABAMA DEVIL | PG-13 |
| ... |
| Horror | ZHIVAGO CORE | NC-17 |
+----------+-----------------------------+--------+
56 rows in set (0.00 sec)
mysql> SELECT COUNT(title)
-> FROM film JOIN film_category USING (film_id)
-> JOIN category USING (category_id)
-> WHERE name = 'Horror' AND rating <> 'R';
+--------------+
| COUNT(title) |
+--------------+
| 42 |
+--------------+
1 row in set (0.00 sec)
Не знаем, как вы, а мы бы хотели посмотреть фильм ужасов с рейтингом G! Теперь давайте поместим этот запрос в инструкцию UPDATE:
mysql> UPDATE film JOIN film_category USING (film_id)
-> JOIN category USING (category_id)
-> SET rating = 'R' WHERE category.name = 'Horror';
Query OK, 42 rows affected (0.01 sec)
Rows matched: 56 Changed: 42 Warnings: 0
Давайте посмотрим на синтаксис. Обновление нескольких таблиц похоже на запрос SELECT. За оператором UPDATE следует список таблиц, который включает любые предложения соединения, которые вам нужны или предпочтительны; в этом примере мы использовали JOIN (помните, что это INNER JOIN) для объединения таблиц film и film_category. За ним следует ключевое слово SET с присвоением отдельным столбцам. Здесь вы можете видеть, что изменен только один столбец (чтобы изменить рейтинг на R), поэтому столбцы во всех других таблицах, кроме film, не изменены. Следующее WHERE является необязательным, но необходимо в этом примере, чтобы касаться только строк с названием категории Horror.
Обратите внимание, как MySQL сообщает, что 56 строк были сопоставлены, но только 42 обновлены. Если вы посмотрите на результаты предыдущих запросов SELECT, вы увидите, что они показывают количество фильмов в категории Horror (56) и фильмов в этой категории с рейтингом, отличным от R (42). Были обновлены только 42 строки, потому что другие фильмы уже имели такой рейтинг.
Как и в случае удаления нескольких таблиц, существуют некоторые ограничения на обновления нескольких таблиц:
-
Вы не можете использовать
ORDER BY. -
Вы не можете использовать
LIMIT. -
Вы не можете обновить таблицу, которая считывается во вложенном подзапросе.
В остальном многотабличные обновления почти такие же, как и однотабличные.
Замена данных
Иногда вам может понадобиться перезаписать данные. Вы можете сделать это двумя способами, используя методы, которые мы показали ранее:
-
Удалите существующую строку, используя ее первичный ключ, а затем вставьте замену с тем же первичным ключом.
-
Обновите строку, используя ее первичный ключ, заменив некоторые или все значения (кроме первичного ключа).
Оператор REPLACE предоставляет третий удобный способ изменения данных. В этом разделе объясняется, как это работает.
Оператор REPLACE похож на INSERT, но с одним отличием. Вы не можете вставить (INSERT) новую строку, если в таблице уже есть строка с тем же первичным ключом. Вы можете обойти эту проблему с помощью запроса REPLACE, который сначала удаляет любую существующую строку с тем же первичным ключом, а затем вставляет новую.
Давайте попробуем пример, где мы заменим строку для актрисы PENELOPE GUINESS в базе данных sakila:
mysql> REPLACE INTO actor VALUES (1, 'Penelope', 'Guiness', NOW());
ERROR 1451 (23000): Cannot delete or update a parent row:
a foreign key constraint fails (`sakila`.`film_actor`,
CONSTRAINT `fk_film_actor_actor` FOREIGN KEY (`actor_id`)
REFERENCES `actor` (`actor_id`) ON DELETE RESTRICT ON UPDATE CASCADE)
К сожалению, как вы уже догадались после прочтения предыдущего абзаца, REPLACE на самом деле должен выполнить DELETE. Если ваша база данных сильно ограничена ссылочно, как база данных sakila, REPLACE часто не будет работать. Давайте не будем бороться с базой данных, а вместо этого воспользуемся таблицей actor_2, которую мы создали в разделе «Создание таблиц с запросами»:
mysql> REPLACE actor_2 VALUES (1, 'Penelope', 'Guiness', NOW());
Query OK, 2 rows affected (0.00 sec)
Вы можете видеть, что MySQL сообщает, что были затронуты две строки: сначала была удалена старая строка, а затем была вставлена новая строка. Вы можете видеть, что сделанное нами изменение было незначительным — мы просто изменили регистр имени — и поэтому его легко можно было выполнить с помощью UPDATE. Поскольку таблицы в базе данных sakila относительно малы, сложно построить пример, в котором REPLACE выглядит проще, чем UPDATE.
Вы можете использовать различные синтаксисы INSERT с REPLACE, включая использование запросов SELECT. Вот некоторые примеры:
mysql> REPLACE INTO actor_2 VALUES (1, 'Penelope', 'Guiness', NOW());
Query OK, 2 rows affected (0.00 sec)
mysql> REPLACE INTO actor_2 (actor_id, first_name, last_name)
-> VALUES (1, 'Penelope', 'Guiness');
Query OK, 2 rows affected (0.00 sec)
mysql> REPLACE actor_2 (actor_id, first_name, last_name)
-> VALUES (1, 'Penelope', 'Guiness');
Query OK, 2 rows affected (0.00 sec)
mysql> REPLACE actor_2 SET actor_id = 1,
-> first_name = 'Penelope', last_name = 'Guiness';
Query OK, 2 rows affected (0.00 sec)
Первый вариант почти идентичен нашему предыдущему примеру, за исключением того, что он включает необязательное ключевое слово INTO (которое, возможно, улучшает читабельность инструкции). Во втором варианте явно перечислены имена столбцов, в которые должны быть вставлены совпадающие значения. Третий вариант аналогичен второму, но без необязательного ключевого слова INTO. В последнем варианте используется синтаксис SET; вы можете добавить в этот вариант необязательное ключевое слово INTO, если хотите. Обратите внимание, что если вы не укажете значение для столбца, для него будет установлено значение по умолчанию, как и для INSERT.
Вы также можете выполнять массовую замену в таблице, удаляя и вставляя более одной строки. Вот пример:
mysql> REPLACE actor_2 (actor_id, first_name, last_name)
-> VALUES (2, 'Nick', 'Wahlberg'),
-> (3, 'Ed', 'Chase');
Query OK, 4 rows affected (0.00 sec)
Records: 2 Duplicates: 2 Warnings: 0
Обратите внимание, что затрагиваются четыре строки: два удаления и две вставки. Вы также можете увидеть, что были найдены два дубликата, что означает, что замена существующих строк прошла успешно. Напротив, если в операторе REPLACE нет соответствующей строки, он действует так же, как INSERT:
mysql> REPLACE actor_2 (actor_id, first_name, last_name)
-> VALUES (1000, 'William', 'Dyer');
Query OK, 1 row affected (0.00 sec)
Вы можете сказать, что произошла только вставка, так как была затронута только одна строка.
Замена также работает с оператором SELECT. Вспомните таблицу recommend из раздела «Вставка данных с помощью запросов» в начале этой главы. Предположим, вы добавили в нее 10 фильмов, но вам не нравится выбор седьмого фильма в списке. Вот как вы можете заменить его случайным выбором другого фильма:
mysql> REPLACE INTO recommend SELECT film_id, language_id,
-> release_year, title, length, 7 FROM film
-> ORDER BY RAND() LIMIT 1;
Query OK, 2 rows affected (0.00 sec)
Records: 1 Duplicates: 1 Warnings: 0
Опять же, синтаксис такой же, как и у INSERT, но попытка удаления выполняется (и успешно!) перед вставкой. Обратите внимание, что мы сохраняем значение sequence_id равным 7.
Если у таблицы нет первичного ключа или другого уникального ключа, замена не имеет смысла. Это связано с тем, что невозможно однозначно идентифицировать совпадающую строку, чтобы удалить ее. Когда вы используете REPLACE для такой таблицы, ее поведение идентично INSERT. Кроме того, как и в случае с INSERT, вы не можете заменять строки в таблице, которая используется в подзапросе. Наконец, обратите внимание на разницу между INSERT IGNORE и REPLACE: первый сохраняет существующие данные с повторяющимся ключом и не вставляет новую строку, а второй удаляет существующую строку и заменяет ее новой.
При указании списка столбцов для REPLACE вы должны указать каждый столбец, не имеющий значения по умолчанию. В наших примерах нам нужно было указать actor_id, first_name и last_name, но мы пропустили столбец last_update, который имеет значение по умолчанию CURRENT_TIMESTAMP.
MySQL предоставляет еще одно нестандартное расширение SQL: INSERT ... ON DUPLICATE KEY UPDATE. Оно похоже на REPLACE, но вместо DELETE, за которым следует INSERT, оно выполняет UPDATE всякий раз, когда обнаруживается повторяющийся ключ. В начале этого раздела у нас возникла проблема с заменой строки в таблице actor. MySQL отказался выполнять REPLACE, потому что удаление строки из таблицы actor нарушило бы ограничение внешнего ключа. Однако легко добиться желаемого результата с помощью следующего выражения:
mysql> INSERT INTO actor_3 (actor_id, first_name, last_name)
-> VALUES (1, 'Penelope', 'Guiness')
-> ON DUPLICATE KEY UPDATE first_name = 'Penelope', last_name = 'Guiness';
Query OK, 2 rows affected (0.00 sec)
Обратите внимание, что мы используем таблицу actor_3, созданную в разделе «Создание таблиц с помощью запросов», поскольку она имеет все те же ограничения, что и исходная таблица actor. Оператор, который мы только что показали, семантически очень похож на REPLACE, но имеет несколько ключевых отличий. Если вы не указываете значение для поля в команде REPLACE, это поле должно иметь значение DEFAULT, и будет установлено это значение по умолчанию. Это естественно следует из того факта, что вставляется совершенно новая строка. В случае INSERT... ON DUPLICATE KEY UPDATE мы обновляем существующую строку, поэтому нет необходимости перечислять все столбцы. Мы можем сделать это, если захотим:
mysql> INSERT INTO actor_3 VALUES (1, 'Penelope', 'Guiness', NOW())
-> ON DUPLICATE KEY UPDATE
-> actor_id = 1, first_name = 'Penelope',
-> last_name = 'Guiness', last_update = NOW();
Query OK, 2 rows affected (0.01 sec)
Чтобы свести к минимуму объем ввода, необходимого для этой команды, и разрешить вставку нескольких строк, мы можем ссылаться на новые значения полей в предложении UPDATE. Вот пример с несколькими строками, одна из которых новая:
mysql> INSERT INTO actor_3 (actor_id, first_name, last_name) VALUES
-> (1, 'Penelope', 'Guiness'), (2, 'Nick', 'Wahlberg'),
-> (3, 'Ed', 'Chase'), (1001, 'William', 'Dyer')
-> ON DUPLICATE KEY UPDATE first_name = VALUES(first_name),
-> last_name = VALUES(last_name);
Query OK, 5 rows affected (0.01 sec)
Records: 4 Duplicates: 2
Рассмотрим этот запрос более подробно. Мы вставляем четыре строки в таблицу actor_3 и, используя ON DUPLICATE KEY UPDATE, сообщаем MySQL, что необходимо выполнить обновление для всех найденных повторяющихся строк. Однако, в отличие от нашего предыдущего примера, на этот раз мы не устанавливаем обновленные значения столбца явно. Вместо этого мы используем специальную функцию VALUES() для получения значения каждого столбца в строках, которые мы передали в INSERT. Например, для второй строки 2, Nick, Walhberg, VALUES(first_name) вернет Nick. Обратите внимание, что MySQL сообщает, что мы обновили нечетное количество строк: пять. Всякий раз, когда вставляется новая строка, количество затрагиваемых строк увеличивается на единицу. Всякий раз, когда старая строка обновляется, количество затронутых строк увеличивается на два. Поскольку мы уже обновили запись для Penelope, выполнив предыдущий запрос, наша новая вставка не добавляет ничего нового, и MySQL также пропустит обновление. У нас осталось два обновления для повторяющихся строк и вставка совершенно новой строки или всего затронуто пять строк.
Оператор EXPLAIN
Иногда вы обнаружите, что MySQL не выполняет запросы так быстро, как вы ожидаете. Например, вы часто будете замечать, что вложенный запрос выполняется медленно. Вы также можете обнаружить — или, по крайней мере, заподозрить, — что MySQL не делает то, на что вы надеялись, потому что вы знаете, что индекс существует, но запрос по-прежнему кажется медленным. Вы можете диагностировать и решать проблемы оптимизации запросов, используя оператор EXPLAIN.
Анализ планов запросов, понимание решений оптимизатора и настройка производительности запросов — сложные темы и больше искусство, чем наука: нет единого способа сделать это. Мы добавляем этот раздел, чтобы вы знали, что эта возможность существует, но мы не будем слишком углубляться в эту тему.
Оператор EXPLAIN поможет вам узнать о SELECT или любом другом запросе. В частности, он сообщает вам, как MySQL будет выполнять работу с точки зрения индексов, ключей и шагов, которые он предпримет, если вы попросите его разрешить запрос. EXPLAIN на самом деле не выполняет запрос (если вы не попросите об этом) и, как правило, не требует много времени для выполнения.
Давайте попробуем простой пример, иллюстрирующий идею:
mysql> EXPLAIN SELECT * FROM actor\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
Выражение дает вам много информации. Оно говорит вам, что:
-
idравен 1, что означает, что эта строка в выводе относится к первому (и единственному!) операторуSELECTв этом запросе. Если мы используем подзапрос, каждый операторSELECTбудет иметь другой идентификатор в выводеEXPLAIN(хотя некоторые подзапросы не приведут к сообщению нескольких идентификаторов, поскольку MySQL может переписать запрос). Позже мы покажем пример с подзапросом и другими значениями идентификатора. -
select_typeявляетсяSIMPLE, что означает, что он не используетUNIONили подзапросы. -
table, на которую ссылается эта строка, — этоactor. -
Столбец
partitionsпуст, поскольку таблицы не разбиты на разделы. -
Тип объединения —
ALL, что означает, что все строки в таблице обрабатываются этим операторомSELECT. Часто это плохо, но не в этом случае; мы объясним, почему позже. -
possible_keys, которые можно использовать, перечислены. В этом случае никакой индекс не поможет найти все строки в таблице, поэтому сообщаетсяNULL. -
Перечислен фактически используемый
key, взятый из спискаpossible_keys. В этом случае, поскольку ключ недоступен, он не используется. -
Указывается
key_len(длина ключа) ключа, который MySQL планирует использовать. Опять же, отсутствие ключа означает, что сообщаетсяNULL key_len. -
Перечислены
ref(ссылочные) столбцы или константы, которые используются с ключом. Опять же, в этом примере их нет. -
Перечислены
rows, которые, по мнению MySQL, необходимо обработать для получения ответа. -
Столбец
filteredсообщает нам процент строк из таблицы, которые будут возвращены на этом этапе: 100 означает, что будут возвращены все строки. Это ожидаемо, так как мы запрашиваем все строки. -
Любая
Extraинформация о разрешении запроса указана. Здесь jyf jncencndetn.
Таким образом, вывод EXPLAIN SELECT * FROM actor сообщает вам, что будут обработаны все строки из таблицы actor (их 200), и никакие индексы не будут использоваться для разрешения запроса. Это имеет смысл и, вероятно, произойдет именно то, что вы ожидали.
Обратите внимание, что каждый оператор EXPLAIN выдает предупреждение. Каждый запрос, который мы отправляем в MySQL, переписывается перед выполнением, и предупреждающее сообщение будет содержать переписанный запрос. Например, * может быть расширен до явного списка столбцов, или подзапрос может быть неявно оптимизирован в JOIN. Вот пример:
mysql> EXPLAIN SELECT * FROM actor WHERE actor_id IN
-> (SELECT actor_id FROM film_actor
-> WHERE film_id = 11);
+----+-------------+------------+------------+--------+...
| id | select_type | table | partitions | type |...
+----+-------------+------------+------------+--------+...
| 1 | SIMPLE | film_actor | NULL | ref |...
| 1 | SIMPLE | actor | NULL | eq_ref |...
+----+-------------+------------+------------+--------+...
...+------------------------+----------------+---------+...
...| possible_keys | key | key_len |...
...+------------------------+----------------+---------+...
...| PRIMARY,idx_fk_film_id | idx_fk_film_id | 2 |...
...| PRIMARY | PRIMARY | 2 |...
...+------------------------+----------------+---------+...
...+----------------------------+------+----------+-------------+
...| ref | rows | filtered | Extra |
...+----------------------------+------+----------+-------------+
...| const | 4 | 100.00 | Using index |
...| sakila.film_actor.actor_id | 1 | 100.00 | NULL |
...+----------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select
`sakila`.`actor`.`actor_id` AS `actor_id`,
`sakila`.`actor`.`first_name` AS `first_name`,
`sakila`.`actor`.`last_name` AS `last_name`,
`sakila`.`actor`.`last_update` AS `last_update`
from `sakila`.`film_actor` join `sakila`.`actor` where
((`sakila`.`actor`.`actor_id` = `sakila`.`film_actor`.`actor_id`)
and (`sakila`.`film_actor`.`film_id` = 11))
1 row in set (0.00 sec)
Мы упомянули, что покажем пример с разными значениями id и подзапросом. Вот запрос:
mysql> EXPLAIN SELECT * FROM actor WHERE actor_id IN
-> (SELECT actor_id FROM film_actor JOIN
-> film USING (film_id)
-> WHERE title = 'ZHIVAGO CORE');
+----+--------------+-------------+------------+------+...
| id | select_type | table | partitions | type |...
+----+--------------+-------------+------------+------+...
| 1 | SIMPLE | <subquery2> | NULL | ALL |...
| 1 | SIMPLE | actor | NULL | ALL |...
| 2 | MATERIALIZED | film | NULL | ref |...
| 2 | MATERIALIZED | film_actor | NULL | ref |...
+----+--------------+-------------+------------+------+...
...+------------------------+----------------+---------+---------------------+...
...| possible_keys | key | key_len | ref |...
...+------------------------+----------------+---------+---------------------+...
...| NULL | NULL | NULL | NULL |...
...| PRIMARY | NULL | NULL | NULL |...
...| PRIMARY,idx_title | idx_title | 514 | const |...
...| PRIMARY,idx_fk_film_id | idx_fk_film_id | 2 | sakila.film.film_id |...
...+------------------------+----------------+---------+---------------------+...
...+------+----------+--------------------------------------------+
...| rows | filtered | Extra |
...+------+----------+--------------------------------------------+
...| NULL | 100.00 | NULL |
...| 200 | 0.50 | Using where; Using join buffer (hash join) |
...| 1 | 100.00 | Using index |
...| 5 | 100.00 | Using index |
...+------+----------+--------------------------------------------+
4 rows in set, 1 warning (0.01 sec)
В этом примере вы можете видеть, что идентификатор 1 используется для таблиц actor и <subquery2>, а id 2 используется для film и film_actor. Но что такое <subquery2>? Это имя виртуальной таблицы, которое используется здесь, потому что оптимизатор материализовал результаты подзапроса или, другими словами, сохранил их во временной таблице в памяти. Вы можете видеть, что запрос с id 2 имеет тип (select_type) MATERIALIZED. Внешний запрос (id 1) будет искать результаты внутреннего запроса (id 2) из этой временной таблицы. Это лишь одна из многих оптимизаций, которые MySQL может выполнять при выполнении сложных запросов.
Далее мы дадим оператору EXPLAIN некоторую работу. Давайте попросим его объяснить INNER JOIN между actor, film_actor, film, film_category и category:
mysql> EXPLAIN SELECT first_name, last_name FROM actor
-> JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> JOIN film_category USING (film_id)
-> JOIN category USING (category_id)
-> WHERE category.name = 'Horror';
+----+-------------+---------------+------------+--------+...
| id | select_type | table | partitions | type |...
+----+-------------+---------------+------------+--------+...
| 1 | SIMPLE | category | NULL | ALL |...
| 1 | SIMPLE | film_category | NULL | ref |...
| 1 | SIMPLE | film | NULL | eq_ref |...
| 1 | SIMPLE | film_actor | NULL | ref |...
| 1 | SIMPLE | actor | NULL | eq_ref |...
+----+-------------+---------------+------------+--------+...
...+-----------------------------------+---------------------------+---------+...
...| possible_keys | key | key_len |...
...+-----------------------------------+---------------------------+---------+...
...| PRIMARY | NULL | NULL |...
...| PRIMARY,fk_film_category_category | fk_film_category_category | 1 |...
...| PRIMARY | PRIMARY | 2 |...
...| PRIMARY,idx_fk_film_id | idx_fk_film_id | 2 |...
...| PRIMARY | PRIMARY | 2 |...
...+-----------------------------------+---------------------------+---------+...
...+------------------------------+------+----------+-------------+
...| ref | rows | filtered | Extra |
...+------------------------------+------+----------+-------------+
...| NULL | 16 | 10.00 | Using where |
...| sakila.category.category_id | 62 | 100.00 | Using index |
...| sakila.film_category.film_id | 1 | 100.00 | Using index |
...| sakila.film_category.film_id | 5 | 100.00 | Using index |
...| sakila.film_actor.actor_id | 1 | 100.00 | NULL |
...+------------------------------+------+----------+-------------+
5 rows in set, 1 warning (0.00 sec)
Прежде чем мы обсудим вывод, подумайте о том, как запрос может быть оценен. MySQL может просмотреть каждую строку в таблице actor, затем сопоставить ее с film_actor, затем с film, film_category и, наконец, с category. У нас есть фильтр в таблице category, поэтому в этом воображаемом случае MySQL сможет сопоставить меньшее количество строк только после того, как попадет в эту таблицу. Это плохая стратегия исполнения. Можете ли вы придумать лучше?
Давайте теперь посмотрим, что на самом деле решила сделать MySQL. На этот раз строк пять, потому что в соединении пять таблиц. Давайте пробежимся по этому примеру, сосредоточившись на тех вещах, которые отличаются его от предыдущих:
-
Первый ряд похож на то, что мы видели раньше. MySQL прочитает все 16 строк из таблицы
category. На этот раз в столбцеExtraуказаноUsing where. Это означает, что будет применяться фильтр, основанный на предложенииWHERE. В этом примере столбецfilteredпоказывает 10, что означает, что примерно 10% строк таблицы будут созданы на этом этапе для дальнейших операций. Оптимизатор MySQL ожидает 16 строк в таблице и ожидает, что здесь будут возвращены одна-две строки. -
Теперь давайте посмотрим на строку 2. Тип соединения для таблицы
film_category—ref, что означает, что будут прочитаны все строки в таблицеfilm_category, соответствующие строкам в таблицеcategory. На практике это означает, что одна или несколько строк из таблицыfilm_categoryбудут считаны для каждого идентификатораcategory_idиз таблицыcategory. Столбецpossible_keysпоказывает какPRIMARY, так иfk_film_category_category, и последний выбран в качестве индекса. Первичный ключ таблицыfilm_categoryимеет два столбца, и первый из них —film_id, что делает этот индекс менее оптимальным для фильтрации поcategory_id. Ключ, используемый для поискаfilm_category, имеет значениеkey_len, равное 1, и поиск выполняется с использованием значенияsakila.category.category_idиз таблицыcategory. -
Переходя к следующей строке, мы видим, что тип соединения для таблицы
film—eq_ref. Это означает, что для каждой строки, полученной на предыдущем этапе (сканированииfilm_category), на этом этапе будет прочитана ровно одна строка. MySQL может гарантировать это, поскольку индекс, используемый для доступа к таблицеfilm, являетсяUNIQUE NOT NULL. В общем, если используется индекс UNIQUE NOT NULL, возможенeq_ref. Это одна из лучших стратегий объединения.
Две вложенные строки в выводе не показывают нам ничего нового. В итоге мы видим, что MySQL выбрал оптимальный план выполнения. Обычно чем меньше строк считывается на первом шаге выполнения, тем быстрее выполняется запрос.
MySQL 8.0 представил новый формат вывода EXPLAIN PLAN, который доступен через оператор EXPLAIN ANALYZE. Хотя это может быть несколько легче для чтения, здесь есть оговорка, что оператор действительно должен быть выполнен, в отличие от обычного EXPLAIN. Мы не будем вдаваться в подробности этого нового формата, но покажем здесь пример:
mysql> EXPLAIN ANALYZE SELECT first_name, last_name
-> FROM actor JOIN film_actor USING (actor_id)
-> JOIN film USING (film_id)
-> WHERE title = 'ZHIVAGO CORE'\G
*************************** 1. row ***************************
EXPLAIN:
-> Nested loop inner join
(cost=3.07 rows=5)
(actual time=0.036..0.055 rows=6 loops=1)
-> Nested loop inner join
(cost=1.15 rows=5)
(actual time=0.028..0.034 rows=6 loops=1)
-> Index lookup on film
using idx_title (title='ZHIVAGO CORE')
(cost=0.35 rows=1)
(actual time=0.017..0.018 rows=1 loops=1)
-> Index lookup on film_actor
using idx_fk_film_id (film_id=film.film_id)
(cost=0.80 rows=5)
(actual time=0.010..0.015 rows=6 loops=1)
-> Single-row index lookup on actor
using PRIMARY (actor_id=film_actor.actor_id)
(cost=0.27 rows=1)
(actual time=0.003..0.003 rows=1 loops=6)
1 row in set (0.00 sec)
Этот вывод еще более совершенен, чем обычный вывод EXPLAIN, так как он дает больше данных. Мы оставим анализ в качестве упражнения для читателя. Вы должны понять это, основываясь на нашем объяснении обычного вывода EXPLAIN.
Альтернативные механизмы хранения
Одной из особенностей MySQL, которая отличает ее от многих других СУБД, является поддержка различных механизмов хранения. Механизм поддержки нескольких движков в MySQL сложен, и чтобы объяснить его должным образом, нам нужно более подробно остановиться на его архитектуре и реализации, чем у нас есть здесь. Однако мы можем попытаться дать вам общее представление о том, какие механизмы доступны, почему вы можете захотеть использовать нестандартный механизм и почему этот выбор важен.
Вместо того, чтобы говорить механизм хранения (storage engine), что звучит сложно, мы могли бы сказать табличный тип (table type). Говоря очень упрощенно, MySQL позволяет вам создавать таблицы разных типов, причем каждый тип дает этим таблицам свои свойства. Не существует универсально хорошего типа таблицы, так как у каждого механизма хранения есть свои плюсы и минусы.
До сих пор в книге мы использовали только тип таблицы InnoDB по умолчанию. Причина проста: почти все, что вам может понадобиться от современной базы данных, может быть достигнуто с помощью InnoDB. Как правило, это быстрый, надежный, проверенный и хорошо поддерживаемый движок, который, как многие считают (в том числе и мы), обеспечивает наилучший баланс плюсов и минусов. Мы видели, как этот движок успешно используется приложениями, требующими очень высокой пропускной способности коротких запросов, а также приложениями хранилища данных, которые выполняют немного, но «больших» запросов.
На момент написания в официальной документации MySQL было зарегистрировано 8 дополнительных механизмов хранения, а для MariaDB — 18 дополнительных механизмов. На самом деле существует еще больше доступных механизмов хранения, но не все из них включены в документацию по основным разновидностям MySQL. Здесь мы опишем только те движки, которые мы считаем полезными и которые хотя бы частично используются. Вполне может быть, что механизм хранения, который лучше всего подходит для вашего варианта использования, не описан нами. Не обижайтесь; их слишком много, чтобы покрыть их всех справедливо.
Прежде чем мы углубимся в наш обзор различных движков, давайте кратко рассмотрим, почему это важно. Подключаемый характер механизмов хранения в MySQL и возможность создавать таблицы с различными типами важны, потому что это позволяет вам унифицировать уровень доступа к вашей базе данных. Вместо того, чтобы использовать несколько продуктов баз данных, каждый со своим собственным драйвером, языком запросов, конфигурацией, управлением, резервным копированием и т. д., вы можете просто использовать MySQL и добиваться различного поведения, изменяя типы таблиц. Вашим приложениям может даже не понадобиться знать, какие типы имеют таблицы. Тем не менее, не все так просто и радужно. Возможно, вы не сможете использовать все решения для резервного копирования, которые мы объясним в главе 10. Вам также необходимо понимать компромиссы, которые предоставляет каждое ядро. Тем не менее, мы по-прежнему считаем, что лучше иметь возможность изменять типы таблиц, чем не иметь ее.
Мы начнем наш обзор с определения широких категорий, основанных на важных свойствах различных механизмов хранения. Одним из наиболее важных разделов является способность движка поддерживать транзакции (подробнее о транзакциях, блокировках и почему все это важно в главе 6).
Доступные в настоящее время транзакционные механизмы включают InnoDB по умолчанию, активно разрабатываемый MyRocks и устаревший TokuDB. Все различные движки доступны в основных версиях MySQL; но только эти три поддерживают транзакции. Любой другой движок не является транзакционным.
Следующее широкое разделение, которое мы можем провести, основано на безопасности при столкновении или способности двигателя гарантировать свойство долговечности набора свойств ACID. Если в таблице используется отказоустойчивый движок, мы можем ожидать, что каждый бит данных, записанных зафиксированной транзакцией, будет доступен после нечистого перезапуска экземпляра. К аварийно-безопасным движкам относятся уже упомянутые InnoDB, MyRocks и TokuDB, а также движок Aria. Ни один из других доступных движков не гарантирует безопасность при столкновении.
Мы могли бы привести больше примеров того, как сгруппировать типы таблиц, но давайте перейдем непосредственно к описанию некоторых механизмов и их свойств. Прежде всего, давайте посмотрим, как на самом деле просмотреть список доступных движков. Для этого мы используем специальную команду SHOW ENGINES. Вот его вывод для установки MySQL 8.0.23 Linux по умолчанию:
mysql> SHOW ENGINES;
+--------------------+---------+...
| Engine | Support |...
+--------------------+---------+...
| ARCHIVE | YES |...
| BLACKHOLE | YES |...
| MRG_MYISAM | YES |...
| FEDERATED | NO |...
| MyISAM | YES |...
| PERFORMANCE_SCHEMA | YES |...
| InnoDB | DEFAULT |...
| MEMORY | YES |...
| CSV | YES |...
+--------------------+---------+...
...+----------------------------------------------------------------+...
...| Comment |...
...+----------------------------------------------------------------+...
...| Archive storage engine |...
...| /dev/null storage engine (anything you write to it disappears) |...
...| Collection of identical MyISAM tables |...
...| Federated MySQL storage engine |...
...| MyISAM storage engine |...
...| Performance Schema |...
...| Supports transactions, row-level locking, and foreign keys |...
...| Hash based, stored in memory, useful for temporary tables |...
...| CSV storage engine |...
...+----------------------------------------------------------------+...
...+--------------+------+------------+
...| Transactions | XA | Savepoints |
...+--------------+------+------------+
...| NO | NO | NO |
...| NO | NO | NO |
...| NO | NO | NO |
...| NULL | NULL | NULL |
...| NO | NO | NO |
...| NO | NO | NO |
...| YES | YES | YES |
...| NO | NO | NO |
...| NO | NO | NO |
...+--------------+------+------------+
9 rows in set (0.00 sec)
Вы можете видеть, что MySQL удобно сообщает нам, поддерживает ли механизм транзакции. Столбец XA предназначен для распределенных транзакций — мы не будем рассматривать их в этой книге. Точки сохранения — это, по сути, возможность создавать мини-транзакции внутри транзакций, еще одна сложная тема. В качестве упражнения рассмотрите возможность запуска SHOW ENGINES; в установках MariaDB и Percona Server.
InnoDB
Прежде чем мы перейдем к «альтернативным» механизмам хранения, давайте обсудим стандартный: InnoDB. InnoDB надежен, эффективен и полнофункционален. Почти все, что вы ожидаете от современной СУБД, в некотором роде достижимо с InnoDB. В этой книге мы никогда не меняем движок таблицы, поэтому в каждом примере используется InnoDB. Пока вы изучаете MySQL, мы рекомендуем вам придерживаться этого движка. Важно понимать его недостатки, но если они не станут для вас проблематичными, почти нет причин не использовать его постоянно.
Тип таблицы InnoDB включает следующие функции:
- Поддержка транзакций
-
Это подробно обсуждается в главе 6.
- Расширенные функции восстановления после сбоев
-
Тип таблицы InnoDB использует журналы, которые представляют собой файлы, содержащие записи о действиях, предпринятых MySQL для изменения базы данных. Журналы позволяют MySQL эффективно восстанавливаться после отключений питания, падений и других основных сбоев базы данных. Конечно, ничто не может помочь вам восстановиться после отключения машины, выхода из строя дисковода или других катастрофических сбоев. Для этого вам нужны удаленные резервные копии и новое оборудование. Каждый инструмент резервного копирования, который мы рассмотрим в главе 10, работает с InnoDB.
- Блокировка на уровне строки
-
В отличие от предыдущего механизма по умолчанию, MyISAM (который мы рассмотрим в следующем разделе), InnoDB предоставляет детализированную инфраструктуру блокировок. Самый низкий уровень блокировки — уровень строки, что означает, что отдельная строка может быть заблокирована выполняющимся запросом или транзакцией. Это важно для большинства приложений оперативной обработки транзакций (OLTP), требующих больших объемов записи; если вы блокируете на более высоком уровне, например на уровне таблицы, вы можете столкнуться со слишком большим количеством проблем с параллелизмом.
- Поддержка внешнего ключа
-
InnoDB в настоящее время является единственным типом таблиц MySQL, который поддерживает внешние ключи. Если вы строите систему, требующую высокого уровня безопасности данных, обеспечиваемой ссылочными ограничениями, InnoDB — ваш единственный выбор.
- Поддержка шифрования
-
Таблицы InnoDB могут быть прозрачно зашифрованы MySQL.
- Поддержка разделов
-
InnoDB поддерживает секционирование (partitioning); то есть физическое распространение данных между несколькими файлами данных на основе некоторых правил. Это позволяет InnoDB эффективно работать с таблицами огромных размеров.
Плюсов много, но есть и минусы:
- Сложность
-
InnoDB относительно сложен. Это означает, что многое нужно настроить и понять. Из почти тысячи серверных опций в MySQL более двухсот специфичны для InnoDB. Однако этот недостаток значительно перевешивается преимуществами, которые дает этот движок.
- Объем данных
-
InnoDB — относительно ресурсоемкий механизм хранения, что делает его менее привлекательным для хранения очень больших наборов данных.
- Масштабирование с размером базы данных
-
InnoDB блистает, когда в его буферном пуле присутствует так называемый «горячий» набор данных или часто используемые данные. Это ограничивает его масштабируемость.
MyISAM и Aria
MyISAM долгое время был механизмом хранения по умолчанию в MySQL и основой этой базы данных. Он прост в использовании и дизайне, достаточно производительен и имеет низкие накладные расходы. Так почему же он перестал быть стандартным? На самом деле для этого есть несколько веских причин, как вы увидите, когда мы обсудим его ограничения.
В настоящее время мы не рекомендуем использовать MyISAM, если это не требуется по устаревшим причинам. Вы можете прочитать в Интернете, что его производительность лучше, чем у InnoDB. К сожалению, большая часть этой информации очень старая и все более устаревает — сегодня в подавляющем большинстве случаев это просто не так. Одной из причин этого являются изменения в ядре Linux, вызванные уязвимостями безопасности Spectre и Meltdown в январе 2018 года, что привело к снижению производительности MyISAM до 90%.
До MySQL 8.0 MyISAM использовался в MySQL для всех объектов словаря данных. Начиная с этой версии словарь данных теперь полностью InnoDB для поддержки расширенных функций, таких как атомарный DDL.
Aria — это переработанный MyISAM, представленный в MariaDB. Помимо обещания лучшей производительности и постоянного улучшения и работы, наиболее важной особенностью Aria является ее безопасность при падении. MyISAM, в отличие от InnoDB, не гарантирует сохранность данных при успешной записи, что является основным недостатком этого механизма хранения. Aria, с другой стороны, позволяет создавать надежные таблицы, поддерживаемые глобальным журналом транзакций. В будущем Aria также может поддерживать полноценные транзакции, но на момент написания статьи это не так.
Тип таблицы MyISAM включает следующие функции:
- Блокировка на уровне таблицы
-
В отличие от InnoDB, MyISAM поддерживает блокировки только на высоком уровне целых таблиц. Это намного проще и менее тонко, чем блокировка на уровне строк, и требует меньших накладных расходов и памяти. Однако при многопараллельных рабочих нагрузках с большим количеством операций записи становится очевидным главный недостаток: даже если каждый сеанс будет обновлять или вставлять отдельную строку, каждый из них будет выполняться по очереди. Чтения в MyISAM могут сосуществовать одновременно, но они будут блокировать параллельные записи. Запись также блокирует чтение.
- Поддержка разделов
-
До MySQL 8.0 MyISAM поддерживал секционирование. В MySQL 8.0 это уже не так, и для этого нужно прибегнуть к использованию других механизмов хранения (Merge или MRG_MyISAM).
- Сжатие
-
С помощью утилиты
myisampackможно создавать сжатые таблицы только для чтения, которые немного меньше, чем эквивалентные таблицы InnoDB без сжатия. Однако, поскольку InnoDB поддерживает сжатие, мы рекомендуем вам сначала проверить, даст ли эта опция лучшие результаты.
Тип MyISAM имеет следующие ограничения:
- Безопасность при падении и восстановлении
-
Таблицы MyISAM не защищены от сбоев. MySQL не гарантирует, что при успешной записи данные действительно достигнут файлов на диске. Если MySQL не завершится корректно, таблицы MyISAM могут быть повреждены, потребовать ремонта и потерять данные.
- Транзакции
-
MyISAM не поддерживает транзакции. Таким образом, MyISAM обеспечивает атомарность только для каждого отдельного оператора, чего в вашем случае может быть недостаточно.
- Шифрование
-
Таблицы MyISAM не поддерживают шифрование.
MyRocks и TokuDB
Одной из наиболее значительных проблем с InnoDB является относительная сложность работы с большими наборами данных. Мы упоминали, что желательно иметь часто используемые данные в памяти, но это не всегда возможно. Более того, когда объем данных достигает нескольких терабайт, производительность InnoDB на диске также страдает. Объекты в InnoDB также имеют довольно большие накладные расходы с точки зрения размера. В последние годы появилось несколько различных проектов, которые пытаются исправить проблемы, присущие базовой структуре данных InnoDB, B-дереву, путем создания механизма хранения на другой структуре данных. К ним относятся MyRocks, основанный на LSM-дереве, и TokuDB, основанный на собственной структуре данных фрактального дерева.
Влияние структур данных на свойства механизмов хранения — сложная тема, возможно, выходящая за рамки администрирования и эксплуатации баз данных. Мы стараемся, чтобы в этой книге все было достаточно просто, поэтому мы не будем углубляться в эту конкретную тему. Вы также должны помнить, что мы писали ранее об InnoDB: это значение по умолчанию не является необоснованным, и чаще всего простое использование InnoDB даст вам лучший набор компромиссов. Мы по-прежнему рекомендуем вам использовать InnoDB при изучении MySQL и в дальнейшем, но мы также считаем, что должны рассмотреть альтернативы.
Тип таблицы MyRocks включает в себя следующие функции:
- Поддержка транзакций
-
MyRocks — это механизм хранения транзакций, поддерживающий обычные и распределенные транзакции. Точки сохранения не полностью поддерживаются.
- Расширенные функции восстановления после сбоев
-
MyRocks полагается на внутренние файлы журналов, называемые файлами WAL (от «write-ahead log» (журнал упреждающей записи)), чтобы обеспечить гарантии восстановления после сбоя. Вы можете ожидать, что все, что было зафиксировано, будет присутствовать после перезапуска базы данных после сбоя.
- Поддержка шифрования
-
Таблицы MyRocks могут быть зашифрованы.
- Поддержка разделов
-
Таблицы MyRocks могут быть разбиты на разделы.
- Сжатие данных и компактность
-
Хранилище таблиц MyRocks обычно меньше, чем у таблиц InnoDB. К этому приводят два свойства: используется более компактная структура хранения, и данные в этой структуре хранения могут быть сжаты. Хотя сжатие не является уникальным для MyRocks, и InnoDB фактически предоставляет параметры сжатия, MyRocks постоянно показывает лучшие результаты.
- Стабильная производительность записи в масштабе
-
Это трудно правильно объяснить, не погружаясь в дебри. Однако минимальная версия заключается в том, что производительность записи MyRocks практически не зависит от объема данных. В реальном мире это означает, что таблицы MyRocks показывают худшую производительность, чем таблицы InnoDB, пока размер данных не станет намного больше памяти. Затем происходит то, что производительность InnoDB снижается быстрее, чем у MyRocks, в конечном итоге отставая.
Тип таблицы MyRocks имеет следующие ограничения:
- Транзакции и блокировки
-
MyRocks не поддерживает уровень изоляции
SERIALIZABLEили блокировку промежутков, описанную в главе 6. - Внешние ключи
-
Только InnoDB поддерживает ограничения внешнего ключа.
- Компромиссы производительности
-
MyRocks плохо справляется с нагрузками, связанными с чтением и аналитикой. InnoDB обеспечивает лучшую общую производительность.
- Сложность
-
Мы упоминали, что InnoDB сложнее, чем MyISAM. Однако в некоторых отношениях MyRocks сложнее, чем InnoDB. Он плохо документирован, активно развивается (поэтому менее стабилен) и с ним может быть сложно работать.
- Общая доступность
-
MyRocks недоступен в Community или Enterprise MySQL; чтобы использовать его, вам нужно использовать другую версию MySQL, например, MariaDB или Percona Server. Это может привести к трудностям в работе. Пакетные версии отстают от разработки, и для использования всех текущих функций необходимо построить выделенный сервер MySQL с исходными кодами MyRocks.
Другие типы таблиц
Мы рассмотрели все основные типы таблиц, но есть еще несколько, которые мы кратко обобщим. Некоторые из этих механизмов хранения редко используются, и у них могут быть проблемы с документацией и ошибки.
- Память
-
Таблицы этого типа полностью хранятся в памяти и никогда не сохраняются на диске. Очевидным преимуществом является производительность: память во много раз быстрее диска и, вероятно, так будет всегда. Недостатком является то, что данные теряются сразу после перезапуска или сбоя MySQL. Таблицы памяти обычно используются как временные таблицы. Кроме того, таблицы памяти можно использовать для хранения небольших, часто используемых горячих данных, таких как своего рода словарь.
- Архив
-
Этот тип обеспечивает способ хранения данных в сильно сжатом виде и только с добавлением. Вы не можете изменять или удалять данные в таблицах с помощью механизма хранения архива. Как следует из названия, он в основном полезен для долгосрочного хранения данных. На самом деле он редко используется, и у него есть несколько проблем с первичным ключом и обработкой автоинкремента. InnoDB со сжатыми таблицами и MyRocks могут предоставить лучшие альтернативы.
- CSV
-
Этот механизм хранения хранит таблицы на диске в формате CSV. Это позволяет вам просматривать такие таблицы и управлять ими с помощью приложений для работы с электронными таблицами или просто текстовых редакторов. Он используется нечасто, но может быть альтернативным подходом к тому, что мы объясняли в разделе «Загрузка данных из файлов с разделителями-запятыми», а также может использоваться для экспорта данных.
- Объединенные таблицы (Federated)
-
Этот тип обеспечивает способ запроса данных в удаленных системах MySQL. Объединенные таблицы не содержат никаких данных, только некоторые метаданные, относящиеся к деталям подключения. Это интересный способ получения или изменения удаленных данных без настройки репликации. По сравнению с простым подключением к удаленному MySQL, он имеет преимущество одновременного предоставления доступа к локальным и удаленным таблицам.
- Черная дыра (Blackhole)
-
Этот механизм хранения отбрасывает каждый бит данных, который должен храниться в его таблицах. Другими словами, все, что записывается в таблицу Blackhole, немедленно теряется. Звучит не очень полезно, но есть варианты использования этого движка. Обычно он используется для фильтрации репликации через промежуточный сервер, где ненужные таблицы блокируются. Другой потенциальный вариант использования — избавиться от таблицы в приложении с закрытым исходным кодом: вы не можете просто удалить таблицу, так как это сломает приложение, но сделав ее черной дырой, вы избавитесь от любых накладных расходов на обработку и хранение.
Эти механизмы хранения довольно экзотичны и редко встречаются в дикой природе. Однако вы должны знать, что они существуют, поскольку невозможно предугадать, когда что-то может оказаться полезным.
Глава 8
Управление пользователями и привилегиями
Простейшая система баз данных — это просто куча файлов, лежащих поблизости, с некоторыми данными в них и без единого процесса доступа. От любой РСУБД мы ожидаем значительно более высокого уровня сложности и абстракции. Во-первых, мы хотим иметь возможность одновременного доступа к базе данных с нескольких клиентов. Однако не все клиенты одинаковы, и не каждому из них обязательно нужен доступ ко всем данным в базе данных. Можно представить себе базу данных, в которой каждый пользователь является суперпользователем, но это будет означать, что вам придется устанавливать выделенную базу данных для каждого приложения и набора данных: расточительно. Вместо этого базы данных эволюционировали, чтобы поддерживать несколько пользователей и ролей и предоставлять средства для управления привилегиями и доступом на очень детальном уровне, чтобы гарантировать безопасные общие среды.
Понимание пользователей и привилегий является важной частью эффективной работы с системой баз данных. Результатом хорошо спланированных и управляемых ролей является безопасная система, которой легко управлять и с которой легко работать. В этой главе мы рассмотрим большую часть вещей, которые необходимо знать об управлении пользователями и привилегиями, начиная с основ и переходя к новым функциям, таким как роли. После прочтения этой главы у вас должны быть все основы, необходимые для управления доступом к базе данных MySQL.
Понимание пользователей и привилегий
Первым строительным блоком в основе общей системы является понятие пользователя. Большинство современных операционных систем имеют пользовательский доступ, так что весьма вероятно, что вы уже знаете, что это значит. Пользователи в MySQL — это специальные объекты, используемые для:
-
Аутентификации (убедитесь, что пользователь может получить доступ к серверу MySQL)
-
Авторизации (убедитесь, что пользователь может взаимодействовать с объектами в базе данных)
Одна вещь, которая отличает MySQL от других СУБД, заключается в том, что пользователи не владеют объектами схемы.
Рассмотрим эти моменты чуть подробнее. Каждый раз, когда вы получаете доступ к серверу MySQL, вы должны указать пользователя, который будет использоваться во время аутентификации. После того, как вы прошли аутентификацию и ваша личность подтверждена, вы получаете доступ к базе данных. Обычно пользователь, от имени которого вы будете работать с объектами схемы, будет тем же, что и для аутентификации, но это не обязательно, и поэтому мы отделим второй пункт. Прокси-пользователь — это пользователь, который используется для проверки привилегий и фактически действует в базе данных, когда во время аутентификации используется другой пользователь. Это довольно сложная тема и требует конфигурации не по умолчанию, но это все же возможно.
Это важное различие между аутентификацией и авторизацией, о котором следует помнить. Хотя вы можете аутентифицироваться как один пользователь, и авторизоваться как другой пользователь и иметь или не иметь различные разрешения.
Разобравшись с этими двумя понятиями, давайте обсудим последний пункт. Некоторые СУБД поддерживают концепцию владения объектами. То есть, когда пользователь создает объект базы данных — базу данных или схему, таблицу или хранимую процедуру, — этот пользователь автоматически становится владельцем нового объекта. Владелец обычно имеет возможность изменять объекты, которыми он владеет, и предоставлять доступ к ним другим пользователям. Здесь важно то, что MySQL никоим образом не имеет концепции владения объектами.
Это отсутствие права собственности делает еще более важным иметь гибкие правила, чтобы пользователи могли создавать объекты, а затем потенциально делиться доступом к этим объектам с другими пользователями. Это достигается с помощью привилегий. Привилегии можно рассматривать как наборы правил, контролирующих, какие действия разрешено выполнять пользователям и к каким данным они могут получить доступ. Важно понимать, что по умолчанию в MySQL пользователь базы данных вообще не имеет привилегий. Предоставление привилегии означает разрешение некоторых действий, которые по умолчанию запрещены.
Пользователи в MySQL также немного отличаются от пользователей в других базах данных, поскольку объект пользователя включает в себя список контроля доступа к сети (ACL). Обычно пользователь MySQL представлен не только своим именем, например bob, но и добавленным сетевым адресом, например bob@localhost. В этом конкретном примере определяется пользователь, к которому можно получить доступ только локально через loopback-интерфейс или соединение через сокет Unix. Мы коснемся этой темы позже, когда будем обсуждать синтаксис SQL для создания существующих пользователей и управления ими.
MySQL хранит всю информацию, связанную с пользователями и привилегиями, в специальных таблицах системной базы данных mysql, которые называются таблицами привилегий (grant tables). Мы поговорим об этой концепции более подробно в разделе «Таблицы грантов».
Этой краткой теоретической основы должно быть достаточно для формирования базового понимания системы пользователей и привилегий MySQL. Давайте приступим к практике и рассмотрим команды и возможности, предоставляемые базой данных для управления пользователями и привилегиями.
Пользователь root
Каждая установка MySQL поставляется с несколькими пользователями, установленными по умолчанию. К большинству из них вам никогда не нужно иметь дело, но есть один, который используется очень часто. Кто-то может даже сказать, что им злоупотребляют, но это не та дискуссия, которую мы хотим здесь вести. Пользователь, о котором мы говорим, — это вездесущий и всемогущий пользователь root. С тем же именем, что и у суперпользователя Unix и Linux по умолчанию, этот пользователь является именно таким в MySQL: пользователь, который по умолчанию может делать все что угодно.
Чтобы быть более конкретным, пользователь root@localhost, иногда называемый начальным пользователем (initial user). Часть localhost имени пользователя, как вы теперь знаете, ограничивает его использование только локальными соединениями. Когда вы устанавливаете MySQL, в зависимости от конкретного варианта MySQL и ОС вы можете получить доступ к root@localhost из корневой учетной записи ОС, просто выполнив команду mysql. В некоторых других случаях для этого пользователя будет сгенерирован временный пароль.
Начальный пользователь — не единственный суперпользователь, которого вы можете создать, как вы увидите в разделе «Привилегия SUPER». Хотя вы можете создать пользователя root@<ip> или даже пользователя root@%, мы настоятельно не рекомендуем вам этого делать, так как это уязвимость в системе безопасности, которую можно использовать. Не каждому серверу MySQL даже нужно прослушивать интерфейс, кроме loopback (то есть localhost), не говоря уже о том, чтобы иметь суперпользователя с именем по умолчанию, доступным для входа в систему. Конечно, вы можете установить безопасные пароли для всех пользователей и, вероятно, следует установить один для root, но, возможно, немного безопаснее не разрешать удаленный доступ суперпользователя, если это возможно.
Во всех смыслах и целях root@localhost — это обычный пользователь со всеми предоставленными привилегиями. Вы даже можете удалить его, что может произойти по ошибке. Потеря доступа к пользователю root@localhost является довольно распространенной проблемой при работе с MySQL. Возможно, вы установили пароль и забыли его, или вы унаследовали сервер, и вам не дали пароль, или что-то еще могло произойти. Мы рассмотрим процедуру восстановления забытого пароля для первоначального пользователя root@localhost в разделе «Изменение пароля root и небезопасный запуск». Если вы удалили своего последнего доступного суперпользователя, вам придется выполнить ту же процедуру, но создать нового пользователя вместо изменения существующего.
Создание и использование новых пользователей
Первая задача, которую мы рассмотрим, — это создание нового пользователя. Давайте начнем с довольно простого примера и рассмотрим каждую часть:
CREATE USER ❶
'bob'@'10.0.2.%' ❷
IDENTIFIED BY 'password'; ❸
❶ Оператор SQL для создания пользователя
❷ Определение пользователя и хоста
❸ Спецификация пароля
Вот более сложный пример:
CREATE USER ❶
'bob'@'10.0.2.%' ❷
IDENTIFIED WITH mysql_native_password ❸
BY 'password' ❹
DEFAULT ROLE 'user_role' ❺
REQUIRE SSL ❻
AND CIPHER 'EDH-RSA-DES-CBC3-SHA' ❼
WITH MAX_USER_CONNECTIONS 10 ❽
PASSWORD EXPIRE NEVER; ❾
❶ Оператор SQL для создания пользователя
❷ Определение пользователя и хоста
❸ Спецификация плагина аутентификации
❹ Строка аутентификации/пароль
❺ Роль по умолчанию устанавливается после аутентификации и подключения пользователя
❻ Требовать SSL для соединений для этого пользователя
❼ Требовать конкретных шифров
❽ Ограничить максимальное количество подключений от этого пользователя
❾ Переопределить глобальные настройки срока действия пароля
Это поверхностно, но должно дать представление о параметрах, которые пользователь может изменить при его создании. Их довольно много. Давайте рассмотрим отдельные части этого выражения более подробно:
- Определение пользователя и хоста
-
Мы упоминали в разделе «Понимание пользователей и привилегий», что пользователи в MySQL определяются не только по имени, но и по имени хоста. В предыдущем примере пользователь —
'bob'@'10.0.2.%', гдеbob— имя пользователя, а10.0.2.%— спецификация имени хоста. По сути, это спецификация имени хоста с подстановочным знаком. Каждый раз, когда кто-то подключается к имени пользователяbob, используя TCP, MySQL делает несколько вещей:-
Получает IP-адрес подключающегося клиента.
-
Выполняет обратный DNS-поиск IP-адреса по имени хоста.
-
Выполняет поиск DNS для этого имени хоста (чтобы убедиться, что обратный поиск не был скомпрометирован).
-
Сравнивает имя хоста или IP-адрес со спецификацией имени хоста пользователя.
Доступ предоставляется только в том случае, если имена хостов совпадают. Для нашего пользователя
bobсоединение с IP-адреса10.0.2.121будет разрешено, а соединение с10.0.3.22— запрещено. Фактически, чтобы разрешить подключения с другого имени хоста, необходимо создать нового пользователя. Внутренне'bob'@'10.0.2.%'— это совершенно другой пользователь, чем'bob'@'10.0.3.%'. Также можно использовать полные доменные имена (FQDN) в спецификации имени хоста, например,'bob'@'acme.com', но поиск в DNS требует времени, и обычно их полностью отключают при оптимизации.Указание всех возможных имен хостов для подключения всех пользователей может быть утомительным, но это полезная функция для безопасности. Однако иногда база данных устанавливается за брандмауэром или просто нецелесообразно указывать имена хостов. Чтобы полностью разрушить эту систему, можно использовать один подстановочный знак в спецификации хоста, например,
'bob'@'10.0.2%'. Подстановочный знак'%'также используется, когда вы вообще не указываете хост ('bob'@'%').Вы заметите, что мы заключили имя пользователя и спецификацию хоста в одинарные кавычки (
''). Это не является обязательным, и спецификация имени пользователя и хоста подчиняется тому же набору правил, что и правила, изложенные для имен и псевдонимов таблиц и столбцов в разделах «Создание и использование баз данных» и «Псевдонимы». Например, при создании или изменении пользователяbob@localhostилиbob@172.17.0.2нет необходимости использовать кавычки. Однако вы не можете создать этого пользователя без кавычек:'username with a space'@'172.%'. Двойные кавычки, одинарные кавычки или обратные кавычки могут использоваться для заключения имен пользователей и имен хостов со специальными символами. -
- Спецификация плагинов аутентификации
-
MySQL поддерживает множество способов аутентификации пользователей с помощью своей системы подключаемых модулей аутентификации. Эти плагины также предоставляют разработчикам возможность реализовать новые средства аутентификации без изменения самого MySQL. Вы можете установить конкретный плагин для пользователя на этапе создания или позже.
Возможно, вам никогда не понадобится менять плагин для пользователя, но все же стоит знать об этой подсистеме. В частности, аутентификация LDAP с MySQL может быть достигнута с помощью специального подключаемого модуля аутентификации. MySQL Enterprise Edition поддерживает первоклассный подключаемый модуль LDAP, а другие версии и разновидности MySQL могут в качестве посредника использовать PAM.
MySQL 8.0 использует подключаемый модуль
caching_sha2_passwordпо умолчанию, который обеспечивает более высокую безопасность и производительность по сравнению с устаревшимmysql_native_password, но не совместим со всеми клиентскими библиотеками. Чтобы изменить плагин по умолчанию, вы можете настроить переменнуюdefault_authentication_plugin, что приведет к созданию новых пользователей с указанным плагином. - Строка аутентификации/пароль
-
Некоторые плагины аутентификации, в том числе плагин по умолчанию, требуют, чтобы вы установили пароль для пользователя. Другие плагины, такие как PAM, требуют, чтобы вы определили сопоставление пользователей ОС с пользователями MySQL.
auth_stringбудет использоваться в обоих случаях. Давайте посмотрим на пример сопоставления с PAM:mysql> CREATE USER ''@'' IDENTIFIED WITH auth_pam -> AS 'mysqld, dba=dbausr, dev=devusr'; Query OK, 0 row affected (0.01 sec)Здесь определено сопоставление, которое можно прочитать следующим образом: будет использоваться файл конфигурации PAM mysqld (обычно находится в /etc/pam.d/mysqld); Пользователи ОС с группой
dbaбудут сопоставлены с пользователем MySQLdbausr, а пользователи ОС с группойdev— сdevusr. Однако одного сопоставления недостаточно, поскольку необходимо назначить необходимые разрешения.Обратите внимание, что для этого требуется либо подключаемый модуль Percona PAM, либо MySQL Enterprise Edition. В этом примере создается прокси-пользователь, которого мы кратко обсуждали в разделе «Знакомство с пользователями и привилегиями».
Использование подключаемых модулей аутентификации не по умолчанию — относительно сложная тема, поэтому мы поднимаем здесь PAM только для того, чтобы показать вам, что строка аутентификации не всегда является паролем.
- Набор ролей по умолчанию
-
Роли — довольно недавнее дополнение к MySQL. Вы можете думать о роли как о наборе привилегий. Мы обсуждаем их в разделе «Роли».
- SSL-конфигурация
-
Вы можете заставить соединения определенных пользователей использовать SSL, передав команду
REQUIRE SSLкомандеCREATE USERилиALTER USER. Незашифрованные соединения с пользователем будут запрещены. Кроме того, вы можете, как показано в приведенном нами примере, указать конкретный набор шифров или несколько наборов, которые можно использовать для этого пользователя. В идеале вы должны установить приемлемые наборы шифров на системном уровне, но установка этого на уровне пользователя полезна, чтобы разрешить некоторые менее безопасные наборы для определенных подключений. Вам не нужно указыватьREQUIRE SSL, чтобы указатьREQUIRE CIPHER, и в этом случае могут быть установлены незашифрованные соединения. Однако, если установлено зашифрованное соединение, оно будет использовать только указанный вами набор шифров:mysql> CREATE USER 'john'@'192.168.%' IDENTIFIED BY 'P@ssw0rd#' -> REQUIRE CIPHER 'EDH-RSA-DES-CBC3-SHA'; Query OK, 0 row affected (0.02 sec)Доступны следующие дополнительные настраиваемые параметры:
Х509-
Принуждение клиента к предъявлению действительного сертификата. Этот, а также следующие варианты предполагают использование
SSL. ISSUER issuer-
Принуждение клиента к предъявлению действительного сертификата, выданного определенным центром сертификации, указанным в
issuer. SUBJECT subject-
Принуждение клиента к предъявлению действительного сертификата с определенным субъектом.
Эти параметры можно комбинировать, чтобы указать очень конкретные требования к сертификату и шифрованию:
mysql> CREATE USER 'john'@'192.168.%' -> REQUIRE SUBJECT '/C=US/ST=NC/L=Durham/ -> O=BI Dept certificate/ -> CN=client/emailAddress=john@nonexistent.com' -> AND ISSUER '/C=US/ST=NC/L=Durham/ -> O=MySQL/CN=CA/emailAddress=ca@nonexistent.com' -> AND CIPHER 'EDH-RSA-DES-CBC3-SHA'; - Лимиты потребления ресурсов
-
Вы можете определить лимиты потребления ресурсов. В нашем примере мы ограничиваем максимальное количество одновременных подключений этого пользователя до 10. Этот и другие параметры ресурса по умолчанию равны 0, что означает неограниченность. Другими возможными ограничениями являются
MAX_CONNECTIONS_PER_HOUR,MAX_QUERIES_PER_HOURиMAX_UPDATES_PER_HOUR. Все эти параметры являются частью спецификацииWITH.Давайте создадим довольно ограниченного пользователя, который может выполнять только 10 запросов в течение каждого заданного часа, может иметь только одно параллельное соединение и не может подключаться более двух раз в час:
mysql> CREATE USER 'john'@'192.168.%' -> WITH MAX_QUERIES_PER_HOUR 10 -> MAX_CONNECTIONS_PER_HOUR 2 -> MAX_USER_CONNECTIONS 1;Обратите внимание, что число
MAX_QUERIES_PER_HOURвключаетMAX_UPDATES_PER_HOURи также ограничивает количество обновлений. Количество запросов также включает в себя все, что выполняет интерфейс командной строки MySQL, поэтому не рекомендуется устанавливать очень маленькое значение. - Переопределение параметров управления паролями
-
Для подключаемых модулей аутентификации, которые работают с паролями, которые хранятся в таблицах привилегий (описанных в «Таблицах привилегий»), вы можете указать различные параметры, связанные с паролями. В нашем примере мы настраиваем пользователя с политикой
PASSWORD EXPIRE NEVER, что означает, что срок действия его пароля никогда не истечет в зависимости от времени. Вы также можете создать пользователя, срок действия пароля которого истекает через день или каждую неделю.MySQL 8.0 расширяет возможности управления, включая отслеживание неудачных попыток аутентификации и возможность временно заблокировать учетную запись. Рассмотрим важного пользователя со строгим контролем:
mysql> CREATE USER 'app_admin'@'192.168.%' -> IDENTIFY BY '...' -> WITH PASSWORD EXPIRE INTERVAL 30 DAY -> PASSWORD REUSE INTERVAL 180 DAY -> PASSWORD REQUIRE CURRENT -> FAILED_LOGIN_ATTEMPTS 3 -> PASSWORD_LOCK_TIME 1;Пароль этого пользователя нужно будет менять каждые 30 дней, а предыдущие пароли нельзя будет использовать повторно в течение 180 дней. При смене пароля необходимо указать текущий пароль. На всякий случай мы также допускаем только три последовательных неудачных попытки входа в систему и заблокируем этого пользователя на один день, если они будут предприняты.
Обратите внимание, что это переопределение системных параметров по умолчанию. Нецелесообразно настраивать каждого отдельного пользователя вручную, поэтому вместо этого мы рекомендуем вам установить значения по умолчанию и использовать переопределения только для определенных пользователей. Например, вы можете увеличить срок действия паролей пользователей DBA.
Существуют и другие варианты создания пользователей, которые мы здесь не будем рассматривать. По мере развития MySQL становится доступным больше опций, но мы считаем, что рассмотренных нами до сих пор должно быть достаточно для изучения MySQL.
Поскольку этот раздел посвящен не только созданию, но и использованию новых пользователей, давайте поговорим об этих применениях. Обычно они делятся на несколько категорий:
- Подключение и аутентификация
-
Это стандартное и наиболее распространенное использование любого пользовательского объекта. Вы указываете пользователя и пароль, и MySQL аутентифицирует вас с этим пользователем и исходным хостом. Затем эта пара формирует пользователя, определенного в таблицах привилегий, который будет использоваться для авторизации при доступе к объектам базы данных. Это стандартная ситуация. Вы можете запустить следующий запрос, чтобы увидеть текущего аутентифицированного пользователя, а также пользователя, предоставленного клиентом:
mysql> SELECT CURRENT_USER(), USER(); +----------------+----------------+ | CURRENT_USER() | USER() | +----------------+----------------+ | root@localhost | root@localhost | +----------------+----------------+ 1 row in set (0.00 sec)Неудивительно, что записи совпадают. Это наиболее распространенное явление, но, как вы увидите далее, это не единственная возможность.
- Обеспечение безопасности хранимых объектов
-
Когда создается хранимый объект (например, хранимая процедура или представление), любой пользователь может быть указан в предложении
DEFINERэтого объекта. Это позволяет вам выполнять объект с точки зрения другого пользователя: определяющего, а не вызывающего. Это может быть полезным способом предоставления повышенных привилегий для какой-то конкретной операции, но это также может быть дырой в безопасности вашей системы.Когда учетная запись MySQL указана в предложении
DEFINERобъекта, такого как хранимая процедура, эта учетная запись будет использоваться для авторизации при выполнении хранимой процедуры или при запросе представления. Другими словами, текущий пользователь сеанса временно меняется. Как мы уже упоминали, это можно использовать для контролируемого повышения привилегий. Например, вместо того, чтобы предоставлять пользователю разрешение на чтение из некоторых таблиц, вы можете создать представление с помощьюDEFINER: указанной вами учетной записи будет разрешен доступ к таблицам при запросе представления, но не при каких-либо других обстоятельствах. Кроме того, само представление может дополнительно ограничивать возвращаемые данные. То же самое относится и к хранимым процедурам. Чтобы взаимодействовать с объектом, имеющимDEFINER, вызывающая сторона должна иметь необходимые разрешения.Давайте посмотрим на пример. Вот простая хранимая процедура, которая возвращает текущего пользователя, использованного для авторизации, а также пользователя, прошедшего проверку подлинности.
DEFINERустановлен на'bob'@'localhost':DELIMITER ;; CREATE DEFINER = 'bob'@'localhost' PROCEDURE test_proc() BEGIN SELECT CURRENT_USER(), USER(); END; ;; DELIMITER ;Если эту процедуру выполняет пользователь
johnиз предыдущих примеров, будет напечатан вывод, аналогичный следующему:mysql> CALL test_proc(); +----------------+--------------------+ | CURRENT_USER() | USER() | +----------------+--------------------+ | bob@localhost | john@192.168.1.174 | +----------------+--------------------+ 1 row in set (0.00 sec)Важно помнить об этом. Иногда пользователи не являются теми, кем кажутся, и это необходимо учитывать для обеспечения безопасности вашей базы данных.
- Прокси
-
Некоторые методы аутентификации, такие как PAM и LDAP, не работают с однозначным сопоставлением между аутентифицируемыми пользователями и пользователями базы данных. Ранее мы показали, как создать пользователя с аутентификацией PAM — давайте посмотрим, что увидит такой пользователь, если он запросит аутентификацию и предоставит пользователей:
mysql> SELECT CURRENT_USER(), USER(); +------------------+------------------------+ | CURRENT_USER() | USER() | +------------------+------------------------+ | dbausr@localhost | localdbauser@localhost | +------------------+------------------------+ 1 row in set (0.00 sec)
Прежде чем мы закроем этот раздел, мы должны поднять пару важных моментов, связанных с оператором CREATE USER. Во-первых, можно создать несколько учетных записей пользователей с помощью одной команды вместо индивидуального выполнения нескольких операторов CREATE USER. Во-вторых, если пользователь уже существует, CREATE USER не приведет к сбою, но изменит этого пользователя тонкими способами. Это может быть опасно. Чтобы избежать этого, вы можете указать для команды опцию IF NOT EXISTS. Тем самым вы указываете MySQL создать пользователя только в том случае, если такой пользователь еще не существует, и ничего не делать, если он существует.
К этому моменту вы должны иметь хорошее представление о том, что такое пользователь MySQL и как его можно использовать. Далее мы покажем вам, как пользователи могут быть изменены, но сначала вам нужно понять, как информация о пользователях хранится внутри.
Таблицы привилегий
MySQL хранит как информацию о пользователях, так и привилегии в виде записей в таблицах привилегий. Это специальные внутренние таблицы в базе данных mysql, которые в идеале никогда не должны изменяться вручную, а вместо этого неявно изменяются при выполнении таких операторов, как CREATE USER или GRANT. Например, вот немного усеченный вывод запроса SELECT к таблице mysql.user, которая содержит записи пользователей, включая их пароли (в хешированной форме):
mysql> SELECT * FROM user WHERE user = 'root'\G
*************************** 1. row ***************************
Host: localhost
User: root
Select_priv: Y
Insert_priv: Y
Update_priv: Y
Delete_priv: Y
...
Create_routine_priv: Y
Alter_routine_priv: Y
Create_user_priv: Y
Event_priv: Y
Trigger_priv: Y
Create_tablespace_priv: Y
ssl_type:
ssl_cipher: 0x
x509_issuer: 0x
x509_subject: 0x
max_questions: 0
max_updates: 0
max_connections: 0
max_user_connections: 0
plugin: mysql_native_password
authentication_string: *E1206987C3E6057289D6C3208EACFC1FA0F2FA56
password_expired: N
password_last_changed: 2020-09-06 17:20:57
password_lifetime: NULL
account_locked: N
Create_role_priv: Y
Drop_role_priv: Y
Password_reuse_history: NULL
Password_reuse_time: NULL
Password_require_current: NULL
User_attributes: NULL
1 row in set (0.00 sec)
Сразу видно, что многие поля напрямую соответствуют конкретным вызовам операторов CREATE USER или ALTER USER. Например, вы можете видеть, что для этого пользователя root не установлены какие-либо определенные правила, касающиеся жизненного цикла его пароля. Вы также можете увидеть довольно много привилегий, хотя мы опустили некоторые из них для краткости. Это привилегии, для которых не требуется цель, например таблица. Такие привилегии называются глобальными (global). Позже мы покажем вам, как просмотреть целевые привилегии.
Начиная с MySQL 8.0, другие таблицы привилегий:
mysql.user-
Учетные записи пользователей, статические глобальные привилегии и другие непривилегированные столбцы
mysql.global_grants-
Динамические глобальные привилегии
mysql.db-
Привилегии уровня базы данных
mysql.tables_priv-
Привилегии на уровне таблицы
mysql.columns_priv-
Привилегии на уровне столбца
mysql.procs_priv-
Привилегии хранимых процедур и функций
mysql.proxy_priv-
Привилегии прокси-пользователя
mysql.default_roles-
Роли пользователей по умолчанию
mysql.role_edges-
Ребра для подграфов ролей
mysql.password_history-
История смены пароля
Вам не нужно запоминать все эти таблицы, не говоря уже об их структуре и содержании, но вы должны помнить, что они существуют. При необходимости вы можете легко найти необходимую информацию о структуре в документации или в самой базе данных.
Внутренне MySQL кэширует таблицы привилегий в памяти и обновляет это кэшированное представление каждый раз, когда запускается оператор управления учетными записями и, таким образом, изменяет таблицы привилегий. Инвалидация кеша происходит только для конкретного затронутого пользователя. В идеале вы никогда не должны изменять эти таблицы привилегий напрямую, и это редко используется. Однако в том случае, если вам нужно изменить таблицу привилегий, вы можете указать MySQL перечитать их, выполнив команду FLUSH PRIVILEGES. Если этого не сделать, кэш в памяти не будет обновляться до тех пор, пока не будет перезапущена база данных, не будет запущен оператор управления учетными записями для того же пользователя, который был обновлен непосредственно в таблицах привилегий, или пока не будет выполнено FLUSH PRIVILEGES для некоторых других целей. Несмотря на то, что название команды предполагает, что она влияет только на привилегии, MySQL считывает информацию из всех таблиц и обновляет свой кэш в памяти.
Команды управления пользователями и ведение журнала
Есть некоторые прямые последствия того факта, что все команды, которые мы обсуждаем в этой главе, под капотом изменяют таблицы привилегий. В некоторых отношениях они близки к операциям DML. Они атомарны: любая операция CREATE USER, ALTER USER, GRANT или другая подобная операция либо завершается успешно, либо терпит неудачу, фактически не меняя своей цели. Они протоколируются: все изменения, сделанные для предоставления таблиц либо вручную, либо с помощью соответствующих команд, регистрируются в бинарном журнале. Таким образом, они реплицируются (см. главу 13) и также будут доступны для восстановления на определенный момент времени (см. главу 10).
Применение этих операторов к источнику может нарушить репликацию, если целевой пользователь не существует в реплике. Поэтому мы рекомендуем, чтобы ваши реплики согласовывались с их источниками не только в данных, но и в пользователях и других метаданных. Конечно, это только «meta» в том смысле, что она существует вне ваших реальных данных приложения; пользователи являются записями в таблице mysql.user, и это следует помнить при настройке репликации.
В большинстве случаев реплики являются полными копиями своих исходников. В более сложных топологиях, таких как разветвление, это может быть не так, но даже в таких случаях мы рекомендуем поддерживать единообразие пользователей в топологии. В общем, это проще и безопаснее, чем чинить сломанные реплики или вспоминать, нужно ли отключать бинарное логирование перед изменением пользователя.
Хотя мы говорим, что выполнение CREATE USER похоже на INSERT в таблицу mysql.user, само выражение CREATE USER не изменяется никоим образом перед записью в журнал. Это верно для бинарного журнала, журнала медленных запросов (с оговоркой), общего журнала запросов и журналов аудита. То же верно и для любой другой операции, обсуждаемой в этой главе. Предостережение относительно журнала медленных запросов заключается в том, что для регистрации здесь административных операторов необходимо включить дополнительную серверную опцию log_slow_admin_statements.
Рассмотрим следующий пример:
mysql> CREATE USER 'vinicius' IDENTIFIED BY '...';
Query OK, 0 rows affected (0.02 sec)
Вот пример того, как одна и та же команда CREATE USER отражается в общем, медленном запросе и бинарном журнале:
- Общий журнал (General log)
-
2020-11-22T15:53:17.354270Z 29 Query CREATE USER 'vinicius'@'%' IDENTIFIED BY <secret> - Журнал медленных запросов (Slow query log)
-
# Time: 2020-11-22T15:53:17.368010Z # User@Host: root[root] @ localhost [] Id: 29 # Query_time: 0.013772 Lock_time: 0.000161 Rows_sent: 0 Rows_examined: 0 SET timestamp=1606060397; CREATE USER 'vinicius'@'%' IDENTIFIED BY <secret>; - Бинарный журнал (Binary log)
-
#201122 18:53:17 server id 1 end_log_pos 4113 CRC32 0xa12ac622 Query thread_id=29 exec_time=0 error_code=0 Xid = 243 SET TIMESTAMP=1606060397.354238/*!*/; CREATE USER 'vinicius'@'%' IDENTIFIED WITH 'caching_sha2_password' AS '$A$005$|v>\ZKe^R...' /*!*/;
Не волнуйтесь, если вывод бинарного журнала пугает. Он не предназначен для легкого потребления человеком. Однако вы можете видеть, что фактический хэш пароля, как он будет отображаться в mysql.user, записывается в бинарный журнал. Подробнее об этом журнале мы поговорим в главе 10.
Изменение и удаление пользователей
Создание пользователя обычно не заканчивается вашим взаимодействием с ним. Позже вам может понадобиться изменить его свойства, возможно, чтобы потребовать зашифрованное соединение. Бывает и так, что пользователей нужно удалить. Ни одна из этих операций не слишком отличается от создания пользователя, но вам нужно знать, как их выполнять, чтобы полностью понять управление пользователями.
Изменение пользователя
Любой параметр, который можно установить во время создания пользователя, также можно позже изменить. Обычно это достигается с помощью команды ALTER USER. В MySQL версии 5.7 и ранее также были команды RENAME USER и SET PASSWORD, тогда как в версии 8.0 этот список был расширен, включив команду SET DEFAULT ROLE (мы рассмотрим систему ролей в разделе «Роли»). Обратите внимание, что ALTER USER можно использовать для изменения всех сведений о пользователе, а другие команды — это просто удобные способы выполнения общих операций обслуживания.
Мы начнем с обычной команды ALTER USER. В первом примере мы собираемся изменить используемый плагин аутентификации. Многие старые программы не поддерживают новый и стандартный в MySQL 8.0 плагин caching_sha2_password и требуют, чтобы вы либо создавали пользователей, используя старый плагин mysql_native_password, либо изменяли их после создания, чтобы использовать этот плагин. Мы можем проверить текущий используемый плагин, запросив одну из таблиц привилегий (см. «Таблицы привилегий» для получения дополнительной информации о них):
mysql> SELECT plugin FROM mysql.user WHERE
-> user = 'bob' AND host = 'localhost';
+-----------------------+
| plugin |
+-----------------------+
| caching_sha2_password |
+-----------------------+
1 row in set (0.00 sec)
И теперь мы можем изменить плагин для этого пользователя и убедиться, что изменение отражено:
mysql> ALTER USER 'bob'@'localhost' IDENTIFIED WITH mysql_native_password;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT plugin FROM mysql.user WHERE
-> user = 'bob' AND host = 'localhost';
+-----------------------+
| plugin |
+-----------------------+
| mysql_native_password |
+-----------------------+
1 row in set (0.00 sec)
Поскольку изменение было сделано с помощью команды ALTER, нет необходимости запускать FLUSH PRIVILEGES. После успешного выполнения этой команды каждая новая попытка аутентификации будет использовать новый подключаемый модуль. Вы можете изменить запись пользователя напрямую, чтобы внести это изменение, но опять же, мы не рекомендуем этого делать.
Свойства, которые может изменить ALTER USER, довольно многочисленны, и они были объяснены или, по крайней мере, описаны в разделе «Создание и использование новых пользователей». Однако есть некоторые часто требуемые операции, о которых вам следует знать немного больше:
- Изменение пароля пользователя
-
Это, вероятно, самая частая операция, которая выполняется над пользователем. Изменение пароля пользователя может быть выполнено другим пользователем, обладающим необходимыми привилегиями, или любым авторизованным пользователем с помощью следующей команды:
mysql> ALTER USER 'bob'@'localhost' IDENTIFIED by 'new password'; Query OK, 0 rows affected (0.01 sec)Это изменение вступает в силу немедленно, поэтому при следующей аутентификации этого пользователя ему потребуется использовать обновленный пароль. Для этой команды также есть сокращение
SET PASSWORD. Команда может быть выполнена аутентифицированным пользователем без указания цели, например:mysql> SET PASSWORD = 'new password'; Query OK, 0 rows affected (0.01 sec)Или другим пользователем с указанием пользователя, у которого изменяется пароль.
mysql> SET PASSWORD FOR 'bob'@'localhost' = 'new password'; Query OK, 0 rows affected (0.01 sec) - Блокировка и разблокировка пользователя
-
Если вам нужно временно (или навсегда) заблокировать доступ к определенному пользователю, вы можете сделать это с помощью параметра
ACCOUNT LOCKвALTER USER. Пользователь в этом случае блокируется только для аутентификации. Хотя никто не сможет подключиться к MySQL в качестве заблокированного пользователя, его все же можно использовать как в качестве прокси, так и в предложенииDEFINER. Это делает таких пользователей немного более безопасными и более простыми в управлении. ПараметрACCOUNT LOCKтакже может быть использован, например, для блокировки трафика от приложения, подключающегося от имени определенного пользователя, который создает чрезмерную нагрузку.Мы можем заблокировать аутентификацию пользователя
bob, используя следующую команду:mysql> ALTER USER 'bob'@'localhost' ACCOUNT LOCK; Query OK, 0 rows affected (0.00 sec)Будут затронуты только новые соединения. Сообщение, которое MySQL выдает в этом случае, ясно:
$ mysql -ubob -p Enter password: ERROR 3118 (HY000): Access denied for user 'bob'@'localhost'. Account is locked.Аналогом
ACCOUNT LOCKявляетсяACCOUNT UNLOCK. Этот параметрALTER USERделает именно то, что говорит. Давайте снова разрешим доступ дляbob:mysql> ALTER USER 'bob'@'localhost' ACCOUNT UNLOCK; Query OK, 0 rows affected (0.01 sec)Теперь попытка подключения будет успешной:
$ mysql -ubob -p Enter password: mysql>
- Срок действия пароля пользователя
-
Вместо того, чтобы полностью блокировать доступ пользователя или менять для него пароль, вы можете заставить его самого сменить пароль. Это возможно в MySQL с опцией
PASSWORD EXPIREкомандыALTER USER. После выполнения этой команды пользователь по-прежнему сможет подключаться к серверу, используя предыдущий пароль. Однако, как только он запустит запрос из нового соединения, то есть как только его привилегии будут проверены, пользователь получит сообщение об ошибке и будет вынужден сменить пароль. Существующие соединения не затрагиваются.Давайте посмотрим, как это выглядит для пользователя. Во-первых, сама команда:
mysql> ALTER USER 'bob'@'localhost' PASSWORD EXPIRE; Query OK, 0 rows affected (0.01 sec)Теперь о том, что получает пользователь. Обратите внимание на успешную аутентификацию:
$ mysql -ubob -p Enter password: mysql> SELECT id, data FROM bobs_db.bobs_private_table; ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.Несмотря на то, что в сообщении об ошибке указано, что вы должны запустить
ALTER USER, теперь вы знаете, что вместо этого вы можете использоватьSET PASSWORD. Также не имеет значения, кто меняет пароль: рассматриваемый пользователь или другой пользователь. ПараметрPASSWORD EXPIREпросто заставляет изменить пароль. Если другой пользователь изменит пароль, сеансы, аутентифицированные со старым паролем после истечения срока действия пароля, необходимо будет открыть повторно. Как мы видели ранее, аутентифицированный пользователь может изменить пароль без указания пользователя, для которого это делается, и он сможет продолжать свою сессию в обычном режиме (однако новые подключения должны будут аутентифицироваться с новым паролем):mysql> SET PASSWORD = 'new password'; Query OK, 0 rows affected (0.06 sec) mysql> SELECT id, data FROM bobs_db.bobs_private_table; Empty set (0.00 sec)В этом случае вы также должны знать, что без повторного использования пароля и контроля истории пользователь может просто сбросить пароль на исходный.
- Переименование пользователя
-
Смена имени пользователя — относительно нечастая операция, но иногда необходимая. Для этой операции есть специальная команда:
RENAME USER. Для этого требуется привилегияCREATE USERили привилегияUPDATEдля базы данныхmysqlили только для таблиц грантов. Для этой команды нет альтернативыALTER USER.Вы можете изменить как часть «name» имени пользователя, так и часть «host». Поскольку, как вы уже знаете, часть «host» действует как файрволл, будьте осторожны при ее изменении, так как вы можете вызвать сбои (на самом деле, то же самое относится и к части «name»). Давайте переименуем нашего пользователя
bobво что-то более формальное:mysql> RENAME USER 'bob'@'localhost' TO 'robert'@'172.%'; Query OK, 0 rows affected, 1 warning (0.01 sec)Когда имя пользователя изменяется, MySQL автоматически просматривает свои внутренние таблицы, чтобы увидеть, был ли этот пользователь назван в предложении
DEFINERпредставления или сохраненного объекта. Всякий раз, когда это так, выдается предупреждение. Поскольку мы получили предупреждение, когда переименовывалиbob, давайте проверим его:mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Warning Code: 4005 Message: User 'bob'@'localhost' is referenced as a definer account in a stored routine. 1 row in set (0.00 sec)Если не решить эту проблему, потенциально это может привести к потерянным объектам, которые будут вызывать ошибку при доступе или выполнении. Мы подробно обсудим это в следующем разделе.
Удаление пользователя
Заключительной частью жизненного цикла пользователя базы данных является конец его жизни. Как и любой объект базы данных, пользователи могут быть удалены. В MySQL для этого используется команда DROP USER. Это одна из самых простых команд, обсуждаемых в этой главе, а возможно, и во всей книге. DROP USER принимает пользователя или, опционально, список пользователей в качестве аргумента и имеет единственный модификатор: IF NOT EXISTS. Успешное выполнение команды безвозвратно удаляет относящуюся к пользователю информацию из таблиц привилегий (с оговоркой, которую мы обсудим позже) и, таким образом, предотвращает дальнейшие входы в систему.
Если вы удаляете пользователя, который выполнил одно или несколько подключений к базе данных, которая все еще открыта, даже если удаление прошло успешно, связанные записи будут удалены только после завершения последнего из этих подключений. Следующая попытка соединения с данным пользователем приведет к сообщению ERROR 1045 (28000): Access denied message.
Модификатор IF NOT EXISTS работает аналогично CREATE USER: если пользователь, которого вы указываете в команде DROP USER, не существует, ошибка не будет возвращена. Это полезно в автоматических сценариях. Если хост-часть имени пользователя не указана, по умолчанию используется подстановочный знак %.
В самом общем виде команда DROP USER выглядит так:
mysql> DROP USER 'jeff'@'localhost';
Query OK, 0 rows affected (0.02 sec)
Повторное выполнение той же команды приведет к ошибке:
mysql> DROP USER 'jeff'@'localhost';
ERROR 1396 (HY000): Operation DROP USER failed for 'jeff'@'localhost'
Если вы хотите создать идемпотентную команду, которая не приведет к сбою, то вместо этого используйте следующую конструкцию:
mysql> DROP USER IF EXISTS 'jeff'@'localhost';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------+
| Note | 3162 | Authorization ID 'jeff'@'localhost' does not exist. |
+-------+------+-----------------------------------------------------+
1 row in set (0.01 sec)
Опять же, если вы не укажете хостовую часть имени пользователя, MySQL примет значение по умолчанию %. Также можно удалить нескольких пользователей одновременно:
mysql> DROP USER 'jeff', 'bob'@'192.168.%';
Query OK, 0 rows affected (0.01 sec)
В MySQL, поскольку пользователи не владеют объектами, их можно легко удалить без особой подготовки. Однако, как мы уже говорили, пользователи могут выполнять дополнительные роли. Если удаленный пользователь используется в качестве прокси-пользователя или является частью предложения DEFINER какого-либо объекта, то его удаление может привести к созданию потерянной записи. Всякий раз, когда удаляемый вами пользователь является частью таких отношений, MySQL выдает предупреждение. Обратите внимание, что команда DROP USER по-прежнему будет выполнена успешно, поэтому вы должны устранить возникающие несоответствия и исправить все потерянные записи:
mysql> DROP USER 'bob'@'localhost';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Warning
Code: 4005
Message: User 'bob'@'localhost' is referenced as a definer account in a stored routine.
1 row in set (0.00 sec)
Мы рекомендуем вам проверить это, прежде чем фактически удалять пользователя. Если вы не заметите предупреждение и не предпримете никаких действий, объекты останутся потерянными. Осиротевшие объекты будут вызывать ошибки при использовании:
mysql> CALL test.test_proc();
ERROR 1449 (HY000): The user specified as a definer ('bob'@'localhost') does not exist
Для пользователей в прокси-отношениях предупреждение не выдается. Однако последующая попытка использовать проксируемого пользователя приведет к ошибке. Поскольку при аутентификации используются прокси-пользователи, конечным результатом будет невозможность входа в MySQL с пользователями, зависящими от удаленного. Возможно, это может быть более эффективным, чем временная потеря возможности вызывать процедуру или запрашивать представление, но тем не менее предупреждение не выдается. Если вы используете подключаемую аутентификацию, полагаясь на прокси-пользователей, помните об этом.
Если вы оказались в ситуации, когда вы удалили пользователя и неожиданно получили предупреждение, вы можете легко создать пользователя снова, чтобы избежать ошибок. Обратите внимание, как следующая инструкция CREATE USER приводит к уже знакомому предупреждению:
mysql> CREATE USER 'bob'@'localhost' IDENTIFIED BY 'new password';
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Warning
Code: 4005
Message: User 'bob'@'localhost' is referenced as a definer account in a stored routine.
1 row in set (0.00 sec)
Однако проблема здесь в том, что если вы не знаете или не помните первоначальные привилегии учетной записи, новые могут стать проблемой безопасности.
Чтобы идентифицировать потерянные записи, вам нужно вручную просмотреть таблицы каталога MySQL. В частности, вам нужно будет просмотреть столбец DEFINER в следующих таблицах:
mysql> SELECT table_schema, table_name FROM information_schema.columns
-> WHERE column_name = 'DEFINER';
+--------------------+------------+
| TABLE_SCHEMA | TABLE_NAME |
+--------------------+------------+
| information_schema | EVENTS |
| information_schema | ROUTINES |
| information_schema | TRIGGERS |
| information_schema | VIEWS |
+--------------------+------------+
Теперь, когда вы это знаете, вы можете легко создать запрос, чтобы проверить, указан ли пользователь, которого вы собираетесь удалить или уже удалили, в каких-либо предложениях DEFINER:
SELECT EVENT_SCHEMA AS obj_schema
, EVENT_NAME obj_name
, 'EVENT' AS obj_type
FROM INFORMATION_SCHEMA.EVENTS
WHERE DEFINER = 'bob@localhost'
UNION
SELECT ROUTINE_SCHEMA AS obj_schema
, ROUTINE_NAME AS obj_name
, ROUTINE_TYPE AS obj_type
FROM INFORMATION_SCHEMA.ROUTINES
WHERE DEFINER = 'bob@localhost'
UNION
SELECT TRIGGER_SCHEMA AS obj_schema
, TRIGGER_NAME AS obj_name
, 'TRIGGER' AS obj_type
FROM INFORMATION_SCHEMA.TRIGGERS
WHERE DEFINER = 'bob@localhost'
UNION
SELECT TABLE_SCHEMA AS obj_scmea
, TABLE_NAME AS obj_name
, 'VIEW' AS obj_type
FROM INFORMATION_SCHEMA.VIEWS
WHERE DEFINER = 'bob@localhost';
Этот запрос может показаться пугающим, но к настоящему моменту вы уже должны были видеть, что UNION используется в «Объединение (UNION)», и запрос представляет собой просто объединение четырех простых запросов. Каждый отдельный запрос ищет объект со значением DEFINER для bob@localhost в одной из следующих таблиц: EVENTS, ROUTINES, TRIGGERS и VIEWS.
В нашем примере запрос возвращает одну запись для bob@localhost:
+------------+-----------+-----------+
| obj_schema | obj_name | obj_type |
+------------+-----------+-----------+
| test | test_proc | PROCEDURE |
+------------+-----------+-----------+
Точно так же легко проверить, была ли предоставлена привилегия прокси для этого пользователя:
mysql> SELECT user, host FROM mysql.proxies_priv
-> WHERE proxied_user = 'bob'
-> AND proxied_host = 'localhost';
+------+------+
| user | host |
+------+------+
| jeff | % |
+------+------+
Мы рекомендуем всегда проверять наличие потерянных объектов и привилегий прокси-сервера, прежде чем удалять конкретного пользователя. Такие пробелы, оставленные в базе данных, не только вызовут очевидные проблемы (ошибки), но, по сути, представляют угрозу безопасности.
Привилегии
Когда пользователь подключается к серверу MySQL, аутентификация выполняется с использованием имени пользователя и информации о хосте, как объяснялось ранее. Однако разрешения, необходимые пользователю для выполнения различных действий, не проверяются перед выполнением каких-либо команд. MySQL предоставляет привилегии в соответствии с идентификатором подключенного пользователя и выполняемыми им действиями. Как обсуждалось в начале этой главы, привилегии — это наборы разрешений на выполнение действий над различными объектами. По умолчанию пользователь не имеет никаких разрешений, и, следовательно, ему не назначаются привилегии после выполнения CREATE USER.
Существует множество привилегий, которые вы можете предоставить пользователю, а затем отозвать. Например, вы можете разрешить пользователю читать из таблицы или изменять данные в ней. Вы можете предоставить привилегию на создание таблиц и баз данных, а другую — на создание хранимых процедур. Список огромен. Любопытно, что вы нигде не найдете привилегии на подключение: невозможно запретить пользователю подключаться к MySQL, предполагая, что хост-часть имени пользователя совпадает. Это прямое следствие того, что было изложено в предыдущем абзаце: привилегии проверяются только при выполнении действия, поэтому по своей природе они будут применяться только после аутентификации пользователя.
Чтобы получить полный список привилегий, поддерживаемых и предоставляемых вашей установкой MySQL, мы всегда рекомендуем обращаться к руководству. Однако здесь мы рассмотрим несколько широких категорий привилегий. Мы также поговорим об уровнях привилегий, поскольку одни и те же привилегии могут быть разрешены на нескольких уровнях. Собственно, с этого мы и начнем. В MySQL существует четыре уровня привилегий:
- Глобальные привилегии
-
Эти привилегии позволяют получателю (пользователю, которому предоставлена привилегия — мы рассмотрим команду
GRANTв разделе «Команды управления привилегиями») либо воздействовать на каждый объект в каждой базе данных, либо воздействовать на кластер в целом. Последнее относится к командам, которые обычно считаются административными. Например, вы можете разрешить пользователю завершить работу кластера.Привилегии этой категории хранятся в таблицах
mysql.userиmysql.global_grants. В первой хранятся обычные статические привилегии, а во второй — динамические привилегии. Разница объясняется в следующем разделе. Версии MySQL до 8.0 хранят все глобальные привилегии вmysql.user. - Ппривилегии базы данных
-
Привилегии, предоставленные на уровне базы данных, позволят пользователю воздействовать на объекты в этой базе данных. Как вы понимаете, на этом уровне список привилегий уже, так как нет особого смысла разбивать привилегию
SHUTDOWN, например, ниже глобального уровня. Записи для этих привилегий хранятся в таблицеmysql.dbи включают возможность запуска запросов DDL и DML в целевой базе данных. - Привилегии объекта
-
Логическое продолжение привилегий уровня базы данных, они нацелены на конкретный объект. Отслеживаемые в
mysql.tables_priv,mysql.procs_privиmysql.proxies_priv, они соответственно охватывают таблицы и представления, все типы хранимых подпрограмм и, наконец, разрешения пользователей прокси. Привилегии прокси-сервера являются особыми, но другие привилегии в этой категории снова являются обычными разрешениями DDL и DML. - Привилегии столбца
-
Хранящиеся в
mysql.columns_priv, это интересный набор привилегий. Вы можете разделить разрешения внутри конкретной таблицы по столбцам. Например, у отчитывающегося пользователя может не возникнуть необходимости читать столбец пароля в определенной таблице. Это мощный инструмент, но привилегиями столбца может быть сложно управлять и поддерживать их.
Полный список привилегий, честно говоря, очень длинный. Всегда рекомендуется обращаться к документации MySQL для вашей конкретной версии для получения полной информации. Вы должны помнить, что любое действие, которое может выполнить пользователь, либо будет иметь назначенную специальную привилегию, либо будет покрыто привилегией, управляющей более широким диапазоном поведения. Как правило, привилегии уровня базы данных и объекта будут иметь выделенное имя привилегии, которое вы можете предоставить (UPDATE, SELECT и т. д.), а глобальные привилегии будут довольно широко сгруппированы вместе, позволяя выполнять несколько действий одновременно. Например, привилегия GROUP_REPLICATION_ADMIN позволяет выполнять пять различных действий одновременно. Глобальные привилегии также обычно предоставляются на системном уровне (объект . (точка)).
Вы всегда можете получить доступ к списку привилегий, доступных в вашем экземпляре MySQL, выполнив команду SHOW PRIVILEGES:
mysql> SHOW PRIVILEGES;
+----------------------------+----------------------+--------------------+
| Privilege | Context | Comment |
+----------------------------+----------------------+--------------------+
| Alter | Tables | To alter the table |
| Alter routine | Functions,Procedures | ... |
| ... |
| REPLICATION_SLAVE_ADMIN | Server Admin | |
| AUDIT_ADMIN | Server Admin | |
+----------------------------+----------------------+--------------------+
58 rows in set (0.00 sec)
Статические и динамические привилегии
Прежде чем мы перейдем к рассмотрению команд, используемых для управления привилегиями в MySQL, мы должны сделать паузу и поговорить о важном различии. В MySQL, начиная с версии 8.0, есть два типа привилегий: статические и динамические. Статические привилегии встроены в сервер, и они будут доступны при каждой установке. Динамические привилегии, с другой стороны, «изменчивы»: их постоянное присутствие не гарантируется.
Что это за динамические привилегии? Это привилегии, которые регистрируются на сервере во время выполнения. Могут быть предоставлены только зарегистрированные привилегии, поэтому возможно, что некоторые привилегии никогда не будут зарегистрированы и никогда не будут предоставлены. Все это — причудливый способ сказать, что теперь можно расширять привилегии с помощью плагинов и компонентов. Однако большинство доступных в настоящее время динамических привилегий регистрируются по умолчанию в обычной установке Community Server.
Важная роль динамических привилегий, предоставляемых MySQL 8.0, заключается в том, что они направлены на уменьшение необходимости использования привилегии SUPER, которой ранее злоупотребляли (мы поговорим об этой привилегии в следующем разделе). Другое отличие динамических привилегий заключается в том, что они обычно контролируют набор действий, которые могут выполнять пользователи. Например, в отличие от прямой привилегии SELECT для таблицы, которая позволяет только запрашивать данные, привилегия CONNECTION_ADMIN допускает целый список действий. В данном конкретном примере это включает в себя отключение соединений других учетных записей, обновление данных на сервере, доступном только для чтения, подключение через дополнительное соединение при достижении лимита и многое другое. Вы можете легко заметить разницу.
Привилегия SUPER
Этот раздел не длинный, но важный. Мы упоминали в разделе «Пользователь root», что при каждой установке MySQL по умолчанию создается суперпользователь: root@localhost. Иногда вы можете захотеть предоставить те же возможности другому пользователю, например, администратору баз данных. Удобный встроенный способ сделать это — использовать специальную привилегию SUPER.
SUPER — это, по сути, всеобъемлющая привилегия, которая превращает пользователя, которому она назначена, в суперпользователя. Как и любую привилегию, ее можно назначить с помощью оператора GRANT, который мы рассмотрим в следующем разделе.
Однако есть две огромные проблемы с привилегией SUPER. Во-первых, начиная с MySQL 8.0, она устарела и будет удалена в будущем выпуске MySQL. Во-вторых, это кошмар безопасности и эксплуатации. Первый пункт ясен, поэтому давайте поговорим о втором и об альтернативах, которые у нас есть.
Использование привилегии SUPER сопряжено с теми же рисками и приводит к тем же проблемам, что и использование пользователя root@localhost по умолчанию. Вместо тщательного изучения объема требуемых привилегий мы прибегаем к использованию универсального молотка для решения всех проблем. Основная проблема с SUPER — его всеобъемлющий охват. Когда вы создаете суперпользователя, вы создаете ответственность: пользователь должен быть ограничен и в идеале проверен, а операторы и программы, аутентифицирующие пользователя, должны быть предельно точными и осторожными в своих действиях. С большой силой приходит большая ответственность — и, среди прочего, возможность просто полностью завершить работу экземпляра MySQL. Представьте, что вы делаете это по ошибке.
В версиях MySQL до 8.0 невозможно избежать использования привилегии SUPER, поскольку для некоторых разрешений не предусмотрено никаких альтернатив. Начиная с версии 8.0, в которой SUPER объявлен устаревшим, MySQL предоставляет целый набор динамических привилегий, направленных на устранение необходимости в единственной универсальной привилегии. Вы должны стараться избегать использования привилегии SUPER, если это возможно.
Рассмотрим пример пользователя, которому необходимо управлять групповой репликацией. В MySQL 5.7 вам нужно будет предоставить этому пользователю привилегию SUPER. Однако, начиная с версии 8.0, вы можете вместо этого предоставить специальную привилегию GROUP_REPLICATION_ADMIN, которая позволяет пользователям выполнять только очень небольшой набор действий, связанных с групповой репликацией.
Иногда вам все равно понадобится полноценный администратор баз данных, который может делать все что угодно. Вместо предоставления SUPER рассмотрите возможность просмотра привилегий root@localhost и их копирования. Мы покажем вам, как это сделать, в разделе «Проверка привилегий». Продолжая это, вы можете пропустить предоставление некоторых привилегий, таких как привилегия INNODB_REDO_LOG_ENABLE, которая разрешает пользователю в основном включать аварийно-небезопасный режим. Гораздо безопаснее вообще не предоставлять эту привилегию и иметь возможность предоставить ее себе, когда это абсолютно необходимо, чем подвергать риску того, что кто-то по ошибке может запустить это выражение.
Команды управления привилегиями
Теперь, когда вы немного знаете о привилегиях, мы можем перейти к основным командам, которые позволяют вам ими управлять. Вы никогда не сможете использовать ALTER как привилегию самостоятельно, поэтому под контролем привилегий здесь мы подразумеваем предоставление их пользователям и удаление их у пользователей. Эти действия выполняются с помощью операторов GRANT и REVOKE.
GRANT
Оператор GRANT используется для предоставления пользователям (или ролям) разрешений на выполнение действий либо в целом, либо с конкретными объектами. Этот же оператор можно также использовать для назначения ролей пользователям, но вы не можете одновременно изменять разрешения и назначать роли. Чтобы иметь возможность предоставлять разрешение (привилегию), вам необходимо назначить эту привилегию себе и иметь специальную привилегию GRANT OPTION (мы рассмотрим ее позже). Пользователи с привилегией SUPER (или новее CONNECTION_ADMIN) могут предоставлять что угодно, и есть особое условие, связанное с таблицами предоставления, которое мы вскоре обсудим.
А пока давайте проверим базовую структуру оператора GRANT:
mysql> GRANT SELECT ON app_db.* TO 'john'@'192.168.%';
Query OK, 0 row affected (0.01 sec)
Этот оператор после выполнения сообщает MySQL, что пользователю 'john'@'192.168.%' разрешено выполнять запросы только для чтения (SELECT) к любой таблице в базе данных app_db. Обратите внимание, что мы использовали подстановочный знак в спецификации объекта. Мы могли бы разрешить конкретному пользователю доступ к каждой таблице каждой базы данных, указав также подстановочный знак для базы данных:
mysql> GRANT SELECT ON *.* TO 'john';
Query OK, 0 row affected (0.01 sec)
В предыдущем вызове явно отсутствует спецификация хоста для пользователя 'john'. Это сокращение означает 'john'@'%'; таким образом, это не будет тот же пользователь, что и 'john'@'192.168.%', которого мы использовали ранее. Говоря о подстановочных знаках и пользователях, невозможно указать подстановочный знак для имени пользователя. Вместо этого вы можете указать несколько пользователей или ролей за один раз, например:
mysql> GRANT SELECT ON app_db.* TO 'john'@'192.168.%',
-> 'kate'@'192.168.%';
Query OK, 0 row affected (0.06 sec)
Мы предупреждали вас о предоставлении слишком большого количества привилегий в предыдущем разделе, но может быть полезно помнить, что существует команда ALL, который позволяет вам предоставлять все возможные привилегии для объекта или набора объектов. Это может пригодиться, когда вы определяете разрешения для пользователя «owner» (владелец) — например, пользователя приложения для чтения/записи:
mysql> GRANT ALL ON app_db.* TO 'app_db_user';
Query OK, 0 row affected (0.06 sec)
Вы не можете связывать спецификации объектов, поэтому вы не сможете предоставить привилегию SELECT сразу для двух таблиц, если только этот оператор не может быть выражен с использованием подстановочных знаков. Как вы увидите в следующем разделе, вы можете комбинировать гранты с подстановочными знаками и конкретные отзывы для дополнительной гибкости.
Интересное свойство команды GRANT состоит в том, что она не проверяет наличие разрешенных вами объектов. То есть подстановочный знак не расширяется, а остается подстановочным знаком навсегда. Независимо от того, сколько новых таблиц будет добавлено в базу данных app_db, и john, и kate смогут выполнять для них операторы SELECT. Более ранние версии MySQL также создавали пользователя, которому предоставлялись привилегии, если он не был найден в таблице mysql.user, но такое поведение устарело, начиная с MySQL 8.0.
Как мы подробно обсуждали в разделе «Таблицы привилегий», оператор GRANT обновляет таблицы грантов. Одна вещь, которая следует из факта обновления таблиц привилегий, заключается в том, что если у пользователя есть привилегия UPDATE для этих таблиц, этот пользователь может предоставить любой учетной записи любую привилегию. Будьте предельно осторожны с разрешениями на объекты в базе данных mysql: от предоставления пользователям каких-либо привилегий мало пользы. Также обратите внимание, что когда включена системная переменная read_only, любой грант требует привилегий суперпользователя (SUPER или CONNECTION_ADMIN).
Есть еще несколько замечаний, которые мы хотели бы высказать по поводу GRANT, прежде чем двигаться дальше. Во введении к этому разделу мы упомянули привилегии столбца. Этот набор привилегий определяет, может ли пользователь читать и обновлять данные в определенном столбце таблицы. Как и все другие привилегии, их можно разрешить с помощью команды GRANT:
mysql> GRANT SELECT(id), INSERT(id, data)
-> ON bobs_db.bobs_private_table TO 'kate'@'192.168.%';
Query OK, 0 rows affected (0.01 sec)
Пользователь kate теперь сможет выполнить команду SELECT id FROM bobs_db.bobs_private_table, но не SELECT * или SELECT data.
Наконец, вы можете предоставить каждую статическую привилегию для конкретного объекта или глобально, запустив GRANT ALL PRIVILEGES вместо указания каждой привилегии по очереди. ALL PRIVILEGES — это просто сокращение и само по себе не является особой привилегией, в отличие, например, от SUPER.
REVOKE
Оператор REVOKE противоположен оператору GRANT: его можно использовать для отзыва привилегий и ролей, назначенных с помощью GRANT. Если не указано иное, каждое свойство GRANT применяется к REVOKE. Например, для отзыва привилегий вам необходимо иметь привилегию GRANT OPTION и конкретные привилегии, которые вы отзываете.
Начиная с MySQL версии 8.0.16, можно отозвать привилегии для определенных схем у пользователей, которым предоставлены привилегии глобально. Это позволяет легко ограничить доступ к некоторым базам данных, разрешив доступ ко всем другим, в том числе вновь созданным. Например, рассмотрим систему базы данных, в которой у вас есть одна ограниченная схема. Вам необходимо создать пользователя для приложения BI. Вы начинаете с запуска обычной команды:
mysql> GRANT SELECT ON *.* TO 'bi_app_user';
Query OK, 0 rows affected (0.03 sec)
Однако этому пользователю должно быть запрещено запрашивать какие-либо данные в базе данных с ограниченным доступом. Это чрезвычайно легко настроить с помощью частичного отзыва:
mysql> REVOKE SELECT ON restricted_database.* FROM 'bi_app_user';
Query OK, 0 rows affected (0.03 sec)
До версии 8.0.16 для достижения этого вам нужно было вернуться к явному запуску GRANT SELECT для каждой отдельной разрешенной схемы.
Точно так же, как вы можете предоставить все привилегии, существует специальный вызов REVOKE, который позволяет удалить все привилегии у конкретного пользователя. Помните, что вам необходимо иметь все привилегии, которые вы отзываете, и, таким образом, этот параметр, скорее всего, будет использоваться только пользователем с правами администратора. Следующий оператор лишит пользователя его привилегий, включая возможность назначать любые привилегии:
mysql> REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'john'@'192.168.%';
Query OK, 0 rows affected (0.03 sec)
Оператор REVOKE ни при каких обстоятельствах не удаляет самого пользователя. Для этого вы можете использовать оператор DROP USER, как описано ранее в этой главе.
Проверка привилегий
Важной частью управления привилегиями является их просмотр, но было бы невозможно запомнить каждую привилегию, предоставленную каждому пользователю. Вы можете запросить таблицы привилегий, чтобы узнать, какие пользователи имеют какие привилегии, но это не всегда удобно. (Однако это все еще вариант, и это может быть хорошим способом найти, например, каждого пользователя, имеющего права записи в определенной таблице.) Более простой вариант просмотра привилегий, предоставленных конкретному пользователю, — использовать встроенную команду SHOW GRANTS. Давайте посмотрим на это:
mysql> SHOW GRANTS FOR 'john'@'192.168.%';
+--------------------------------------------------+
| Grants for john@192.168.% |
+--------------------------------------------------+
| GRANT UPDATE ON *.* TO `john`@`192.168.%` |
| GRANT SELECT ON `sakila`.* TO `john`@`192.168.%` |
+--------------------------------------------------+
2 rows in set (0.00 sec)
В общем, вы можете ожидать увидеть все привилегии в этом выводе, но есть особый случай. Когда у пользователя есть все статические привилегии, предоставленные для определенного объекта, вместо того, чтобы перечислять каждую из них, MySQL вместо этого выводит ALL PRIVILEGES. Это не особая привилегия сама по себе, а скорее сокращение для всех возможных привилегий. Внутри ALL PRIVILEGES просто преобразуется в Y, установленный для каждой привилегии в соответствующей таблице привилегий:
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+----------------------------------------------------------+
| Grants for bob@localhost |
+----------------------------------------------------------+
...
| GRANT ALL PRIVILEGES ON `bobs_db`.* TO `bob`@`localhost` |
...
Вы также можете просмотреть права, предоставленные ролям, с помощью команды SHOW GRANTS, но об этом подробнее мы поговорим в разделе «Роли». Чтобы просмотреть разрешения текущего аутентифицированного и авторизованного пользователя, вы можете использовать любое из следующих утверждений, которые являются синонимами:
SHOW GRANTS;
SHOW GRANTS FOR CURRENT_USER;
SHOW GRANTS FOR CURRENT_USER();
Всякий раз, когда вы не помните, что означает конкретная привилегия, вы можете либо обратиться к документации, либо запустить команду SHOW PRIVILEGES, которая выведет список всех доступных в настоящее время привилегий. Это касается как привилегий статических объектов, так и привилегий динамического сервера.
Иногда вам может потребоваться просмотреть привилегии, относящиеся ко всем учетным записям, или перенести эти привилегии в другую систему. Один из вариантов, который у вас есть, — это использовать команду mysqldump, поставляемую с сервером MySQL для всех поддерживаемых платформ. Мы подробно рассмотрим эту команду в Главе 10. Короче говоря, вам нужно будет сделать дамп всех таблиц привилегий, иначе вы можете пропустить некоторые разрешения. Самый безопасный способ — сбросить все данные в базу данных mysql:
$ mysqldump -uroot -p mysql
Enter password:
Вывод будет включать все определения таблиц, а также множество операторов INSERT. Этот вывод можно перенаправить в файл, а затем использовать для заполнения новой базы данных. Мы поговорим об этом подробнее в главе 10. Если версии вашего сервера не совпадают или на целевом сервере уже сохранены некоторые пользователи и привилегии, лучше не удалять существующие объекты. Добавьте параметр --no-create-info к вызову mysqldump, чтобы получать только операторы INSERT.
Используя mysqldump, вы получаете переносимый список пользователей и привилегий, но он не совсем удобен для чтения. Вот пример некоторых строк в выводе:
--
-- Dumping data for table `tables_priv`
--
LOCK TABLES `tables_priv` WRITE;
/*!40000 ALTER TABLE `tables_priv` DISABLE KEYS */;
INSERT INTO `tables_priv` VALUES ('172.%','sakila','robert'...
'Select,Insert,Update,Delete,Create,Drop,Grant,References,...
('localhost','sys','mysql.sys','sys_config','root@localhost' '2020-07-13 07:14:57','Select','');
/*!40000 ALTER TABLE `tables_priv` ENABLE KEYS */;
UNLOCK TABLES;Другим вариантом проверки привилегий может быть написание пользовательских запросов к таблицам привилегий, как уже упоминалось. Мы не будем давать никаких рекомендаций по этому поводу, так как не существует универсального решения.
Еще один способ — запустить SHOW GRANTS для каждого пользователя в базе данных. Объединив это с оператором SHOW CREATE USER, вы можете создать список привилегий, который также можно использовать для воссоздания пользователей и их привилегий в другой базе данных:
mysql> SELECT CONCAT("SHOW GRANTS FOR `", user, "`@`", host,
-> "`; SHOW CREATE USER `", user, "`@`", host, "`;") grants
-> FROM mysql.user WHERE user = "bob";
+----------------------------------------------------------------+
| grants
|
+----------------------------------------------------------------+
| SHOW GRANTS FOR bob@%; SHOW CREATE USER bob@%;
|
| SHOW GRANTS FOR bob@localhost; SHOW CREATE USER bob@localhost; |
+----------------------------------------------------------------+
2 rows in set (0.00 sec)
Как вы понимаете, идея автоматизации этой процедуры не нова. На самом деле, в Percona Toolkit есть инструмент — pt-show-grants — который делает именно это и многое другое. К сожалению, этот инструмент официально можно использовать только в Linux и он может вообще не работать на любой другой платформе:
$ pt-show-grants
-- Grants dumped by pt-show-grants
-- Dumped from server Localhost via Unix socket, MySQL 8.0.22 at 2020-12-12 14:32:33
-- Roles
CREATE ROLE IF NOT EXISTS `application_ro`;
-- End of roles listing
...
-- Grants for 'robert'@'172.%'
CREATE USER IF NOT EXISTS 'robert'@'172.%';
ALTER USER 'robert'@'172.%' IDENTIFIED WITH 'mysql_native_password'
AS '*E1206987C3E6057289D6C3208EACFC1FA0F2FA56' REQUIRE NONE
PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT
PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT ALL PRIVILEGES ON `bobs_db`.* TO `robert`@`172.%`;
GRANT ALL PRIVILEGES ON `sakila`.`actor` TO `robert`@`172.%` WITH GRANT OPTION;
GRANT SELECT ON `sakila`.* TO `robert`@`172.%` WITH GRANT OPTION;
GRANT SELECT ON `test`.* TO `robert`@`172.%` WITH GRANT OPTION;
GRANT USAGE ON *.* TO `robert`@`172.%`;
Привилегия GRANT OPTION
Как обсуждалось в начале этой главы, в MySQL нет концепции владения объектами. Таким образом, в отличие от некоторых других систем, тот факт, что какой-то пользователь создал таблицу, не означает автоматически, что этот же пользователь может позволить другому пользователю делать что-либо с этой таблицей. Чтобы сделать это немного менее запутанным, давайте рассмотрим пример.
Предположим, что у пользователя bob есть права на создание таблиц в базе данных с именем bobs_db:
mysql> CREATE TABLE bobs_db.bobs_private_table
-> (id SERIAL PRIMARY KEY, data TEXT);
Query OK, 0 rows affected (0.04 sec)
Оператор, использующий пользователя bob, хочет разрешить пользователю john читать данные во вновь созданной таблице, но, увы, это невозможно:
mysql> GRANT SELECT ON bobs_db.bobs_private_table TO 'john'@'192.168.%';
ERROR 1142 (42000): SELECT, GRANT command denied to user 'bob'@'localhost' for table 'bobs_private_table'
Давайте проверим, какие привилегии на самом деле есть у пользователя bob:
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+----------------------------------------------------------+
| Grants for bob@localhost |
+----------------------------------------------------------+
| GRANT USAGE ON *.* TO `bob`@`localhost` |
| GRANT SELECT ON `sakila`.* TO `bob`@`localhost` |
| GRANT ALL PRIVILEGES ON `bobs_db`.* TO `bob`@`localhost` |
+----------------------------------------------------------+
3 rows in set (0.00 sec)
Недостающая часть здесь — это привилегия, которая позволила бы пользователю предоставлять другим пользователям привилегии, которые ему были предоставлены. Если администратор базы данных хочет разрешить пользователю bob предоставлять другим пользователям доступ к таблицам в базе данных bobs_db, необходимо предоставить дополнительную привилегию. bob не может предоставить это себе, поэтому требуется пользователь с правами администратора:
mysql> GRANT SELECT ON bobs_db.* TO 'bob'@'localhost'
-> WITH GRANT OPTION;
Query OK, 0 rows affected (0.01 sec)
Обратите внимание на дополнение WITH GRANT OPTION. Это именно та привилегия, которую мы искали. Эта опция позволит пользователю bob передавать свои привилегии другим пользователям. Давайте подтвердим это, снова запустив оператор GRANT SELECT от имени пользователя bob:
mysql> GRANT SELECT ON bobs_db.bobs_private_table TO 'john'@'192.168.%';
Query OK, 0 rows affected (0.02 sec)
Как и ожидалось, запрос был принят и выполнен. Однако остается сделать несколько уточнений. Во-первых, мы можем захотеть узнать, насколько детализирована привилегия GRANT OPTION. То есть, что именно (помимо SELECT на bobs_private_table) bob может предоставить другим пользователям? SHOW GRANTS может четко ответить на этот вопрос:
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+----------------------------------------------------------------------------+
| Grants for bob@localhost |
+----------------------------------------------------------------------------+
| GRANT USAGE ON *.* TO `bob`@`localhost` |
| GRANT SELECT ON `sakila`.* TO `bob`@`localhost` |
| GRANT ALL PRIVILEGES ON `bobs_db`.* TO `bob`@`localhost` WITH GRANT OPTION |
+----------------------------------------------------------------------------+
3 rows in set (0.00 sec)
Это намного яснее. Мы видим, что WITH GRANT OPTION применяется к привилегиям, которые bob имеет в конкретной базе данных. Это важно помнить. Несмотря на то, что мы выполнили GRANT SELECT ... WITH GRANT OPTION, bob получил возможность предоставлять все привилегии, которые у него есть в базе данных bobs_db.
Во-вторых, мы можем захотеть узнать, можно ли отозвать только привилегию GRANT OPTION:
mysql> REVOKE GRANT OPTION ON bobs_db.* FROM 'bob'@'localhost';
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+----------------------------------------------------------+
| Grants for bob@localhost |
+----------------------------------------------------------+
| GRANT USAGE ON *.* TO `bob`@`localhost` |
| GRANT SELECT ON `sakila`.* TO `bob`@`localhost` |
| GRANT ALL PRIVILEGES ON `bobs_db`.* TO `bob`@`localhost` |
+----------------------------------------------------------+
3 rows in set (0.00 sec)
Наконец, глядя на то, как можно отозвать GRANT OPTION, мы можем захотеть узнать, может ли он быть предоставлен сам по себе. Ответ — да, с оговоркой, которую мы покажем. Предоставим привилегию GRANT OPTION для доступа к базам данных sakila и test. Как видно из предыдущего вывода, у пользователя bob в настоящее время есть привилегия SELECT для sakila, но нет привилегий для базы данных test:
mysql> GRANT GRANT OPTION ON sakila.* TO 'bob'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT GRANT OPTION ON test.* TO 'bob'@'localhost';
Query OK, 0 rows affected (0.01 sec)
Оба запроса удались. Совершенно ясно, что именно bob может предоставить для sakila привилегию SELECT. Однако менее ясно, что произошло с test. Давайте проверим это:
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+-------------------------------------------------------------------+
| Grants for bob@localhost |
+-------------------------------------------------------------------+
| GRANT USAGE ON *.* TO `bob`@`localhost` |
| GRANT SELECT ON `sakila`.* TO `bob`@`localhost` WITH GRANT OPTION |
| GRANT USAGE ON `test`.* TO `bob`@`localhost` WITH GRANT OPTION |
| GRANT ALL PRIVILEGES ON `bobs_db`.* TO `bob`@`localhost` |
+-------------------------------------------------------------------+
4 rows in set (0.00 sec)
Итак, привилегия GRANT OPTION сама по себе дает пользователю только привилегию USAGE, которая является спецификатором «без привилегий». Однако привилегию GRANT OPTION можно рассматривать как переключатель, и когда она «включена», она будет применяться к привилегиям, предоставленным пользователю bob в базе данных test:
mysql> GRANT SELECT ON test.* TO 'bob'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+-------------------------------------------------------------------+
| Grants for bob@localhost |
+-------------------------------------------------------------------+
...
| GRANT SELECT ON `test`.* TO `bob`@`localhost` WITH GRANT OPTION |
...
+-------------------------------------------------------------------+
4 rows in set (0.00 sec)
До сих пор мы использовали привилегии с подстановочными знаками, но можно включать GRANT OPTION для конкретной таблицы:
mysql> GRANT INSERT ON sakila.actor
-> TO 'bob'@'localhost' WITH GRANT OPTION;
Query OK, 0 rows affected (0.01 sec)
mysql> SHOW GRANTS FOR 'bob'@'localhost';
+-------------------------------------------------------------------------+
| Grants for bob@localhost |
+-------------------------------------------------------------------------+
...
| GRANT INSERT ON `sakila`.`actor` TO `bob`@`localhost` WITH GRANT OPTION |
+-------------------------------------------------------------------------+
5 rows in set (0.00 sec)
К настоящему моменту должно быть ясно, что GRANT OPTION — мощное дополнение к системе привилегий. Учитывая, что в MySQL отсутствует концепция владения, это единственный способ убедиться, что пользователи, не являющиеся суперпользователями, могут предоставлять друг другу разрешения. Однако также важно, как всегда, помнить, что GRANT OPTION применяется ко всем разрешениям, которые есть у пользователя.
Роли
Роли, представленные в MySQL 8.0, представляют собой наборы привилегий. Они упрощают управление пользователями и привилегиями за счет группировки и «контейнеризации» необходимых разрешений. У вас может быть несколько разных пользователей DBA, которым нужны одинаковые разрешения. Вместо того, чтобы предоставлять привилегии индивидуально каждому из пользователей, вы можете создать роль, предоставить разрешения для этой роли и назначить эту роль пользователям. При этом вы также упрощаете управление, поскольку вам не нужно будет обновлять каждого пользователя по отдельности. Если вашим администраторам баз данных потребуется настроить свои привилегии, вы можете просто настроить роль.
Роли очень похожи на пользователей в том, как они создаются, хранятся и управляются. Чтобы создать роль, вам необходимо выполнить оператор CREATE ROLE [IF NOT EXISTS] role1[, role2[, role3 ...]]. Чтобы удалить роль, выполните оператор DROP ROLE [IF EXISTS] role1[, role2[, role3 ...]]. Когда вы удаляете роль, назначения этой роли всем пользователям удаляются. Привилегии, необходимые для создания роли: CREATE ROLE или CREATE USER. Чтобы удалить роль, требуется привилегия DROP ROLE или DROP USER. Как и в случае с командами управления пользователями, если установлен параметр read_only, для создания и удаления ролей дополнительно требуются права администратора. Привилегии прямого изменения таблиц привилегий позволяют пользователю изменять что угодно, как мы уже обсуждали.
Как и имена пользователей, имена ролей состоят из двух частей: самого имени и спецификации хоста. Если хост не указан, предполагается подстановочный знак %. Спецификация хоста для роли никоим образом не ограничивает ее использование. Причина в том, что роли хранятся точно так же, как и пользователи в таблице привилегий mysql.user. Как следствие, вы не можете иметь то же rolename@host, что и у существующего пользователя. Чтобы иметь роль с тем же именем, что и у существующего пользователя, укажите для роли другое имя хоста.
В отличие от привилегий, роли не активны постоянно. Когда пользователю предоставляется роль, он имеет право использовать эту роль, но не обязан это делать. На самом деле у пользователя может быть несколько ролей, и он может «включить» одну или несколько из них в рамках одного соединения.
Одна или несколько ролей могут быть назначены пользователю по умолчанию во время его создания или позже с помощью команды ALTER USER. Такие роли будут активны, как только пользователь будет аутентифицирован.
Давайте рассмотрим команды, настройки и терминологию, связанные с управлением ролями:
- Команды
GRANT PRIVILEGEиREVOKE PRIVILEGE -
Мы рассмотрели эти команды в разделе «Команды управления привилегиями». Во всех смыслах и целях роли можно использовать точно так же, как пользователей с командами
GRANTиREVOKE PRIVILEGE. То есть вы можете назначить роли все те же привилегии, что и пользователю, и отозвать их тоже. GRANT role [, role ...]команде пользователя-
Основная команда, связанная с управлением ролями. Выполняя эту команду, вы разрешаете пользователю выполнять определенную роль. Как упоминалось ранее, пользователь не обязан использовать роль. Давайте создадим пару ролей, которые смогут работать с базой данных
sakila:mysql> CREATE ROLE 'application_rw'; Query OK, 0 rows affected (0.01 sec) mysql> CREATE ROLE 'application_ro'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT ALL ON sakila.* TO 'application_rw'; Query OK, 0 rows affected (0.06 sec) mysql> GRANT SELECT ON sakila.* TO 'application_ro'; Query OK, 0 rows affected (0.00 sec)Теперь вы можете назначать эти роли произвольному количеству пользователей и менять роли только при необходимости. Здесь мы разрешаем нашему пользователю
bobдоступ только для чтения к базе данныхsakila:mysql> GRANT 'application_ro' TO 'bob'@'localhost'; Query OK, 0 rows affected (0.00 sec)Вы также можете предоставить более одной роли в одном операторе.
- Модификатор
WITH ADMIN OPTION -
Когда вы предоставляете роль пользователю, этому пользователю разрешается только активировать роль, но не изменять ее каким-либо образом. Этот пользователь не может предоставлять роль любому другому пользователю. Если вы хотите разрешить пользователю как изменять роль, так и предоставлять ее другим пользователям, вы можете указать
WITH ADMIN OPTIONв командеGRANT ROLE. Результат будет отражен в таблицах привилегий и будет виден в выводе командыSHOW GRANTS:mysql> SHOW GRANTS FOR 'bob'@'localhost'; +-------------------------------------------------------------------+ | Grants for bob@localhost | +-------------------------------------------------------------------+ | GRANT USAGE ON *.* TO `bob`@`localhost` | | GRANT `application_ro`@`%` TO `bob`@`localhost` WITH ADMIN OPTION | +-------------------------------------------------------------------+ 2 rows in set (0.00 sec) SHOW GRANTSи роли-
Команда
SHOW GRANTS, которую мы представили в разделе «Проверка привилегий», способна показать вам как назначенные роли, так и действующие разрешения с одной или несколькими активированными ролями. Это возможно, если добавить необязательный модификаторUSING role. Здесь мы показываем действующие привилегии, которые будут у пользователяbob, как только будет активирована рольapplication_ro:mysql> SHOW GRANTS FOR 'bob'@'localhost' USING 'application_ro'; +-------------------------------------------------------------------+ | Grants for bob@localhost | +-------------------------------------------------------------------+ | GRANT USAGE ON *.* TO `bob`@`localhost` | | GRANT SELECT ON `sakila`.* TO `bob`@`localhost` | | GRANT `application_ro`@`%` TO `bob`@`localhost` WITH ADMIN OPTION | +-------------------------------------------------------------------+ 3 rows in set (0.00 sec) - Команда
SET ROLE DEFAULT | NONE | ALL | ALL EXCEPT role [, role1 ...] | role [, role1 ...] -
Команда управления ролью
SET ROLEвызывается аутентифицированным пользователем, чтобы назначить себе определенную роль или роли. После того, как роль установлена, ее разрешения применяются к пользователю. Давайте продолжим наш пример для пользователяbob:$ mysql -ubob mysql> SELECT staff_id, first_name FROM sakila.staff; ERROR 1142 (42000): SELECT command denied to user 'bob'@'localhost' for table 'staff' mysql> SET ROLE 'application_rw'; ERROR 3530 (HY000): `application_rw`@`%` is not granted to `bob`@`localhost` mysql> SET ROLE 'application_ro'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT staff_id, first_name FROM sakila.staff; +----------+------------+ | staff_id | first_name | +----------+------------+ | 1 | Mike | | 2 | Jon | +----------+------------+ 2 rows in set (0.00 sec)Только когда роль назначена,
bobможет использовать свои привилегии. Обратите внимание, что вы не можете использоватьSET ROLE, чтобы назначить себе роль, на использование которой вы не авторизованы (черезGRANT ROLE).Команды
UNSET ROLEнет, но есть несколько других расширенийSET ROLE, допускающих такое поведение. Чтобы отключить каждую роль, запуститеSET ROLE NONE. Пользователь также может вернуться к своему набору ролей по умолчанию, выполнивSET ROLE DEFAULT, или активировать все роли, к которым у него есть доступ, выполнивSET ROLE ALL. Если вам нужно установить подмножество ролей, которое не является ни значением по умолчанию, ни всеми, вы можете создать операторSET ROLE ALL EXCEPT role [, role1 ...]и явно избежать задания одной или нескольких ролей. - Параметр пользователя
DEFAULT ROLE -
Когда вы запускаете
CREATE USERили позже черезALTER USER, вы можете установить одну или несколько ролей по умолчанию для определенного пользователя. Эти роли будут неявно установлены после аутентификации пользователя, что избавит вас от оператораSET ROLE. Это удобно, например, для пользователей приложения, которые большую часть времени используют одну роль или известный набор ролей. Давайте установимapplication_roкак роль по умолчанию для пользователяbob:$ mysql -uroot mysql> ALTER USER 'bob'@'localhost' DEFAULT ROLE 'application_ro'; Query OK, 0 rows affected (0.02 sec) $ mysql -ubob mysql> SELECT CURRENT_ROLE(); +----------------------+ | CURRENT_ROLE() | +----------------------+ | `application_ro`@`%` | +----------------------+ 1 row in set (0.00 sec)Как только
bob@localhostвойдет в систему, функцияCURRENT_ROLE()вернет желаемоеapplication_ro. - Обязательные роли
-
Каждому пользователю в базе данных можно неявно предоставить одну или несколько ролей. Это достигается установкой системного параметра
required_roles(глобального по объему и динамического) в список ролей. Роли, предоставленные таким образом, не активируются до тех пор, пока не будет запущена командаSET ROLE. Отменить назначенные таким образом роли невозможно, но вы можете явно предоставить их пользователю. Роли, перечисленные вrequired_roles, нельзя удалить, пока они не будут удалены из настройки. - Автоматическая активация ролей
-
По умолчанию роли не активны до тех пор, пока не будет выполнена команда
SET ROLE. Однако это поведение можно переопределить и автоматически активировать каждую роль, доступную пользователю после аутентификации. Это аналогично запускуSET ROLE ALLпри входе в систему. Это поведение можно включить или отключить (по умолчанию), изменив системный параметрenable_all_roles_on_login(глобальный и динамический). Если для параметраenable_all_roles_on_loginустановлено значениеON, для каждого пользователя будут активированы предоставленные роли как явно, так и неявно (черезmandatory_roles). - Каскадные разрешения ролей
-
Роли могут быть предоставлены ролям. Затем происходит то, что все разрешения предоставленной роли наследуются ролью получателя. Как только роль получателя активируется пользователем, вы можете считать, что этот пользователь активировал предоставленную роль. Давайте немного усложним наш пример. У нас будет роль приложения, которой предоставлены роли
application_roиapplication_rw. Сама рольapplicationне имеет прямого назначения разрешений. Мы назначим рольapplicationнашему пользователюbobи изучим результат:mysql> CREATE ROLE 'application'; Query OK, 0 rows affected (0.01 sec) mysql> GRANT 'application_rw', 'application_ro' TO 'application'; Query OK, 0 rows affected (0.01 sec) mysql> REVOKE 'application_ro' FROM 'bob'@'localhost'; Query OK, 0 rows affected (0.02 sec) mysql> GRANT 'application' TO 'bob'@'localhost'; Query OK, 0 rows affected (0.00 sec)Что происходит сейчас, так это то, что когда
bobактивирует рольapplication, у него будут разрешения обеих ролейrwиro. Мы можем легко убедиться в этом. Обратите внимание, чтоbobне может активировать ни одну из ролей, которые ему были предоставлены косвенно:$ mysql -ubob mysql> SET ROLE 'application'; Query OK, 0 rows affected (0.00 sec) mysql> SELECT staff_id, first_name FROM sakila.staff; +----------+------------+ | staff_id | first_name | +----------+------------+ | 1 | Mike | | 2 | Jon | +----------+------------+ 2 rows in set (0.00 sec) - Графическое отображение ролей
-
Поскольку роли могут быть предоставлены ролям, результирующая иерархия может быть довольно сложной для понимания. Вы можете ознакомиться с ней, изучив таблицу привилегий
mysql.role_edges:mysql> SELECT * FROM mysql.role_edges; +-----------+----------------+-----------+-------------+----------------+ | FROM_HOST | FROM_USER | TO_HOST | TO_USER | WITH_ADMIN_... | +-----------+----------------+-----------+-------------+----------------+ | % | application | localhost | bob | N | | % | application_ro | % | application | N | | % | application_rw | % | application | N | | % | developer | 192.168.% | john | N | | % | developer | localhost | bob | N | | 192.168.% | john | % | developer | N | +-----------+----------------+-----------+-------------+----------------+ 6 rows in set (0.00 sec)Для более сложных иерархий MySQL удобно включает встроенную функцию, позволяющую генерировать XML-документ в допустимом формате GraphML. Вы можете использовать любое подходящее программное обеспечение для визуализации вывода. Вот вызов функции и результирующий сильно отформатированный вывод (XML плохо работает в книгах):
mysql> SELECT * FROM mysql.roles_graphml()\G *************************** 1. row *************************** roles_graphml(): <?xml version="1.0" encoding="UTF-8"?> <graphml xmlns="... ... <node id="n0"> <data key="key1">`application`@`%`</data> </node> <node id="n1"> <data key="key1">`application_ro`@`%`</data> </node> ...В идеале следует использовать
SELECT ... INTO OUTFILE(см. «Запись данных в файлы с разделителями-запятыми»). Затем вы можете использовать такой инструмент, как графический редактор yEd, который представляет собой мощное кроссплатформенное бесплатное настольное приложение, для визуализации этого вывода. На рисунке 8-1 вы можете увидеть увеличенную часть полного графика, в которой основное внимание уделяется нашему пользователюbobи окружающим его ролям. Для запуска этой функции требуется привилегияROLE_ADMIN.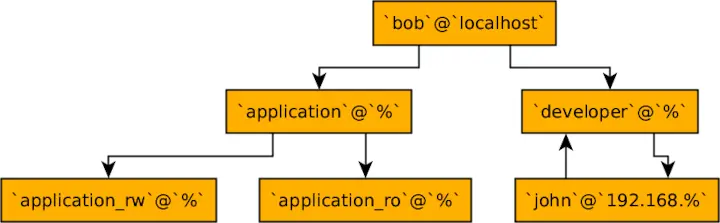
Рисунок 8-1. Раздел визуализированного графа ролей MySQL
- Различия между ролями и пользователями
-
Ранее мы упоминали, что привилегии
CREATE USERиDROP USERпозволяют изменять роли. Учитывая, что роли хранятся вместе с пользователями вmysql.user, вы также можете предположить, что обычные команды управления пользователями будут работать для ролей. Это легко проверить и подтвердить: просто запуститеRENAME USERилиDROP USERдля роли. Еще одна вещь, на которую стоит обратить внимание, это то, как командыGRANTиREVOKE PRIVILEGEнацелены на роли, как если бы они были пользователями.Роли — это, по сути, обычные пользователи. На самом деле можно использовать
GRANT ROLE, чтобы предоставить разблокированного пользователя другому разблокированному пользователю или роли:mysql> CREATE ROLE 'developer'; Query OK, 0 rows affected (0.02 sec) mysql> GRANT 'john'@'192.168.%' TO 'developer'; Query OK, 0 rows affected (0.01 sec) mysql> SELECT from_user, to_user FROM mysql.role_edges; +-----------+-----------+ | from_user | to_user | +-----------+-----------+ | john | developer | +-----------+-----------+ 1 row in set (0.00 sec)Роли являются мощным и гибким дополнением к системе пользователей и привилегий MySQL. Как и практически с любой функцией, ими можно злоупотреблять, что приводит к излишне сложной иерархии, которой будет трудно следовать. Однако, если вы будете придерживаться простоты, роли могут сэкономить вам много работы.

Изменение пароля root и небезопасный запуск
Иногда может возникнуть необходимость получить доступ к экземпляру MySQL, не зная пароля пользователя. Или же вы можете случайно удалить всех пользователей из базы данных, что фактически заблокирует вас. MySQL предоставляет обходной путь в таких ситуациях, но требует, чтобы вы могли изменить его конфигурацию и перезапустить соответствующий экземпляр. Вы можете подумать, что это сомнительно или опасно, но на самом деле это просто защита от одной из самых простых проблем, с которыми сталкиваются администраторы баз данных: забытых паролей. Просто представьте, что у вас есть рабочий экземпляр, у которого нет доступа суперпользователя: это, очевидно, нежелательно. К счастью, при необходимости можно обойти авторизацию.
Чтобы выполнить обход аутентификации и привилегий, вы должны перезапустить экземпляр MySQL с указанной опцией --skip-grant-tables. Поскольку в большинстве установок для запуска экземпляра используются служебные сценарии, вы можете указать skip-grant-tables в файле конфигурации my.cnf в разделе [mysqld]. Когда mysqld запускается в этом режиме, он (очевидно) пропускает чтение таблиц разрешений, что имеет следующие последствия:
-
Аутентификация не выполняется; таким образом, нет необходимости знать какие-либо имена пользователей или пароли.
-
Никакие привилегии не загружаются, и никакие разрешения не проверяются.
-
MySQL неявно установит
--skip-networkingдля предотвращения любого доступа, кроме локального, пока он работает в небезопасной конфигурации.
Когда вы подключаетесь к экземпляру MySQL, работающему с параметром --skip-grant-tables, вы авторизуетесь как специальный пользователь. Этот пользователь имеет доступ к каждой таблице и может изменить любого пользователя. Прежде чем изменить, например, утерянный пароль пользователя root, вам нужно запустить FLUSH PRIVILEGES; в противном случае ALTER завершится ошибкой:
mysql> SELECT current_user();
+-----------------------------------+
| current_user() |
+-----------------------------------+
| skip-grants user@skip-grants host |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'P@ssw0rd!';
ERROR 1290 (HY000): The MySQL server is running with the --skip-grant-tables option so it cannot execute this statement
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.02 sec)
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'P@ssw0rd!';
Query OK, 0 rows affected (0.01 sec)
После сброса пароля рекомендуется перезапустить экземпляр MySQL в обычном режиме.
Есть еще один способ восстановить пароль root, возможно, более безопасный. Одним из многочисленных аргументов командной строки, которые принимает mysqld, является --init-file (или init_file, если используется через my.cnf). Этот аргумент указывает путь к файлу, содержащему некоторые операторы SQL, которые будут выполняться во время запуска MySQL. В это время проверка привилегий не выполняется, поэтому можно ввести здесь инструкцию ALTER USER root. Рекомендуется удалить файл и отключить параметр, как только вы восстановите доступ или создадите нового пользователя root.
Некоторые идеи для безопасной установки
В этой главе мы описали несколько приемов, связанных с управлением пользователями и привилегиями, которые могут помочь сделать ваш сервер более безопасным и безопасным. Здесь мы представим краткий обзор этих методов и наши рекомендации по их использованию.
С административной стороны у нас есть следующие рекомендации:
-
Избегайте чрезмерного использования встроенного суперпользователя
root@localhost. Представьте пять человек, имеющих доступ к этому пользователю. Даже если у вас включен аудит в MySQL, вы не сможете эффективно определить, какой конкретный человек обращался к пользователю и когда. Этот пользователь также будет первым, кого попытаются использовать потенциальные злоумышленники. -
Начиная с MySQL 8.0, избегайте создания новых суперпользователей с помощью привилегии
SUPER. Вместо этого вы можете создать специальную роль администратора баз данных, которой будут назначены либо все динамические привилегии по отдельности, либо только некоторые из них, которые часто требуются. -
Рассмотрите возможность организации привилегий для функций DBA в отдельные роли. Например, привилегии
INNODB_REDO_LOG_ARCHIVEиINNODB_REDO_LOG_ENABLEмогут быть частью ролиinnodb_redo_admin. Поскольку роли по умолчанию не активируются автоматически, сначала необходимо явно задатьSET ROLE, прежде чем запускать потенциально опасные административные команды.
Для обычных пользователей рекомендации примерно такие же:
-
Постарайтесь свести к минимуму объем разрешений. Всегда спрашивайте, нужен ли этому пользователю доступ ко всем базам данных в кластере или даже к каждой таблице в конкретной базе данных.
-
В MySQL 8.0 использование ролей является удобным и, возможно, более безопасным способом группировки и управления привилегиями. Если у вас есть три пользователя, которым нужны одинаковые или похожие привилегии, они могут использовать одну роль.
-
Никогда не разрешайте никакие разрешения на изменение таблиц в базе данных
mysqlбез прав суперпользователя. Это простая ошибка, вытекающая из первой рекомендации в этом списке. ПредоставлениеUPDATEдля*.*позволит получателю предоставлять себе любые разрешения. -
Чтобы сделать вещи еще более безопасными и видимыми, вы можете периодически сохранять все привилегии, назначенные в настоящее время пользователям, и сравнивать результат с ранее сохраненным образцом. Вы можете легко сравнить вывод
pt-show-grantsили даже выводmysqldump.
Завершив эту главу, вы должны освоиться с администрированием пользователей и привилегий в MySQL.
Глава 9
Использование файлов параметров
Почти каждое программное обеспечение может быть сконфигурировано или даже должно быть обязательно сконфигурировано. MySQL не сильно отличается в этом отношении. Хотя конфигурация по умолчанию, вероятно, подойдет для поразительного количества установок, скорее всего, вам потребуется настроить сервер или клиент. MySQL предоставляет два способа настройки себя: с помощью параметров аргументов командной строки и с помощью файла конфигурации. Поскольку этот файл содержит только параметры, которые можно указать в командной строке, он также называется файлом параметров.
Файл параметров не является эксклюзивным для MySQL Server. Также не совсем корректно говорить о файле параметров, так как почти каждая установка MySQL будет иметь несколько файлов параметров. Большинство программ MySQL поддерживает включение в файлы параметров, и мы рассмотрим и это.
Знание того, как обращаться с файлом параметров — понимание его разделов и приоритета опций — важная часть эффективной работы с MySQL Server и связанным программным обеспечением. Прочитав эту главу, вы сможете чувствовать себя комфортно при настройке сервера MySQL и других программ, использующих файлы параметров. В этой главе основное внимание будет уделено самим файлам. Конфигурация самого сервера и некоторые идеи настройки подробно обсуждаются в главе 11.
Структура файла параметров
Файлы конфигурации в MySQL следуют повсеместно распространенной файловой схеме INI. Короче говоря, это обычные текстовые файлы, предназначенные для редактирования вручную. Конечно, вы можете автоматизировать процесс редактирования, но структура этих файлов намеренно очень проста. Почти каждый файл конфигурации MySQL можно создать и изменить с помощью любого текстового редактора. Есть только два исключения из этого правила, рассмотренные в «Специальных файлах параметров».
Чтобы дать вам представление о файловой структуре, давайте взглянем на файл конфигурации, поставляемый с MySQL 8 в Fedora Linux (обратите внимание, что точное содержимое файлов параметров в вашей системе может отличаться). Мы отредактировали несколько строк для краткости:
$ cat /etc/my.cnf
...
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
...
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
log-error=/var/log/mysqld.log
pid-file=/run/mysqld/mysqld.pid
В файловой структуре есть несколько основных частей:
- Заголовки разделов (групп)
-
Это значения в квадратных скобках перед параметрами конфигурации. Все программы, использующие файлы параметров, ищут параметры в одном или нескольких именованных разделах. Например,
[mysqld]— это раздел, используемый сервером MySQL, а[mysql]— использует программа интерфейса командной строкиmysql. Названия разделов, строго говоря, произвольны, и туда можно поместить что угодно. Однако, если вы измените[mysqld]на[section], ваш сервер MySQL будет игнорировать все параметры, следующие за этим заголовком.В документации MySQL разделы (sections) называются группами (groups), но оба термина могут использоваться взаимозаменяемо.
Заголовки управляют тем, как анализируются файлы и какими программами. Каждая опция после заголовка раздела и перед заголовком следующего раздела будет относиться к первому заголовку. Пример сделает это более понятным:
[mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock [mysql] default-character-set=latin1Здесь параметры
datadirиsocketнаходятся (и будут атрибутированы) в разделе[mysqld], тогда как параметрdefault-character-setнаходится в разделе[mysql]. Обратите внимание, что некоторые программы MySQL читают несколько разделов; но мы поговорим об этом позже.Заголовки разделов могут переплетаться. Следующий пример полностью верен:
[mysqld] datadir=/var/lib/mysql [mysql] default-character-set=latin1 [mysqld] socket=/var/lib/mysql/mysql.sock [mysqld_safe] core-file-size=unlimited [mysqld] core-fileЧеловеку может быть трудно читать такую конфигурацию, но программам, анализирующим файл, порядок не важен. Тем не менее, вероятно, лучше сделать файлы конфигурации максимально удобными для восприятия человеком.
- Пары «опция-значение»
-
Это основная часть файла параметров, состоящая из самих переменных конфигурации и их значений. Каждая из этих пар определяется на новой строке и соответствует одному из двух общих шаблонов. В дополнение к шаблону
option=value, показанному в предыдущем примере, есть еще только шаблонoption. Например, в том же стандартном конфигурационном файле MySQL 8 есть следующие строки:# Remove the leading "# " to disable binary logging # Binary logging captures changes between backups and is enabled by # default. Its default setting is log_bin=binlog # disable_log_bindisable_log_bin— это опция без значения. Если мы раскомментируем ее, MySQL Server применит эту опцию.При использовании шаблона
option=valueвы можете добавить пробелы вокруг знака равенства для удобства чтения, если хотите. Любые пробелы, предшествующие и следующие за именем и значением параметра, будут автоматически обрезаны.Значения параметров также могут быть заключены в одинарные или двойные кавычки. Это полезно, если вы не уверены, будет ли значение правильно интерпретировано. Например, в Windows пути содержат символ
\, который рассматривается как escape-символ. Таким образом, вы должны помещать пути в Windows в двойные кавычки (хотя вы также можете экранировать каждый символ\, удвоив его как\\). Заключение значений параметра в кавычки требуется, когда значение включает символ#, который в противном случае рассматривался бы как указание на начало комментария.Эмпирическое правило, которое мы рекомендуем, заключается в использовании кавычек, когда вы не уверены. Вот несколько допустимых пар опций/значений, которые иллюстрируют предыдущие пункты:
slow_query_log_file = "C:\mysqldata\query.log" slow_query_log_file=C:\\mysqldata\\query.log innodb_temp_tablespaces_dir="./#innodb_temp/"При установке значений числовых параметров, таких как размеры различных буферов и файлов, работа с байтами может стать утомительной. Чтобы упростить жизнь, MySQL понимает множество суффиксов, обозначающих разные единицы измерения. Например, все приведенные ниже значения эквивалентны и определяют пул буферов одинакового размера (268 435 456 байт):
innodb_buffer_pool_size = 268435456 innodb_buffer_pool_size = 256M innodb_buffer_pool_size = 256MB innodb_buffer_pool_size = 256MiBВы также можете указать
G,GBиGiBдля гигабайт иT,TBиTiBдля терабайт, если у вас достаточно большой сервер. Конечно,Kи другие формы также принимаются. MySQL всегда использует единицы измерения с основанием 2: 1 ГБ равен 1024 МБ, а не 1000 МБ.Вы не можете указывать дробные значения для опций. Так, например,
0.25G— неверное значение для переменнойinnodb_buffer_pool_size. Кроме того, в отличие от установки значений из интерфейса командной строкиmysqlили другого клиентского соединения, вы не можете использовать математическую запись для значений параметров. Вы можете запуститьSET GLOBAL max_heap_table_size=16*1024*1024;, но вы не можете поместить то же значение в файл опций.Вы даже можете настроить одну и ту же опцию несколько раз, как мы сделали с
innodb_buffer_pool_size. Последняя настройка будет иметь приоритет над предыдущими, а файлы сканируются сверху вниз. Файлы параметров также имеют глобальный порядок приоритета; мы поговорим об этом в разделе «Порядок поиска файлов параметров».Очень важно помнить, что установка неправильного имени опции приведет к тому, что программы не запустятся. Конечно, если неправильный вариант находится в разделе, который конкретная программа не читает, это нормально. Но
mysqldпотерпит неудачу, если обнаружит неизвестный параметр в[mysqld]. В MySQL 8.0 вы можете проверить некоторые изменения, которые вы делаете в файлах параметров, используя аргумент командной строки--validate-configсmysqld. Однако эта проверка будет охватывать только основные функции сервера и не будет проверять параметры механизма хранения.Иногда вам нужно установить параметр, который MySQL не знает во время запуска. Например, это может быть полезно при настройке плагинов, которые могут загружаться после запуска. Вы можете добавить к таким опциям префикс
loose-(или--loose-в командной строке), и MySQL выдаст предупреждение только когда увидит их, но не откажет в запуске.. Вот пример с неизвестной опцией:# mysqld --validate-config 2021-02-11T08:02:58.741347Z 0 [ERROR] [MY-000067] [Server] ... ... unknown variable audit_log_format=JSON. 2021-02-11T08:02:58.741470Z 0 [ERROR] [MY-010119] [Server] AbortingПосле того, как параметр изменен на
loose-audit_log_format, вместо этого мы видим следующее. Отсутствие вывода означает, что все параметры были успешно проверены:# mysqld --validate-config # - Комментарии
-
Часто упускаемая из виду, но важная особенность файлов параметров MySQL — возможность добавлять комментарии. Комментарии позволяют вам включать произвольный текст, обычно описание того, почему параметр находится здесь, который не будет анализироваться никакими программами MySQL. Как вы видели в примере с
disable_log_bin, комментарии — это строки, начинающиеся с#. Вы также можете создавать комментарии, начинающиеся с точки с запятой (;); принимаются любые комментарии. Вам не обязательно выделять целую строку для комментария: они также могут появляться в конце строки, хотя в этом случае они должны начинаться с#, а не с;. Как только MySQL находит#в строке (если он не экранирован), всё, что находится за этой точкой, рассматривается как комментарий. Следующая строка является допустимой конфигурацией:innodb_buffer_pool_size = 268435456 # 256M - Директивы включения
-
Файлы конфигурации (и целые каталоги) могут быть включены в другие файлы конфигурации. Это может упростить управление сложными конфигурациями, но также затруднит чтение параметров, поскольку люди, в отличие от программ, не могут легко объединять файлы вместе. Тем не менее, полезно иметь возможность разделять конфигурации различных программ MySQL. Утилита
xtrabackup(см. главу 10), например, не имеет специального конфигурационного файла и считывает стандартные системные файлы настроек. Благодаря включению вы можете аккуратно упорядочить конфигурацииxtrabackupв специальном файле и навести порядок в основном файле параметров MySQL. Затем вы можете включить его следующим образом:$ cat /etc/my.cnf !include /etc/mysql.d/xtrabackup.cnf ...Вы можете видеть, что /etc/my.cnf включает файл /etc/mysql.d/xtrabackup.cnf, который, в свою очередь, имеет несколько параметров конфигурации, перечисленных в разделе
[xtrabackup].Однако нет необходимости иметь разные разделы в разных файлах. Например, Percona XtraDB Cluster имеет параметры конфигурации библиотеки
wsrepв разделе[mysqld]. Таких конфигураций много, и они не всегда полезны в вашем файле my.cnf. Вы можете создать отдельный файл, например, /etc/mysql.d/wsrep.conf, и перечислить там переменные wsrep в разделе[mysqld]. Любая программа, читающая основной файл my.cnf, также будет читать все включенные файлы и только затем анализировать переменные в разных разделах.Когда создается много таких дополнительных файлов конфигурации, вы можете просто включить весь каталог или каталоги, которые их содержат, вместо включения каждого отдельного файла параметров. Это делается с помощью другой директивы,
includedir, которая ожидает путь к каталогу в качестве аргумента:!includedir /etc/mysql.dПрограммы MySQL воспринимают этот путь как каталог и пытаются включить каждый файл параметров в дерево этого каталога. В Unix-подобных системах включены файлы .cnf; в Windows включены файлы .cnf и .ini.
Обычно включения определяются в начале конкретного конфигурационного файла, но это не обязательно. Вы можете думать о включении как о добавлении содержимого включенного файла или файлов к родительскому файлу; везде, где в файле определено включение, содержимое включаемого файла будет помещено прямо под этим включением. На самом деле все немного сложнее, но эта ментальная модель работает, например, когда мы думаем о приоритете параметров, который мы рассматриваем в разделе «Порядок поиска файлов параметров».
В каждом включенном файле должен быть определен хотя бы один раздел конфигурации. Например, в начале может быть
[mysqld]. - Пустые строки
-
Пустые строки в файлах параметров не играют никакой роли. Но вы можете использовать их для визуального разделения разделов или отдельных параметров, чтобы файл было легче читать.
Область видимости параметров
Мы можем говорить об области видимости параметров в MySQL с двух точек зрения. Во-первых, каждый отдельный параметр может иметь глобальную область видимости, область видимости сеанса или и то, и другое, и может устанавливаться динамически или статически. Во-вторых, мы можем поговорить о том, как параметры, установленные в файлах параметров, распределяются по разделам и каковы область видимости и порядок приоритета самих файлов параметров.
Мы упомянули, что заголовки разделов определяют, какая конкретная программа (или программы, поскольку ничто не мешает читать несколько разделов) предназначена для чтения параметров под определенным заголовком. Некоторые параметры конфигурации не имеют смысла за пределами своих разделов, но некоторые могут быть определены в нескольких разделах и не обязательно должны быть установлены одинаково.
Давайте рассмотрим пример, когда у нас есть сервер MySQL, сконфигурированный с набором символов latin1 по устаревшим причинам. Однако теперь есть более новые таблицы с кодировкой utf8mb4. Мы хотим, чтобы наши логические дампы mysqldump были только в UTF-8, поэтому мы хотим переопределить кодировку для этой программы. Удобно, что mysqldump считывает свой собственный раздел конфигурации, поэтому мы можем написать файл опций следующим образом:
[mysqld]
character_set_server=latin1
[mysqldump]
default_character_set=utf8mb4
Этот небольшой пример показывает, как параметры могут быть установлены на разных уровнях. В данном конкретном случае мы использовали разные варианты, но это мог быть один и тот же вариант в разных масштабах. Например, предположим, что мы хотим ограничить будущий размер значений BLOB и TEXT (см. «Типы строк») до 32 МБ, но у нас уже есть строки размером до 256 МБ. Мы можем добавить искусственный барьер для локальных клиентов, используя такую конфигурацию:
[mysqld]
max_allowed_packet=256M
[client]
max_allowed_packet=32M
Значение max_allowed_packet сервера MySQL будет установлено в глобальной области и будет действовать как жесткое ограничение на максимальный размер запроса (а также на размер поля BLOB или TEXT). Значение клиента будет установлено в области сеанса и будет действовать как мягкое ограничение. Если конкретному клиенту требуется большее значение (например, чтобы прочитать старую строку), он может использовать оператор SET, чтобы перейти к ограничению сервера.
Сами файлы параметров также имеют разные области видимости. Файлы параметров MySQL можно разделить по области видимости на несколько групп: глобальные, клиентские, серверные и дополнительные. Файлы глобальных параметров читаются всеми или большинством программ MySQL, тогда как файлы клиента и сервера читаются только клиентскими программами и mysqld соответственно. Поскольку можно указать дополнительный файл конфигурации для чтения программой, мы также перечисляем категорию «дополнительно».
Давайте рассмотрим файлы параметров, устанавливаемые и читаемые в Linux и Windows при обычной установке MySQL 8.0. Мы начнем с Windows, в таблице 9-1.
| Имя файла | Область видимости и назначение |
|---|---|
| %WINDIR%\my.ini, %WINDIR%\my.cnf | Глобальные опции, читаемые всеми программами |
| C:\my.ini, C:\my.cnf | Глобальные опции, читаемые всеми программами |
| BASEDIR\my.ini, BASEDIR\my.cnf | Глобальные опции, читаемые всеми программами |
| Дополнительный файл конфигурации | Файл, опционально указанный с --defaults-extra-file |
| %APPDATA%\MySQL\.mylogin.cnf | Конфигурационный файл пути входа в систему |
| DATADIR\mysqld-auto.cnf | Файл параметров для постоянных переменных |
В Таблице 9-2 представлены файлы параметров для типичной установки в Fedora Linux.
| Имя файла | Область видимости и назначение |
|---|---|
| /etc/my.cnf, /etc/mysql/my.cnf, /usr/etc/my.cnf | Глобальные параметры, читаемые всеми программами |
| $MYSQL_HOME/my.cnf | Параметры сервера, только для чтения, если переменная установлена |
| ~/.my.cnf | Глобальные параметры, читаемые всеми программами, запущенными конкретным пользователем ОС |
| Дополнительный файл конфигурации | Файл, опционально указанный с --defaults-extra-file |
| ~/.mylogin.cnf | Файл конфигурации пути входа в систему под определенным пользователем ОС |
| DATADIR/mysqld-auto.cnf | Файл параметров для сохраняемых переменных |
В Linux трудно определить универсальный полный список файлов конфигурации, поскольку пакеты MySQL для разных дистрибутивов Linux могут считывать немного разные файлы или места. Как правило, хорошей отправной точкой в Linux является /etc/my.cnf, а в Windows — либо %WINDIR%\my.cnf, либо BASEDIR\my.cnf.
Пара файлов конфигурации, которые мы перечислили, могут различаться по своим путям в разных системах. /usr/etc/my.cnf также можно записать как SYSCONFIGDIR/my.cnf, а путь определяется во время компиляции. $MYSQL_HOME/my.cnf читается только в том случае, если установлена переменная. Упакованная по умолчанию программа mysqld_safe (используемая для запуска демона mysqld) установит $MYSQL_HOME в BASEDIR перед запуском mysqld. Вы не найдете $MYSQL_HOME установленным ни для одного из пользователей ОС, и установка этой переменной актуальна, только если вы запускаете mysqld вручную, другими словами, не используя команды service или systemctl.
Есть одно своеобразное различие между Windows и Linux. В Linux программы MySQL читают некоторые файлы конфигурации, расположенные в домашнем каталоге данного пользователя ОС. В таблице 9-2 домашний каталог представлен как ~. MySQL в Windows не имеет такой возможности. Одним из частых вариантов использования таких файлов конфигурации является управление параметрами клиентов в зависимости от пользователя их ОС. Обычно они содержат учетные данные. Однако средство пути входа в систему, описанное в «Специальных файлах параметров», делает это излишним.
Дополнительный конфигурационный файл, указанный в командной строке с помощью --defaults-extra-file, будет считан после того, как будет прочитан любой другой глобальный файл, в соответствии с его положением в таблице. Это полезная опция, когда вы хотите выполнить однократный запуск программы, например, для проверки новых переменных. Однако чрезмерное использование этого параметра может привести к проблемам с пониманием текущего набора действующих параметров (см. «Определение действующих параметров»). Опция --defaults-extra-file не единственная, которая изменяет обработку файла параметров. --no-defaults запрещает программе вообще читать какие-либо файлы конфигурации. --defaults-file заставляет программу читать один файл, что может быть полезно, если у вас есть все настройки в одном месте.
К настоящему моменту вы должны иметь четкое представление о том, какие файлы параметров используются в большинстве установок MySQL. В следующем разделе более подробно рассказывается о том, как разные программы читают разные файлы, в каком порядке и какую конкретную группу или группы они считывают из этих файлов.
Порядок поиска файлов параметров
На этом этапе вы должны знать структуру файлов параметров и где их найти. Большинство программ MySQL считывают один или несколько файлов параметров, и важно знать, в каком конкретном порядке программа ищет эти файлы и читает их. В этом разделе рассматриваются темы порядка поиска и приоритета параметров, а также обсуждается их важность.
Если программа MySQL читает какие-либо файлы параметров, вы можете найти конкретные файлы, которые она читает, а также порядок, в котором она их читает. Общий порядок чтения конфигурационных файлов будет либо точно таким же, либо очень похожим на порядок, указанный в таблицах 9-1 и 9-2. Вы можете использовать следующую команду, чтобы увидеть точный порядок:
$ mysqld --verbose --help | grep "Default options" -A2
Default options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf
The following groups are read: mysqld server mysqld-8.0
В Windows вам нужно запустить mysqld.exe вместо mysqld, но вывод останется прежним. Этот вывод включает в себя список прочитанных файлов конфигурации и их порядок. Вы также можете увидеть список групп параметров, читаемых mysqld: [mysqld], [server] и [mysqld-8.0]. Обратите внимание, что вы можете изменить список групп параметров, которые читает любая программа, добавив параметр --defaults-group-suffix:
$ mysqld --defaults-group-suffix=-test --verbose --help | grep "groups are read"
The following groups are read: mysqld server mysqld-8.0 ...
... mysqld-test server-test mysqld-8.0-test
Теперь вы знаете, какие файлы параметров и группы параметров считываются. Однако также важно знать порядок старшинства этих файлов параметров. В конце концов, ничто не мешает вам установить один или несколько параметров в нескольких файлах конфигурации. В случае программ MySQL порядок старшинства конфигурационных файлов прост: параметры из файлов, прочитанных позже, имеют приоритет над параметрами в ранее прочитанных файлах. Параметры, передаваемые командам непосредственно в качестве аргументов командной строки, имеют приоритет над любыми параметрами конфигурации в любых файлах конфигурации.
В таблицах 9-1 и 9-2 файлы читаются в порядке сверху вниз. Чем ниже файл конфигурации в списке, тем выше «вес» параметров в нем. Например, для любых программ, отличных от mysqld, значения в .mylogin.cnf имеют приоритет над значениями в любых других файлах конфигурации и имеют только более низкий приоритет, чем значения, заданные с помощью аргументов командной строки. Для mysqld то же самое верно для сохраняемых переменных, установленных в DATADIR /mysqld-auto.cnf.
Возможность включать файлы конфигурации в другие файлы с помощью директив включения немного усложняет ситуацию, но вы всегда включаете дополнительные файлы в один или несколько файлов параметров, перечисленных в таблицах 9-1 и 9-2. Вы можете думать об этом как о том, что MySQL добавляет включенные файлы в родительский файл конфигурации непосредственно перед его чтением, вставляя каждый из них в файл сразу после его директивы включения. Таким образом, глобальный приоритет параметров — приоритет родительского файла конфигурации. В самом результирующем файле (со всеми включенными файлами, добавленными по порядку) параметры, определенные позже, имеют приоритет над определенными ранее.
Файлы специальных параметров
В MySQL используются два специальных файла конфигурации, которые являются исключениями из структуры, описанной в разделе «Структура файла параметров».
Файл конфигурации пути входа в систему
Во-первых, это файл .mylogin.cnf, который используется как часть системы путей входа в систему. Несмотря на то, что вы можете думать о его структуре как об обычном файле параметров, этот конкретный файл не является обычным текстовым файлом. По сути, это зашифрованный текстовый файл. Этот файл предназначен для создания и изменения с помощью специальной программы mysql_config_editor, которая поставляется вместе с MySQL, обычно в клиентском пакете. Он зашифрован, потому что цель .mylogin.cnf (и всей системы путей входа в систему) состоит в том, чтобы хранить параметры подключения MySQL, включая пароли, удобным и безопасным способом.
По умолчанию mysql_config_editor и другие программы MySQL будут искать .mylogin.cnf в $HOME текущего пользователя в Linux и различных версиях Unix, а также в %APPDATA%\MySQL в Windows. Можно изменить местоположение и имя файла, установив переменную среды MYSQL_TEST_LOGIN_FILE.
Вы можете создать этот файл, если он еще не существует, сохранив в нем пароль для пользователя root:
$ mysql_config_editor set --user=root --password
Enter password:
После ввода пароля и подтверждения ввода мы можем взглянуть на содержимое файла:
$ ls -la ~/.mylogin.cnf
-rw-------. 1 skuzmichev skuzmichev 100 Jan 18 18:03 .mylogin.cnf
$ cat ~/.mylogin.cnf
>pZ
prI
R86w"># &.h.m:4+|DDKnl_K3>73x$
$ file ~/.mylogin.cnf
.mylogin.cnf: data
$ file ~/.my.cnf
.my.cnf: ASCII text
Как видите, по крайней мере на первый взгляд, .mylogin.cnf точно не является обычным файлом конфигурации. В связи с этим он требует особого отношения. Помимо создания файла, вы можете просматривать и изменять .mylogin.cnf с помощью редактора mysql_config_editor. Начнем с того, как на самом деле увидеть, что внутри. Опцией для этого является print:
$ mysql_config_editor print
[client]
user = "root"
password = *****
client — это путь входа по умолчанию. Все операции, выполняемые с помощью mysql_config_editor без явного указания пути входа, влияют на путь входа client. Мы не указывали никакого пути входа в систему при запуске set ранее, поэтому учетные данные root были записаны по пути client. Однако можно указать конкретный путь входа для любой операции. Давайте поместим учетные данные root в путь входа с именем root:
$ mysql_config_editor set --login-path=root --user=root --password
Enter password:
Чтобы указать путь для входа, используйте параметр --login-path или -G, а для просмотра всех путей при использовании print добавьте параметр --all:
$ mysql_config_editor print --login-path=root
[root]
user = root
password = *****
$ mysql_config_editor print --all
[client]
user = root
password = *****
[root]
user = root
password = *****
Вы можете видеть, что выходные данные напоминают файл параметров, поэтому вы можете думать о .mylogin.cnf как о файле параметров с некоторой специальной обработкой. Только не редактируйте его вручную. Говоря о редактировании, давайте добавим еще несколько параметров в команду set, когда ее вызывает mysql_config_editor. В процессе мы создадим новый путь входа.
mysql_config_editor поддерживает аргумент --help (или -?), который можно комбинировать с другими параметрами, чтобы получить справку конкретно по print или set, например. Начнем с немного урезанного вывода справки для set:
$ mysql_config_editor set --help
...
MySQL Configuration Utility.
Description: Write a login path to the login file.
Usage: mysql_config_editor [program options] [set [command options]]
-?, --help Display this help and exit.
-h, --host=name Host name to be entered into the login file.
-G, --login-path=name
Name of the login path to use in the login file. (Default: client)
-p, --password Prompt for password to be entered into the login file.
-u, --user=name User name to be entered into the login file.
-S, --socket=name Socket path to be entered into login file.
-P, --port=name Port number to be entered into login file.
-w, --warn Warn and ask for confirmation if set command attempts to overwrite an existing login path (enabled by default). (Defaults to on; use --skip-warn to disable.)
...
Здесь вы можете увидеть еще одно интересное свойство файла .mylogin.cnf: в него нельзя помещать произвольные параметры. Теперь мы знаем, что в основном мы можем установить только несколько параметров, связанных с входом в экземпляр или экземпляры MySQL, чего, конечно же, и следует ожидать от файла «путь входа». Теперь вернемся к редактированию файла:
$ mysql_config_editor set --login-path=scott --user=scott
$ mysql_config_editor set --login-path=scott --user=scott
WARNING : scott path already exists and will be overwritten. Continue? (Press y|Y for Yes, any other key for No) : y
$ mysql_config_editor set --login-path=scott --user=scott --skip-warn
Здесь мы показали все варианты поведения, которые mysql_config_editor может демонстрировать при изменении или создании пути входа в систему. Если путь входа еще не существует, предупреждение не выдается. Если такой путь уже есть, будет напечатано предупреждение и подтверждение, но только если не указан --skip-warn. Обратите внимание, что здесь мы говорим о полном пути входа в систему! Невозможно изменить одно свойство пути: каждый раз записывается весь путь входа. Если вы хотите изменить одно свойство, вам также нужно будет указать все остальные свойства, которые вам нужны.
Добавим еще немного деталей и посмотрим на результат:
$ mysql_config_editor set --login-path=scott \
--user=scott --port=3306 --host=192.168.122.1 \
--password --skip-warn
Enter password:
$ mysql_config_editor print --login-path=scott
[scott]
user = scott
password = *****
host = 192.168.122.1
port = 3306
Файл конфигурации постоянных системных переменных
Второй специальный файл — это mysqld-auto.cnf, который находится в каталоге данных, начиная с MySQL 8.0. Это часть новой функции постоянных системных переменных, которая позволяет обновлять параметры MySQL на диске с помощью обычных операторов SET. Раньше вы не могли изменить конфигурацию MySQL из соединения с базой данных. Обычный процесс состоял в том, чтобы изменить файлы параметров на диске, а затем запустить оператор SET GLOBAL для изменения переменных конфигурации в режиме онлайн. Как вы можете себе представить, это может привести к ошибкам и к тому, что изменения будут вноситься, например, только онлайн. Новый оператор SET PERSIST решает обе задачи: переменные, обновляемые онлайн, также обновляются на диске. Также возможно обновить переменную только на диске.
Сам файл, на удивление, совсем не похож ни на один другой файл конфигурации в MySQL. В то время как .mylogin.cnf был зашифрованным, но все еще обычным файлом параметров, mysqld-auto.cnf использует общий, но совершенно другой формат: JSON.
До того, как вы что-то сохраните, mysqld-auto.cnf не существует. Итак, начнем с изменения системной переменной:
mysql> SELECT @@GLOBAL.max_connections;
+--------------------------+
| @@GLOBAL.max_connections |
+--------------------------+
| 100 |
+--------------------------+
1 row in set (0.00 sec)
mysql> SET PERSIST max_connections = 256;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT @@GLOBAL.max_connections;
+--------------------------+
| @@GLOBAL.max_connections |
+--------------------------+
| 256 |
+--------------------------+
1 row in set (0.00 sec)
Как и ожидалось, переменная была обновлена в глобальной области онлайн. Давайте теперь исследуем полученный файл конфигурации. Поскольку мы знаем, что содержимое находится в формате JSON, мы воспользуемся утилитой jq, чтобы красиво отформатировать его. Это не обязательно, но облегчает чтение файла:
$ cat /var/lib/mysql/mysqld-auto.cnf | jq .
{
"Version": 1,
"mysql_server": {
"max_connections": {
"Value": "256",
"Metadata": {
"Timestamp": 1611728445802834,
"User": "root",
"Host": "localhost"
}
}
}
}
Просто взглянув на этот файл, содержащий одно значение переменной, вы поймете, почему для файлов конфигурации, предназначенных для редактирования людьми используется обычный .ini. Это многословно! Однако JSON отлично подходит для чтения компьютерами, поэтому он хорошо подходит для конфигурации, написанной и читаемой самой MySQL. В качестве дополнительного преимущества вы получаете аудит изменений: как видите, свойство max_connection имеет метаданные, содержащие время, когда произошло изменение, и автора изменения.
Поскольку это текстовый файл, в отличие от файла конфигурации пути входа в систему, который является бинарным, можно отредактировать mysqld-auto.cnf вручную. Однако маловероятно, что будет много случаев, когда это необходимо.
Определение действующих параметров
Последняя рутинная задача, с которой сталкивается практически каждый, кто работает с MySQL, — это определение значений переменных и того, в каких файлах параметров они установлены (и почему, но иногда никакие технологии не могут помочь с человеческим мышлением!).
На данный момент мы знаем, какие файлы программы MySQL читают, в каком порядке и их приоритет. Мы также знаем, что аргументы командной строки переопределяют любые другие параметры. Тем не менее, понять, где именно установлена та или иная переменная, может оказаться непростой задачей. Сканирование нескольких файлов, потенциально с вложенными включениями, может привести к длительному расследованию.
Давайте начнем с того, как определить параметры, используемые в настоящее время программой. Для некоторых программ, таких как MySQL Server (mysqld), это легко. Вы можете получить список текущих значений, используемых mysqld, запустив SHOW GLOBAL VARIABLES. Невозможно изменить значение параметра, которое использует mysqld, и не увидеть эффект, отраженный в состоянии глобальных переменных. С другими программами дело обстоит сложнее. Чтобы понять, какие параметры используются mysql, вам нужно запустить ее, а затем проверить выходные данные SHOW VARIABLES и SHOW GLOBAL VARIABLES, чтобы увидеть, какие параметры переопределены на уровне сеанса. Но даже до того, как будет установлено успешное соединение с сервером, mysql должен прочитать или получить информацию о соединении.
Существует два простых способа определить список параметров, действующих при запуске программы: путем передачи этой программе аргумента --print-defaults или с помощью специальной программы my_print_defaults. Давайте посмотрим на первый вариант, выполненный в Linux. Вы можете проигнорировать часть sed, но она делает вывод более приятным для человеческого глаза:
$ mysql --print-defaults
mysql would have been started with the following arguments:
--user=root --password=*****
$ mysqld --print-defaults | sed 's/--/\n--/g'
/usr/sbin/mysqld would have been started with the following arguments:
--datadir=/var/lib/mysql
--socket=/var/lib/mysql/mysql.sock
--log-error=/var/log/mysqld.log
--pid-file=/run/mysqld/mysqld.pid
--max_connections=100000
--core-file
--innodb_buffer_pool_in_core_file=OFF
--innodb_buffer_pool_size=256MiB
Выбранные здесь переменные взяты из всех файлов опций, которые мы обсуждали ранее. Если значение переменной было задано несколько раз, последнее вхождение будет иметь приоритет. Однако --print-defaults на самом деле выведет каждый набор параметров. Например, вывод может выглядеть следующим образом: несмотря на то, что innodb_buffer_pool_size устанавливается пять раз, фактическое значение будет равно 384 МБ:
$ mysqld --print-defaults | sed 's/--/\n--/g'
/usr/sbin/mysqld would have been started with the following arguments:
--datadir=/var/lib/mysql
--socket=/var/lib/mysql/mysql.sock
--log-error=/var/log/mysqld.log
--pid-file=/run/mysqld/mysqld.pid
--max_connections=100000
--core-file
--innodb_buffer_pool_in_core_file=OFF
--innodb_buffer_pool_size=268435456
--innodb_buffer_pool_size=256M
--innodb_buffer_pool_size=256MB
--innodb_buffer_pool_size=256MiB
--large-pages
--innodb_buffer_pool_size=384M
Вы также можете комбинировать --print-defaults с другими аргументами командной строки. Например, если вы собираетесь запустить программу с аргументами командной строки, вы можете увидеть, будут ли они переопределять или повторять уже установленные значения параметров конфигурации для конкретного сеанса:
$ mysql --print-defaults --host=192.168.4.23 --user=bob | sed 's/--/\n--/g'
mysql would have been started with the following arguments:
--user=root
--password=*****
--host=192.168.4.23
--user=bob
Другой способ печати переменных — использование программы my_print_defaults. Она принимает один или несколько заголовков разделов в качестве аргументов и печатает все параметры, которые находит в отсканированных файлах и попадает в запрошенные группы. Это может быть лучше, чем использование --print-defaults, когда вам просто нужно просмотреть одну группу опций. В MySQL 8.0 программа mysqld считывает следующие группы: [mysqld], [server] и [mysqld-8.0]. Комбинированный вывод параметров может быть длительным, но что, если нам нужно просмотреть только параметры, специально установленные для версии 8.0? Для этого примера мы добавили группу параметров [mysqld-8.0] в файл параметров и поместили туда несколько значений параметров конфигурации:
$ my_print_defaults mysqld-8.0
--character_set_server=latin1
--collation_server=latin1_swedish_ci
Это также может помочь с другим программным обеспечением, таким как PXC, или с вариантом MySQL MariaDB, оба из которых включают несколько групп конфигурации. В частности, вы, вероятно, захотите просмотреть раздел [wsrep] без каких-либо других вариантов. my_print_defaults можно, конечно, использовать и для вывода полного набора опций; ей просто нужно передать все заголовки разделов, которые читает программа. Например, программа mysql считывает группы параметров [mysql] и [client], поэтому мы могли бы использовать:
$ my_print_defaults mysql client
--user=root
--password=*****
--default-character-set=latin1
Определения пользователя и пароля берутся из группы клиентов в конфигурации пути входа в систему, которую мы установили ранее, а кодировка — из группы параметров [mysql] в обычном .my.cnf. Обратите внимание, что мы добавили эту группу и конфигурацию кодировки вручную; по умолчанию этот параметр не установлен.
Вы можете видеть, что, хотя оба способа чтения параметров говорят о значениях по умолчанию, они на самом деле выводят параметры, которые мы установили явно, что делает их нестандартными. Это интересный момент, но он ничего не меняет в общей схеме вещей.
К сожалению, ни один из этих способов просмотра вариантов не идеален для определения полного набора действующих вариантов. Проблема в том, что они читают только файлы конфигурации, перечисленные в таблицах 9-1 и 9-2, но программы MySQL могут читать другие файлы конфигурации или запускаться с аргументами командной строки. Кроме того, переменные, сохраняемые в DATADIR /mysqld-auto.cnf через SET PERSIST, не предоставляются процедурами печати по умолчанию.
Мы упомянули, что программы MySQL не читают опции ни из каких других файлов, кроме тех, которые перечислены в таблицах 9-1 и 9-2. Однако эти списки включают «дополнительный файл конфигурации», который может находиться в произвольном месте. Если вы не укажете тот же дополнительный файл при вызове my_print_defaults или другой программы с параметром --print-defaults, параметры из этого дополнительного файла не будут прочитаны. Дополнительный файл указывается с помощью аргумента командной строки --defaults-extra-file и может быть указан для большинства, если не для всех программ MySQL. Две процедуры печати по умолчанию читают только предопределенные файлы конфигурации и пропустят этот файл. Однако вы можете указать --defaults-extra-file как для my_print_defaults, так и для программы, вызванной с --print-defaults, и тогда обе будут читать дополнительный файл. То же самое относится к параметру --defaults-file, о котором мы упоминали ранее.
И --defaults-extra-file, и --defaults-file имеют одну общую черту: они являются аргументами командной строки. Аргументы командной строки, передаваемые программе MySQL, переопределяют любые параметры, считанные из файлов конфигурации, но в то же время вы можете пропустить их, когда используете --print-defaults или my_print_defaults, поскольку они поступают извне любых файлов конфигурации. Говоря более кратко: определенная программа MySQL, такая как mysqld, может быть запущена кем-то с неизвестными и произвольными аргументами командной строки. Таким образом, когда мы говорим о вариантах, по сути, мы также должны учитывать наличие таких аргументов.
В Linux и Unix-подобных системах вы можете использовать утилиту ps (или аналогичную) для просмотра информации о запущенных в данный момент процессах, включая их полные командные строки. Давайте посмотрим на пример в Linux, где mysqld был запущен с --no-defaults и со всеми параметрами конфигурации, переданными в качестве аргументов:
$ ps auxf | grep mysqld | grep -v grep
root 397830 ... \_ sudo -u mysql bash -c mysqld ...
mysql 397832 ... \_ mysqld --datadir=/var/lib/mysql ...
Или, если мы напечатаем только командную строку для процесса mysqld и сделаем ее чище с помощью sed:
$ ps -p 397832 -ocommand ww | sed 's/--/\n--/g'
COMMAND
mysqld
--datadir=/var/lib/mysql
--socket=/var/lib/mysql/mysql.sock
--log-error=/var/log/mysqld.log
--pid-file=/run/mysqld/mysqld.pid
...
--character_set_server=latin1
--collation_server=latin1_swedish_ci
Обратите внимание, что в этом примере мы запустили mysqld без использования каких-либо предоставленных сценариев. Вы не часто встретите такой способ запуска сервера MySQL, но это возможно.
Вы можете передать любой параметр конфигурации в качестве аргумента, поэтому вывод может быть довольно длинным. Однако, если вы не уверены, как именно была запущена mysqld или другая программа, это важно проверить. В Windows вы можете просмотреть аргументы командной строки запущенной программы, либо открыв Диспетчер задач и добавив столбец Командная строка на вкладку Процессы (через меню Вид), либо с помощью инструмента Process Explorer из пакета sysinternals.
Если ваша программа MySQL запускается из сценария, вы должны проверить этот сценарий, чтобы найти все используемые аргументы. Хотя это, вероятно, будет редким случаем для mysqld, обычно из пользовательских сценариев запускаются mysql, mysqldump и xtrabackup.
Понимание используемых в настоящее время параметров может быть сложной задачей, но иногда это чрезвычайно важно. Надеемся, что эти рекомендации и советы помогут вам.
Глава 10
Резервное копирование и восстановление
Наиболее важной задачей любого администратора баз данных является резервное копирование данных. Правильные и проверенные процедуры резервного копирования и восстановления могут спасти компанию, а значит, и работу. Случаются ошибки, сбои в работе и нештатные ситуации. MySQL — надежное программное обеспечение, но оно не полностью лишено ошибок или сбоев. Таким образом, очень важно понять, почему и как выполнять резервное копирование.
Помимо сохранения содержимого базы данных, большинство методов резервного копирования также можно использовать для другой важной цели: копирования содержимого базы данных между отдельными системами. Хотя, вероятно, это не так важно, как предотвращение повреждения, такое копирование является рутинной операцией для подавляющего большинства операторов баз данных. Разработчикам часто приходится использовать последующие среды, которые должны быть аналогичны рабочей среде. Сотрудникам по контролю качества может потребоваться изменчивая среда с продолжительностью жизни в один час. Аналитика может быть запущена на выделенном хосте. Часть этих задач можно решить с помощью репликации, но любая реплика запускается из восстановленной резервной копии.
В этой главе сначала кратко рассматриваются два основных типа резервных копий и обсуждаются их основные свойства. Затем рассматриваются некоторые инструменты, доступные в мире MySQL для резервного копирования и восстановления. Рассмотрение каждого инструмента и его параметров выходит за рамки этой книги, но к концу главы вы должны знать, как создавать резервные копии и восстанавливать данные MySQL. Мы также рассмотрим некоторые базовые сценарии передачи данных. Наконец, в главе описывается надежная архитектура резервного копирования, которую вы можете использовать в качестве основы для своей работы.
Обзор того, что мы считаем хорошей стратегией резервного копирования, приведен в разделе «Стратегия резервного копирования базы данных». Мы считаем, что важно понимать инструменты и движущие элементы, прежде чем принимать решение о стратегии, и поэтому этот раздел идет последним.
Физические и логические резервные копии
Вообще говоря, большинство, если не все, инструменты резервного копирования можно отнести всего к двум широким категориям: логическим и физическим. Логические резервные копии работают с внутренними структурами: базами данных (схемами), таблицами, представлениями, пользователями и другими объектами. Физические резервные копии касаются представления структур базы данных на стороне ОС: файлов данных, журналов транзакций и т. д.
Возможно, это было бы проще объяснить на примере. Представьте себе резервное копирование одной таблицы MyISAM в базе данных MySQL. Как вы увидите позже в этой главе, механизм хранения InnoDB более сложен для правильного резервного копирования. Зная, что MyISAM не является транзакционным и что в эту таблицу не выполняются текущие операции записи, мы можем копировать связанные с ней файлы. При этом мы создаем физическую резервную копию таблицы. Вместо этого мы могли бы запустить операторы SELECT * и SHOW CREATE TABLE для этой таблицы и где-нибудь сохранить результаты этих операторов. Это очень простая форма логического резервного копирования. Конечно, это всего лишь простые примеры, и в реальности процесс получения обоих типов резервных копий будет более сложным и детализированным. Однако концептуальные различия между этими воображаемыми резервными копиями могут быть перенесены и применены к любым логическим и физическим резервным копиям.
Логические резервные копии
Логические резервные копии связаны с фактическими данными, а не с их физическим представлением. Как вы уже видели, такие резервные копии не копируют какие-либо существующие файлы базы данных, а вместо этого полагаются на запросы или другие средства для получения необходимого содержимого базы данных. Результатом обычно является некоторое текстовое представление, хотя это и не предусмотрено, и выходные данные логической резервной копии вполне могут быть в двоичном коде. Давайте посмотрим еще несколько примеров того, как могут выглядеть такие резервные копии, а затем обсудим их свойства.
Вот несколько примеров логических резервных копий:
-
Данные таблицы запрашиваются и сохраняются во внешнем файле .csv с помощью инструкции
SELECT ... INTO OUTFILE, которую мы рассмотрим в разделе «Запись данных в файлы с разделителями-запятыми». -
Таблица или определение любого другого объекта, сохраняется как оператор SQL.
-
Одна или несколько инструкций SQL
INSERT, которые выполняются для базы данных и пустой таблицы, заполняют эту таблицу до сохраненного состояния. -
Запись всех когда-либо выполнявшихся операторов, которые касались определенной таблицы или базы данных и изменяли данные или объекты схемы. Под этим мы подразумеваем команды DML и DDL; вы должны быть знакомы с обоими типами, они были описаны в главах 3 и 4.
Восстановление логической резервной копии обычно выполняется путем выполнения одного или нескольких операторов SQL. Продолжая наши предыдущие примеры, давайте рассмотрим варианты восстановления:
-
Данные из файла .csv можно загрузить в таблицу с помощью команды
LOAD DATA INFILE. -
Таблицу можно создать или воссоздать заново, выполнив инструкцию DDL SQL.
-
Операторы
INSERTSQL могут выполняться с использованием интерфейса командной строкиmysqlили любого другого клиента. -
Повтор всех операторов, запущенных в базе данных, восстановит ее состояние после последнего оператора.
Логические резервные копии обладают некоторыми интересными свойствами, которые делают их чрезвычайно полезными в некоторых ситуациях. Чаще всего логическая резервная копия представляет собой некую форму текстового файла, состоящего в основном из операторов SQL. Однако это не обязательно и не является определяющим свойством (хотя и полезным). Процесс создания логических резервных копий также обычно включает выполнение некоторых запросов. Это важные функции, поскольку они обеспечивают высокую степень гибкости и мобильности.
Логические резервные копии являются гибкими, поскольку они позволяют очень легко создавать резервные копии части базы данных. Например, вы можете создавать резервные копии объектов схемы без их содержимого или легко создавать резервные копии только нескольких таблиц базы данных. Вы даже можете создать резервную копию части данных таблицы, что обычно невозможно при физическом резервном копировании. Когда файл резервной копии готов, вы можете использовать инструменты для просмотра и изменения его вручную или автоматически, что нелегко сделать с копиями файлов базы данных.
Переносимость обусловлена тем, что логические резервные копии могут быть легко загружены в разные версии MySQL, работающие в разных операционных системах и архитектурах. С некоторой модификацией вы действительно можете загружать логические резервные копии, взятые из одной СУБД, в совершенно другую. По этой причине большинство инструментов миграции баз данных используют внутреннюю логическую репликацию. Это свойство также делает этот тип резервного копирования подходящим для резервного копирования облачных баз данных за пределами площадки и для миграции между ними.
Еще одно интересное свойство логических резервных копий заключается в том, что они эффективны в борьбе с повреждением, то есть с физическим повреждением физического файла данных. Ошибки в данных все еще могут быть вызваны, например, ошибками в программном обеспечении или постепенным ухудшением состояния носителей. Тема повреждений данных и её противоположности, целостности, очень обширна, но этого краткого объяснения на данный момент должно быть достаточно.
После повреждения файла данных база данных может быть не в состоянии считывать из него данные и обслуживать запросы. Поскольку искажение обычно происходит незаметно, вы можете не знать, когда оно произошло. Однако, если логическая резервная копия была создана без ошибок, это означает, что она исправна и содержит правильные данные. Повреждение может произойти во вторичном индексе (любом непервичном индексе; дополнительные сведения см. в Главе 4 «Работа со структурами базы данных»), поэтому логическая резервная копия, выполняющая полное сканирование таблицы, может генерироваться нормально и не вызывать ошибки. Короче говоря, логическое резервное копирование может помочь вам обнаружить повреждение данных на ранней стадии (так как оно сканирует все таблицы) и сохранить данные (так как последнее успешное логическое резервное копирование будет содержать корректную копию данных).
Проблема, присущая всем логическим резервным копиям, заключается в том, что они создаются и восстанавливаются путем выполнения операторов SQL в работающей системе баз данных. Хотя это обеспечивает гибкость и переносимость, это также означает, что эти резервные копии приводят к нагрузке на базу данных и, как правило, довольно медленны. Администраторы баз данных всегда недовольны, когда кто-то запускает запрос, который считывает все данные из таблицы без разбора, и именно это обычно делают инструменты логического резервного копирования. Точно так же операция восстановления для логической резервной копии обычно приводит к интерпретации и выполнению каждого оператора, как если бы он был получен от обычного клиента. Это не означает, что логические резервные копии плохи или их не следует использовать, но об этом компромиссе следует помнить.
Физические резервные копии
В то время как логические резервные копии — это все данные, содержащиеся в содержимом базы данных, физические резервные копии — это все данные, такие как файлы операционной системы и внутренняя работа СУБД. Помните, что в примере с резервной копией таблицы MyISAM физическая резервная копия представляла собой копию файлов, представляющих эту таблицу. Большинство резервных копий и инструментов этого типа связаны с копированием и переносом всех или части файлов базы данных.
Некоторые примеры физических резервных копий включают следующее:
-
Холодная копия каталога базы данных, что означает, что она выполняется, когда база данных закрыта (в отличие от горячей копии, выполняемой во время работы базы данных).
-
Моментальный снимок хранилища томов и файловых систем, используемых базой данных.
-
Копия файлов данных таблицы.
-
Поток изменений в файлах данных базы данных той или иной формы. Большинство СУБД используют подобный поток для аварийного восстановления, а иногда и для репликации; Журнал повторов InnoDB представляет собой аналогичную концепцию.
Восстановление физической резервной копии обычно выполняется путем копирования файлов и приведения их в соответствие. Давайте рассмотрим варианты восстановления для предыдущих примеров:
-
Сохраненная холодная копия может быть перемещена в нужное место или на нужный сервер, а затем использована в качестве каталога данных экземпляром MySQL, старым или новым.
-
Моментальный снимок может быть восстановлен на месте или на другом томе, а затем использован MySQL.
-
Табличные файлы могут быть помещены вместо существующих.
-
Повтор потока изменений файлов данных восстановит их состояние до последнего момента времени.
Из них самая простая физическая резервная копия, которую можно выполнить, — это резервная копия холодного каталога базы данных. Да, это просто и элементарно, но это очень мощный инструмент.
Физические резервные копии, в отличие от логических, являются очень жесткими, что дает мало возможностей для контроля над тем, что может быть зарезервировано и где эта резервная копия может быть использована. Вообще говоря, большинство физических резервных копий можно использовать только для восстановления точно такого же состояния базы данных или таблицы. Обычно эти резервные копии также накладывают ограничения на версию программного обеспечения целевой базы данных и операционную систему. Приложив некоторые усилия, вы сможете восстановить логическую резервную копию из MySQL в PostgreSQL. Однако холодная копия каталога данных MySQL, сделанная в Linux, может не работать при восстановлении в Windows. Кроме того, вы не можете сделать физическую резервную копию, если у вас нет физического доступа к серверу базы данных. Это означает, что выполнение такого резервного копирования управляемой базы данных в облаке невозможно: поставщик может выполнять физические резервные копии в фоновом режиме, но у вас может не быть возможности их извлечь.
Поскольку физическая резервная копия по своей природе является копией всех или подмножества исходных страниц резервной копии, любое повреждение, присутствующее в оригинале, будет включено в резервную копию. Это важно помнить, потому что это свойство делает физические резервные копии малопригодными для борьбы с повреждением.
Вы можете удивиться, зачем использовать такой, казалось бы, неудобный способ резервного копирования. Причина в том, что физические резервные копии выполняются быстро. Физические методы резервного копирования, работающие на уровне ОС или даже на уровне хранилища, иногда являются единственным возможным способом фактического резервного копирования базы данных. Например, моментальный снимок хранилища многотерабайтного тома может занять несколько секунд или минут, тогда как запрос и потоковая передача этих данных для логического резервного копирования могут занять часы или дни. То же самое касается восстановления.
Обзор логических и физических резервных копий
Теперь мы рассмотрели две категории резервных копий и готовы приступить к изучению реальных инструментов, используемых для этих резервных копий в мире MySQL. Прежде чем мы это сделаем, давайте обобщим различия между логическими и физическими резервными копиями и кратко рассмотрим свойства инструментов, используемых для их создания.
Свойства логических резервных копий:
Содержат описание и содержание логических структур
Являются удобочитаемыми и редактируемыми
Относительно медленно создаются и восстанавливаются
Инструменты логического резервного копирования:
-
Очень гибкие, позволяющие переименовывать объекты, объединять отдельные источники, выполнять частичное восстановление и многое другое.
-
Обычно не привязаны к конкретной версии базы данных или платформе
-
Имеют возможность извлекать данные из поврежденных таблиц и защищать от повреждения
-
Подходят для резервного копирования удаленных баз данных (например, в облаке)
Свойства физических резервных копий:
-
Представляют собой побайтовые копии частей файлов данных или целых файловых систем/томов.
-
Быстро создаются и восстанавливаются
-
Предлагают небольшую гибкость и всегда приводит к одной и той же структуре при восстановлении.
-
Могут включать поврежденные страницы
Инструменты физического резервного копирования:
-
Громоздкие в эксплуатации
-
Обычно не допускают простой кроссплатформенности или даже переносимости между версиями.
-
С ними не удастся выполнить резервное копирование удаленных баз данных без доступа к ОС
Репликация как средство резервного копирования
Репликация — очень широкая тема, которая подробно рассматривается в следующих главах. В этом разделе мы кратко обсудим, как репликация связана с концепцией резервного копирования и восстановления базы данных.
Короче говоря, репликация не заменяет создание резервных копий. Специфика репликации такова, что в результате получается полная или частичная копия целевой базы данных. Это позволяет использовать репликацию во многих, но не во всех, возможных сценариях отказа, связанных с MySQL. Давайте рассмотрим два примера. Они будут полезны и позже в этой главе.
Сбой инфраструктуры
Инфраструктура подвержена сбоям: диски выходят из строя, отключается питание, случаются пожары. Практически ни одна система не может обеспечить 100%-ную безотказную работу, и только сильно распределенные системы могут приблизиться к этому. Это означает, что в конечном итоге любая база данных выйдет из строя из-за сбоя на главном сервере. В лучшем случае для восстановления может быть достаточно перезагрузки. В худшем — часть или все данные могут быть потеряны.
Восстановление резервной копии ни в коем случае не является мгновенной операцией. В реплицируемой среде для установки реплики на место вышедшей из строя базы данных может быть выполнена специальная операция, называемая переключением (switchover). Во многих случаях переключение экономит много времени и позволяет без особой спешки приступить к работе над вышедшей из строя системой.
Представьте себе установку с двумя идентичными серверами, работающими под управлением MySQL. Один из них — выделенный первичный, который получает все подключения и обслуживает все запросы. Другой — реплика. Существует механизм перенаправления подключений к реплике, при этом переключение приводит к 5-минутному простою.
Однажды на основном сервере выходит из строя жесткий диск. Это простой сервер, так что само по себе это приводит к сбоям и простоям. Мониторинг выявляет проблему, и администратор базы данных сразу понимает, что для восстановления базы данных на этом сервере ему потребуется установить новый диск, а затем восстановить последнюю резервную копию. Вся операция займет пару часов.
В этом случае переход на реплику является хорошей идеей, поскольку это экономит много ценного времени безотказной работы.
Ошибка развертывания
Ошибки в программном обеспечении — это факт жизни, который необходимо принять. Чем сложнее система, тем выше вероятность логических ошибок. Хотя все мы стремимся ограничить и уменьшить количество ошибок, мы должны понимать, что они будут возникать, и планировать их соответствующим образом.
Представьте, что выпущена новая версия приложения, включающая сценарий миграции базы данных. Несмотря на то, что и новая версия, и сценарий были протестированы в последующих средах, в них есть ошибка. Миграция безвозвратно искажает фамилии всех клиентов, которые содержат «специальные» не-ASCII символы. О повреждении не сообщается, так как скрипт успешно завершается, и только неделю спустя разгневанный клиент, чье имя теперь указано неверно, замечает проблему.
Несмотря на то, что существует реплика рабочей базы данных, в ней те же данные и те же логические повреждения. Переход на реплику в этом случае не поможет, и необходимо восстановить резервную копию, сделанную до миграции, чтобы получить список правильных фамилий.
Два только что рассмотренных сценария отказа охватывают две различные области: физическую и логическую. Репликация хорошо подходит для защиты от физических проблем, в то время как она не обеспечивает (или обеспечивает лишь небольшую) защиту от логических проблем. Репликация — полезный инструмент, но она не может заменить резервное копирование.
Программа mysqldump
Возможно, самый простой способ создать резервную копию базы данных в режиме онлайн — это выгрузить ее содержимое в виде инструкций SQL. Это наиболее распространенный тип логического резервного копирования. В вычислительной технике под получением дампа обычно подразумевается вывод содержимого некоторой системы или ее частей, в результате чего создается дамп. В мире баз данных дамп обычно представляет собой логическую резервную копию, а получение дампа — это действие по получению такой резервной копии. Восстановление резервной копии включает в себя применение инструкций к базе данных. Вы можете создавать дампы вручную, используя, например, SHOW CREATE TABLE и некоторые операции CONCAT для получения операторов INSERT из строк данных в таблицах, например:
mysql> SHOW CREATE TABLE sakila.actor\G
*************************** 1. row ***************************
Table: actor
Create Table: CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> SELECT CONCAT("INSERT INTO actor VALUES",
-> "(",actor_id,",'",first_name,"','",
-> last_name,"','",last_update,"');")
-> AS insert_statement FROM actor LIMIT 1\G
*************************** 1. row ***************************
insert_statement: INSERT INTO actor VALUES
(1,'PENELOPE','GUINESS','2006-02-15 04:34:33');
1 row in set (0.00 sec)
Однако это очень быстро становится крайне непрактичным. Более того, есть еще вещи, которые следует учитывать: порядок операторов, чтобы при восстановлении INSERT не запускался до создания таблицы, а также владение и согласованность. Хотя создание логических резервных копий вручную полезно для понимания, это утомительно и чревато ошибками. К счастью, MySQL поставляется с мощным инструментом логического резервного копирования под названием mysqldump, который скрывает большую часть сложности.
Программа mysqldump, входящая в состав MySQL, позволяет создавать дампы запущенных экземпляров базы данных. Вывод mysqldump представляет собой ряд операторов SQL, которые впоследствии могут быть применены к тому же или другому экземпляру MySQL. mysqldump — это кроссплатформенный инструмент, доступный во всех операционных системах, в которых доступен сам сервер MySQL. Поскольку результирующий файл резервной копии состоит из большого количества текста, он также не зависит от платформы.
Аргументы командной строки для mysqldump многочисленны, поэтому разумно просмотреть Справочное руководство по MySQL, прежде чем переходить к использованию этого инструмента. Однако в самом простом сценарии требуется только один аргумент: имя целевой базы данных.
В следующем примере mysqldump вызывается без перенаправления вывода, и инструмент выводит все операторы на стандартный вывод:
$ mysqldump sakila
...
--
-- Table structure for table `actor`
--
DROP TABLE IF EXISTS `actor`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `actor`
--
LOCK TABLES `actor` WRITE;
/*!40000 ALTER TABLE `actor` DISABLE KEYS */;
INSERT INTO `actor` VALUES
(1,'PENELOPE','GUINESS','2006-02-15 01:34:33'),
(2,'NICK','WAHLBERG','2006-02-15 01:34:33'),
...
(200,'THORA','TEMPLE','2006-02-15 01:34:33');
/*!40000 ALTER TABLE `actor` ENABLE KEYS */;
UNLOCK TABLES;
...
Вы можете заметить, что этот вывод более детализирован, чем вы могли ожидать. Например, есть оператор DROP TABLE IF EXISTS, который предотвращает ошибку для следующей команды CREATE TABLE, когда таблица уже существует в целевом объекте. Операторы LOCK и UNLOCK TABLES улучшат производительность вставки данных и так далее.
Говоря о структуре схемы, можно создать дамп без данных. Это может быть полезно для создания логического клона базы данных, например, для среды разработки. Подобная гибкость является одной из ключевых особенностей логических резервных копий и mysqldump:
$ mysqldump --no-data sakila
...
--
-- Table structure for table `actor`
--
DROP TABLE IF EXISTS `actor`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Temporary view structure for view `actor_info`
--
...
Также возможно создать дамп одной таблицы в базе данных. В следующем примере sakila — это база данных, а category — целевая таблица:
$ mysqldump sakila categoryПовышая гибкость, вы можете вывести всего несколько строк из таблицы, указав аргумент --where или -w. Как следует из названия, синтаксис такой же, как и для предложения WHERE в операторе SQL:
$ mysqldump sakila actor --where="actor_id > 195"
...
--
-- Table structure for table `actor`
--
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
...
--
-- Dumping data for table `actor`
--
-- WHERE: actor_id > 195
LOCK TABLES `actor` WRITE;
/*!40000 ALTER TABLE `actor` DISABLE KEYS */;
INSERT INTO `actor` VALUES
(196,'BELA','WALKEN','2006-02-15 09:34:33'),
(197,'REESE','WEST','2006-02-15 09:34:33'),
(198,'MARY','KEITEL','2006-02-15 09:34:33'),
(199,'JULIA','FAWCETT','2006-02-15 09:34:33'),
(200,'THORA','TEMPLE','2006-02-15 09:34:33');
/*!40000 ALTER TABLE `actor` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
Приведенные до сих пор примеры касались только дампа всей или части единой базы данных: sakila. Иногда необходимо вывести каждую базу данных, каждый объект и даже каждого пользователя. mysqldump на это способен. Следующая команда эффективно создаст полную логическую резервную копию экземпляра базы данных:
$ mysqldump --all-databases --triggers --routines --events > dump.sqlТриггеры сбрасываются по умолчанию, поэтому этот параметр не будет отображаться в выводах команды в будущем. Если вы не хотите сбрасывать триггеры, вы можете использовать --no-triggers.
Однако есть пара проблем с этой командой. Во-первых, несмотря на то, что мы перенаправили вывод команды в файл, результирующий файл может быть огромным. К счастью, его содержимое, вероятно, хорошо подходит для сжатия, хотя это зависит от фактических данных. В любом случае рекомендуется сжать вывод:
$ mysqldump --all-databases \
--routines --events | gzip > dump.sql.gz
В Windows сжатие вывода через канал затруднено, поэтому просто сожмите файл dump.sql, созданный при выполнении предыдущей команды. В системе с перегруженным процессором, такой как небольшая виртуальная машина, которую мы здесь используем, сжатие может значительно увеличить время процесса резервного копирования. Это компромисс, который необходимо взвесить для вашей конкретной системы:
$ time mysqldump --all-databases \
--routines --events > dump.sql
real 0m24.608s
user 0m15.201s
sys 0m2.691s
$ time mysqldump --all-databases \
--routines --events | gzip > dump.sql.gz
real 2m2.769s
user 2m4.400s
sys 0m3.115s
$ ls -lh dump.sql
-rw... 2.0G ... dump.sql
-rw... 794M ... dump.sql.gz
Вторая проблема заключается в том, что для обеспечения согласованности на таблицы будут наложены блокировки, предотвращающие запись во время создания дампа базы данных (запись в другие базы данных может продолжаться). Это плохо как для производительности, так и для согласованности резервного копирования. Результирующий дамп согласован только внутри базы данных, а не во всем экземпляре. Такое поведение по умолчанию необходимо, поскольку некоторые механизмы хранения, используемые MySQL, не являются транзакционными (в основном, более старые MyISAM). Механизм хранения InnoDB по умолчанию, с другой стороны, имеет модель многоверсионного управления параллелизмом (MVCC), которая позволяет поддерживать моментальный снимок чтения. Мы более подробно рассмотрели различные подсистемы хранения в разделе «Альтернативные механизмы хранения», а блокировку — в главе 6.
Использование транзакционных возможностей InnoDB возможно путем передачи аргумента командной строки --single-transaction в mysqldump. Однако это устраняет блокировку таблицы, что делает нетранзакционные таблицы подверженными несогласованности во время дампа. Если ваша система использует, например, и таблицы InnoDB, и таблицы MyISAM, для них может потребоваться отдельное создание дампа, если не требуется прерывание записи и непротиворечивость.
Основная команда для создания дампа системы, использующая в основном таблицы InnoDB, которая гарантирует ограниченное влияние на одновременную запись, выглядит следующим образом:
$ mysqldump --single-transaction --all-databases \
--routines --events | gzip > dump.sql.gz
В реальном мире у вас, вероятно, будет больше аргументов для указания параметров подключения. Вы также можете написать сценарий вокруг инструкции mysqldump, чтобы выявить любые проблемы и уведомить вас, если что-то пойдет не так.
Дамп с --all-databases включает внутренние базы данных MySQL, такие как mysql, sys и information_schema. Эта информация не всегда необходима для восстановления ваших данных и может вызвать проблемы при восстановлении в экземпляр, в котором уже есть некоторые базы данных. Тем не менее, вы должны помнить, что данные пользователя MySQL будут выгружаться только как часть базы данных mysql.
В целом, использование mysqldump и создаваемых им логических резервных копий позволяет:
-
Легкую передачу данных между средами.
-
Редактирование данных на месте как людьми, так и программами. Например, вы можете удалить из дампа личные или ненужные данные.
-
Обнаруживать определенные повреждения файла данных.
-
Переносить данные между основными версиями баз данных, разными платформами и даже базами данных.
Запуск репликации с помощью mysqldump
Программу mysqldump можно использовать для создания экземпляра реплики либо пустого, либо с данными. Для этого доступно несколько аргументов командной строки. Например, если указан параметр --master-data, результирующий вывод будет содержать оператор SQL (CHANGE MASTER TO), который правильно установит координаты репликации на целевом экземпляре. Когда позднее репликация будет запущена с использованием этих координат на целевом экземпляре, пробелов в данных не будет. В топологии репликации на основе GTID можно использовать --set-gtid-purged для достижения того же результата. Однако mysqldump обнаружит параметр gtid_mode=ON, и включит необходимые выходные данные даже без дополнительных аргументов командной строки.
Пример настройки репликации с помощью mysqldump приведен в разделе «Создание реплики с помощью mysqldump».
Загрузка данных из файла дампа SQL
При выполнении резервного копирования всегда важно помнить, что вы делаете это, чтобы иметь возможность впоследствии восстановить данные. При логическом резервном копировании процесс восстановления так же прост, как передача содержимого файла резервной копии в интерфейс командной строки mysql. Как обсуждалось ранее, тот факт, что MySQL должна быть готова к логическому восстановлению из резервной копии, имеет как хорошие, так и плохие последствия:
-
Вы можете восстановить один объект, в то время как другие части вашей системы продолжают работать нормально, что является плюсом.
-
Процесс восстановления неэффективен и будет нагружать систему так же, как любой обычный клиент, если он решит вставить большой объем данных. Это минус.
Давайте рассмотрим простой пример резервного копирования и восстановления одной базы данных. Как мы видели ранее, mysqldump включит в дамп необходимые операторы DROP, так что даже если объекты присутствуют, они будут успешно восстановлены:
$ mysqldump sakila > /tmp/sakila.sql
$ mysql -e "CREATE DATABASE sakila_mod"
$ mysql sakila_mod < /tmp/sakila.sql
$ mysql sakila_mod -e "SHOW TABLES"
+----------------------------+
| Tables_in_sakila_mod |
+----------------------------+
| actor |
| actor_info |
| ... |
| store |
+----------------------------+
Восстановление SQL-дампов, подобных тому, которые создаются с помощью mysqldump или mysqlpump (обсуждается в следующем разделе), требует больших ресурсов. По умолчанию это также последовательный процесс, который может занять значительное время. Есть несколько приемов, которые вы можете использовать, чтобы ускорить этот процесс, но имейте в виду, что ошибки могут привести к потере или неправильному восстановлению данных. Варианты включают:
Параллельное восстановление для каждой схемы/базы данных
Параллельное восстановление объектов в схеме
Первое легко сделать, если дамп с помощью mysqldump выполняется для каждой базы данных. Процесс резервного копирования также можно распараллелить, если не требуется согласованность между базами данных (она не гарантируется). В следующем примере используется модификатор &, который указывает оболочке выполнить предыдущую команду в фоновом режиме:
$ mysqldump sakila > /tmp/sakila.sql &
$ mysqldump nasa > /tmp/nasa.sql &
Полученные дампы независимы. mysqldump не обрабатывает пользователей и привилегии, если не создается дамп базы данных mysql, поэтому вам нужно позаботиться об этом отдельно. Восстановление так же просто:
$ mysql sakila < /tmp/sakila.sql &
$ mysql nasa < /tmp/nasa.sql &
В Windows также можно отправить выполнение команды в фоновый режим с помощью команды PowerShell Start-Process или, в более поздних версиях, того же &.
Второй вариант немного сложнее. Либо вам нужно сделать дамп отдельно для каждой таблицы (например, mysqldump sakila artist > sakila.artists.sql), что приводит к прямому восстановлению, либо вам нужно отредактировать файл дампа, чтобы разделить его на несколько. В крайнем случае вы даже можете распараллелить вставку данных на уровне таблицы, хотя это, вероятно, не будет практичным.
Хотя это выполнимо, предпочтительнее использовать инструменты, специально созданные для этой задачи.
mysqlpump
mysqlpump — это служебная программа, входящая в состав MySQL версии 5.7 и более поздних, которая улучшает mysqldump в нескольких областях, в основном в отношении производительности и удобства использования. Ключевые отличия заключаются в следующем:
-
Возможность параллельного дампа
-
Встроенное сжатие дампа
-
Улучшена производительность восстановления благодаря отложенному созданию вторичных индексов.
-
Более легкий контроль над тем, какие объекты выгружаются
-
Изменено поведение дампа учетных записей пользователей
Использование программы очень похоже на использование mysqldump. Главное непосредственное отличие состоит в том, что, когда никакие аргументы не передаются, mysqlpump по умолчанию выгружает все базы данных (за исключением INFORMATION_SCHEMA, performance_schema, ndbinfo и схемы sys). Другими примечательными вещами являются наличие индикатора выполнения и то, что mysqlpump по умолчанию использует параллельный дамп с двумя потоками:
$ mysqlpump > pump.out
Dump progress: 1/2 tables, 0/530419 rows
Dump progress: 80/184 tables, 2574413/646260694 rows
...
Dump progress: 183/184 tables, 16297773/646260694 rows
Dump completed in 10680
Концепция параллелизма в mysqlpump несколько сложна. Вы можете использовать параллелизм между разными базами данных и между разными объектами в данной базе данных. По умолчанию, когда никакие другие параллельные параметры не указаны, mysqlpump будет использовать одну очередь с двумя параллельными потоками для обработки всех баз данных и пользовательских определений (если требуется). Вы можете управлять уровнем параллелизма очереди по умолчанию, используя аргумент --default-parallelism. Для дальнейшей точной настройки параллелизма можно настроить несколько параллельных очередей для обработки отдельных баз данных. Будьте осторожны при выборе желаемого уровня параллелизма, так как в конечном итоге вы можете использовать большую часть ресурсов базы данных для выполнения резервного копирования.
Важное отличие от mysqldump при использовании mysqlpump заключается в том, как последний обрабатывает учетные записи пользователей. mysqldump управляет пользователями, создавая дамп mysql.user и других соответствующих таблиц. Если база данных mysql не была включена в дамп, никакая пользовательская информация не будет сохранена. mysqlpump улучшает это, вводя аргументы командной строки --users и --include-users. Первый говорит утилите добавить в дамп пользовательские команды для всех пользователей, а второй принимает список имен пользователей. Это большое улучшение по сравнению со старым способом ведения дел.
Давайте объединим все новые функции для создания сжатого дампа несистемных баз данных и пользовательских определений и используем параллелизм в процессе:
$ mysqlpump --compress-output=zlib --include-users=bob,kate \
--include-databases=sakila,nasa,employees \
--parallel-schemas=2:employees \
--parallel-schemas=sakila,nasa > pump.out
Dump progress: 1/2 tables, 0/331579 rows
Dump progress: 19/23 tables, 357923/3959313 rows
...
Dump progress: 22/23 tables, 3755358/3959313 rows
Dump completed in 10098
Дамп, полученный в результате запуска mysqlpump, не подходит для параллельного восстановления, поскольку данные внутри него чередуются. Например, следующий результат выполнения mysqlpump показывает создание таблицы среди вставок в таблицы в разных базах данных:
...,(294975,"1955-07-31","Lucian","Rosis","M","1986-12-08");
CREATE TABLE `sakila`.`store` (
`store_id` tinyint unsigned NOT NULL AUTO_INCREMENT,
`manager_staff_id` tinyint unsigned NOT NULL,
`address_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT
CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`store_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT
CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
;
INSERT INTO `employees`.`employees` VALUES
(294976,"1961-03-19","Rayond","Khalid","F","1989-11-03"),...
mysqlpump является улучшением по сравнению с mysqldump и добавляет важные функции параллелизма, сжатия и управления объектами. Однако инструмент не позволяет параллельно восстанавливать дамп и фактически делает это невозможным. Единственное улучшение производительности восстановления заключается в том, что вторичные индексы добавляются после завершения основной загрузки.
mydumper и myloader
mydumper и myloader являются частью проекта mydumper с открытым исходным кодом. Этот набор инструментов пытается сделать логическое резервное копирование более производительным, простым в управлении и более удобным для человека. Мы не будем вдаваться здесь слишком глубоко, так как в книге, охватывающей все возможные варианты резервного копирования MySQL, может не хватить места.
Эти программы можно установить, взяв самую свежую версию со страницы проекта на GitHub или скомпилировав исходный код. На момент написания последний релиз несколько отставал от основной ветки. Пошаговые инструкции по установке доступны в разделе «Настройка утилит mydumper и myloader».
Ранее мы показали, как mysqlpump повышает производительность дампа, но упоминали, что его переплетенные выходные данные не помогают при восстановлении. mydumper сочетает в себе подход параллельного дампа с подготовкой основания для параллельного восстановления с помощью myloader. Это достигается путем выгрузки каждой таблицы в отдельный файл.
Вызов mydumper по умолчанию очень прост. Инструмент пытается подключиться к базе данных, инициирует согласованный дамп и создает каталог под текущим для файлов экспорта. Обратите внимание, что каждая таблица имеет свой собственный файл. По умолчанию mydumper также создает дамп баз данных mysql и sys. Параметр параллелизма по умолчанию для операции дампа равен 4, что означает одновременное чтение четырех отдельных таблиц. myloader, запущенный в этом каталоге, сможет восстанавливать таблицы параллельно.
Чтобы создать дамп и изучить его, выполните следующие команды:
$ mydumper -u root -a
Enter the MySQL password:
$ ls -ld export
drwx... export-20210613-204512
$ ls -la export-20210613-204512
...
-rw... sakila.actor.sql
-rw... sakila.address-schema.sql
-rw... sakila.address.sql
-rw... sakila.category-schema.sql
-rw... sakila.category.sql
-rw... sakila.city-schema.sql
-rw... sakila.city.sql
...
Помимо возможностей параллельного дампа и восстановления, mydumper имеет еще несколько дополнительных функций:
-
Поддержка легковесных блокировок при резервном копировании Percona Server для MySQL реализует некоторую дополнительную облегченную блокировку, используемую Percona XtraBackup.
mydumperиспользует эти блокировки по умолчанию, когда это возможно. Эти блокировки не блокируют одновременное чтение и запись в таблицы InnoDB, но блокируют любые операторы DDL, которые в противном случае могли бы сделать резервную копию недействительной. -
Использование точек сохранения.
mydumperиспользует трюк с точками сохранения транзакций, чтобы свести к минимуму блокировку метаданных. -
Ограничения на продолжительность блокировки метаданных. Чтобы обойти длительную блокировку метаданных, проблему, которую мы описали в разделе «Блокировки метаданных»,
mydumperдопускает два варианта: быстрое завершение работы с ошибкой или завершение длительных запросов, препятствующих успешной работеmydumper.
mydumper и myloader — это продвинутые инструменты, максимально использующие возможности логического резервного копирования. Однако, поскольку они являются частью проекта сообщества, им не хватает документации и завершенности, которые обеспечивают другие инструменты. Еще одним серьезным недостатком является отсутствие какой-либо поддержки или гарантий. Тем не менее, они могут быть полезным дополнением к набору инструментов оператора базы данных.
Холодное резервное копирование и моментальные снимки файловой системы
Краеугольный камень физических резервных копий, холодная резервная копия — это просто копия каталога данных и других необходимых файлов, сделанная, когда экземпляр базы данных не работает. Этот метод используется нечасто, но он может спасти день, когда вам нужно быстро создать непротиворечивую резервную копию. Теперь, когда размеры баз данных регулярно приближаются к диапазону размеров в несколько терабайт, простое копирование файлов может занять очень много времени. Тем не менее, у холодного резервного копирования все же есть свои плюсы:
-
Очень быстрое (вероятно, самый быстрый метод резервного копирования, кроме моментальных снимков)
-
Простое
-
Простое в использовании, трудно сделать неправильно
Современные системы хранения и некоторые файловые системы имеют легкодоступные возможности моментальных снимков. Они позволяют создавать почти мгновенные копии томов произвольного размера, используя внутренние механизмы. Свойства различных систем, поддерживающих моментальные снимки, сильно различаются, поэтому мы не можем охватить их все. Тем не менее, мы все еще можем немного поговорить о них с точки зрения базы данных.
Большинство моментальных снимков будут копироваться при записи (copy-on-write) (COW) и внутренне непротиворечивы в какой-то момент времени. Однако мы уже знаем, что файлы базы данных несовместимы на диске, особенно с механизмами хранения транзакций, такими как InnoDB. Это несколько затрудняет правильное создание резервной копии моментального снимка. Есть два варианта:
- Моментальный снимок холодного резервного копирования
-
Когда база данных закрыта, ее файлы данных все еще могут быть не полностью согласованными. Но если вы сделаете снимок всех файлов базы данных (включая, например, журналы повторов InnoDB), вместе они позволят запустить базу данных. Это вполне естественно, потому что в противном случае база данных теряла бы данные при каждом перезапуске. Не забывайте, что у вас могут быть файлы базы данных, разделенные на множество томов. Вам нужно будет иметь их все. Этот метод будет работать для всех механизмов хранения.
- Горячий резервный снимок
-
При работающей базе данных правильное создание моментального снимка является более сложной задачей, чем когда база данных не работает. Если файлы вашей базы данных расположены на нескольких томах, вы не можете гарантировать, что моментальные снимки, даже инициированные одновременно, будут соответствовать одному и тому же моменту времени, что может привести к катастрофическим результатам. Кроме того, нетранзакционные механизмы хранения, такие как MyISAM, не гарантируют согласованности файлов на диске во время работы базы данных. На самом деле это верно и для InnoDB, но журналы повторов InnoDB всегда согласуются (если только не отключены меры безопасности), а MyISAM не имеет этой функциональности.
Поэтому рекомендуемый способ сделать моментальный снимок горячего резервного копирования — использовать некоторую степень блокировки. Поскольку процесс создания моментального снимка обычно быстрый, возникающее время простоя не должно быть значительным. Вот процесс:
-
Создайте новый сеанс и заблокируйте все таблицы с помощью команды
FLUSH TABLES WITH READ LOCK. Этот сеанс нельзя закрывать, иначе блокировки будут сняты. -
При необходимости запишите текущую позицию binlog, выполнив команду
SHOW MASTER STATUS. -
Создайте снимки всех томов, на которых расположены файлы базы данных MySQL, в соответствии с руководством по системе хранения.
-
Разблокируйте таблицы с помощью команды
UNLOCK TABLESв первоначально открытом сеансе.
Этот общий подход должен подойти для большинства, если не для всех существующих систем хранения и файловых систем, способных делать моментальные снимки. Обратите внимание, что все они немного отличаются по фактической процедуре и требованиям. Некоторые поставщики облачных услуг требуют, чтобы вы дополнительно выполнили fsfreeze в файловых системах.
Всегда тщательно проверяйте свои резервные копии, прежде чем внедрять их в производство и доверять им свои данные. Вы можете доверять только тому решению, которое вы протестировали и которым удобно пользоваться. Копирование произвольных предложений стратегии резервного копирования — не очень хорошая идея.
Percona XtraBackup
Логическим шагом вперед в физическом резервном копировании является внедрение так называемого горячего резервного копирования, т. е. создание копии файлов базы данных во время работы базы данных. Мы уже упоминали, что таблицы MyISAM можно копировать, но это не работает для InnoDB и других механизмов хранения транзакций, таких как MyRocks. Поэтому проблема в том, что вы не можете просто скопировать файлы, потому что база данных постоянно претерпевает изменения. Например, InnoDB может сбрасывать некоторые грязные страницы в фоновом режиме, даже если прямо сейчас в базу данных не поступает никаких записей. Вы можете испытать удачу и скопировать каталог базы данных в работающей системе, а затем попытаться восстановить этот каталог и запустить сервер MySQL, используя его. Скорее всего, это не сработает. И хотя иногда это может сработать, мы настоятельно рекомендуем не рисковать с резервным копированием базы данных.
Возможность выполнения горячего резервного копирования встроена в три основных инструмента резервного копирования MySQL: Percona XtraBackup, MySQL Enterprise Backup и mariabackup. Мы кратко расскажем обо всех из них, но в основном сконцентрируемся на утилите XtraBackup. Важно понимать, что все инструменты имеют общие свойства, поэтому знание того, как использовать один, поможет вам использовать другие.
Percona XtraBackup — это бесплатный инструмент с открытым исходным кодом, поддерживаемый Percona и более широким сообществом MySQL. Он способен выполнять онлайн-резервное копирование экземпляров MySQL с таблицами InnoDB, MyISAM и MyRocks. Программа доступна только для Linux. Обратите внимание, что невозможно использовать XtraBackup с последними версиями MariaDB: поддерживаются только MySQL и Percona Server. Для MariaDB используйте утилиту, которую мы рассматриваем в «mariabackup».
Вот обзор того, как работает утилита XtraBackup:
-
Записывает текущий порядковый номер журнала (LSN), внутренний номер версии операции.
-
Начинает накапливать данные повторного выполнения InnoDB (тип данных, которые InnoDB хранит для восстановления после сбоя)
-
Блокирует таблицы наименее навязчивым способом
-
Копирует таблицы InnoDB
-
Полностью блокирует нетранзакционные таблицы
-
Копирует таблицы MyISAM
-
Разблокирует все таблицы
-
Обрабатывает таблицы MyRocks, если они есть
-
Помещает накопленные данные повторного выполнения вместе с скопированными файлами базы данных.
Основная идея, лежащая в основе XtraBackup и горячего резервного копирования в целом, заключается в сочетании отсутствия простоя логического резервного копирования с производительностью и относительным отсутствием влияния на производительность холодного резервного копирования. XtraBackup не гарантирует бесперебойной работы, но это большой шаг вперед по сравнению с обычным холодным резервным копированием. Отсутствие влияния на производительность означает, что XtraBackup будет использовать некоторое количество ЦП и операций ввода-вывода, но только то, что необходимо для копирования файлов базы данных. С другой стороны, логические резервные копии должны пропускать каждую строку через все внутренние компоненты базы данных, что по своей сути делает их медленными.
Утилита XtraBackup широко доступна в репозиториях различных дистрибутивов Linux, поэтому ее легко установить с помощью диспетчера пакетов. Кроме того, вы можете загружать пакеты и бинарные дистрибутивы непосредственно со страницы загрузок XtraBackup на веб-сайте Percona.
Резервное копирование и восстановление
В отличие от других инструментов, о которых мы упоминали ранее, XtraBackup, по своей природе являющийся инструментом физического резервного копирования, требует не только доступа к серверу MySQL, но и доступа для чтения к файлам базы данных. В большинстве установок MySQL это обычно означает, что программа xtrabackup должна запускаться пользователем root или должна использоваться sudo. В этом разделе мы будем использовать пользователя root и настроим путь входа в систему, используя шаги из раздела «Файл конфигурации пути входа в систему».
Во-первых, нам нужно запустить основную команду xtrabackup:
# xtrabackup --host=127.0.0.1 --target-dir=/tmp/backup --backup
...
Using server version 8.0.25
210613 22:23:06 Executing LOCK INSTANCE FOR BACKUP...
...
210613 22:23:07 [01] Copying ./sakila/film.ibd to /tmp/backup/sakila/film.ibd
210613 22:23:07 [01] ...done
...
210613 22:23:10 [00] Writing /tmp/backup/xtrabackup_info
210613 22:23:10 [00] ...done
xtrabackup: Transaction log of lsn (6438976119) to (6438976129) was copied.
210613 22:23:11 completed OK!
Если путь входав систему не работает, вы можете передать учетные данные пользователя root в xtrabackup, используя аргументы командной строки --user и --password. XtraBackup обычно может определить каталог данных целевого сервера, прочитав файлы опций по умолчанию, но если это не работает или у вас несколько установок MySQL, вам может потребоваться также указать параметр --datadir. Несмотря на то, что xtrabackup работает только локально, ему все же необходимо подключиться к локально работающему экземпляру MySQL, и поэтому он имеет аргументы --host, --port и --socket. Возможно, вам придется указать некоторые из них в соответствии с вашей конкретной настройкой.
Результатом этого вызова xtrabackup --backup является набор файлов базы данных, которые на самом деле не соответствуют ни одному моменту времени, и фрагмент данных повторного выполнения, которые InnoDB не сможет применить:
# ls -l /tmp/backup/
...
drwxr-x---. 2 root root 160 Jun 13 22:23 mysql
-rw-r-----. 1 root root 46137344 Jun 13 22:23 mysql.ibd
drwxr-x---. 2 root root 60 Jun 13 22:23 nasa
drwxr-x---. 2 root root 580 Jun 13 22:23 sakila
drwxr-x---. 2 root root 580 Jun 13 22:23 sakila_mod
drwxr-x---. 2 root root 80 Jun 13 22:23 sakila_new
drwxr-x---. 2 root root 60 Jun 13 22:23 sys
...
Чтобы сделать резервную копию готовой к будущему восстановлению, необходимо выполнить еще один этап — подготовку. Для этого не нужно подключаться к серверу MySQL:
# xtrabackup --target-dir=/tmp/backup --prepare
...
xtrabackup: cd to /tmp/backup/
xtrabackup: This target seems to be not prepared yet.
...
Shutdown completed; log sequence number 6438976524
210613 22:32:23 completed OK!
Результирующий каталог данных фактически полностью готов к использованию. Вы можете запустить экземпляр MySQL, указывающий непосредственно на этот каталог, и он будет работать. Очень распространенной ошибкой здесь является попытка запустить MySQL Server под пользователем mysql, в то время как восстановленная и подготовленная резервная копия принадлежит пользователю root или другому пользователю ОС. Не забудьте включить chown и chmod в процедуру восстановления из резервной копии. Тем не менее, есть полезная функция --copy-back. xtrabackup сохраняет исходные расположения файлов базы данных, а вызов --copy-back восстановит все файлы в их исходные расположения:
# xtrabackup --target-dir=/tmp/backup --copy-back
...
Original data directory /var/lib/mysql is not empty!
Это не сработало, потому что наш исходный сервер MySQL все еще работает, и его каталог данных не пуст. XtraBackup откажется восстанавливать резервную копию, если целевой каталог данных не пуст. Это должно защитить вас от случайного восстановления резервной копии. Давайте выключим работающий сервер MySQL, удалим или переместим его каталог данных и восстановим резервную копию:
# systemctl stop mysqld
# mv /var/lib/mysql /var/lib/mysql_old
# xtrabackup --target-dir=/tmp/backup --copy-back
...
210613 22:39:01 [01] Copying ./sakila/actor.ibd to /var/lib/mysql/sakila/actor.ibd
210613 22:39:01 [01] ...done
...
210613 22:39:01 completed OK!
После этого файлы находятся в своих правильных местах, но принадлежат пользователю root:
# ls -l /var/lib/mysql/
drwxr-x---. 2 root root 4096 Jun 13 22:39 sakila
drwxr-x---. 2 root root 4096 Jun 13 22:38 sakila_mod
drwxr-x---. 2 root root 4096 Jun 13 22:39 sakila_new
Вам нужно будет изменить владельца файлов обратно на mysql (или пользователя, используемого в вашей системе) и исправить права доступа к каталогу. Как только это будет сделано, вы можете запустить MySQL и проверить данные:
# chown -R mysql:mysql /var/lib/mysql/
# chmod o+rx /var/lib/mysql/
# systemctl start mysqld
# mysql sakila -e "SHOW TABLES;"
+----------------------------+
| Tables_in_sakila |
+----------------------------+
| actor |
...
| store |
+----------------------------+
Расширенные возможности
В этом разделе мы обсудим некоторые из более продвинутых функций XtraBackup. Они не обязательны для использования инструмента, и мы приводим их просто в качестве краткого обзора:
- Проверка файла базы данных
-
При выполнении резервного копирования XtraBackup проверит контрольные суммы всех страниц обрабатываемых файлов данных. Это попытка облегчить присущую физическим резервным копиям проблему, заключающуюся в том, что они будут содержать любые повреждения в исходной базе данных. Мы рекомендуем дополнить эту проверку другими шагами, перечисленными в разделе «Тестирование и проверка резервных копий».
- Сжатие
-
Несмотря на то, что копирование физических файлов происходит намного быстрее, чем запрос к базе данных, процесс резервного копирования может быть ограничен производительностью диска. Вы не можете уменьшить объем данных, которые вы читаете, но вы можете использовать сжатие, чтобы сделать саму резервную копию меньше, уменьшив объем данных, которые необходимо записать. Это особенно важно, когда местом назначения резервного копирования является сетевое расположение. Кроме того, вы просто будете использовать меньше места для хранения резервных копий. Обратите внимание, что, как мы показали в разделе «Программа mysqldump», сжатие системы с перегрузкой ЦП может фактически увеличить время, необходимое для создания резервной копии. XtraBackup использует инструмент
qpressдля сжатия. Этот инструмент доступен в пакетеpercona-release:# xtrabackup --host=127.0.0.1 \ --target-dir=/tmp/backup_compressed/ \ --backup --compress - Параллелизм
-
Процессы резервного копирования и обратного копирования можно запускать параллельно, используя аргумент командной строки
--parallel. - Шифрование
-
Помимо возможности работать с зашифрованными базами данных, XtraBackup также может создавать зашифрованные резервные копии.
- Потоковая передача
-
Вместо того, чтобы создавать каталог, полный резервных копий файлов, XtraBackup может выполнять потоковую передачу результирующей резервной копии в формате
xbstream. Это приводит к более портативным резервным копиям и позволяет интегрироваться сxbcloud. Например, вы можете передавать резервные копии через SSH. - Облачная загрузка
-
Резервные копии, сделанные с помощью XtraBackup, можно загружать в любое совместимое с S3 хранилище с помощью
xbcloud. S3 — это объектное хранилище Amazon и API, широко используемое многими компаниями. Этот инструмент работает только с резервными копиями, передаваемыми черезxbstream.
Инкрементное резервное копирование с помощью XtraBackup
Как описано ранее, горячее резервное копирование — это копия каждого байта информации в базе данных. Так XtraBackup работает по умолчанию. Но во многих случаях базы данных изменяются неравномерно: новые данные добавляются часто, в то время как старые данные меняются незначительно (или вообще не меняются). Например, новые финансовые отчеты могут добавляться каждый день, а счета могут изменяться, но в течение данной недели изменяется лишь небольшой процент счетов. Таким образом, следующим логическим шагом в улучшении горячего резервного копирования является добавление возможности выполнения так называемых инкрементных резервных копий, или резервных копий только измененных данных. Это позволит вам выполнять резервное копирование чаще, уменьшая потребность в пространстве.
Чтобы инкрементное резервное копирование работало, вам сначала нужно иметь полную резервную копию базы данных, называемую базовой резервной копией (base backup), иначе не из чего будет увеличиваться. Когда ваша базовая резервная копия будет готова, вы можете выполнить любое количество инкрементных резервных копий, каждая из которых будет состоять из изменений, внесенных с момента предыдущей (или из базовой резервной копии в случае первой инкрементной резервной копии). В крайнем случае вы можете создавать инкрементную резервную копию каждую минуту, достигая так называемого восстановления на момент времени (point-in-time recovery) (PITR), но это не очень практично, и, как вы скоро узнаете, есть лучшие способы сделать это.
Вот пример команд XtraBackup, которые можно использовать для создания базовой резервной копии, а затем добавочной резервной копии. Обратите внимание, как инкрементная резервная копия указывает на базовую резервную копию через аргумент --incremental-basedir:
# xtrabackup --host=127.0.0.1 \
--target-dir=/tmp/base_backup --backup
# xtrabackup --host=127.0.0.1 --backup \
--incremental-basedir=/tmp/base_backup \
--target-dir=/tmp/inc_backup1
Если вы проверите размеры резервной копии, вы увидите, что инкрементная резервная копия очень мала по сравнению с базовой резервной копией:
# du -sh /tmp/base_backup
2.2G /tmp/base_backup
6.0M /tmp/inc_backup1
Давайте создадим еще одну инкрементную резервную копию. В этом случае мы передадим каталог предыдущей инкрементной резервной копии в качестве базового каталога:
# xtrabackup --host=127.0.0.1 --backup \
--incremental-basedir=/tmp/inc_backup1 \
--target-dir=/tmp/inc_backup2
210613 23:32:20 completed OK!
Вам может быть интересно, можно ли указать каталог исходной базовой резервной копии в качестве --incremental-basedir для каждой новой инкрементной резервной копии. На самом деле это приводит к полностью корректной резервной копии, которая является разновидностью инкрементной резервной копии (или наоборот). Такие инкрементные резервные копии, которые содержат изменения, внесенные не только с момента предыдущего инкрементного резервного копирования, но и с момента создания базовой резервной копии, обычно называются кумулятивными резервными копиями. Инкрементные резервные копии, нацеленные на любую предыдущую резервную копию, называются дифференциальными резервными копиями. Кумулятивные инкрементные резервные копии обычно занимают больше места, но могут значительно сократить время, необходимое для этапа подготовки при восстановлении резервной копии.
Важно отметить, что процесс подготовки инкрементного резервного копирования отличается от процесса подготовки обычного резервного копирования. Давайте подготовим резервные копии, которые мы только что сделали, начиная с базовой резервной копии:
# xtrabackup --prepare --apply-log-only \
--target-dir=/tmp/base_backup
Аргумент --apply-log-only указывает xtrabackup не завершать процесс подготовки, поскольку нам все еще нужно применить изменения из инкрементных резервных копий. Давайте сделаем это:
# xtrabackup --prepare --apply-log-only \
--target-dir=/tmp/base_backup \
--incremental-dir=/tmp/inc_backup1
# xtrabackup --prepare --apply-log-only \
--target-dir=/tmp/base_backup \
--incremental-dir=/tmp/inc_backup2
Все команды должны сообщать completed OK! в конце. После запуска операции --prepare --apply-log-only базовая резервная копия переходит к точке инкрементной резервной копии, что делает невозможным PITR на более раннее время. Таким образом, не рекомендуется сразу же готовиться к выполнению инкрементого резервного копирования. Чтобы завершить процесс подготовки, базовая резервная копия с изменениями, примененными к инкрементным резервным копиям, должна быть подготовлена обычным образом:
# xtrabackup --prepare --target-dir=/tmp/base_backupПосле того, как базовая резервная копия будет «полностью» подготовлена, попытки применить инкрементные резервные копии завершатся ошибкой со следующим сообщением:
xtrabackup: This target seems to be already prepared.
xtrabackup: error: applying incremental backup needs target prepared with --apply-log-only.
Инкрементное резервное копирование неэффективно, когда относительное количество изменений в базе данных велико. В худшем случае, когда каждая строка в базе данных была изменена между полной резервной копией и инкрементной резервной копией, последняя на самом деле будет просто полной резервной копией, сохраняющей 100% данных. Инкрементные резервные копии наиболее эффективны, когда в основном добавляются новые данные и изменяется относительно небольшое количество старых данных. В отношении этого нет никаких правил, но если 50% ваших данных изменяются между базовой резервной копией и инкрементной резервной копией, рассмотрите возможность не использовать инкрементные резервные копии.
Другие инструменты физического резервного копирования
XtraBackup — не единственный доступный инструмент, способный выполнять «горячее» физическое резервное копирование MySQL. Наше решение объяснить концепции с помощью этого конкретного инструмента было продиктовано нашим опытом работы с ним. Однако это не означает, что другие инструменты хуже. Возможно, они лучше подходят для ваших нужд. Однако место у нас ограничено, а тема резервного копирования очень широка. Мы могли бы написать книгу Резервное копирование MySQL значительного объема!
Тем не менее, чтобы дать вам представление о некоторых других вариантах, давайте взглянем на два других доступных физических инструмента резервного копирования.
MySQL Enterprise Backup
Этот инструмент, для краткости называемый MEB, доступен как часть Oracle MySQL Enterprise Edition. Это проприетарный инструмент с закрытым исходным кодом, по функциональности аналогичный XtraBackup. Вы найдете исчерпывающую документацию по нему на веб-сайте MYSQL. В настоящее время эти два инструмента имеют равные возможности, поэтому почти все, что было описано для XtraBackup, будет справедливо и для MEB.
Выдающимся свойством MEB является то, что это действительно кроссплатформенное решение. XtraBackup работает только в Linux, тогда как MEB также работает в Solaris, Windows, macOS и FreeBSD. MEB не поддерживает разновидности MySQL, кроме стандартной версии Oracle.
Некоторые дополнительные функции MEB, недоступные в XtraBackup, включают следующее:
Отчет о ходе резервного копирования
Автономные резервные копии
Резервное копирование на ленту с помощью Oracle Secure Backups
Резервные копии бинарных и ретрансляционных журналов
Переименование таблицы во время восстановления
mariabackup
mariabackup — это инструмент от MariaDB для резервного копирования баз данных MySQL. Первоначально созданный из XtraBackup, это бесплатный инструмент с открытым исходным кодом, доступный для Linux и Windows. Выдающимся свойством mariabackup является его бесперебойная работа с форком MySQL MariaDB, который продолжает значительно отличаться как от основного MySQL, так и от Percona Server. Поскольку это прямое ответвление XtraBackup, вы найдете много общего в том, как инструменты используются и в их свойствах. Некоторые новые функции XtraBackup, такие как шифрование резервных копий и исключение вторичного индекса, отсутствуют в mariabackup. Однако использование XtraBackup для резервного копирования MariaDB в настоящее время невозможно.
Восстановление на момент времени (Point-in-time recovery, PITR)
Теперь, когда вы знакомы с концепцией горячего резервного копирования, у вас есть почти все, что вам нужно, чтобы завершить свой набор инструментов для резервного копирования. До сих пор все типы резервного копирования, которые мы обсуждали, имели одинаковую черту — недостаток. Они позволяют восстановить только в тот момент времени, когда они были взяты. Если у вас есть две резервные копии, одна сделана в 23:00 в понедельник, а вторая в 23:00 во вторник, вы не сможете восстановить до 17:00 во вторник.
Помните пример отказа инфраструктуры, приведенный в начале главы? Теперь давайте усугубим ситуацию и скажем, что данные пропали, все диски вышли из строя, а репликации нет. Событие произошло в среду в 21:00. Без PITR и ежедневных резервных копий, сделанных в 23:00, это означает, что вы только что безвозвратно потеряли данные за целый день. Возможно, инкрементные резервные копии, сделанные с помощью XtraBackup, позволяют сделать эту проблему несколько менее выраженной, но они все же оставляют место для потери данных, и запускать их очень часто нецелесообразно.
MySQL поддерживает журнал транзакций, называемый бинарным журналом (binary log). Комбинируя любой из методов резервного копирования, которые мы обсуждали до сих пор, с бинарными журналами, мы получаем возможность восстановить транзакцию в произвольный момент времени. Очень важно понимать, что вам нужна как резервная копия, так и бинарные журналы после резервного копирования, чтобы это работало. Вы также не можете вернуться в прошлое, поэтому вы не можете восстановить данные на момент времени, предшествующий созданию самой старой базовой резервной копии или дампа.
Бинарные журналы содержат как временные метки транзакций, так и их идентификаторы. Вы можете полагаться на любой из них для восстановления, и можно указать MySQL восстановиться до определенной временной метки. Это не проблема, если вы хотите выполнить восстановление до последнего момента времени, но может быть чрезвычайно важным и полезным при попытке выполнить восстановление для устранения логической несогласованности, например той, которая описана в разделе «Ошибка развертывания». Однако в большинстве случаев вам потребуется определить конкретную проблемную транзакцию, и мы покажем вам, как это сделать.
Одна интересная особенность MySQL заключается в том, что она допускает PITR для логических резервных копий. В разделе «Загрузка данных из файла дампа SQL» обсуждается сохранение позиции binlog для подготовки реплик с помощью mysqldump. Эту же позицию в бинарном журнале можно использовать в качестве отправной точки для PITR. Каждый тип резервного копирования в MySQL подходит для PITR, в отличие от других баз данных. Чтобы упростить это свойство, обязательно запишите позицию binlog при создании резервной копии. Некоторые инструменты резервного копирования делают это за вас. При использовании тех, которые этого не делают, вы можете запустить SHOW MASTER STATUS, чтобы получить эти данные.
Технические сведения о бинарных журналах
MySQL отличается от многих других популярных СУБД тем, что поддерживает несколько механизмов хранения, как описано в разделе «Альтернативные механизмы хранения». Кроме того, она поддерживает несколько механизмов хранения для таблиц в одной базе данных. В результате некоторые концепции в MySQL отличаются от других систем.
Бинарные журналы в MySQL по сути являются журналами транзакций. Когда ведение бинарного журнала включено, каждая транзакция (за исключением транзакций только для чтения) будет отражаться в бинарном журнале. Существует три способа записи транзакций в бинарные журналы:
- На основе инструкций
-
В этом режиме операторы регистрируются в бинарных журналах по мере их записи, что может привести к недетерминированному выполнению в сценариях репликации.
- На основе строк
-
В этом режиме операторы разбиваются на минимальные операции DML, каждая из которых модифицирует одну конкретную строку. Хотя он гарантирует детерминированное выполнение, этот режим является наиболее подробным и приводит к самым большим файлам и, следовательно, к наибольшей нагрузке на ввод-вывод.
- Смешанный
-
В этом режиме «безопасные» операторы регистрируются как есть, а другие разбиваются.
Обычно в системах управления базами данных журнал транзакций используется для аварийного восстановления, репликации и PITR. Однако, поскольку MySQL поддерживает несколько механизмов хранения, его бинарные журналы нельзя использовать для аварийного восстановления. Вместо этого каждый движок поддерживает свой собственный механизм восстановления после сбоев. Например, MyISAM не является отказоустойчивым, тогда как InnoDB имеет свои собственные журналы повторного выполнения. Каждая транзакция в MySQL является распределенной транзакцией с двухфазной фиксацией, чтобы учесть этот многокомпонентный характер. Каждая зафиксированная транзакция гарантированно будет отражена в журналах повторов подсистемы хранения, если подсистема является транзакционной, а также в собственном журнале транзакций MySQL (бинарные журналы).
Подробнее о том, как работают бинарные журналы, мы поговорим в главе 13.
Сохранение бинарных журналов
Чтобы разрешить PITR, вы должны сохранять бинарные журналы, начиная с позиции binlog самой старой резервной копии. Есть несколько способов сделать это:
-
Скопируйте или синхронизируйте бинарные журналы «вручную», используя любой доступный инструмент, такой как
rsync. Помните, что MySQL продолжает писать в текущий бинарный файл журнала. Если вы копируете файлы вместо их постоянной синхронизации, не копируйте текущий бинарный файл журнала. Непрерывная синхронизация файлов решит эту проблему, перезаписав частичный файл, как только он станет неактуальным. -
Используйте
mysqlbinlogдля непрерывного копирования отдельных файлов или потоковых бинарных журналов. Инструкции доступны в документации. -
Используйте MySQL Enterprise Backup со встроенной функцией копирования binlog. Обратите внимание, что это не непрерывное копирование, а полагается на инкрементные резервные копии для получения копий binlog. Это позволяет использовать PITR между двумя резервными копиями.
-
Разрешите серверу MySQL хранить все необходимые бинарные журналы в своем каталоге данных, установив высокое значение для переменных
binlog_expire_logs_secondsилиexpire_logs_days. Этот вариант в идеале не должен использоваться сам по себе, но может использоваться в дополнение к любому другому. Если что-то случится с каталогом данных, например, с повреждением файловой системы, хранящиеся там бинарные журналы также могут быть потеряны.
Определение цели PITR
Вы можете использовать технику PITR для достижения двух целей:
Восстановление до последнего момента времени.
Восстановление до произвольного момента времени.
Первый, как обсуждалось ранее, полезен для восстановления полностью потерянной базы данных до последнего доступного состояния. Второй полезен для получения данных, как это было раньше. Пример случая, когда это может быть полезно, был приведен в разделе «Ошибка развертывания». Чтобы восстановить потерянные или неправильно измененные данные, вы можете восстановить резервную копию, а затем восстановить ее на момент времени непосредственно перед выполнением развертывания.
Определение фактического конкретного времени, когда возникла проблема, может быть проблемой. Чаще всего единственный способ найти нужный момент времени — просмотреть бинарные журналы, записанные примерно в то время, когда возникла проблема. Например, если вы подозреваете, что таблица была удалена, вы можете искать имя таблицы, а затем любые операторы DDL, выполненные для этой таблицы, или конкретно оператор DROP TABLE.
Давайте проиллюстрируем этот пример. Во-первых, нам нужно удалить таблицу, поэтому мы удалим таблицу facilities, созданную нами в разделе «Загрузка данных из файлов с разделителями-запятыми». Однако перед этим мы вставим запись, которая наверняка отсутствует в оригинальной резервной копии:
mysql> INSERT INTO facilities(center)
-> VALUES ('this row was not here before');
Query OK, 1 row affected (0.01 sec)
mysql> DROP TABLE nasa.facilities;
Query OK, 0 rows affected (0.02 sec)
Теперь мы могли бы вернуться и восстановить одну из резервных копий, которые мы сделали в этой главе, но тогда мы потеряли бы все изменения, внесенные в базу данных между этим моментом и DROP. Вместо этого мы будем использовать mysqlbinlog для проверки содержимого бинарных журналов и поиска цели восстановления непосредственно перед выполнением оператора DROP. Чтобы найти список бинарных журналов, доступных в каталоге данных, вы можете запустить следующую команду:
mysql> SHOW BINARY LOGS;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000291 | 156 | No |
| binlog.000292 | 711 | No |
+---------------+-----------+-----------+
2 rows in set (0.00 sec)
Теперь, когда доступен список бинарных журналов, вы можете либо попытаться поискать в них, от самого нового до самого старого, либо просто сбросить все их содержимое вместе. В нашем примере файлы небольшие, поэтому мы можем использовать последний подход. В любом случае используется команда mysqlbinlog:
# cd /var/lib/mysql
# mysqlbinlog binlog.000291 binlog.000292 \
-vvv --base64-output='decode-rows' > /tmp/mybinlog.sql
Изучив выходной файл, мы можем найти проблемное утверждение:
...
#210613 23:32:19 server id 1 end_log_pos 200 ... Rotate to binlog.000291
...
# at 499
#210614 0:46:08 server id 1 end_log_pos 576 ...
# original_commit_timestamp=1623620769019544 (2021-06-14 00:46:09.019544 MSK)
# immediate_commit_timestamp=1623620769019544 (2021-06-14 00:46:09.019544 MSK)
/*!80001 SET @@session.original_commit_timestamp=1623620769019544*//*!*/;
/*!80014 SET @@session.original_server_version=80025*//*!*/;
/*!80014 SET @@session.immediate_server_version=80025*//*!*/;
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 576
#210614 0:46:08 server id 1 end_log_pos 711 ... Xid = 25
use `nasa`/*!*/;
SET TIMESTAMP=1623620768/*!*/;
DROP TABLE `facilities` /* generated by server */
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
...
Мы должны остановить восстановление до 2021-06-14 00:46:08 или на позиции бинарного журнала 499. Нам также потребуются все бинарные журналы из последней резервной копии, включая binlog.00291. Используя эту информацию, мы можем перейти к восстановлению и восстановлению резервной копии.
Пример восстановления на момент времени: XtraBackup
Сам по себе XtraBackup не предоставляет возможности PITR. Вам нужно добавить дополнительный шаг запуска mysqlbinlog для воспроизведения содержимого binlog в восстановленной базе данных:
-
Восстановите резервную копию. Точные шаги см. в разделе «Резервное копирование и восстановление».
-
Запустите сервер MySQL. Если вы восстанавливаете исходный экземпляр напрямую, рекомендуется использовать параметр
--skip-networking, чтобы предотвратить доступ нелокальных клиентов к базе данных. В противном случае некоторые клиенты могут изменить базу данных до того, как вы закончите восстановление. -
Найдите позицию бинарного журнала резервной копии. Она доступна в файле xtrabackup_binlog_info в каталоге резервного копирования:
# cat /tmp/base_backup/xtrabackup_binlog_info binlog.000291 156 -
Найдите отметку времени или позицию в бинарном журнале, до которой вы хотите восстановиться, например, непосредственно перед выполнением
DROP TABLE, как обсуждалось ранее. -
Воспроизведите binlog до нужной точки. Для этого примера мы сохранили бинарный журнал binlog.000291 отдельно, но вы должны использовать свое централизованное хранилище бинарных журналов в качестве источника бинарных журналов. Для этого вы используете команду
mysqlbinlog:# mysqlbinlog /opt/mysql/binlog.000291 \ /opt/mysql/binlog.000292 --start-position=156 \ --stop-datetime="2021-06-14 00:46:00" | mysql -
Убедитесь, что восстановление прошло успешно и данные отсутствуют. В нашем случае мы будем искать запись, которую мы добавили в таблицу объектов, прежде чем удалить ее:
mysql> SELECT center FROM facilities -> WHERE center LIKE '%before%'; +------------------------------+ | center | +------------------------------+ | this row was not here before | +------------------------------+ 1 row in set (0.00 sec)
Пример восстановления на момент времени: mysqldump
Шаги, необходимые для PITR с mysqldump, аналогичны шагам, предпринятым ранее с XtraBackup. Мы показываем это только для полноты и чтобы вы могли видеть, что PITR одинаков для каждого типа резервного копирования в MySQL. Вот процесс:
-
Восстановите дамп SQL. Опять же, если ваш целевой сервер восстановления является источником резервного копирования, вы, вероятно, захотите сделать его недоступным для клиентов.
-
Найдите позицию бинарного журнала в файле резервной копии
mysqldump:CHANGE MASTER TO MASTER_LOG_FILE='binlog.000010', MASTER_LOG_POS=191098797; -
Найдите отметку времени или позицию в бинарном журнале, до которой вы хотите восстановиться (например, непосредственно перед выполнением
DROP TABLE, как обсуждалось ранее). -
Воспроизведите бинарные логи до нужной точки:
# mysqlbinlog /path/to/datadir/mysql-bin.000010 \ /path/to/datadir/mysql-bin.000011 \ --start-position=191098797 \ --stop-datetime="20-05-25 13:00:00" | mysql
Экспорт и импорт табличных пространств InnoDB
Одним из основных недостатков физических резервных копий является то, что они обычно требуют одновременного копирования значительной части файлов базы данных. Хотя механизм хранения, такой как MyISAM, позволяет копировать файлы данных простаивающих таблиц, вы не можете гарантировать согласованность файлов InnoDB. Однако бывают ситуации, когда вам нужно перенести только несколько таблиц или только одну таблицу. Пока единственный вариант, который мы видели для этого, — это использование логических резервных копий, которые могут быть неприемлемо медленными. Функция экспорта и импорта табличных пространств InnoDB, официально называемая Transportable Tablespace, — это способ получить лучшее из обоих миров. Мы также будем называть эту функцию экспортом/импортом для краткости.
Функция переносимых табличных пространств позволяет сочетать производительность физического резервного копирования в режиме онлайн с детализацией логического. По сути, она предлагает возможность сделать онлайн-копию файлов данных таблицы InnoDB, которые будут использоваться для импорта в ту же или другую таблицу. Такая копия может служить резервной копией или способом передачи данных между отдельными установками MySQL.
Зачем использовать экспорт/импорт, если логический дамп позволяет сделать то же самое? Экспорт/импорт выполняется намного быстрее и, кроме блокировки таблицы, не оказывает существенного влияния на сервер. Особенно это касается импорта. При размерах таблиц в несколько гигабайт это один из немногих возможных вариантов передачи данных.
Техническое образование
Чтобы помочь вам понять, как работает эта функция, мы кратко рассмотрим две концепции: физические резервные копии и табличные пространства.
Как мы видели, для того, чтобы физическая резервная копия была согласованной, мы обычно можем пойти двумя путями. Первый — закрыть экземпляр или иным образом сделать данные доступными только для чтения гарантированным образом. Во-вторых, сделать файлы данных согласованными на определенный момент времени, а затем аккумулировать все изменения между этим моментом времени и концом резервного копирования. Функция переносимых табличных пространств работает в первом случае, требуя, чтобы таблица на короткое время была доступна только для чтения.
Табличное пространство — это файл, в котором хранятся данные таблицы и ее индексы. По умолчанию InnoDB использует параметр innodb_file_per_table, который принудительно создает отдельный файл табличного пространства для каждой таблицы. Можно создать табличное пространство, которое будет содержать данные для нескольких таблиц, и вы можете использовать «старое» поведение, когда все таблицы находятся в одном табличном пространстве ibdata. Однако экспорт поддерживается только для конфигурации по умолчанию, где для каждой таблицы есть выделенное табличное пространство. Табличные пространства существуют отдельно для каждого раздела в многораздельной таблице, что дает интересную возможность переноса разделов между отдельными таблицами или создания таблицы из раздела.
Экспорт табличного пространства
Теперь, когда эти концепции рассмотрены, вы знаете, что нужно сделать для экспорта. Однако одна вещь, которой все еще не хватает, — это определение таблицы. Несмотря на то, что большинство файлов табличных пространств InnoDB на самом деле содержат избыточную копию записей словаря данных для своих таблиц, текущая реализация переносимых табличных пространств требует наличия таблицы в целевом объекте перед импортом.
Шаги для экспорта табличного пространства:
-
Получите определение таблицы.
-
Остановите все записи в таблицу (или таблицы) и сделайте ее согласованной.
-
Подготовьте дополнительные файлы, необходимые для импорта табличного пространства позже:
-
В файле .cfg хранятся метаданные, используемые для проверки схемы.
-
Файл .cfp создается только при использовании шифрования и содержит ключ перехода, необходимый целевому серверу для расшифровки табличного пространства.
-
Чтобы получить определение таблицы, вы можете использовать команду SHOW CREATE TABLE, которую мы неоднократно показывали в этой книге. Все остальные шаги выполняются MySQL автоматически с помощью одной команды: FLUSH TABLE ... FOR EXPORT. Эта команда блокирует таблицу и создает дополнительный требуемый файл (или файлы, если используется шифрование) рядом с обычным файлом .ibd целевой таблицы. Давайте экспортируем таблицу actor из базы данных sakila:
mysql> USE sakila
mysql> FLUSH TABLE actor FOR EXPORT;
Query OK, 0 rows affected (0.00 sec)
Сеанс, в котором был выполнен оператор FLUSH TABLE, должен оставаться открытым, потому что таблица actor будет освобождена, как только сеанс завершится. Рядом с обычным файлом actor.ibd в каталоге данных MySQL должен появиться новый файл actor.cfg. Давайте проверим:
# ls -1 /var/lib/mysql/sakila/actor.
/var/lib/mysql/sakila/actor.cfg
/var/lib/mysql/sakila/actor.ibd
Эту пару файлов .ibd и .cfg теперь можно куда-нибудь скопировать и использовать позже. После того, как вы скопировали файлы, обычно рекомендуется снять блокировки таблицы, выполнив оператор UNLOCK TABLES или закрыв сеанс, в котором был вызван FLUSH TABLE. Когда все это будет сделано, у вас будет готовое к импорту табличное пространство.
Импорт табличного пространства
Импорт табличного пространства довольно прост. Он состоит из следующих шагов:
-
Создайте таблицу, используя сохраненное определение. Невозможно каким-либо образом изменить определение таблицы.
-
Удалите табличное пространство таблицы.
-
Скопируйте файлы .ibd и .cfg.
-
Измените таблицу, чтобы импортировать табличное пространство.
Если таблица существует на целевом сервере и имеет то же определение, то нет необходимости выполнять шаг 1.
Давайте восстановим таблицу actor в другой базе данных на том же сервере. Таблица должна существовать, поэтому мы ее создадим:
mysql> USE nasa
mysql> CREATE TABLE `actor` (
-> `actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
-> `first_name` varchar(45) NOT NULL,
-> `last_name` varchar(45) NOT NULL,
-> `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
-> ON UPDATE CURRENT_TIMESTAMP,
-> PRIMARY KEY (`actor_id`),
-> KEY `idx_actor_last_name` (`last_name`)
-> ) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT
-> CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.04 sec)
Как только таблица actor создана, MySQL создает для нее файл .ibd:
# ls /var/lib/mysql/nasa/
actor.ibd facilities.ibd
Это подводит нас к следующему шагу: удаление табличного пространства этой новой таблицы. Это делается запуском специального оператора ALTER TABLE:
mysql> ALTER TABLE actor DISCARD TABLESPACE;
Query OK, 0 rows affected (0.02 sec)
Теперь файл .ibd исчез:
# ls /var/lib/mysql/nasa/
facilities.ibd
Теперь мы можем скопировать экспортированное табличное пространство исходной таблицы actor вместе с файлом .cfg:
# cp -vip /opt/mysql/actor.* /var/lib/mysql/nasa/
'/opt/mysql/actor.cfg' -> '/var/lib/mysql/nasa/actor.cfg'
'/opt/mysql/actor.ibd' -> '/var/lib/mysql/nasa/actor.ibd'
После выполнения всех шагов можно импортировать табличное пространство и проверить данные:
mysql> ALTER TABLE actor IMPORT TABLESPACE;
Query OK, 0 rows affected (0.02 sec)
mysql> SELECT * FROM nasa.actor LIMIT 5;
+----------+------------+--------------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+--------------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
| 3 | ED | CHASE | 2006-02-15 04:34:33 |
| 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 |
| 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33 |
+----------+------------+--------------+---------------------+
5 rows in set (0.00 sec)
Вы можете видеть, что у нас есть данные из sakila.actor в nasa.actor.
Пожалуй, самое лучшее в переносимых табличных пространствах — это эффективность. С помощью этой функции вы можете легко перемещать очень большие таблицы между базами данных.
Восстановление одной таблицы XtraBackup
Возможно, это будет неожиданно, но мы снова упомянем XtraBackup в контексте переносимых табличных пространств. Это связано с тем, что XtraBackup позволяет экспортировать таблицы из любой существующей резервной копии. На самом деле это наиболее удобный способ восстановления отдельной таблицы, а также первый строительный блок для PITR для одной таблицы или частичной базы данных.
Это один из самых передовых методов резервного копирования и восстановления, полностью основанный на функции переносимых табличных пространств. Он также переносит все ограничения: например, он не будет работать с табличными пространствами без файлов на таблицу. Мы не будем давать здесь точных шагов, а только рассмотрим эту технику, чтобы вы знали, что это возможно.
Чтобы выполнить восстановление одной таблицы, вы должны сначала запустить xtrabackup с аргументом командной строки --export, чтобы подготовить таблицу к экспорту. Вы можете заметить, что в этой команде не указано имя таблицы, и в действительности каждая таблица будет экспортирована. Давайте запустим команду для одной из резервных копий, которые мы сделали ранее:
# xtrabackup --prepare --export --target-dir=/tmp/base_backup
# ls -1 /tmp/base_backup/sakila/
actor.cfg
actor.ibd
address.cfg
address.ibd
category.cfg
category.ibd
...
Вы можете видеть, что у нас есть файл .cfg для каждой таблицы: теперь каждое табличное пространство готово к экспорту и импорту в другую базу данных. Отсюда вы можете повторить шаги из предыдущего раздела, чтобы восстановить данные из одной из таблиц.
PITR с одной таблицей или частичной базой данных сложен, и это верно для большинства существующих систем управления базами данных. Как вы видели в разделе «Восстановление на момент времени», PITR в MySQL основан на бинарных журналах. Что это означает для частичного восстановления, так это то, что транзакции, касающиеся всех таблиц во всех базах данных, записываются, но бинарные журналы могут быть отфильтрованы при применении через репликацию. Поэтому очень кратко процедура частичного восстановления такова: вы экспортируете нужные таблицы, строите полностью отдельный инстанс и кормите его бинарными логами через канал репликации.
Дополнительную информацию можно найти в блогах сообщества и в таких статьях, как MySQL Single Table PITR, Filtering Binary Logs with MySQL и How to Make MySQL PITR Faster.
Функция экспорта/импорта является мощной техникой при правильном использовании и при определенных обстоятельствах.
Тестирование и проверка ваших резервных копий
Резервные копии хороши только тогда, когда вы уверены, что можете им доверять. Есть множество примеров, когда у людей системы резервного копирования выходили из строя в самый нужный момент. Вполне возможно часто делать резервные копии и все равно терять данные.
Существует несколько причин, по которым резервное копирование может оказаться бесполезным или привести к сбою:
- Несогласованные резервные копии
-
Простейшим примером этого является резервная копия моментального снимка, неправильно взятая из нескольких томов при работающей базе данных. Полученная резервная копия может быть повреждена или в ней могут отсутствовать данные. К сожалению, некоторые из резервных копий, которые вы делаете, могут быть непротиворечивыми, а другие могут быть недостаточно поврежденными или противоречивыми, чтобы вы заметили, пока не стало слишком поздно.
- Повреждение исходной базы данных
-
Физические резервные копии, как мы подробно рассмотрели, будут содержать копии всех страниц базы данных, поврежденных или нет. Некоторые инструменты пытаются проверять данные по мере их поступления, но это не совсем безошибочно. Ваши успешные резервные копии могут содержать неверные данные, которые невозможно будет прочитать позже.
- Повреждение резервных копий
-
Резервные копии — это просто данные сами по себе, и поэтому они подвержены тем же проблемам, что и исходные данные. Ваша успешная резервная копия может оказаться совершенно бесполезной, если ее данные будут повреждены во время хранения.
- Ошибки
-
Всякое случается. Инструмент для резервного копирования, которым вы пользовались уже дюжину лет, может иметь ошибку, которую обнаружите только вы. В лучшем случае ваша резервная копия не удастся; в худшем случае она может не восстановиться.
- Операционные ошибки
-
Все мы люди, и мы делаем ошибки. Если все автоматизировать, риск здесь меняется с человеческих ошибок на баги.
Это не исчерпывающий список проблем, но он дает вам некоторое представление о проблемах, с которыми вы можете столкнуться, даже если ваша стратегия резервного копирования верна. Давайте рассмотрим некоторые шаги, которые вы можете предпринять, чтобы лучше спать:
-
При внедрении системы резервного копирования тщательно протестируйте ее и протестируйте в различных режимах. Убедитесь, что вы можете создать резервную копию своей системы и использовать резервную копию для восстановления. Тестируйте с нагрузкой и без. Ваши резервные копии могут быть согласованными, когда никакое соединение не изменяет данные, и завершаться ошибкой, когда это не так.
-
Используйте как физические, так и логические резервные копии. У них разные свойства и режимы отказа, особенно в случае повреждения исходных данных.
-
Сделайте резервную копию своих резервных копий или просто убедитесь, что они не менее долговечны, чем база данных.
-
Периодически выполняйте тестирование восстановления из резервной копии.
Последний пункт особенно интересен. Ни одна резервная копия не должна считаться безопасной, пока она не будет восстановлена и протестирована. Это означает, что в идеальном мире ваша автоматизация на самом деле попытается использовать резервную копию для создания сервера базы данных и сообщит об успехе только тогда, когда все пойдет хорошо. Кроме того, эту новую базу данных можно подключить к источнику в качестве реплики, а для проверки согласованности данных можно использовать инструмент проверки данных, такой как pt-table-checksum из Percona Toolkit.
Вот несколько возможных шагов для проверки данных резервного копирования для физических резервных копий:
-
Подготовьте резервную копию.
-
Восстановите резервную копию.
-
Запустите
innochecksumдля всех файлов .ibd.Следующая команда запустит четыре процесса
innochecksumпараллельно в Linux:$ find . -type f -name "*.ibd" -print0 |\ xargs -t -0r -n1 --max-procs=4 innochecksum -
Запустите новый экземпляр MySQL, используя восстановленную резервную копию. Используйте запасной сервер или просто выделенный файл .cnf и не забудьте использовать нестандартные порты и пути.
-
Используйте
mysqldumpили любую альтернативу для дампа всех данных, убедитесь, что они доступны для чтения, и предоставьте еще одну копию резервной копии. -
Присоедините новый экземпляр MySQL в качестве реплики к оригинальной исходной базе данных и используйте
pt-table-checksumили любую другую альтернативу для проверки соответствия данных. Процедура хорошо описана в документации поxtrabackup, среди других источников.
Эти шаги сложны и могут занять много времени, поэтому вам следует решить, подходит ли ваш бизнес и среда для использования всех их.
Руководство по стратегии резервного копирования баз данных
Теперь, когда мы рассмотрели многие детали, связанные с резервным копированием и восстановлением, мы можем собрать воедино надежную стратегию резервного копирования. Вот элементы, которые нам нужно рассмотреть:
- Восстановление на момент времени
-
Нам нужно решить, потребуется ли нам возможность восстановления до точки во времени (PITR), так как это будет влиять на наши решения по стратегии резервного копирования. Вам нужно принять решение для вашего конкретного случая, но мы рекомендуем по умолчанию предусмотреть наличие PITR. Это может быть спасением. Если мы решим, что нам понадобится эта возможность, нам нужно настроить ведение бинарного журнала и копирование бинарного журнала.
- Логические резервные копии
-
Скорее всего, нам понадобятся логические резервные копии либо для их переносимости, либо для защиты от повреждения. Поскольку логические резервные копии значительно нагружают исходную базу данных, запланируйте их на время с наименьшей нагрузкой. В некоторых случаях будет невозможно сделать логическое резервное копирование вашей производственной базы данных либо из-за ограничений по времени или нагрузке, либо из-за того и другого. Поскольку мы все еще хотим иметь возможность запускать логические резервные копии, мы можем использовать следующие методы:
-
Выполнение логических резервных копий в реплицированной базе данных. В этом случае может быть проблематично отследить позицию бинарного лога, поэтому в этом случае рекомендуется использовать репликацию на основе GTID.
-
Включение создания логических резервных копий в процесс проверки физической резервной копии. Подготовленная резервная копия — это каталог данных, который сразу же может быть использован сервером MySQL. Если вы запустите сервер, нацеленный на резервную копию, вы испортите эту резервную копию, поэтому вам нужно сначала скопировать подготовленную резервную копию куда-нибудь.
-
- Физические резервные копии
-
Основываясь на ОС, разновидности MySQL, свойствах системы и тщательном изучении документации, нам нужно выбрать инструмент, который мы будем использовать для физического резервного копирования. Для простоты мы выбираем здесь XtraBackup.
Первое решение, которое необходимо принять, — это насколько важно для нас целевое среднее время восстановления (mean time to recovery) (MTTR). Например, если мы делаем только еженедельные базовые резервные копии, нам может потребоваться применение почти недельных транзакций для восстановления резервной копии. Чтобы уменьшить MTTR, выполняйте инкрементное резервное копирование ежедневно или, возможно, даже ежечасно.
Сделав шаг назад, ваша система может быть настолько большой, что даже горячее резервное копирование с помощью одного из физических инструментов резервного копирования для вас нецелесообразно. В этом случае вам нужно сделать снимки томов, если это возможно.
- Резервное хранилище
-
Нам нужно убедиться, что наши резервные копии хранятся безопасно и, в идеале, с избыточностью. Мы можем добиться этого с помощью аппаратной настройки хранилища с использованием менее производительного, но избыточного RAID-массива уровня 5 или 6, или с менее надежной настройкой хранилища, если мы также будем постоянно передавать наши резервные копии в облачное хранилище, такое как Amazon S3. Или мы можем просто по умолчанию использовать S3, если это возможно для нас с выбранными инструментами резервного копирования.
- Резервное копирование и проверка
-
Наконец, когда у нас есть резервные копии, нам необходимо реализовать процесс их тестирования. В зависимости от бюджета, выделяемого на реализацию и сопровождение этой операции, мы должны решить, какие из шагов будет выполняться каждый раз, а какие — только периодически.
Сделав все это, мы можем сказать, что наши базы защищены, и резервные копии нашей базы данных тоже надежно защищены. Это может показаться большим усилием, учитывая, как редко используются резервные копии, но вы должны помнить, что в конечном итоге вы столкнетесь с катастрофой — это всего лишь вопрос времени.
Глава 11
Конфигурирование и настройка сервера
Процесс установки MySQL (см. главу 1) предоставляет все необходимое для установки процесса MySQL и начала его использования. Однако для производственных систем требуется тонкая настройка, настройка параметров MySQL и операционной системы для оптимизации производительности MySQL Server. В этой главе будут рассмотрены рекомендуемые передовые методы для различных установок и показаны параметры, которые необходимо настроить в зависимости от ожидаемой или текущей рабочей нагрузки. Как вы увидите, нет необходимости запоминать все параметры MySQL. Основываясь на принципе Парето, который гласит, что для многих событий примерно 80% эффектов исходят из 20% причин, мы сосредоточимся на параметрах MySQL и операционной системы, которые ответственны за большинство проблем с производительностью. В этой главе есть несколько дополнительных тем, связанных с архитектурой компьютера (например, NUMA); цель здесь состоит в том, чтобы познакомить вас с несколькими компонентами, которые могут повлиять на производительность MySQL, с которыми вам рано или поздно придется взаимодействовать в вашей карьере.
Демон сервера MySQL
С 2015 года большинство дистрибутивов Linux используют systemd. Из-за этого операционные системы Linux больше не используют процесс mysqld_safe для запуска MySQL. mysqld_safe называется ангельским процессом, потому что он добавляет некоторые функции безопасности, такие как перезапуск сервера при возникновении ошибки и запись информации о времени выполнения в журнал ошибок MySQL. Для операционных систем, использующих systemd (управляемых и настраиваемых с помощью команды systemctl), эти функции были включены в systemd и процесс mysqld.
mysqld — это основной процесс MySQL Server. Это одна многопоточная программа, которая выполняет большую часть работы на сервере. Он не порождает дополнительных процессов — мы говорим об одном процессе с несколькими потоками, что делает MySQL многопоточным процессом.
Давайте подробнее рассмотрим некоторые из этих терминов. Программа — это код, предназначенный для достижения определенной цели. Существует много типов программ, в том числе программы для поддержки частей операционной системы и другие, предназначенные для нужд пользователя, например для просмотра веб-страниц.
Процесс — это то, что мы называем программой, загруженной в память вместе со всеми ресурсами, необходимыми для ее работы. Операционная система выделяет для него память и другие ресурсы.
Поток — это единица выполнения внутри процесса. Процесс может иметь только один поток или много потоков. В однопоточных процессах процесс содержит один поток, поэтому одновременно выполняется только одна команда.
Поскольку современные процессоры имеют несколько ядер, они могут выполнять несколько потоков одновременно, поэтому в настоящее время широко распространены многопоточные процессы. Важно знать об этой концепции, чтобы понять некоторые из предлагаемых настроек в следующих разделах.
В заключение можно сказать, что MySQL является программным обеспечением с одним процессом, которое порождает несколько потоков для различных целей, таких как обслуживание действий пользователя и выполнение фоновых задач.
Переменные сервера MySQL
MySQL Server имеет множество переменных, которые позволяют настраивать его работу. Например, MySQL Server 8.0.25 имеет впечатляющие 588 серверных переменных!
Каждая системная переменная имеет значение по умолчанию. Кроме того, мы можем настроить большинство системных переменных динамически (или «на лету»); однако некоторые из них являются статическими, а это означает, что нам нужно изменить файл my.cnf и перезапустить процесс MySQL, чтобы они вступили в силу (как обсуждалось в главе 9).
Системные переменные могут иметь две разные области видимости: SESSION и GLOBAL. То есть системная переменная может иметь глобальное значение, влияющее на работу сервера в целом, например innodb_log_file_size, или значение сеанса, влияющее только на конкретный сеанс, например sql_mode.
Проверка настроек сервера
Базы данных не являются статическими объектами; напротив, их нагрузка динамична и меняется во времени, с тенденцией к росту. Это органичное поведение требует постоянного наблюдения, анализа и корректировки. Команда для отображения настроек MySQL:
SHOW [GLOBAL|SESSION] VARIABLES;При использовании модификатора GLOBAL оператор отображает значения глобальных системных переменных. Когда вы используете SESSION, он отображает значения системных переменных, которые влияют на текущее соединение. Обратите внимание, что разные соединения могут иметь разные значения.
Если модификатор отсутствует, по умолчанию используется SESSION.
Лучшие практики
Есть много аспектов, которые нужно оптимизировать в базе данных. Если база данных работает на голом железе (физическом хосте), мы можем контролировать аппаратные ресурсы и ресурсы операционной системы. Когда мы переходим на виртуализированные машины, мы уменьшаем контроль над этими ресурсами, потому что не можем контролировать то, что происходит с базовым хостом. Последний вариант — это управляемые базы данных в облаке, подобные тем, которые предоставляет Amazon Relational Database Service (RDS), где доступно лишь несколько настроек базы данных. Существует компромисс между возможностью выполнять тонкую настройку для получения максимальной производительности и удобством автоматизации большинства задач (за счет нескольких дополнительных долларов).
Начнем с обзора некоторых настроек на уровне операционной системы. После этого мы проверим параметры MySQL.
Лучшие практики для операционных систем
Есть несколько настроек операционной системы, которые могут повлиять на производительность MySQL. Здесь мы рассмотрим некоторые из наиболее важных.
Настройка подкачки и использование подкачки
Параметр swappiness управляет поведением операционной системы Linux в области подкачки. Подкачка — это процесс передачи данных между памятью и диском. Это может существенно повлиять на производительность, поскольку доступ к диску (даже NVMe) как минимум на порядок медленнее, чем доступ к памяти.
Значение по умолчанию (60) побуждает сервер к подкачке. Вы захотите, чтобы ваш сервер MySQL по соображениям производительности поддерживал подкачку на минимальном уровне. Рекомендуемое значение равно 1, что означает: не выполнять подкачку до тех пор, пока это не станет абсолютно необходимым для функционирования операционной системы. Чтобы настроить этот параметр, выполните следующую команду от имени пользователя root:
# echo 1 > /proc/sys/vm/swappinessОбратите внимание, что это непостоянное изменение; параметр вернется к исходному значению при перезагрузке ОС. Чтобы это изменение сохранялось после перезагрузки операционной системы, измените параметр в sysctl.conf:
# sudo sysctl -w vm.swappiness=1Вы можете получить информацию об использовании пространства подкачки, используя следующую команду:
# free -mИли, если вам нужна более подробная информация, вы можете запустить следующий фрагмент в оболочке:
#!/bin/bash
SUM=0
OVERALL=0
for DIR in `find /proc/ -maxdepth 1 -type d | egrep "^/proc/[0-9]"` ; do
PID=`echo $DIR | cut -d / -f 3`
PROGNAME=`ps -p $PID -o comm --no-headers`
for SWAP in `grep Swap $DIR/smaps 2>/dev/null| awk '{ print $2 }'`
do
let SUM=$SUM+$SWAP
done
echo "PID=$PID - Swap used: $SUM - ($PROGNAME )"
let OVERALL=$OVERALL+$SUM
SUM=0
done
echo "Overall swap used: $OVERALL"
Планировщик ввода/вывода
Планировщик ввода-вывода — это алгоритм, который ядро использует для фиксации операций чтения и записи на диск. По умолчанию в большинстве установок Linux используется планировщик Completely Fair Queuing (cfq). Он хорошо работает для многих общих случаев использования, но дает мало гарантий задержки. Два других планировщика — это deadline и noop. Планировщик deadline превосходен в случаях использования, чувствительных к задержкам (например, в базах данных), а noop ближе к полному отсутствию планирования. Для установок на физическом хосте лучше будет либо deadline, либо noop (разница в производительности между ними незаметна), чем cfq.
Если вы используете MySQL на виртуальной машине (у которой есть собственный планировщик ввода-вывода), лучше всего использовать noop и позволить уровню виртуализации самому позаботиться о планировании ввода-вывода.
Во-первых, проверьте, какой алгоритм в настоящее время используется в Linux:
# cat /sys/block/xvda/queue/scheduler
noop [deadline] cfq
Чтобы изменить его динамически, запустите эту команду от имени пользователя root:
# echo "noop" > /sys/block/xvda/queue/schedulerЧтобы сделать это изменение постоянным, вам нужно отредактировать файл конфигурации GRUB (обычно /etc/sysconfig/grub) и добавить опцию elevator в GRUB_CMDLINE_LINUX_DEFAULT. Например, замените эту строку:
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200строкой:
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 elevator=noop"Очень важно проявлять особую осторожность при редактировании конфигурации GRUB. Ошибки или неправильные настройки могут сделать сервер непригодным для использования и потребовать повторной установки операционной системы.
Файловые системы и параметры монтирования
Выбор файловой системы, подходящей для вашей базы данных, является важным решением из-за множества доступных вариантов и сопутствующих компромиссов. Стоит упомянуть две важных файловых системы, которые часто используются: XFS и ext4.
XFS — это высокопроизводительная журналируемая файловая система, предназначенная для высокой масштабируемости. Она обеспечивает почти родную производительность ввода-вывода, даже когда файловая система охватывает несколько устройств хранения. XFS имеет функции, которые делают ее подходящей для очень больших файловых систем, поддерживая файлы размером до 8 EiB. Другие функции включают в себя быстрое восстановление, быстрые транзакции, отложенное выделение для уменьшения фрагментации и почти чистую производительность ввода-вывода при прямом вводе-выводе.
Команда создания файловой системы XFS (mkfs.xfs) имеет несколько опций для настройки. Однако параметры по умолчанию для mkfs.xfs хороши для оптимальной скорости, поэтому команда по умолчанию для создания файловой системы обеспечит хорошую производительность при обеспечении целостности данных:
# mkfs.xfs /dev/target_volumeЧто касается параметров монтирования файловой системы, значения по умолчанию снова должны подходить для большинства случаев. Вы можете увидеть увеличение производительности на некоторых файловых системах, добавив параметр монтирования noatime в файл /etc/fstab. Для файловых систем XFS поведением atime по умолчанию является relatime, которое почти не имеет накладных расходов по сравнению с noatime и по-прежнему поддерживает разумные значения atime. Если вы создаете файловую систему XFS на логическом устройстве с номером (LUN) с энергонезависимым кэшем с батарейным питанием, вы можете еще больше повысить производительность файловой системы, отключив барьер записи с помощью параметра монтирования nobarrier. Эти настройки помогают избежать сброса данных чаще, чем это необходимо. Однако, если блок резервной батареи (BBU) отсутствует или вы в нем не уверены, оставьте барьеры включенными; в противном случае вы можете поставить под угрозу целостность данных. В приведенном ниже примере показаны две воображаемые точки монтирования с этими параметрами:
/dev/sda2 /datastore xfs noatime,nobarrier
/dev/sdb2 /binlog xfs noatime,nobarrier
Другой популярный вариант — ext4, разработанный как преемник ext3 с дополнительными улучшениями производительности. Это надежный вариант, который подходит для большинства рабочих нагрузок. Здесь следует отметить, что он поддерживает файлы размером до 16 ТБ, что меньше, чем XFS. Это то, что вы должны учитывать, если требуется чрезмерный размер/рост табличного пространства. В отношении вариантов монтирования применяются те же соображения. Мы рекомендуем значения по умолчанию для надежной файловой системы без рисков для согласованности данных. Однако при наличии корпоративного контроллера системы хранения данных с кэшем BBU следующие параметры монтирования обеспечат наилучшую производительность:
/dev/sda2 /datastore ext4 noatime,data=writeback,barrier=0,nobh,errors=remount-ro
/dev/sdb2 /binlog ext4 noatime,data=writeback,barrier=0,nobh,errors=remount-ro
Transparent Huge Pages
Операционная система управляет памятью блоками, известными как страницы (pages). Страница имеет размер 4096 байт (или 4 КБ); 1 МБ памяти соответствует 256 страницам, 1 ГБ памяти соответствует 256 000 страниц и т. д. ЦП имеют встроенный модуль управления памятью, который содержит список этих страниц, причем ссылка на каждую страницу осуществляется через запись в таблице страниц. В настоящее время часто можно увидеть серверы с сотнями мегабайт или терабайтами памяти. Есть два способа разрешить системе управлять большими объемами памяти:
-
Увеличить количество записей таблицы страниц в блоке управления аппаратной памятью.
-
Увеличить размер страницы.
Первый метод является дорогостоящим, поскольку аппаратный блок управления памятью в современном процессоре поддерживает только сотни или тысячи записей в таблице страниц. Кроме того, аппаратные средства и алгоритмы управления памятью, которые хорошо работают с тысячами страниц (мегабайтами памяти), могут иметь проблемы с работой с миллионами (или даже миллиардами) страниц. Чтобы решить проблему масштабируемости, операционные системы начали использовать огромные страницы (huge pages). Проще говоря, огромные страницы — это блоки памяти, которые могут иметь размеры 2 МБ, 4 МБ, 1 ГБ и т. д. Использование памяти больших страниц увеличивает число попаданий кэша ЦП в резервный буфер транзакций (TLB).
Вы можете запустить cpuid для проверки кеша процессора и TLB:
# cpuid | grep "cache and TLB information" -A 5
cache and TLB information (2):
0x5a: data TLB: 2M/4M pages, 4-way, 32 entries
0x03: data TLB: 4K pages, 4-way, 64 entries
0x76: instruction TLB: 2M/4M pages, fully, 8 entries
0xff: cache data is in CPUID 4
0xb2: instruction TLB: 4K, 4-way, 64 entries
Transparent Huge Pages (THP), как следует из названия, предназначены для автоматической поддержки больших страниц в приложениях без необходимости специальной настройки.
В частности, для MySQL использование THP не рекомендуется по нескольким причинам. Во-первых, базы данных MySQL используют небольшие страницы памяти (16 КБ), и использование THP может привести к чрезмерному вводу-выводу, поскольку MySQL считает, что обращается к 16 КБ, в то время как THP сканирует страницу большего размера. Кроме того, огромные страницы имеют тенденцию к фрагментации и снижению производительности. За прошедшие годы также было зарегистрировано несколько случаев, когда использование THP может привести к утечке памяти, что в конечном итоге приведет к сбою MySQL.
Чтобы отключить THP для RHEL/CentOS 6 и RHEL/CentOS 7, выполните следующие команды:
# echo "never" > /sys/kernel/mm/transparent_hugepage/enabled
# echo "never" > /sys/kernel/mm/transparent_hugepage/defrag
Чтобы гарантировать, что это изменение сохранится после перезагрузки сервера, вам нужно будет добавить флаг transparent_hugepage=never в параметры ядра (/etc/sysconfig/grub):
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 elevator=noop transparent_hugepage=never"Создайте резервную копию существующего файла конфигурации GRUB2 (/boot/grub2/grub.cfg), а затем перестройте его заново. На машинах с BIOS это можно сделать с помощью следующей команды:
# grub2-mkconfig -o /boot/grub2/grub.cfgЕсли THP по-прежнему не отключен, может потребоваться отключить настроенные службы:
# systemctl stop tuned
# systemctl disable tuned
Чтобы отключить THP для Ubuntu 20.04 (Focal Fossa), мы рекомендуем использовать пакет sysfsutils. Чтобы установить его, выполните следующую команду:
# apt install sysfsutilsЗатем добавьте следующие строки в файл /etc/sysfs.conf:
kernel/mm/transparent_hugepage/enabled = never
kernel/mm/transparent_hugepage/defrag = never
Перезагрузите сервер и проверьте правильность настроек:
# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
# cat /sys/kernel/mm/transparent_hugepage/defrag
always defer defer+madvise madvise [never]
jemalloc
MySQL Server использует динамическое выделение памяти, поэтому хороший распределитель памяти важен для правильного использования ресурсов ЦП и ОЗУ. Эффективный распределитель памяти должен улучшить масштабируемость, увеличить пропускную способность и держать под контролем объем памяти.
Здесь важно упомянуть характеристику InnoDB. InnoDB создает представление чтения для каждой транзакции и выделяет память для этой структуры из области heap. Проблема в том, что MySQL освобождает кучу при каждой фиксации, и, таким образом, память для чтения перераспределяется при следующей транзакции, что приводит к фрагментации памяти.
jemalloc — это распределитель памяти, в котором особое внимание уделяется предотвращению фрагментации и поддержке масштабируемого параллелизма.
Используя jemalloc (с отключенным THP), вы получаете меньшую фрагментацию памяти и более эффективное управление ресурсами доступной памяти сервера. Вы можете установить пакет jemalloc из репозитория jemalloc или репозитория Percona yum или apt. Мы предпочитаем использовать репозиторий Percona, поскольку считаем его более простым в установке и управлении. Мы описываем шаги по установке репозитория yum в разделе «Установка Percona Server 8.0», а репозитория apt — в разделе «Установка Percona Server 8».
Подключив репозиторий, вы запускаете команду установки для своей операционной системы.
Если вы используете Ubuntu 20.04, вам необходимо выполнить следующие шаги, чтобы включить jemalloc:
-
Установить
jemalloc:# apt-get install libjemalloc2 # dpkg -L libjemalloc2 -
Команда
dpkgпокажет расположение библиотекиjemalloc:# dpkg -L libjemalloc2 /. /usr /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/libjemalloc.so.2 /usr/share /usr/share/doc /usr/share/doc/libjemalloc2 /usr/share/doc/libjemalloc2/README /usr/share/doc/libjemalloc2/changelog.Debian.gz /usr/share/doc/libjemalloc2/copyright -
Переопределить конфигурацию службы по умолчанию с помощью команды:
# systemctl edit mysqlкоторая создаст файл /etc/systemd/system/mysql.service.d/override.conf.
-
Добавить в файл следующую конфигурацию:
[Service] Environment="LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so.2" -
Перезапустить службу MySQL, чтобы включить библиотеку
jemalloc:# systemctl restart mysql -
Чтобы убедиться, что это сработало, при запущенном процессе
mysqldвыполните следующую команду:# lsof -Pn -p $(pidof mysqld) | grep "jemalloc"Вы должны увидеть результат, аналогичный следующему:
mysqld 3844 mysql mem REG 253,0 744776 36550 /usr/lib/x86_64-linux-gnu/libjemalloc.so.2
Если вы используете CentOS/RHEL, вам необходимо выполнить следующие шаги:
-
Установить пакет jemalloc:
# yum install jemalloc # rpm -ql jemalloc -
Команда
rpm -qlпокажет расположение библиотеки:/usr/bin/jemalloc.sh /usr/lib64/libjemalloc.so.1 /usr/share/doc/jemalloc-3.6.0 /usr/share/doc/jemalloc-3.6.0/COPYING /usr/share/doc/jemalloc-3.6.0/README /usr/share/doc/jemalloc-3.6.0/VERSION /usr/share/doc/jemalloc-3.6.0/jemalloc.html -
Переопределить конфигурацию службы по умолчанию с помощью команды:
# systemctl edit mysqldкоторая создаст файл /etc/systemd/system/mysqld.service.d/override.conf.
-
Добавить в файл следующую конфигурацию:
[Service] Environment="LD_PRELOAD=/usr/lib64/libjemalloc.so.1" -
Перезапустить службу MySQL, чтобы включить библиотеку
jemalloc:# systemctl restart mysqld -
Чтобы убедиться, что это сработало, при запущенном процессе
mysqldвыполните следующую команду:# lsof -Pn -p $(pidof mysqld) | grep "jemalloc"Вы должны увидеть результат, аналогичный следующему:
mysqld 4784 mysql mem REG 253,0 212096 33985101 /usr/lib64/libjemalloc.so.1
Регулятор ЦПУ (CPU governor)
Один из наиболее эффективных способов снизить энергопотребление и тепловыделение вашей системы — использовать CPUfreq. CPUfreq, также называемая масштабированием частоты ЦП или масштабированием скорости ЦП, позволяет регулировать тактовую частоту процессора на лету. Эта функция позволяет системе работать на пониженной тактовой частоте для экономии энергии. Правила переключения частот — следует ли и когда переходить на более высокую или низкую тактовую частоту — определяются регулятором CPUfreq. Регулятор определяет характеристики питания системного ЦП, что, в свою очередь, влияет на производительность ЦП. Каждый регулятор имеет собственное уникальное поведение, назначение и пригодность с точки зрения рабочей нагрузки. Однако для баз данных MySQL мы рекомендуем использовать настройку максимальной производительности для достижения наилучшей пропускной способности.
Для CentOS вы можете просмотреть, какой регулятор процессора используется в данный момент, выполнив:
# cat /sys/devices/system/cpu/cpu/cpufreq/scaling_governorВы можете включить режим производительности, запустив:
# cpupower frequency-set --governor performanceДля Ubuntu мы рекомендуем установить пакет linux-tools-common, чтобы у вас был доступ к утилите cpupower:
# apt install linux-tools-commonПосле того, как вы его установили, вы можете перевести регулятор в режим производительности с помощью следующей команды:
# cpupower frequency-set --governor performanceЛучшие практики MySQL
Теперь давайте посмотрим на настройки MySQL Server. В этом разделе предлагаются рекомендуемые значения для основных параметров MySQL, которые напрямую влияют на производительность. Вы увидите, что нет необходимости изменять значения по умолчанию для большинства параметров.
Размер буферного пула
Параметр innodb_buffer_pool_size управляет размером в байтах пула буферов InnoDB, области памяти, где InnoDB кэширует данные таблиц и индексов. Нет никаких сомнений в том, что для настройки InnoDB это самый важный параметр. Типичное эмпирическое правило состоит в том, чтобы установить его примерно на 70% от общего объема доступной оперативной памяти для выделенного сервера MySQL.
Однако чем больше сервер, тем больше вероятность того, что это приведет к пустой трате оперативной памяти. Например, для сервера с 512 ГБ ОЗУ для операционной системы останется 153 ГБ ОЗУ, что больше, чем ей нужно.
Так какое же правило лучше? Установите innodb_buffer_pool_size как можно большим, не вызывая подкачки, когда система выполняет рабочую нагрузку. Это потребует некоторой настройки.
В MySQL 5.7 и более поздних версиях это динамический параметр, поэтому вы можете изменять его на лету без необходимости перезапуска базы данных. Например, чтобы установить его на 1 ГБ, используйте эту команду:
mysql> SET global innodb_buffer_pool_size = 1024*1024*1024;
Query OK, 0 rows affected (0.00 sec)
Чтобы изменения сохранялись при перезапусках, вам нужно добавить этот параметр в my.cnf в разделе [mysqld]:
[mysqld]
innodb_buffer_pool_size = 1G
Параметр innodb_buffer_pool_instances
Один из самых малоизвестных параметров MySQL — innodb_buffer_pool_instances. Этот параметр определяет количество экземпляров, на которые InnoDB разделит буферный пул. Для систем с пулами буферов в диапазоне нескольких гигабайт разделение пула буферов на отдельные экземпляры может улучшить параллелизм за счет уменьшения конкуренции, поскольку разные потоки читают и записывают кэшированные страницы.
Однако, по нашему опыту, установка высокого значения для этого параметра также может привести к дополнительным накладным расходам. Причина в том, что каждый экземпляр пула буферов управляет своим собственным списком свободных мест, списком сброса, списком LRU и всеми другими структурами данных, подключенными к пулу буферов, и защищен собственным мьютексом пула буферов.
Если вы не запускаете тесты, подтверждающие прирост производительности, мы рекомендуем использовать значение по умолчанию (8).
Размер журнала повторов
Журнал повторов — это структура, используемая во время аварийного восстановления для исправления данных, записанных незавершенными транзакциями. Основная цель состоит в том, чтобы гарантировать свойство устойчивости (D) транзакций ACID путем обеспечения повторного восстановления для совершенных транзакций. Поскольку файл повторного выполнения регистрирует все данные, записанные в MySQL еще до фиксации, наличие правильного размера журнала повторного выполнения имеет основополагающее значение для бесперебойной работы MySQL без проблем. Недостаточный размер журнала повторов может даже привести к ошибкам в операциях!
Вот пример ошибки, которую вы можете увидеть при использовании небольшого файла журнала повторов:
[ERROR] InnoDB: The total blob data length (12299456) is greater than 10% of the total redo log size (100663296). Please increase total redo log size.
В этом случае MySQL использовал значение по умолчанию для параметра innodb_log_file_size, которое составляет 48 МБ. Для оценки оптимального размера журнала повторного выполнения существует формула, которую можно использовать в большинстве случаев. Взгляните на следующие команды:
mysql> pager grep sequence
PAGER set to 'grep sequence'
mysql> show engine innodb status\G select sleep(60);
-> show engine innodb status\G
Log sequence number 3836410803
1 row in set (0.06 sec)
1 row in set (1 min 0.00 sec)
Log sequence number 3838334638
1 row in set (0.05 sec)
Порядковый номер журнала — это общее количество байтов, записанных в журнал повторов. Используя команду SLEEP(), мы можем вычислить дельту для этого периода. Затем, используя следующую формулу, мы можем получить оценочное значение объема пространства, необходимого для хранения журналов в течение часа или около того (хорошее эмпирическое правило):
mysql> SELECT (((3838334638 - 3836410803)/1024/1024)*60)/2
-> AS Estimated_innodb_log_file_size;
+--------------------------------+
| Estimated_innodb_log_file_size |
+--------------------------------+
| 55.041360855088 |
+--------------------------------+
1 row in set (0.00 sec)
Мы обычно округляем, поэтому окончательное число будет 56 МБ. Это значение необходимо добавить в my.cnf в разделе [mysqld]:
[mysqld]
innodb_log_file_size=56M
Параметр sync_binlog
Бинарный журнал представляет собой набор файлов журнала, которые содержат информацию об изменениях данных, внесенных в экземпляр сервера MySQL. Они отличаются от файлов повторов и имеют другое применение. Например, они используются для создания реплик и кластеров InnoDB и полезны для выполнения PITR.
По умолчанию сервер MySQL синхронизирует свой бинарный журнал с диском (используя fdatasync()) перед фиксацией транзакций. Преимущество в том, что в случае сбоя питания или сбоя операционной системы транзакции, отсутствующие в бинарном журнале, находятся только в подготовленном состоянии; это позволяет процедуре автоматического восстановления откатывать транзакции, гарантируя, что ни одна транзакция не будет потеряна из бинарного журнала. Однако значение по умолчанию (sync_binlog = 1) снижает производительность. Поскольку это динамический параметр, вы можете изменить его во время работы сервера с помощью следующей команды:
mysql> SET GLOBAL sync_binlog = 0;Чтобы изменение сохранялось после перезагрузки, добавьте параметр в файл my.cnf в разделе [mysqld]:
[mysqld]
sync_binlog=0
Параметры binlog_expire_logs_seconds и expire_logs_days
Чтобы MySQL не заполнял весь диск бинарными логами, вы можете настроить параметры binlog_expire_logs_seconds и expire_logs_days. expire_logs_days указывает количество дней до автоматического удаления бинарных файлов журнала. Однако этот параметр устарел в MySQL 8.0, и вы должны ожидать, что он будет удален в будущем релизе.
Следовательно, лучше использовать binlog_expire_logs_seconds, который устанавливает срок действия бинарного журнала в секундах. Значение по умолчанию для этого параметра — 2592000 (30 дней). MySQL может автоматически удалить файлы бинарного журнала после истечения срока действия либо при запуске, либо при следующем сбросе бинарного журнала.
Параметр innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit управляет балансом между строгим соответствием ACID для операций фиксации и возможной более высокой производительностью, когда операции ввода-вывода, связанные с фиксацией, переупорядочиваются и выполняются пакетами. Это деликатный вариант, и многие предпочитают использовать значение по умолчанию (innodb_flush_log_at_trx_commit=1) на исходных серверах, тогда как для реплик они используют значение 0 или 2. Значение 2 указывает InnoDB записывать данные в файлы журнала после фиксации каждой транзакции, но сбрасывать их на диск только один раз в секунду. Это означает, что вы можете потерять до секунды обновлений в случае сбоя ОС, что при современном оборудовании, поддерживающем до миллиона вставок в секунду, не является незначительным. Значение 0 еще хуже: журналы записываются и сбрасываются на диск только раз в секунду, поэтому вы можете потерять транзакции продолжительностью до секунды, даже если процесс mysqld завершится сбоем.
Параметр innodb_thread_concurrency
innodb_thread_concurrency по умолчанию имеет значение 0, что означает, что внутри MySQL может быть открыто и выполнено бесконечное количество (вплоть до аппаратного предела) потоков. Обычная рекомендация — оставить для этого параметра значение по умолчанию и изменять его только для решения проблем с конкуренцией.
Если ваша рабочая нагрузка постоянно велика или имеет случайные пики, вы можете установить значение innodb_thread_concurrency, используя следующую формулу:
innodb_thread_concurrency = Number of Cores * 2Поскольку MySQL не использует несколько ядер для выполнения одного запроса (это отношение 1:1), каждое ядро будет выполнять один запрос в одну единицу времени. Исходя из нашего опыта, поскольку современные процессоры в целом быстры, хорошим началом является установка максимального количества выполняемых потоков, чтобы удвоить количество доступных процессоров.
Как только количество исполняемых потоков достигает этого предела, дополнительные потоки приостанавливаются на количество микросекунд, заданное параметром конфигурации innodb_thread_sleep_delay, перед помещением в очередь.
innodb_thread_concurrency — это динамическая переменная, и мы можем изменять ее во время выполнения:
mysql> SET GLOBAL innodb_thread_concurrency = 0;Чтобы сделать изменение постоянным, вам также необходимо добавить этот параметр в my.cnf в разделе [mysqld]:
[mysqld]
innodb-thread-concurrency=0
Вы можете проверить, что MySQL применил настройку с помощью этой команды:
mysql> SHOW GLOBAL VARIABLES LIKE '%innodb_thread_concurrency%';Архитектура NUMA
Неоднородный доступ к памяти (NUMA) — это архитектура с общей памятью, описывающая размещение модулей основной памяти относительно процессоров в многопроцессорной системе. В архитектуре с общей памятью NUMA каждый процессор имеет свой собственный локальный модуль памяти, что приводит к явному преимуществу в производительности, поскольку память и процессор физически расположены ближе. В то же время он также может получить доступ к любому модулю памяти, принадлежащему другому процессору, через общую шину (или какой-либо другой тип соединения), как показано на рис. 11-1.

Рисунок 11-1. Обзор архитектуры NUMA
Следующая команда показывает пример доступных узлов на сервере с включенной NUMA:
shell> numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 130669 MB
node 0 free: 828 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46
node 1 size: 131072 MB
node 1 free: 60 MB
node distances:
node 0 1
0: 10 21
1: 21 10
Как мы видим, в узле 0 больше свободной памяти, чем в узле 1. С этим связана проблема, из-за которой ОС выполняет подкачку даже при доступной памяти, как объясняется в отличной статье The MySQL Swap Insanity Problem and the Effects of the NUMA Architecture Джереми Коула.
В MySQL 5.7 параметры innodb_buffer_pool_populate и numa_interleave были удалены, и теперь их функции контролируются параметром innodb_numa_interleave. Когда мы включаем его, мы балансируем распределение памяти между узлами в системе NUMA, избегая проблемы безумия подкачки.
Этот параметр не является динамическим, поэтому для его включения нам нужно добавить его в файл my.cnf в разделе [mysqld] и перезапустить MySQL:
[mysqld]
innodb_numa_interleave = 1
Глава 12
Мониторинг серверов MySQL
Мониторинг можно определить как наблюдение или проверку качества или прогресса чего-либо в течение определенного периода времени. Применяя это определение к MySQL, мы наблюдаем и проверяем «здоровье» и производительность сервера. Таким образом, качество будет заключаться в поддержании времени безотказной работы и обеспечении производительности на желаемом уровне. Так что на самом деле мониторинг — это непрерывная попытка держать вещи под наблюдением и контролем. Обычно это считается чем-то необязательным, что может не понадобиться, если нет особенно высокой нагрузки или высоких ставок. Однако, как и резервное копирование, мониторинг приносит пользу почти каждой установке любой базы данных.
Мы думаем, что наличие мониторинга и понимание получаемых от него метрик — одна из самых важных задач для любого, кто работает с системой баз данных — вероятно, сразу после настройки надлежащих проверенных резервных копий. Как и при работе с базой данных без резервных копий, отсутствие контроля за вашей базой данных опасно: какая польза от системы, которая обеспечивает непредсказуемую производительность и может случайно «отключиться»? Данные могут быть в безопасности, но их нельзя использовать.
В этой главе мы попытаемся дать вам основу для понимания того, как эффективно контролировать MySQL. Эта книга не называется High Performance MySQL, и мы не будем вдаваться в подробности того, что именно означают различные показатели или как выполнять комплексный анализ системы. Но мы поговорим о нескольких основных метриках, которые следует регулярно проверять при каждой установке MySQL, и обсудим важные метрики и инструменты на уровне ОС. Затем мы кратко коснемся нескольких широко используемых методологий оценки производительности системы. После этого мы рассмотрим несколько популярных решений для мониторинга с открытым исходным кодом и, наконец, покажем вам, как собирать данные для целей расследования и мониторинга вручную.
После прочтения этой главы вы должны чувствовать себя комфортно при выборе инструмента мониторинга и понимать некоторые из наиболее важных показателей, которые он показывает.
Метрики операционной системы
Операционная система — это сложная компьютерная программа: интерфейс между приложениями, в нашем случае в основном MySQL, и оборудованием. Раньше ОС были простыми; теперь они, возможно, довольно сложны, но идея, лежащая в их основе, никогда не менялась. ОС пытается скрыть или абстрагироваться от сложности работы с базовым оборудованием. Можно представить себе РСУБД специального назначения, работающую непосредственно на оборудовании, являющуюся собственной операционной системой, но на самом деле вы, скорее всего, никогда этого не увидите. Помимо предоставления удобного и мощного интерфейса, операционные системы также предоставляют множество показателей производительности. Вам не обязательно знать каждый из них, но важно иметь базовое представление о том, как оценивать производительность слоя под вашей базой данных.
Обычно, когда мы говорим о производительности и показателях операционной системы, на самом деле речь идет о производительности оборудования, оцениваемой на уровне операционной системы. Нет ничего плохого в том, чтобы сказать «метрики ОС», но помните, что в конечном итоге они в основном показывают производительность оборудования.
Давайте взглянем на наиболее важные метрики ОС, которые вы хотите отслеживать и в целом иметь представление. В этом разделе мы рассмотрим две основные ОС: Linux и Windows. Unix-подобные системы, такие как macOS и другие, будут иметь либо те же инструменты, что и Linux, либо, по крайней мере, инструменты, показывающие такие же или похожие результаты.
Процессор
Центральный процессор (ЦП) — это сердце любого компьютера. В настоящее время процессоры настолько сложны, что их можно рассматривать как отдельные компьютеры внутри компьютеров. К счастью, основные показатели, которые, как мы думаем, вы должны понимать, универсальны. В этом разделе мы рассмотрим загрузку ЦП по данным Linux и Windows и посмотрим, что влияет на общую нагрузку.
Прежде чем мы приступим к измерению загрузки ЦП, давайте кратко рассмотрим, что такое ЦП и какие его характеристики наиболее важны для операторов баз данных. Мы назвали его «сердцем компьютера», но это слишком упрощенно. Фактически, ЦП — это устройство, которое может выполнять несколько основных (и не очень) операций, поверх которых мы строим уровни сложности от машинного кода до языков программирования высокого уровня, работающих под управлением операционных систем, и, в конечном счете, (для нас) системы баз данных.
Каждая операция, которую выполняет компьютер, выполняется центральным процессором. Как сказал Кевин Клоссон: «Все дело в процессоре». Когда программа активно выполняется — например, MySQL анализирует запрос — ЦП выполняет всю работу. Когда программа ожидает ресурса — MySQL ожидает чтения данных с диска — ЦП участвует в «сообщении» программе, когда данные доступны. Такой список можно продолжать вечно.
Вот несколько наиболее важных показателей ЦП для сервера (или любого компьютера в целом):
- Частота процессора
-
Частота ЦП — это количество раз в секунду, которое ядро ЦП может «просыпаться» для выполнения части работы. Это в основном «скорость» процессора. Чем больше, тем лучше, но на удивление часто частота не является самым важным показателем.
- Кэш-память
-
Размер кеша определяет объем памяти, расположенной непосредственно внутри ЦП, что делает его чрезвычайно быстрым. Опять же, чем больше, тем лучше, и нет никаких недостатков в том, чтобы иметь больше.
- Количество ядер
-
Это количество исполнительных единиц в одном «пакете» ЦП (физический элемент) и сумма этих единиц по всем ЦП, которые мы можем разместить на сервере. В настоящее время становится все труднее найти ЦП с одним ядром: большинство ЦП являются многоядерными системами. У некоторых даже есть «виртуальные» ядра, из-за чего разница между «реальным» количеством процессоров и общим количеством ядер становится еще больше.
Обычно наличие большего количества ядер — это хорошо, но здесь есть оговорки. Как правило, чем больше ядер доступно, тем больше процессов может быть запланировано операционной системой для одновременного выполнения. Для MySQL это означает большее количество запросов, выполняемых параллельно, и меньшее влияние фоновых операций.
Но если половина доступных ядер «виртуальна», вы не получите ожидаемого двукратного увеличения производительности. Скорее, вы можете получить 2-кратное увеличение, или вы можете получить где-то между 1-кратным и 2-кратным увеличением: не каждая рабочая нагрузка (даже в пределах MySQL) выигрывает от виртуальных ядер.
Кроме того, наличие нескольких процессоров в разных разъемах усложняет взаимодействие с памятью (ОЗУ) и другими встроенными устройствами (например, сетевыми картами). Обычно стандартные сервера физически расположены таким образом, что некоторые ЦП (и их ядра) будут получать доступ к частям оперативной памяти быстрее, чем к другим частям — это архитектура NUMA, о которой мы говорили в предыдущей главе. Для MySQL это означает, что распределение памяти и проблемы, связанные с памятью, могут стать болевой точкой. Мы рассмотрели необходимую конфигурацию систем NUMA в разделе «Архитектура NUMA».
Базовым показателем CPU является его загрузка в процентах. Когда вам говорят «CPU 20», вы можете быть совершенно уверены, что имеется в виду «CPU в данный момент занят на 20%». Однако вы никогда не можете быть полностью в этом уверены, поэтому вам лучше перепроверить. Например, 20% одного ядра в многоядерной системе могут составлять всего 1% от общей нагрузки. Попробуем визуализировать эту нагрузку.
В Linux основной командой для получения загрузки ЦП является vmstat. Если запустить его без аргументов, он выведет текущие средние значения, а затем завершится. Если мы запустим его с числовым аргументом (здесь мы назовем его X), он будет печатать значения каждые X секунд. Мы рекомендуем запускать vmstat с числовым аргументом, например, vmstat 1, на несколько секунд. Если вы запустите только vmstat, вы получите средние значения с момента загрузки, которые обычно вводят в заблуждение. vmstat 1 будет выполняться вечно, пока не будет прерван (нажатие Ctrl+C — самый простой выход).
Программа vmstat выводит информацию не только о загрузке процессора, но и о показателях, связанных с памятью и диском, а также о расширенных системных показателях. Вскоре мы изучим некоторые другие разделы выходных данных vmstat, но здесь мы сосредоточимся на метриках ЦП и процессов.
Для начала давайте посмотрим на вывод vmstat на бездействующей системе. Раздел ЦП усечен; мы подробно рассмотрим его позже:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id ...
2 0 0 1229924 1856608 6968268 0 0 39 125 61 144 18 7 75...
1 0 0 1228028 1856608 6969384 0 0 0 84 2489 3047 2 1 97...
0 0 0 1220972 1856620 6977688 0 0 0 84 2828 4712 3 1 96...
0 0 0 1217420 1856644 6976796 0 0 0 164 2405 3164 2 2 96...
0 0 0 1223768 1856648 6968352 0 0 0 84 2109 2762 2 1 97...
Первая строка вывода после заголовка представляет собой среднее значение с момента загрузки, а последующие строки представляют текущие значения при печати. Поначалу вывод может быть трудночитаемым, но к нему довольно быстро привыкаешь. Для ясности в оставшейся части этого раздела мы предоставим усеченный вывод только с той информацией, которая нам нужна, в разделах procs и cpu:
procs ------cpu-----
r b us sy id wa st
2 0 18 7 75 0 0
1 0 2 1 97 0 0
0 0 3 1 96 0 0
0 0 2 2 96 0 0
0 0 2 1 97 0 0
r и b — метрики процесса: количество активно запущенных процессов и количество заблокированных процессов (обычно ожидающих ввода-вывода). Другие столбцы представляют разбивку загрузки ЦП в процентных пунктах (от 0% до 100%, даже в многоядерной системе). Вместе значения в этих столбцах всегда будут составлять 100. Вот что показывают столбцы cpu:
us(пользователь)-
Время, затраченное на выполнение пользовательских программ (или нагрузка, создаваемая этими программами на систему). MySQL Server — это пользовательская программа, как и любая часть кода, существующая вне ядра. Важно отметить, что эта метрика показывает время, проведенное исключительно внутри самой программы. Например, когда MySQL выполняет какие-то вычисления или анализирует сложный запрос, это значение увеличивается. Когда MySQL хочет выполнить дисковую или сетевую операцию, это значение также увеличится, как и два других значения, как вы скоро увидите.
sy(система)-
Время, потраченное на выполнение кода ядра. Из-за того, как устроены Linux и другие Unix-подобные системы, пользовательские программы увеличивают этот счетчик. Например, всякий раз, когда MySQL необходимо выполнить чтение с диска, ядро ОС должно выполнить некоторую работу. Время, потраченное на выполнение этой работы, будет включено в значение
sy. id(бездействие)-
Время, потраченное на бездействие; время простоя. На полностью простаивающем сервере эта метрика будет равна 100.
wa(ожидание ввода/вывода)-
Время ожидания ввода-вывода. Это важный показатель для MySQL, так как чтение и запись в различные файлы составляют относительно большую часть работы MySQL. Когда MySQL выполняет чтение с диска, некоторое время будет потрачено на внутренние функции MySQL и отразится в
us. Затем некоторое время будет проведено внутри ядра и отразится вsy. Наконец, после того как ядро отправило запрос на чтение базовому устройству хранения (которое может быть локальным или сетевым устройством) и ожидает ответа и данных, все затраченное время накапливается вwa. Если наша программа и ядро работают очень медленно и все, что мы делаем, это ввод-вывод, теоретически этот показатель может быть близок к 100. В действительности двузначные значения встречаются редко и обычно указывают на некоторые проблемы с вводом-выводом. Мы подробно поговорим о вводе-выводе в разделе «Диск». st(украдено)-
Эту метрику трудно объяснить, не углубляясь в детали. Справочное руководство MySQL определяет его как «время, украденное у виртуальной машины». Вы можете думать об этом как о времени, в течение которого виртуальная машина хотела выполнить свои инструкции, но должна была ждать, пока хост-сервер выделит процессорное время. Есть несколько причин для такого поведения, пара из которых примечательна. Первая — это избыточное выделение хоста: запуск слишком большого количества больших ВМ, что приводит к ситуации, когда сумма ресурсов, требуемых ВМ, превышает возможности хоста. Вторая — ситуация «шумного соседа», когда одна или несколько ВМ страдают от особо загруженной ВМ.
Другие команды, такие как top (которую мы покажем чуть позже), будут иметь более точную разбивку загрузки процессора. Однако только что перечисленные столбцы являются хорошей отправной точкой и охватывают большую часть того, что вам нужно знать о работающей системе.
Теперь давайте вернемся к нашим выводам vmstat 1 в бездействующей системе:
procs ------cpu-----
r b us sy id wa st
2 0 18 7 75 0 0
1 0 2 1 97 0 0
0 0 3 1 96 0 0
0 0 2 2 96 0 0
0 0 2 1 97 0 0
Что мы можем сказать из этого вывода? Как упоминалось ранее, первая строка является средней с момента загрузки. В среднем в этой системе запущено два процесса (r), из которых 0 заблокировано (b); Загрузка ЦП пользователем составляет 18% (us), загрузка ЦП системы составляет 7% (sy), а в целом ЦП простаивает на 75% (id). Ожидание ввода-вывода (wa) и украденное время (st) равны 0.
После первой каждая строка вывода представляет собой среднее значение за интервал выборки, который в нашем примере равен 1 секунде. Это довольно близко к тому, что мы могли бы назвать «текущими» значениями. Поскольку это простаивающая машина, мы видим, что в целом значения ниже среднего. Выполняется или блокируется только один процесс или ни одного, процессорное время пользователя составляет 2–3%, системное процессорное время составляет 1–2%, а простаивает система 96–97% времени.
Для наглядности давайте посмотрим на вывод vmstat 1 в той же системе, выполняющей вычисления с интенсивным использованием ЦП в одном процессе:
procs ------cpu-----
r b us sy id wa st
2 0 18 7 75 0 0
1 0 13 0 87 0 0
1 0 13 0 86 0 0
1 0 14 0 86 0 0
1 0 15 0 84 0 0
Средние значения с момента загрузки одинаковы, но в каждом примере выполняется один процесс, что приводит к увеличению времени ЦП пользователя до 13–15%. Проблема с vmstat заключается в том, что мы не можем узнать из его вывода, какой именно процесс загружает процессор. Конечно, если это выделенный сервер базы данных, вы можете предположить, что большая часть, если не все процессорное время пользователя будет приходиться на долю MySQL и его потоков, но всякое бывает. Другая проблема заключается в том, что на машинах с большим количеством ядер ЦП вы можете ошибочно принять низкие показания в выводе vmstat за факт, но vmstat дает показания от 0% до 100% даже на 256-ядерной машине. Если 8 ядер такой машины загружены на 100%, время пользователя, показанное vmstat, будет равно 3%, но в действительности некоторая рабочая нагрузка может быть занижена.
Прежде чем мы поговорим о решении этих проблем, давайте немного поговорим о Windows. Многое из того, что мы говорили в целом об использовании ЦП и особенно о процессорах, будет перенесено в Windows с некоторыми заметными отличиями:
-
В Windows нет учета ожидания ввода-вывода, поскольку подсистема ввода-вывода принципиально отличается. Время, затрачиваемое потоками на ожидание ввода-вывода, засчитывается в счетчик простоя.
-
Аналогом системного процессорного времени является, грубо говоря, привилегированное процессорное время.
-
Информация об
stнедоступна.
Счетчики пользователей и бездействия остаются неизменными, поэтому вы можете основывать мониторинг ЦП на пользовательском, привилегированном времени и времени бездействия ЦП, которое отображается в Windows. Есть и другие счетчики и метрики, но это должно быть вам достаточно хорошо известно. Получить текущую загрузку ЦП в Windows можно с помощью множества различных инструментов. Самый простой и, вероятно, самый близкий по духу к vmstat — это старый добрый диспетчер задач, основной инструмент для просмотра показателей производительности Windows. Это легко доступно, это просто, и вы, вероятно, использовали его раньше. Диспетчер задач может показать загрузку ЦП в процентных пунктах с разбивкой по ядрам ЦП, а также разделить время пользователя и ядра.
На рисунке 12-1 показан диспетчер задач, работающий в бездействующей системе.

Рисунок 12-1. Диспетчер задач показывает неактивный процессор
На рисунке 12-2 показан диспетчер задач, работающий в загруженной системе.

Рисунок 12-2. Диспетчер задач показывает загруженный процессор
Как мы уже говорили ранее, у vmstat есть несколько проблем: он не распределяет нагрузку по процессам или ядрам ЦП. Решение обеих проблем требует запуска других инструментов. Почему бы не запустить их сразу? vmstat универсален, дает больше, чем просто показания ЦП, и очень лаконичен. Это хороший способ быстро увидеть, есть ли что-то очень неправильное в данной системе. То же самое касается диспетчера задач, хотя на самом деле он более функционален, чем vmstat.
В Linux следующий по простоте использования инструмент после vmstat — это top, еще один базовый элемент в наборе инструментов любого, кто имеет дело с сервером Linux. Он расширяет базовые показатели ЦП, которые мы обсуждали, и добавляет как разбивку нагрузки по ядрам, так и учет нагрузки по процессам. Когда вы выполняете top без каких-либо аргументов, он запускается в режиме UI (пользовательского интерфейса) терминала или TUI. Нажмите ? чтобы увидеть меню помощи. Чтобы отобразить разбивку нагрузки по ядрам, нажмите 1. На рисунке 12-3 показано, как выглядят выходные данные команды top.

Рисунок 12-3. top в режиме TUI
Здесь вы можете видеть, что каждый процесс получает свое собственное общее использование ЦП, показанное в столбце %CPU. Например, mysqld использует 104,7% всего процессорного времени. Теперь мы также можем увидеть, как эта нагрузка распределяется между множеством ядер сервера. В данном конкретном случае одно ядро (Cpu0) загружено немного больше, чем другое. Бывают случаи, когда MySQL достигает предела пропускной способности одного процессора, и поэтому важна разбивка нагрузки по ядрам. Наличие представления о том, как нагрузка распределяется между процессами, важно, если вы подозреваете, что какой-то мошеннический процесс потребляет ресурсы сервера.
Есть много других инструментов, которые могут показать вам еще больше данных. Мы не можем подробно говорить обо всех из них, но назовем некоторые. mpstat может предоставить очень подробную статистику процессора. pidstat — это универсальный инструмент, предоставляющий статистику использования ЦП, памяти, диска и сети для каждого отдельного запущенного процесса. atop — это расширенная версия top. Их гораздо больше, и у каждого есть свой любимый набор инструментов. Мы твердо верим, что на самом деле важны не сами инструменты, хотя они и помогают, а понимание основных показателей и статистики, которые они предоставляют.
В Windows программа Диспетчер задач на самом деле намного ближе к top, чем к vmstat, хотя мы провели именно это сравнение. Способность Диспетчера задач отображать нагрузку на ядро и нагрузку на процесс делает его весьма полезным первым шагом в любом расследовании. Мы рекомендуем сразу же погрузиться в Монитор ресурсов, так как он предоставляет более подробную информацию. Самый простой способ получить к нему доступ — щелкнуть ссылку «Открыть Монитор ресурсов» в Диспетчере задач.
На рисунке 12-4 показано окно монитора ресурсов с информацией о загрузке ЦП.

Рисунок 12-4. Монитор ресурсов, показывающий сведения о загрузке ЦП
Диспетчер задач и Монитор ресурсов — не единственные инструменты в Windows, способные отображать показатели производительности. Вот еще несколько инструментов, которыми вы, возможно, захотите освоиться. Они более продвинутые, поэтому здесь мы не будем вдаваться в подробности:
- Performance Monitor
-
Этот встроенный инструмент представляет собой графический интерфейс для подсистемы счетчика производительности в Windows. Короче говоря, вы можете просматривать и отображать любые (или все) различные показатели производительности, измеряемые Windows, а не только те, которые относятся к процессору.
- Process Explorer
-
Этот инструмент является частью набора расширенных системных утилит под названием Windows Sysinternals. Он более мощный и продвинутый, чем другие инструменты, перечисленные здесь, и может быть полезен для изучения. В отличие от других инструментов, вам придется устанавливать Process Explorer отдельно с его домашней страницы на сайте Sysinternals.
Диск
Дисковая подсистема или подсистема ввода-вывода имеют решающее значение для производительности базы данных. Хотя ЦП поддерживает каждую операцию, выполняемую в любой данной системе, в частности, для баз данных, диск, вероятно, будет наиболее проблематичным узким местом. Это вполне логично — в конце концов, базы данных хранят данные на диске, а затем обслуживают эти данные с диска. Существует много слоев кэшей поверх медленного и надежного долговременного хранилища, но они не всегда могут быть использованы и не бесконечно велики. Таким образом, понимание базовой производительности дисков чрезвычайно важно при работе с системами баз данных. Другое важное и часто недооцениваемое свойство любой системы хранения вообще не связано с производительностью — это емкость. Мы начнем с этого.
Емкость диска и использование относятся к общему объему данных, которые могут храниться на данном диске (или на множестве дисков вместе в системе хранения), и к тому, сколько этих данных уже сохранено. Это скучные, но важные показатели. Хотя на самом деле нет необходимости следить за емкостью диска, так как она вряд ли изменится без вашего ведома, вы обязательно должны следить за использованием диска и доступным пространством.
Размер большинства баз данных со временем только увеличивается. MySQL, в частности, требует достаточного объема доступного дискового пространства для размещения изменений в таблицах, длительных транзакций и резких скачков нагрузки на запись. Когда на диске больше нет свободного места для использования экземпляром базы данных MySQL, он может дать сбой или перестать работать и вряд ли снова начнет работать, пока не будет освобождено место или не будет добавлено больше места на диске. В зависимости от ваших обстоятельств добавление дополнительной емкости может занять от нескольких минут до нескольких дней. Это то, что вы, вероятно, захотите запланировать заранее.
К счастью, контролировать использование дискового пространства очень просто. В Linux это можно сделать с помощью простой команды df. Без аргументов она покажет емкость и использование в блоках по 1 КБ для каждой файловой системы. Вы можете добавить аргумент -h, чтобы получить удобочитаемые измерения, и указать точку монтирования (или просто путь), чтобы ограничить проверку. Вот пример:
$ df -h /var/lib/mysql
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 40G 18G 23G 45% /
Вывод df говорит сам за себя, и это один из самых простых инструментов для работы. Мы рекомендуем вам поддерживать точки монтирования вашей базы данных на уровне 90%, если только вы не используете многотерабайтные системы. В таком случае идите выше. Уловка, которую вы можете использовать, состоит в том, чтобы поместить несколько больших фиктивных файлов в ту же файловую систему, что и ваша база данных. Если у вас начнет заканчиваться место, вы можете удалить один или несколько из этих файлов, чтобы дать себе больше времени, чтобы отреагировать. Однако вместо того, чтобы полагаться на этот трюк, мы рекомендуем вам иметь некоторый мониторинг дискового пространства.
В Windows надежный File Explorer может предоставить информацию об использовании дискового пространства и емкости, как показано на рисунке 12-5.

Рисунок 12-5. Проводник, показывающий доступное место на диске
Рассмотрев тему дискового пространства, мы теперь углубимся в основные характеристики производительности любой подсистемы ввода-вывода:
- Пропускная способность
-
Сколько байтов данных может быть передано (или извлечено) из хранилища в единицу времени
- Операций ввода-вывода в секунду (IOPS)
-
Количество операций, которые диск (или другая система хранения) способен обслуживать в единицу времени.
- Задержка
-
Сколько времени требуется для обработки системой хранения данных операций чтения или записи
Этих трех свойств достаточно, чтобы описать любую систему хранения и начать формировать понимание того, хороша она, плоха или отвратительна. Как и в разделе ЦП, мы покажем вам несколько инструментов для проверки производительности диска и используем их выходные данные для объяснения конкретных показателей. Мы снова сфокусируемся на Linux и Windows; в других системах будет что-то похожее, так что знания можно переносить.
Аналогом нагрузки ввода-вывода для vmstat в Linux является программа iostat. Схема взаимодействия должна быть вам знакома: вызовите команду без аргументов, и вы получите средние значения с момента загрузки; передайте число в качестве аргумента, и вы получите средние значения за период выборки. Мы также предпочитаем запускать инструмент с аргументом -x, что добавляет много полезных деталей. В отличие от vmstat, iostat предоставляет метрики с разбивкой по блочным устройствам, подобно команде mpstat, о которой мы упоминали ранее.
Давайте посмотрим на пример вывода. Мы будем использовать команду iostat -dxyt 5, которая означает: распечатать отчет об использовании устройства, отобразить расширенную статистику, пропустить первый отчет со средними значениями с момента загрузки, добавить метку времени для каждого отчета и сообщить средние значения за каждый 5-секундный период некоторого выборочного вывода в загруженной системе:
05/09/2021 04:45:09 PM
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s...
sda 0.00 0.00 0.00 1599.00 0.00 204672.00...
...avgrq-sz avgqu-sz await r_await w_await svctm %util
... 256.00 141.67 88.63 0.00 88.63 0.63 100.00
Здесь предстоит разобраться во многом. Мы не будем охватывать все столбцы, но выделим те, которые соответствуют упомянутым ранее свойствам:
- Пропускная способность
-
В выходных данных
iostatстолбцыrkB/sиwkB/sсоответствуют использованию полосы пропускания (чтение и запись соответственно). Если вы знаете характеристики базового хранилища (например, вы можете знать, что оно обещает 200 МБ/с комбинированной пропускной способности для чтения и записи), вы можете сказать, выходите ли вы за пределы. Здесь вы можете увидеть внушительную цифру — чуть более 200 000 КБ в секунду записывается на устройство/dev/sda, и никаких операций чтения не происходит. - IOPS
-
Эта метрика представлена столбцами
r/sиw/s, указывающими количество операций чтения и записи в секунду соответственно. Наш пример показывает 1599 операций записи в секунду. Как и ожидалось, операций чтения не зарегистрировано. - Задержка
-
Показанная несколько более сложным образом, задержка разбита на четыре столбца (или более, в более новых версиях
iostat):await,r_await,w_awaitиsvctm. Для базового анализа вы должны смотреть на значениеawait, которое является средней задержкой для обслуживания любого запроса.r_awaitиw_awaitпрерываютawaitпри чтении и записи.svctime— это устаревшая метрика, которая пытается показать чистую задержку устройства без какой-либо очереди.
Имея эти основные показатели и зная некоторые основные факты об используемом хранилище, можно сказать, что происходит. Наш пример работает на современном твердотельном накопителе NVMe потребительского уровня в одном из ноутбуков автора. Хотя пропускная способность довольно хорошая, каждый запрос в среднем занимает 88 мс, что очень много. Вы также можете выполнить некоторые простые математические действия, чтобы получить шаблон нагрузки ввода-вывода из этих метрик. Например, если мы разделим пропускную способность на IOPS, мы получим цифру 128 КБ на запрос. На самом деле iostat включает эту метрику в столбец avgrq-sz, который показывает средний размер запроса в исторических единицах измерения секторов (512 байт). Вы можете пойти дальше и измерить, что 1599 операций записи в секунду могут обрабатываться только со скоростью ~40 мс/запрос, что означает наличие параллельной нагрузки при записи (а также то, что наше устройство способно обслуживать параллельные запросы).
Шаблоны ввода-вывода — размер запросов, степень параллелизма, случайный или последовательный — могут сдвигать верхние пределы базового хранилища. Большинство устройств будут объявлять максимальную пропускную способность, максимальное количество операций ввода-вывода в секунду и минимальную задержку при определенных условиях, но эти условия могут различаться для измерения максимального количества операций ввода-вывода в секунду и максимальной пропускной способности, а также для оптимальной задержки. Довольно сложно однозначно ответить на вопрос, хорошие или плохие показания метрики. Не зная ничего о базовом хранилище, один из способов оценить его использование — попытаться оценить насыщенность. Насыщенность, которую мы коснемся в разделе «Метод USE», является мерой того, насколько ресурс перегружен. Это становится все более сложным с современным хранилищем, способным эффективно обслуживать длинные очереди параллельно, но в целом очередь на устройстве хранения является признаком насыщения. В выходных данных iostat это столбец avgqu-sz (или aqu-sz в новых версиях iostat), и значения больше 1 обычно означают, что устройство перегружено. В нашем примере показана очередь из 146 запросов, что, вероятно, говорит о высокой загруженности операций ввода-вывода и может быть узким местом.
К сожалению, как вы, возможно, заметили, не существует простого и однозначного показателя использования ресурсов ввода-вывода: для каждого показателя есть свои нюансы. Измерение производительности хранилища - сложная задача!
Одни и те же метрики определяют устройства хранения в Linux, Windows и любой другой ОС.
Давайте теперь рассмотрим основные инструменты Windows для оценки производительности ввода-вывода. Их показания уже должны быть вам знакомы. Мы рекомендуем использовать Монитор ресурсов, который мы показали в разделе «Процессор», но на этот раз перейдите на вкладку «Диск». На рисунке 12.6 показано это представление с MySQL при большой нагрузке на запись.

Рисунок 12-6. Монитор ресурсов, показывающий сведения о нагрузке ввода-вывода
Метрики, представленные монитором ресурсов, аналогичны метрикам iostat. Вы можете увидеть пропускную способность, задержку и длину очереди запросов. Отсутствует одна метрика — IOPS. Чтобы получить эту информацию, вам нужно будет использовать Монитор производительности (perfmon), но мы оставим это в качестве упражнения.
Монитор ресурсов на самом деле показывает немного более подробное представление, чем iostat. Существует разбивка нагрузки ввода-вывода на процесс и дальнейшая разбивка этой нагрузки на файл. Мы не знаем ни одного инструмента в Linux, способного отображать такую разбивку нагрузки одновременно. Чтобы получить разбивку нагрузки по программам, вы можете использовать инструмент pidstat в Linux, о котором мы упоминали ранее. Вот пример вывода:
# pidstat -d 5
...
10:50:01 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
10:50:06 AM 27 4725 0.00 30235.06 0.00 mysqld
10:50:06 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
10:50:11 AM 27 4725 0.00 23379.20 0.00 mysqld
...
Получение разбивки по файлам в Linux довольно легко достигается с помощью BCC Toolkit, в частности инструмента filetop. В наборе инструментов есть еще много инструментов для изучения, но большинство из них довольно продвинуты. Инструментов, которые мы показали здесь, должно быть достаточно для удовлетворения основных потребностей в исследованиях и мониторинге.
Память
Память или ОЗУ — еще один важный ресурс для любой базы данных. Память обеспечивает значительно более высокую производительность по сравнению с диском при чтении и записи данных, поэтому базы данных стремятся как можно больше работать «в памяти». К сожалению, память не является постоянной, поэтому в конечном итоге каждая операция должна отражаться на диске. (Подробнее о производительности диска см. в предыдущем разделе.)
В отличие от разделов процессора и диска, мы фактически не будем говорить о производительности памяти. Несмотря на то, что это важно, это также очень продвинутая и глубокая тема. Вместо этого мы сосредоточимся на использовании памяти. Это также может довольно быстро усложниться, поэтому мы постараемся оставаться сосредоточенными.
Начнем с некоторых основных предпосылок. Каждая программа нуждается в некоторой памяти для работы. Системы баз данных, включая MySQL, обычно требуют много памяти. Когда она заканчивается, у приложений начинаются проблемы с производительностью, и они могут даже дать сбой, как вы увидите в конце раздела. Таким образом, мониторинг использования памяти имеет решающее значение для стабильности любой системы, но особенно для системы баз данных.
В данном случае мы фактически начнем с Windows, так как на первый взгляд у нее немного менее запутанный механизм учета памяти, чем у Linux. Чтобы получить общее использование памяти ОС в Windows, все, что вам нужно сделать, это запустить Диспетчер задач, как описано в разделе «Процессор», перейти на вкладку «Производительность» и выбрать «Память». На рисунке 12-7 вы можете увидеть отображение использования памяти в Диспетчере задач.

Рисунок 12-7. Диспетчер задач, показывающий сведения об использовании памяти
Эта машина имеет в общей сложности 4 ГБ памяти, из которых 2,4 ГБ используются в настоящее время и 1,6 ГБ доступны, что делает общее использование 60%. Это безопасное количество, и мы можем даже захотеть выделить больше памяти для MySQL, чтобы свести к минимуму «потерю» свободной памяти. Некоторые идеи по размеру буферного пула InnoDB в MySQL можно найти в разделе «Размер буферного пула».
В Linux самым простым инструментом для получения сведений об использовании памяти является команда free. Мы рекомендуем использовать его с аргументом -h, который преобразует все поля в удобочитаемый формат. Вот пример вывода на машине под управлением CentOS 7:
$ free -h
total used free shared buff/cache available
Mem: 3.7G 2.7G 155M 8.5M 905M 787M
Swap: 2.0G 13M 2.0G
Теперь это больше данных, чем мы видели в Windows. На самом деле большинство этих счетчиков есть в Windows; они просто не так видны.
Пройдемся по выводу команды. Сейчас мы рассмотрим строку Mem, а о Swap поговорим позже.
Две ключевые метрики здесь used и available, что означает Используется и Доступно в Диспетчере задач. Частая ошибка, которую часто совершали ваши авторы, — смотреть на метрику free, а не на available. Это не правильно! Linux (и, собственно, Windows) не любит оставлять память свободной. В конце концов, свободная память — это потраченный впустую ресурс. Когда есть доступная память, которая не нужна напрямую приложениям, Linux будет использовать эту память для хранения кэша данных, которые считываются и записываются с диска и на него. Позже мы покажем, что Windows делает то же самое, но вы не можете увидеть это из Диспетчера задач. Подробнее о том, почему ошибочно ориентироваться на метрику free, см. на сайте Linux ate my ram.
Давайте далее разберем вывод этой команды. Столбцы:
total-
Общий объем памяти, доступный на машине
used-
Объем памяти, используемой в настоящее время приложениями
free-
Фактическая свободная память, вообще не используемая ОС
shared-
Особый тип памяти, который необходимо специально запрашивать и выделять, и к которому несколько процессов могут обращаться одновременно; поскольку он не используется MySQL, мы опускаем здесь подробности.
buff/cache-
Объем памяти, который ОС в настоящее время использует в качестве кэша для улучшения операций ввода-вывода.
available-
Объем памяти, который приложения могли бы использовать, если бы они в ней нуждались; обычно сумма
freeиbuff/cache
В общем, для базового, но надежного мониторинга вам нужно только посмотреть на сумму total, used и availableё. Linux должен иметь возможность самостоятельно обрабатывать кэшированную память. Мы намеренно не рассматриваем здесь кеш страниц, так как это сложная тема. По умолчанию MySQL в Linux будет использовать кеш страниц, поэтому размер вашего экземпляра должен соответствовать этому. Тем не менее, часто рекомендуемое изменение состоит в том, чтобы указать MySQL избегать кеша страниц (ищите документацию по innodb_flush_method), что позволит самой MySQL использовать больше памяти.
Мы упоминали, что Windows имеет в основном одни и те же показатели; они просто скрыты. Чтобы увидеть это, откройте Монитор ресурсов и перейдите на вкладку «Память». На рисунке 12-8 показано содержимое этой вкладки.

Рисунок 12-8. Монитор ресурсов показывает сведения об использовании памяти
Вы сразу заметите, что объем свободной памяти составляет всего 52 МБ, а резервной памяти прилично, с небольшим количеством измененной памяти. Кэшированное значение в списке ниже представляет собой сумму измененного и резервного количества. Когда был сделан снимок экрана, 1593 МБ памяти использовались кешем, из которых 33 МБ были грязными (dirty) (или модифицированными). Windows, как и Linux, кэширует страницы файловой системы, пытаясь свести к минимуму и сгладить ввод-вывод и максимально использовать память.
Еще одна вещь, которую вы можете увидеть, это разбивка использования памяти для каждого процесса, при этом mysqld.exe занимает чуть менее 500 МБ памяти. В Linux аналогичный вывод можно получить с помощью команды top, которую мы впервые использовали в разделе «Процессор». После запуска top нажмите Shift+M, чтобы отсортировать вывод по использованию памяти и получить удобочитаемые цифры. верхний вывод, показывающий детали использования памяти, показан на рисунке 12-9.

Рисунок 12-9. top показывает сведения об использовании памяти
В этой системе вывод не очень интересен, но вы можете быстро увидеть, что именно MySQL потребляет больше всего памяти своим процессом mysqld.
Прежде чем закончить этот раздел, мы хотим поговорить о том, что происходит, когда у вас заканчивается память. Однако перед этим давайте обсудим подкачку или пейджинг. Здесь следует упомянуть, что большинство современных операционных систем реализуют управление памятью таким образом, что каждое отдельное приложение имеет собственное представление системной памяти (отсюда вы можете видеть, что память приложения называется виртуальной памятью) и что общая сумма виртуальной памяти, которую приложение может использовать превышает общий фактический объем памяти системы. Обсуждение первого пункта лучше подходит для университетского курса по проектированию операционных систем, но последний пункт очень важен при работе с системами баз данных.
Последствия такого дизайна важны, потому что ОС не может просто волшебным образом увеличить емкость системной памяти. На самом деле происходит то, что ОС использует дисковое хранилище для расширения объема памяти, а, как мы уже упоминали, оперативная память обычно гораздо более производительна, чем даже самый быстрый диск. Таким образом, как вы понимаете, за это расширение памяти приходится платить. Пейджинг может происходить несколькими способами и по разным причинам. Наиболее важным для MySQL является тип подкачки, называемый свопингом, — запись частей памяти в выделенное место на диске. В Linux этим местом может быть отдельный раздел или файл. В Windows есть специальный файл pagefile.sys, который в основном используется так же.
Подкачка сама по себе неплоха, но проблематична для MySQL. Проблема в том, что наша база данных думает, что читает что-то из памяти, тогда как на самом деле ОС выгрузила часть этих данных в файл подкачки и на самом деле прочитает их с диска. MySQL не может предсказать, когда эта ситуация произойдет, и ничего не может сделать, чтобы предотвратить ее или оптимизировать доступ. Для конечного пользователя это может означать внезапное необъяснимое снижение времени ответа на запрос. Однако, как мы покажем, наличие некоторого пространства подкачки является важной защитной мерой.
Давайте перейдем к ответу на вопрос, что на самом деле происходит, когда у вас заканчивается память. Коротко: ничего хорошего. Есть только несколько общих результатов для MySQL, когда системе не хватает памяти, поэтому давайте поговорим о них:
-
MySQL запрашивает у ОС больше памяти, но ее нет — все, что можно было бы выгрузить, отсутствует в памяти, а файл подкачки отсутствует или уже заполнен. Обычно такая ситуация приводит к сбою. Это очень плохой результат.
-
В Linux вариант предыдущего пункта заключается в том, что ОС обнаруживает ситуацию, когда система близка к нехватке памяти, и принудительно завершает работу, другими словами, уничтожает один или несколько процессов. Обычно завершаемые процессы будут занимать больше всего памяти, и, как правило, на сервере базы данных MySQL будет основным потребителем памяти. Обычно это происходит до ситуации, описанной в предыдущем пункте.
-
MySQL или какая-либо другая программа заполняют память до такой степени, что ОС должна начать подкачку. Это предполагает, что пространство подкачки (или файл подкачки в Windows) настроено. Как объяснялось несколькими абзацами ранее, производительность MySQL будет неожиданно и непредсказуемо снижаться при выгрузке памяти. Возможно, это лучший результат, чем просто сбой или завершение работы MySQL, но, тем не менее, этого следует избегать.
Таким образом, MySQL либо станет медленнее, либо выйдет из строя, либо будет убит, вот так просто. Теперь вы должны ясно видеть, почему мониторинг доступной и используемой памяти очень важен. Мы также рекомендуем оставить некоторый запас памяти на ваших серверах и настроить файл подкачки. Советы по настройке подкачки в Linux см. в разделе «Лучшие практики для операционных систем».
Сеть
Из всех ресурсов ОС сеть, вероятно, чаще всего обвиняют в случайных необъяснимых проблемах. Для этого есть веская причина: мониторинг сети затруднен. Для понимания проблем с сетью иногда требуется подробный анализ всего сетевого потока. Это своеобразный ресурс, потому что, в отличие от ЦП, диска и памяти, он не содержится в одном сервере. По крайней мере, вам нужны две машины, взаимодействующие друг с другом, чтобы понятие «сеть» вообще имело значение. Конечно, есть локальные связи, но они, как правило, стабильны. И конечно, дисковое хранилище может быть общим, а ЦП и память в случае виртуальных машин также могут быть общими, но сеть всегда связана с несколькими машинами.
Поскольку эта глава посвящена мониторингу, мы не собираемся рассматривать здесь вопросы подключения, тем не менее удивительное количество проблем с сетью сводится к простой проблеме, когда один компьютер не может связаться с другим. Не принимайте подключение как должное. Сетевые топологии обычно сложны, и каждый пакет следует по сложному маршруту через несколько машин. В облачных средах маршруты могут быть еще более сложными и менее очевидными. Если вы считаете, что у вас есть какие-то проблемы с сетью, разумно проверить, можно ли вообще установить соединения.
Мы коснемся следующих свойств любой сети:
- Пропускная способность и ее использование (throughput)
-
Это похоже на ту же концепцию, определенную в разделе «Диск». Каждое сетевое соединение имеет максимальную пропускную способность, обычно выражаемую в единицах объема данных в секунду. Интернет-соединения обычно используют Mbps или мегабиты в секунду, но также могут использоваться MBps или мегабайты в секунду. Сетевые соединения и оборудование накладывают жесткие ограничения на максимальную пропускную способность. Например, в настоящее время обычное бытовое сетевое оборудование редко имеет пропускную способность более 1 Gbps (Гбит/с). Более современное оборудование ЦОД обычно поддерживает 10 Гбит/с. Существует специальное оборудование, которое может увеличить пропускную способность до сотен Гбит/с, но такие соединения обычно представляют собой немаршрутизируемые прямые соединения между двумя серверами.
- Ошибки — их количество и источники
-
Сетевые ошибки неизбежны. На самом деле протокол управления передачей (TCP), основа Интернета и протокол, используемый MySQL, основан на предположении, что пакеты будут потеряны. Вы, несомненно, будете время от времени сталкиваться с ошибками, но высокий уровень ошибок приведет к медленному подключению, так как взаимодействующим сторонам придется повторно отправлять пакеты снова и снова.
Продолжая аналогию с диском, мы могли бы также включить задержку и количество отправленных и полученных пакетов (относительно IOPS). Однако задержку при передаче пакетов можно измерить только приложением, выполняющим фактическую передачу. ОС не может измерить и показать среднюю задержку для сети. А количество пакетов обычно избыточно, поскольку оно соответствует показателям пропускной способности.
Одна конкретная метрика, которую полезно добавить при рассмотрении сетей, — это количество повторно переданных пакетов. Повторная передача происходит, когда пакет потерян или поврежден. Это не ошибка, а обычно результат некоторых проблем с подключением. Как и при нехватке полосы пропускания, увеличение количества повторных передач приведет к нестабильной работе сети.
В Linux мы можем начать с просмотра статистики сетевого интерфейса. Самый простой способ сделать это — запустить команду ifconfig. Ее вывод по умолчанию будет включать каждый сетевой интерфейс на конкретном хосте. Поскольку мы знаем, что в этом случае вся нагрузка идет через eth1, мы можем показать статистику только для него:
$ ifconfig eth1
...
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::a00:27ff:fef6:b4f prefixlen 64 scopeid 0x20
ether 08:00:27:f6:0b:4f txqueuelen 1000 (Ethernet)
RX packets 6217203 bytes 735108061 (701.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11381894 bytes 18025086781 (16.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
...
Мы сразу видим, что сеть довольно исправна, просто по тому факту, что нет ошибок при приеме (RX) или отправке (TX) пакетов. Общая статистика данных RX и TX (701,0 МБ и 16,7 ГБ соответственно) будет расти каждый раз, когда вы запускаете ifconfig, поэтому вы можете легко измерить использование полосы пропускания, запуская его с течением времени. Это не очень удобно, и есть программы, которые показывают скорость передачи в реальном времени, но ни одна из них не поставляется по умолчанию в обычных дистрибутивах Linux. Чтобы увидеть историю скорости передачи и ошибок, вы можете использовать команду sar -n DEV или sar -n EDEV соответственно (sar является частью пакета sysstat, о котором мы упоминали, говоря о iostat):
$ sar -n DEV
IFACE rxpck/s txpck/s rxkB/s txkB/s...
06:30:01 PM eth0 0.16 0.08 0.01 0.01...
06:30:01 PM eth1 7269.55 13473.28 843.84 21618.70...
06:30:01 PM lo 0.00 0.00 0.00 0.00...
06:40:01 PM eth0 0.48 0.28 0.03 0.05...
06:40:01 PM eth1 7844.90 13941.09 893.95 19204.10...
06:40:01 PM lo 0.00 0.00 0.00 0.00...
...rxcmp/s txcmp/s rxmcst/s
... 0.00 0.00 0.00
... 0.00 0.00 0.00
... 0.00 0.00 0.00
... 0.00 0.00 0.00
... 0.00 0.00 0.00
... 0.00 0.00 0.00
$ sar -n EDEV
04:30:01 PM IFACE rxerr/s txerr/s coll/s rxdrop/s...
06:40:01 PM eth0 0.00 0.00 0.00 0.00...
06:40:01 PM eth1 0.00 0.00 0.00 0.00...
06:40:01 PM lo 0.00 0.00 0.00 0.00...
...txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
... 0.00 0.00 0.00 0.00 0.00
... 0.00 0.00 0.00 0.00 0.00
... 0.00 0.00 0.00 0.00 0.00
Опять же, мы видим, что в нашем примере интерфейс eth1 достаточно загружен, но сообщений об ошибках нет. Если мы остаемся в пределах пропускной способности, производительность сети должна быть нормальной.
Чтобы получить полное подробное представление о различных ошибках и проблемах, которые произошли в сети, вы можете использовать команду netstat. С флагом -s он сообщит о большом количестве счетчиков. Для простоты мы покажем только часть вывода раздела Tcp с несколькими повторными передачами. Для получения более подробного обзора ознакомьтесь с разделом выходных данных TcpExt:
$ netstat -s
...
Tcp:
55 active connections openings
39 passive connection openings
0 failed connection attempts
3 connection resets received
9 connections established
14449654 segments received
25994151 segments send out
54 segments retransmitted
0 bad segments received.
19 resets sent
...
Учитывая огромное количество отправленных сегментов, скорость повторной передачи превосходна. Эта сеть, кажется, в порядке.
В Windows мы снова прибегаем к проверке Монитора ресурсов, который предоставляет большинство нужных нам метрик и многое другое. На рисунке 12.10 показаны представления, связанные с сетью, которые Монитор ресурсов может предложить на узле, выполняющем искусственную нагрузку на MySQL.

Рисунок 12-10. Монитор ресурсов, показывающий сведения об использовании сети
Чтобы узнать количество ошибок в Windows, вы можете использовать команду netstat. Обратите внимание, что хотя у нее то же имя, что и у инструмента Linux, который мы использовали ранее, они немного отличаются. В этом случае у нас нет ошибок:
C:\Users\someuser> netstat -e
Interface Statistics
Received Sent
Bytes 58544920 7904968
Unicast packets 62504 32308
Non-unicast packets 0 364
Discards 0 0
Errors 0 0
Unknown protocols 0
Модификатор -s для netstat существует и в Windows. Опять же, здесь мы показываем только часть вывода:
C:\Users\someuser> netstat -s
...
TCP Statistics for IPv4
Active Opens = 457
Passive Opens = 30
Failed Connection Attempts = 3
Reset Connections = 121
Current Connections = 11
Segments Received = 61237201
Segments Sent = 30866526
Segments Retransmitted = 0
...
Судя по показателям, которые мы выделили для мониторинга — использованию полосы пропускания и ошибкам, — сеть этой системы работает идеально. Мы понимаем, что это лишь малая часть того, что касается сложности сетевого взаимодействия. Однако этот минимальный набор инструментов может отлично помочь вам понять, стоит ли вообще обвинять свою сеть.
На этом довольно длинный обзор основ мониторинга ОС заканчивается. Вероятно, мы могли бы сделать его короче, и вы можете спросить, почему мы поместили все это в книгу о MySQL. Ответ довольно прост: потому что это важно. Любая программа взаимодействует с ОС и требует некоторых системных ресурсов. MySQL по своей природе обычно очень требовательная программа, и вы ожидаете, что она будет работать хорошо. Однако для этого вам нужно убедиться, что у вас есть необходимые ресурсы и что у вас не заканчивается производительность диска, процессора или сети или просто хватает емкости диска и памяти. Иногда проблема с системными ресурсами, вызванная MySQL, также может привести к обнаружению проблем в самой MySQL. Например, плохо написанный запрос может сильно нагрузить процессор и диск, вызывая всплеск использования памяти.
Мониторинг сервера MySQL
Мониторинг MySQL одновременно прост и сложен. Это легко, потому что MySQL предоставляет почти 500 переменных состояния, которые позволяют вам довольно точно видеть, что происходит внутри вашей базы данных. В дополнение к этому InnoDB имеет собственный диагностический вывод. Однако мониторинг затруднен, потому что может быть сложно разобраться в имеющихся у вас данных.
В этом разделе мы собираемся объяснить основы мониторинга MySQL, начиная с того, что такое переменные состояния и как их получить, и переходя к диагностике InnoDB. Как только это будет рассмотрено, мы покажем несколько основных рецептов, которые, по нашему мнению, должны быть частью каждого пакета мониторинга базы данных MySQL. С помощью этих рецептов и того, что вы узнали о мониторинге ОС в предыдущем разделе, вы сможете понять, что происходит с вашей системой.
Переменные состояния
Мы начнем с переменных состояния сервера MySQL. Эти переменные, в отличие от параметров конфигурации, доступны только для чтения и отображают информацию о текущем состоянии сервера MySQL. Они различаются по своей природе: большинство из них представляют собой либо постоянно увеличивающиеся счетчики, либо датчики со значениями, движущимися вверх и вниз. Однако некоторые из них представляют собой статические текстовые поля, которые помогают понять текущую конфигурацию сервера. Доступ ко всем переменным состояния можно получить на глобальном уровне сервера и на уровне текущего сеанса. Но не каждая переменная имеет смысл на уровне сеанса, а некоторые будут показывать одинаковые значения на обоих уровнях.
SHOW STATUS используется для получения текущих значений переменных состояния. Он имеет два необязательных модификатора, GLOBAL и SESSION, и по умолчанию имеет значение SESSION. Вы также можете указать имя переменной или шаблон, но это не обязательно. Команда в следующем примере показывает все значения переменных состояния для текущего сеанса:
mysql> SHOW STATUS;
+-----------------------------------------------+-----------------------+
| Variable_name | Value |
+-----------------------------------------------+-----------------------+
| Aborted_clients | 0 |
| Aborted_connects | 0 |
| Acl_cache_items_count | 0 |
| ... |
| Threads_connected | 2 |
| Threads_created | 2 |
| Threads_running | 2 |
| Uptime | 305662 |
| Uptime_since_flush_status | 305662 |
| validate_password.dictionary_file_last_parsed | 2021-05-22 20:53:08 |
| validate_password.dictionary_file_words_count | 0 |
+-----------------------------------------------+-----------------------+
482 rows in set (0.01 sec)
Прокрутка сотен строк вывода неоптимальна, поэтому давайте вместо этого используем подстановочный знак, чтобы ограничить количество запрашиваемых переменных. LIKE в SHOW STATUS работает так же, как и для обычных операторов SELECT, как описано в главе 3:
mysql> SHOW STATUS LIKE 'Created%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 7 |
| Created_tmp_tables | 0 |
+-------------------------+-------+
3 rows in set (0.01 sec)
Теперь вывод намного легче читать. Чтобы прочитать значение одной переменной, просто укажите ее полное имя в кавычках без подстановочного знака, например:
mysql> SHOW STATUS LIKE 'Com_show_status';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Com_show_status | 11 |
+-----------------+-------+
1 row in set (0.00 sec)
Вы можете заметить, что в выходных данных для переменных состояния Created% MySQL показал значение 7 для Created_tmp_files. Означает ли это, что в этом сеансе было создано семь временных файлов и ноль временных таблиц? Нет — на самом деле переменная состояния Created_tmp_files имеет только глобальную область действия. На данный момент это известная проблема с MySQL: вы всегда видите все переменные состояния, независимо от запрошенной области, но их значения будут иметь правильную область. Документация MySQL включает полезный Server Status Variable Reference, который может помочь вам понять область действия различных переменных.
В отличие от Created_tmp_files, переменная Com_show_status имеет область действия «both», что означает, что вы можете получить глобальный счетчик, а также значение для сеанса. Посмотрим, что на практике:
mysql> SHOW STATUS LIKE 'Com_show_status';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Com_show_status | 13 |
+-----------------+-------+
1 row in set (0.00 sec)
mysql> SHOW GLOBAL STATUS LIKE 'Com_show_status';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Com_show_status | 45 |
+-----------------+-------+
1 row in set (0.00 sec)
Еще одна важная вещь, на которую следует обратить внимание при просмотре переменных состояния, заключается в том, что большинство из них можно сбросить до нуля на уровне сеанса. Это достигается запуском команды FLUSH STATUS. Эта команда сбрасывает переменные состояния во всех подключенных сеансах на ноль после добавления их текущих значений в глобальные счетчики. Таким образом, FLUSH STATUS работает на уровне сеанса, но для всех сеансов. Чтобы проиллюстрировать это, мы сбросим значения переменных состояния в сеансе, который мы использовали ранее:
mysql> FLUSH STATUS;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW STATUS LIKE 'Com_show_status';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Com_show_status | 1 |
+-----------------+-------+
1 row in set (0.00 sec)
mysql> SHOW GLOBAL STATUS LIKE 'Com_show_status';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Com_show_status | 49 |
+-----------------+-------+
1 row in set (0.00 sec)
Несмотря на то, что глобальный счетчик продолжает увеличиваться, счетчик сеансов был сброшен до 0 и увеличен только до 1, когда мы выполнили команду SHOW STATUS. Это может быть полезно, чтобы увидеть, как, например, выполнение одного запроса изменяет значения переменных состояния (в частности, семейство переменных состояния Handler_*).
Обратите внимание, что невозможно сбросить глобальные счетчики без перезагрузки.
Основные рецепты мониторинга
Вы можете отслеживать множество показателей в различных комбинациях. Однако мы считаем, что некоторые из них должны быть в наборе инструментов каждого оператора базы данных. Пока вы изучаете MySQL, этого должно быть достаточно, чтобы дать вам разумное представление о том, как работает ваша база данных. Большинство существующих систем мониторинга должны охватывать их и обычно включают гораздо больше показателей. Возможно, вы никогда не будете настраивать сбор данных самостоятельно, но наше объяснение должно помочь вам лучше понять, что именно сообщает вам ваша система мониторинга.
Мы собираемся дать несколько широких категорий метрик в следующих подразделах, в которых мы подробно расскажем о том, что мы считаем одними из наиболее важных счетчиков.
Доступность сервера MySQL
Это самое главное, за чем вы должны следить. Если MySQL Server не принимает соединения или не работает, все остальные показатели не имеют значения.
MySQL Server — это надежное программное обеспечение, способное безотказно работать в течение нескольких месяцев или лет. Тем не менее, есть ситуации, которые могут привести к преждевременному незапланированному отключению (или, проще говоря, к сбою). Например, в разделе «Память» мы обсуждали, что условия нехватки памяти могут привести к сбою или завершению работы MySQL. Случаются и другие инциденты. В MySQL есть ошибки, приводящие к сбоям, однако в настоящее время они редки. Есть и операционные ошибки: кто не забывал поднять базу после планового обслуживания? Отказ оборудования, перезапуск серверов — многие вещи могут поставить под угрозу доступность MySQL.
Существует несколько подходов к мониторингу доступности MySQL, и нет одного наилучшего; лучше совмещать несколько. Очень простой базовый подход заключается в проверке того, что процесс mysqld (или mysqld.exe) действительно запущен и виден с уровня ОС. В Linux и Unix-подобных системах вы можете использовать для этого команду ps, а в Windows вы можете проверить диспетчер задач или запустить команду Get-Service PowerShell. Это не бесполезная проверка, но у нее есть свои проблемы. Во-первых, тот факт, что MySQL работает, не гарантирует, что он действительно делает то, что должен, то есть обрабатывает запросы клиентов. MySQL может быть перегружен нагрузкой или страдать от сбоя диска и работать невыносимо медленно. С точки зрения ОС процесс запущен, но с точки зрения клиента он все равно остановлен.
Второй подход заключается в проверке доступности MySQL с точки зрения приложения. Обычно это достигается запуском монитора MySQL и выполнением какого-нибудь простого короткого запроса. В отличие от предыдущей проверки, эта проверяет возможность установки нового соединения с MySQL и обработку запросов базой данных. Вы можете разместить эти проверки на стороне приложения, чтобы сделать их еще ближе к тому, как приложения видят базу данных. Вместо того, чтобы настраивать такие проверки как независимые сущности, приложения можно настроить так, чтобы они исследовали MySQL и сообщали о явных ошибках либо операторам, либо системе мониторинга.
Третий подход лежит между двумя предыдущими и сконцентрирован на стороне БД. При мониторинге MySQL вам, по крайней мере, потребуется выполнить простые запросы к базе данных, чтобы проверить переменные состояния. Если эти запросы завершатся неудачей, ваша система мониторинга должна предупредить, так как, возможно, у MySQL начинаются проблемы. Вариантом может быть проверка того, были ли какие-либо данные от целевого экземпляра получены вашей системой мониторинга за последние несколько минут.
В идеале в результате этих проверок должно получиться не только оповещение «MySQL не работает» в нужное время, но и некоторая подсказка о том, почему она не работает. Например, если второй тип проверки не может инициировать новое соединение, потому что у MySQL закончились соединения, то это должно быть частью предупреждения. Если проверка третьего типа не проходит, а проверка первого типа в порядке, то это ситуация, отличная от сбоя.
Клиентские подключения
MySQL Server — это многопоточная программа, подробно описанная в разделе «Демон сервера MySQL». Каждый клиент, подключающийся к базе данных, вызывает создание нового потока в процессе сервера MySQL (mysqld или mysqld.exe). Этот поток будет отвечать за выполнение инструкций, отправленных клиентом, и теоретически может выполняться столько же одновременных запросов, сколько существует клиентских потоков.
Каждое соединение и его поток создают небольшую нагрузку на сервер MySQL, даже когда они простаивают. Кроме того, с точки зрения базы данных, каждое соединение является обязательством: база данных не может знать, когда соединение отправит запрос. Параллелизм, или количество одновременно выполняемых транзакций и запросов, обычно увеличивается с увеличением количества установленных соединений. Параллелизм сам по себе неплох, но у каждой системы есть предел масштабируемости. Как вы помните из раздела «Метрики операционной системы», ресурсы процессора и диска имеют ограничения производительности, и их невозможно преодолеть. И даже при бесконечном количестве ресурсов ОС сама MySQL имеет внутренние пределы масштабируемости.
Проще говоря: количество подключений, особенно активных, в идеале должно быть минимальным. Со стороны MySQL отсутствие соединений — идеальная ситуация, но со стороны приложения это неприемлемо. Некоторые приложения, тем не менее, не пытаются ограничить количество соединений, которые они устанавливают, и запросов, которые они посылают, предполагая, что база данных позаботится об этой нагрузке. Это может создать опасную ситуацию, известную как thundering herd: по какой-то причине запросы выполняются дольше, и приложение реагирует, отправляя все больше и больше запросов, перегружая базу данных.
Наконец, у MySQL есть верхний предел количества клиентских подключений, управляемый системной переменной max_connections. Как только количество существующих подключений достигнет значения этой переменной, MySQL откажется создавать новые подключения. Это плохо. max_connections следует использовать для защиты от полного обвала сервера, если клиенты устанавливают тысячи подключений. Но в идеале вы должны отслеживать количество подключений и работать с командами приложений, чтобы это число было низким.
Давайте рассмотрим конкретные счетчики соединений и потоков, которые предоставляет MySQL:
Threads_connected-
Количество подключенных в данный момент клиентских потоков или, другими словами, количество установленных клиентских подключений. Мы объясняли важность этого в нескольких последних абзацах, поэтому вы должны знать, почему вы должны это проверить.
Threads_running-
Количество клиентских потоков, которые в данный момент выполняют инструкцию. В то время как
Threads_connectedуказывает на возможность высокого параллелизма,Threads_runningфактически показывает текущую меру этого параллелизма. Всплески в этом счетчике указывают либо на повышенную нагрузку со стороны приложения, либо на медленную работу базы данных, что приводит к накоплению запросов. Max_used_connections-
Максимальное количество установленных соединений, зарегистрированных с момента последнего перезапуска сервера MySQL. Если вы подозреваете, что произошел поток подключений, но у вас нет записанной истории изменений в
Threads_connected, вы можете проверить эту переменную состояния, чтобы увидеть самый высокий зарегистрированный пик. Max_used_connections_time-
Дата и время, когда MySQL Server видел максимальное количество подключений с момента последнего перезапуска до настоящего времени.
Еще одна важная метрика, которую необходимо отслеживать в отношении подключений, — это частота их отказов. Повышенный уровень ошибок может указывать на то, что у ваших приложений возникают проблемы при обмене данными с вашей базой данных. MySQL различает соединения, которые клиентам не удалось установить, и существующие соединения, которые не удалось установить из-за тайм-аута, например:
Aborted_clients-
Количество уже установленных соединений, которые были прерваны. В документации MySQL упоминается, что «клиент умер, не закрыв соединение должным образом», но это также может произойти, если между сервером и клиентом возникла проблема с сетью. Частыми источниками увеличения этого счетчика являются нарушения
max_allowed_packet(см. «Область видимости параметров») и тайм-ауты сеанса (см. системные переменныеwait_timeoutиinteractive_timeout). Следует ожидать некоторых ошибок, но следует проверять острые всплески. Aborted_connects-
Количество новых соединений, которые не удалось установить. Среди причин могут быть неправильные пароли, подключение к базе данных, для которой у пользователя нет разрешения, несоответствие протоколов, нарушение времени ожидания подключения и достижение максимального_подключения, среди прочего. Они также включают различные проблемы, связанные с сетью. Под подстановочным знаком
Connection_errors_%находится семейство переменных состояния, которые более подробно рассматривают некоторые конкретные проблемы. Необходимо проверить увеличениеAborted_connects, так как это может указывать на проблему с конфигурацией приложения (неправильный пользователь/пароль) или проблему с базой данных (исчерпание соединений).
Количество запросов
Следующая широкая категория метрик — это метрики, связанные с запросами. В то время как Threads_running показывает, сколько сеансов активно одновременно, метрики в этой категории будут показывать качество нагрузки, создаваемой этими сеансами. Здесь мы начнем с рассмотрения общего количества запросов, затем перейдем к разбивке запросов по типам и, наконец, что не менее важно, рассмотрим, как выполняются запросы.
Важно отслеживать количество запросов. Каждый из тридцати запущенных потоков может выполнять один часовой запрос или несколько десятков запросов в секунду. Выводы, которые вы сделаете, будут в каждом случае совершенно разными, и профиль нагрузки, скорее всего, тоже изменится. Это важные показатели, показывающие количество выполненных запросов:
Queries-
Проще говоря, эта глобальная переменная состояния дает количество операторов, выполненных сервером (исключая
COM_PINGиCOM_STATISTICS). Если вы запуститеSHOW GLOBAL STATUS LIKE 'Queries'на бездействующем сервере, вы увидите, что значение счетчика увеличивается с каждым выполнением командыSHOW STATUS. Questions-
Почти то же, что и
Queries, но исключает операторы, выполняемые внутри хранимых процедур, а также следующие типы запросов:COM_PING,COM_STATISTICS,COM_STMT_PREPARE,COM_STMT_CLOSEиCOM_STMT_RESET. Если только клиенты вашей базы данных не используют хранимые процедуры широко, метрикаQuestionsближе к количеству фактических запросов, выполняемых сервером, по сравнению с количеством операторов вQueries. В дополнение к этому,Questions— это как переменная уровня сеанса, так и глобальная переменная состояния. - QPS
-
Число запросов в секунду. Это синтетическая метрика, которую вы можете получить, посмотрев, как переменная запросов меняется с течением времени. QPS, основанное на
Queries, будет включать практически любую инструкцию, которую выполняет сервер.Метрика QPS не говорит нам о качестве выполненных запросов, то есть о степени их воздействия на сервер, но, тем не менее, это полезный показатель. Обычно нагрузка на БД со стороны приложений носит регулярный характер. Она может двигаться волнообразно (больше днем, меньше ночью), но в течение недели или месяца проявится закономерность количества запросов с течением времени. Когда вы получаете отчет о медленной работе базы данных, просмотр QPS может дать вам быстрое представление о том, произошел ли внезапный неожиданный рост нагрузки приложения. С другой стороны, падение количества запросов в секунду может указывать на то, что проблемы связаны с базой данных, поскольку она не может обрабатывать столько запросов, сколько обычно, за одно и то же время.
Типы запросов и их качество
Следующим логическим шагом после получения информации о количестве запросов в секунду является понимание того, какие типы запросов выполняются клиентами, а также влияние этих запросов на сервер. Все запросы неравнозначны, а некоторые, можно сказать, плохие или производят ненужную нагрузку на систему. Поиск и перехват таких запросов — важная часть мониторинга. В этом разделе мы пытаемся ответить на вопрос «много ли плохих запросов?» а в разделе «Журнал медленных запросов» мы покажем вам, как поймать конкретных нарушителей.
Типы запросов
Каждый выполняемый MySQL запрос имеет тип. Более того, любая команда, которую вы можете выполнить, имеет тип. MySQL отслеживает различные типы команд и запросов, выполняемых с помощью семейства переменных состояния Com_%. В MySQL 8.0.25 таких переменных 172, что составляет почти треть всех переменных состояния. Как вы можете догадаться по этому числу, MySQL подсчитывает множество команд, о которых вы, возможно, даже не подозревали: например, Com_uninstall_plugin подсчитывает количество вызовов UNINSTALL PLUGIN, а Com_help подсчитывает использование статуса HELP.
Каждая переменная состояния Com_% доступна как на глобальном уровне, так и на уровне сеанса, как показано для Com_show_status в разделе «Переменные состояния». Однако MySQL не предоставляет счетчики других потоков для переменных Com_%, поэтому в целях мониторинга здесь предполагаются глобальные переменные состояния. Можно получить счетчики операторов других сеансов, но это достигается с помощью семейства событий Performance Schema, которое называется statement/sql/%. Это может быть полезно, чтобы попытаться найти поток, который отправляет непропорциональное количество операторов определенного типа, но это немного сложно и подпадает под исследование, а не мониторинг. Вы можете найти более подробную информацию в разделе Performance Schema Status Variable Tables документации MySQL.
Поскольку существует так много переменных состояния Com_%, отслеживание каждого типа команды было бы слишком излишним и бессмысленным. Однако вы должны попытаться сохранить значения всех из них. Вы можете пойти двумя путями, глядя на эти счетчики.
Первый вариант — выбрать типы команд, соответствующие вашему профилю загрузки базы данных, и отслеживать их. Например, если клиенты вашей базы данных не используют хранимые процедуры, просмотр Com_call_procedure — пустая трата времени. Хорошим начальным выбором является рассмотрение SELECT и основных операторов DML, которые обычно составляют большую часть нагрузки любой системы баз данных, например, Com_select, Com_insert, Com_update и Com_delete (имена переменных состояния здесь говорят сами за себя). Одна интересная вещь, которую делает MySQL, это учет обновлений и удалений нескольких таблиц (см. «Выполнение обновлений и удалений с несколькими таблицами») отдельно, в Com_update_multi и Com_delete_multi; их также следует отслеживать, если вы не уверены, что такие операторы никогда не запускаются в вашей системе.
Затем вы можете просмотреть все переменные состояния Com_%, увидеть, какие из них растут, и добавить их к выбранным отслеживаемым переменным. К сожалению, недостатком этого подхода является то, что вы можете пропустить некоторые неожиданные всплески.
Еще один способ взглянуть на эти счетчики — посмотреть на топ 5 или 10 из них с течением времени. Таким образом, внезапную смену режима нагрузки будет сложнее не заметить.
Знание того, какие типы запросов выполняются, важно для формирования общего понимания нагрузки на данную базу данных. Более того, это меняет подход к настройке базы данных, поскольку, например, для рабочей нагрузки с большим количеством вставок может потребоваться другая настройка по сравнению с рабочей нагрузкой только для чтения или в основном для чтения. Изменения в профиле загрузки запроса, такие как внезапное появление тысяч операторов UPDATE, выполняемых в секунду, могут указывать на изменения на стороне приложения.
Качество запроса
Следующим шагом после того, как мы узнаем, какие запросы выполняются, является понимание их качества или их влияния на систему. Мы упоминали об этом, но стоит повторить: не все запросы одинаковы. Некоторые из них будут нагружать систему больше, чем другие. Просмотр общих метрик, связанных с запросами, может дать вам заблаговременное предупреждение о росте проблем в базе данных. Вы узнаете, что можно заметить проблемное поведение, отслеживая всего несколько счетчиков.
Select_scan подсчитывает количество запросов, которые вызвали полное сканирование таблицы или, другими словами, заставили MySQL прочитать всю таблицу для формирования результата. Теперь мы должны сразу признать, что полное сканирование таблицы не всегда является проблемой. В конце концов, иногда просто чтение всех данных в таблице является жизнеспособной стратегией выполнения запроса, особенно когда количество строк невелико. Вы также можете ожидать, что всегда будет происходить некоторое количество полных сканирований таблиц, так как многие таблицы каталога MySQL читаются таким образом. Например, простое выполнение запроса SHOW GLOBAL STATUS приведет к увеличению Select_scan в два раза. Однако часто полное сканирование таблиц означает, что есть запросы к базе данных, которые выполняются неоптимально: либо они неправильно написаны и неэффективно фильтруют данные, либо просто отсутствуют индексы, которые могут использовать запросы. Более подробную информацию о деталях и планах выполнения запросов мы приводим в разделе «Оператор EXPLAIN».
Select_full_join аналогичен Select_scan, но подсчитывает количество запросов, вызвавших полное сканирование таблицы, на которую ссылаются, в запросе JOIN. Таблица, на которую ссылаются, является самой правой таблицей в условии JOIN — дополнительную информацию см. в разделе «Объединение двух таблиц». Опять же, как и в случае с Select_scan, трудно сказать, что большое количество Select_full_join всегда плохо. Например, в больших системах хранения данных обычно используются компактные словарные таблицы, и их полное чтение может не быть проблемой. Тем не менее, обычно высокое значение этой переменной состояния указывает на наличие плохо работающих запросов.
Select_range подсчитывает количество запросов, которые сканировали данные с некоторым условием диапазона (описано в разделе «Выбор строк с помощью предложения WHERE»). Обычно это вообще не проблема. Если условие диапазона невозможно удовлетворить с помощью индекса, значение Select_scan или Select_full_join будет расти вместе с этой переменной состояния. Вероятно, единственный случай, когда значение этого счетчика может указывать на проблему, — это когда вы видите, что оно растет, даже если вы знаете, что большинство запросов, выполняемых в базе данных, на самом деле не используют диапазоны. Пока количество связанных счетчиков сканирования таблицы также не растет, проблема, скорее всего, все еще безобидна.
Select_full_range_join объединяет Select_range и Select_full_join. Эта переменная содержит счетчик запросов, вызвавших сканирование диапазона таблиц, на которые ссылаются в запросах JOIN.
До сих пор мы считали отдельные запросы, но MySQL также ведет аналогичный учет для каждой строки, которую он считывает из механизмов хранения! Семейство переменных состояния, показывающих эти счетчики, — это переменные Handler_%. Проще говоря, каждая строка, которую MySQL читает, увеличивает некоторую переменную Handler_%. Объединение этой информации с типом запроса и счетчиками качества запроса, которые вы видели до сих пор, может сказать вам, например, является ли проблемой полное сканирование таблиц, которое выполняется в вашей базе данных.
Первый обработчик, который мы рассмотрим, это Handler_read_rnd_next, который подсчитывает количество прочитанных строк при выполнении полного или частичного сканирования таблицы. В отличие от переменных состояния Select_%, переменные Handler_% не имеют красивых, легко запоминающихся имен, поэтому необходимо некоторое усилие для запоминания. Высокие значения переменной состояния Handler_read_rnd_next в целом указывают на то, что либо множество таблиц не индексируются должным образом, либо многие запросы не используют существующие индексы. Помните, что при объяснении Select_scan мы упомянули, что некоторые полные сканирования таблиц не вызывают проблем. Чтобы понять, верно это или нет в вашем случае, посмотрите на отношение Handler_read_rnd_next к другим обработчикам. Вы хотите увидеть низкое значение для этого счетчика. Если ваша база данных возвращает в среднем миллион строк в минуту, то вы, вероятно, хотите, чтобы количество строк, возвращаемых при полном сканировании, исчислялось тысячами, а не десятками или сотнями тысяч.
Handler_read_rnd подсчитывает количество строк, обычно читаемых при выполнении сортировки результирующего набора. Высокие значения могут указывать на наличие множества полных просмотров таблиц и объединений без использования индексов. Однако, в отличие от Handler_read_rnd_next, это не является верным признаком проблем.
Handler_read_first подсчитывает, сколько раз была прочитана первая запись индекса. Высокое значение этого счетчика указывает на то, что выполняется много полных просмотров индекса. Это лучше, чем полное сканирование таблицы, но все равно вызывает проблемы. Вероятно, в некоторых запросах отсутствуют фильтры в предложениях WHERE. Значение этой переменной состояния следует снова рассматривать по отношению к другим обработчикам, поскольку некоторые полные сканирования индекса неизбежны.
Handler_read_key подсчитывает количество строк, прочитанных индексом. Вы хотите, чтобы значение этого обработчика было высоким по сравнению с другими обработчиками, связанными с чтением. В общем, большое число здесь означает, что ваши запросы правильно используют индексы.
Обратите внимание, что обработчики по-прежнему могут скрывать некоторые проблемы. Если запрос только читает строки с использованием индексов, но делает это неэффективно, то Select_scan не будет увеличиваться, а Handler_read_key — наш хороший обработчик чтения — будет расти, но конечным результатом все равно будет медленный запрос. Мы объясняем, как найти определенные медленные запросы в разделе «Журнал медленных запросов», но для них также есть специальный счетчик: Slow_queries. Эта переменная состояния подсчитывает запросы, выполнение которых заняло больше времени, чем значение Long_query_time, независимо от того, включен ли журнал медленных запросов. Вы можете постепенно уменьшать значение Long_query_time и смотреть, когда Slow_queries начнет приближаться к общему количеству запросов, выполняемых вашим сервером. Это хороший способ оценить, сколько запросов в вашей системе занимает, например, больше секунды, фактически не включая журнал медленных запросов, который имеет накладные расходы.
Не каждый выполняемый запрос доступен только для чтения, и MySQL также подсчитывает количество строк, вставленных, обновленных или удаленных, соответственно, в переменных состояния Handler_insert, Handler_update и Handler_delete. В отличие от запросов SELECT, здесь трудно делать выводы о качестве ваших операторов записи, основываясь только на переменных состояния. Однако вы можете отслеживать их, чтобы увидеть, например, что клиенты вашей базы данных начинают обновлять больше строк. Без изменения количества операторов UPDATE (переменные состояния Com_update и Com_update_multi), которые могут указывать на изменение параметров, передаваемых в те же запросы: более широкие диапазоны, больше элементов в предложениях IN и т. д. Это может не указывать на проблему само по себе, но его можно использовать при исследовании медлительности, чтобы увидеть, не увеличивается ли нагрузка на базу данных.
Помимо инструкций INSERT, инструкции UPDATE, DELETE и даже INSERT SELECT должны искать строки для изменения. Так, например, оператор DELETE увеличит счетчики, связанные с чтением, и может привести к неожиданной ситуации: не рост Select_scan, а увеличение значения Handler_read_rnd_next. Не забывайте об этой особенности, если видите расхождение между статусными переменными. Журнал медленных запросов будет включать операторы SELECT, а также операторы DML.
Временные объекты
Иногда при выполнении запросов MySQL необходимо создавать и использовать временные объекты, которые могут находиться в памяти или на диске. Примеры причин для создания временных объектов включают, среди прочего, использование предложения UNION, производных таблиц, общих табличных выражений и некоторых вариантов предложений ORDER BY и GROUP BY. В этой главе мы уже говорили почти обо всем этом, но временные объекты не проблема: некоторые из них неизбежны и действительно желательны. Тем не менее, они потребляют ресурсы вашего сервера: если временные таблицы достаточно малы, они будут храниться в памяти и использовать ее, а если они станут большими, MySQL начнет выгружать их на диск, как используя дисковое пространство, так и влияя на производительность.
MySQL поддерживает три переменные состояния, связанные с временными объектами, созданными во время выполнения запроса. Обратите внимание, что сюда не входят временные таблицы, созданные явно с помощью инструкции CREATE TEMPORARY TABLE; ищите их под счетчиком Com_create_table.
Created_tmp_tables подсчитывает количество временных таблиц, неявно созданных сервером MySQL при выполнении различных запросов. Вы не можете знать, почему и для каких запросов они были созданы, но здесь будет учитываться каждая таблица. При стабильной рабочей нагрузке вы должны увидеть одинаковое количество созданных временных таблиц, так как примерно одни и те же запросы выполняются одинаковое количество раз. Рост этого счетчика обычно связан с изменением запросов или их планов, например из-за роста базы данных, и может быть проблематичным. Хотя это полезно, создание временных таблиц даже в памяти требует ресурсов. Вы не можете полностью избежать временных таблиц, но вы должны проверить, почему их количество растет, выполнив, например, аудит запросов с помощью журнала медленных запросов.
Created_tmp_disk_tables подсчитывает количество временных таблиц, которые были выгружены на диск после того, как их размер превысил установленные верхние пределы для временных таблиц в памяти. В старом движке памяти ограничение контролировалось параметрами tmp_table_size или max_heap_table_size. MySQL 8.0 по умолчанию перешел на новый механизм TempTable для временных таблиц, который по умолчанию не переносится на диск так же, как таблицы памяти. Если для переменной temptable_use_mmap установлено значение по умолчанию ON, то временные таблицы TempTable не увеличивают эту переменную, даже если они записываются на диск.
Created_tmp_files подсчитывает количество временных файлов, созданных MySQL. Это отличается от переноса временных таблиц модуля памяти на диск, но будет учитывать записи таблиц TempTable на диск. Мы понимаем, что это может показаться сложным, и это действительно так, но серьезные изменения обычно не обходятся без некоторых недостатков.
Какую бы конфигурацию вы ни использовали, важен размер временных таблиц, а также отслеживание скорости их создания и утечки. Если рабочая нагрузка создает большое количество временных таблиц размером примерно 32 МБ, но верхний предел для таблиц в памяти составляет 16 МБ, то сервер увидит повышенную скорость ввода-вывода из-за того, что эти таблицы записываются на диск и считываются обратно с диска. Это нормально для сервера с ограниченным объемом памяти, но это пустая трата времени, если у вас есть доступная память. И наоборот, установка слишком высокого верхнего предела может привести к переключению сервера или полному сбою, как описано в разделе «Память».
Мы видели, как серверы останавливались из-за всплесков памяти, когда множество одновременно открытых подключений выполняли запросы, требующие временных таблиц. Мы также встречали серверы, на которых большая часть нагрузки ввода-вывода создавалась временными таблицами, переносящимися на диск. Как и в большинстве случаев, связанных с операционными базами данных, решение о размере таблицы является балансирующим актом. Три счетчика, которые мы показали, могут помочь вам сделать осознанный выбор.
Метрики ввода-вывода и транзакций InnoDB
До сих пор мы в основном говорили об общих показателях MySQL и игнорировали тот факт, что существуют такие вещи, как транзакции и блокировки. В этом подразделе мы рассмотрим некоторые полезные показатели, предоставляемые механизмом хранения InnoDB. Некоторые из этих показателей относятся к тому, сколько данных InnoDB читает и записывает, и почему. Некоторые, однако, могут отображать важную информацию о блокировках, которую можно комбинировать со счетчиками уровня MySQL, чтобы получить четкое представление о текущей ситуации блокировок в базе данных.
Механизм хранения InnoDB предоставляет 61 переменную состояния, показывающую различную информацию о его внутреннем состоянии. Глядя на их изменение с течением времени, вы можете увидеть, насколько загружена InnoDB и какую нагрузку на ОС она производит. Учитывая, что InnoDB является механизмом хранения по умолчанию, это, вероятно, будет большей частью нагрузки, которую производит MySQL.
Возможно, нам следовало поместить их в раздел о качестве запросов, но InnoDB поддерживает свои собственные счетчики для количества прочитанных, вставленных, обновленных или удаленных строк. Переменные, соответственно, Inndb_rows_read, Inndb_rows_inserted, Inndb_rows_updated и Inndb_rows_deleted. Обычно их значения довольно хорошо соответствуют значениям соответствующих переменных Handler_%. Если вы в основном используете таблицы InnoDB, может быть проще использовать счетчики Innodb_rows_% вместо счетчиков Handler_% для отслеживания относительной нагрузки от запросов, выраженной в количестве обработанных строк.
Другие важные и полезные переменные состояния, предоставляемые InnoDB, показывают количество данных, которые механизм хранения читает и записывает. В разделе «Диск» мы увидели, как проверять и отслеживать общее использование ввода-вывода и использование операций ввода-вывода. InnoDB позволяет вам точно увидеть, почему он читает и записывает данные и сколько их:
Innodb_data_read-
Объем данных, выраженный в байтах, прочитанных с диска с момента запуска сервера. Если вы измеряете значение этой переменной с течением времени, вы можете преобразовать его в использование полосы пропускания в байтах в секунду. Эта метрика тесно связана с размером буферного пула InnoDB и его эффективностью, и мы вернемся к этому чуть позже. Можно предположить, что все эти данные считываются из файлов данных для удовлетворения запросов.
Innodb_data_writing-
Объем данных, выраженный в байтах, записанных на диск с момента запуска сервера. Это то же самое, что и
Innodb_data_read, но в другом направлении. Обычно на это значение приходится большая часть общей пропускной способности записи, которую генерирует MySQL. В отличие от чтения данных, InnoDB записывает данные в различных ситуациях; таким образом, существуют дополнительные переменные, определяющие части этого ввода-вывода, а также другие источники ввода-вывода. Innodb_os_log_writing-
Количество данных, выраженное в байтах, записанных InnoDB в свои журналы повторов. Эта сумма также включена в
Innodb_data_writing, но ее стоит отслеживать отдельно, чтобы увидеть, не нужно ли изменить размер ваших журналов повторного выполнения. Дополнительные сведения см. в разделе «Размер журнала повторов». Innodb_pages_writing-
Количество данных, выраженное в страницах (по умолчанию 16 КиБ), записанных InnoDB во время его работы. Это вторая половина переменной состояния
Innodb_data_writing. Полезно видеть количество операций ввода-вывода без повторного выполнения, которые генерирует InnoDB. Innodb_buffer_pool_pages_flushed-
Количество данных, выраженное в страницах, записанных InnoDB из-за сброса. В отличие от записей, охваченных двумя предыдущими счетчиками, записи, вызванные сбросом, не происходят сразу после выполнения фактической записи. Сброс — это сложная фоновая операция, подробности которой выходят за рамки нашей книги. Однако вы должны, по крайней мере, знать, что сбрасывание существует и что оно генерирует ввод-вывод независимо от других счетчиков.
Объединив Innodb_data_writing и Innodb_buffer_pool_pages_flushed, вы сможете получить довольно точную цифру пропускной способности диска, используемой InnoDB и MySQL Server. Добавление Innodb_data_read завершает профиль ввода-вывода InnoDB. MySQL использует не только InnoDB, а ввод-вывод может осуществляться из других частей системы, например, временные таблицы, переносимые на диск, как мы обсуждали ранее. Тем не менее, часто операции ввода-вывода InnoDB совпадают с операциями ввода-вывода MySQL Server, наблюдаемыми из операционной системы.
Одно из применений этой информации — увидеть, насколько ваш сервер MySQL близок к достижению пределов производительности вашей системы хранения. Это особенно важно в облаке, где хранилище часто имеет строгие ограничения. Во время инцидентов, связанных с производительностью базы данных, вы можете проверить счетчики, связанные с вводом-выводом, чтобы увидеть, что MySQL пишет или читает больше, возможно, указывая на увеличение нагрузки или вместо этого выполняя меньше фактических операций ввода-вывода. Последнее может означать, что MySQL в настоящее время ограничен каким-то другим ресурсом, например ЦП, или страдает от других проблем, таких как блокировка. К сожалению, уменьшение ввода-вывода также может означать, что у хранилища есть проблемы.
В InnoDB есть несколько переменных состояния, которые могут помочь найти проблемы с хранилищем или его производительностью: Innodb_data_pending_fsyncs, Innodb_data_pending_reads, Innodb_data_pending_writes, Innodb_os_log_pending_fsyncs и Innodb_os_log_pending_writes. Вы можете ожидать увидеть некоторое количество ожидающих операций чтения и записи данных, хотя, как всегда, полезно посмотреть на тенденции и предыдущие данные. Самым важным из них является Innodb_os_log_pending_fsyncs. Журналы повторов часто синхронизируются, и производительность операции синхронизации чрезвычайно важна для общей производительности и пропускной способности транзакций InnoDB.
В отличие от многих других переменных состояния, все они являются датчиками, что означает, что их значения увеличиваются и уменьшаются, а не просто увеличиваются. Вы должны попробовать эти переменные и посмотреть, как часто выполняются незавершенные операции, в частности, для синхронизации журнала повторов. Даже небольшое увеличение Innodb_os_log_pending_fsyncs может указывать на серьезные проблемы с хранилищем: либо у вас не хватает производительности, либо есть проблемы с оборудованием.
Когда мы писали о переменной Innodb_data_read, мы упомянули, что объем данных, которые читает InnoDB, связан с размером и использованием пула буферов. Давайте подробнее об этом. InnoDB кэширует страницы, считанные с диска, внутри своего буферного пула. Чем больше буферный пул, тем больше страниц будет в нем храниться и тем реже страницы придется считывать с диска. Мы говорим об этом в разделе «Размер буферного пула». Здесь, при обсуждении мониторинга, давайте посмотрим, как контролировать эффективность пула буферов. Это легко сделать с помощью всего двух переменных состояния:
Innodb_buffer_pool_read_requests-
В документации MySQL это определяется как «количество логических запросов на чтение». Проще говоря, это количество страниц, которые различные операции в InnoDB хотели прочитать из пула буферов. Обычно большая часть страниц читается из-за активности запросов.
Innodb_buffer_pool_reads-
Это количество страниц, которые InnoDB должна была прочитать с диска, чтобы удовлетворить запросы на чтение с помощью запросов или других операций. Значение этого счетчика обычно меньше или равно
Innodb_buffer_pool_read_requestsдаже в самом худшем случае с полностью пустым (или «холодным») буферным пулом, потому что чтение с диска выполняется для удовлетворения запросов на чтение.
В нормальных условиях, даже при небольшом буферном пуле, вы не получите отношения 1:1 между этими переменными. То есть можно будет удовлетворить хоть какие-то чтения из буферного пула. В идеале вы должны попытаться свести количество операций чтения с диска к минимуму. Это не всегда возможно, особенно если размер базы данных намного превышает объем памяти сервера.
Вы можете попытаться оценить коэффициент попаданий в буферный пул, и в Интернете доступны формулы. Однако сравнивать значения двух переменных не совсем корректно, как сравнивать яблоки и апельсины. Если вы считаете, что значение Innodb_buffer_pool_reads слишком велико, возможно, стоит выполнить запросы, выполняемые в системе (например, используя журнал медленных запросов), вместо того, чтобы пытаться увеличить размер пула буферов. Конечно, вы должны стараться поддерживать как можно больший буферный пул, чтобы охватить большую часть или все горячие данные в базе данных. Тем не менее, по-прежнему будут запросы, которые могут привести к большому количеству операций ввода-вывода при чтении из-за получения страниц с диска (и увеличения Innodb_buffer_pool_reads при этом), и попытка исправить их путем еще большего увеличения размера пула буферов приведет к уменьшению отдачи.
Наконец, чтобы завершить обсуждение InnoDB, мы перейдем к транзакциям и блокировкам. Много информации по обеим темам было дано в главе 6, поэтому здесь мы сделаем краткий обзор связанных переменных состояния:
- Счетчики команд, связанные с транзакциями
-
BEGIN,COMMITиROLLBACK— это специальные команды MySQL. Таким образом, MySQL подсчитает, сколько раз они были выполнены с переменными состоянияCom_%:Com_begin,Com_commitиCom_rollback. Глядя на эти счетчики, вы можете увидеть, сколько транзакций запущено явно и либо зафиксировано, либо отменено. - Переменные состояния, связанные с блокировкой
-
Вы уже знаете, что InnoDB обеспечивает блокировку с детализацией на уровне строк. Это огромное улучшение по сравнению с блокировкой на уровне таблицы MyISAM, так как влияние каждой отдельной блокировки сведено к минимуму. Тем не менее, может быть влияние, если транзакции ждут друг друга даже в течение короткого времени.
InnoDB предоставляет переменные состояния, которые позволяют вам видеть, сколько блокировок создается, и дают вам подробную информацию об ожиданиях блокировок, которые происходят:
Innodb_row_lock_current_waitsпоказывает, сколько транзакций, работающих с таблицами InnoDB, в настоящее время ожидают снятия блокировки некоторыми другими транзакциями. Значение этой переменной увеличивается с нуля при наличии заблокированных сеансов, а затем возвращается к нулю, как только блокировка разрешается.Innodb_row_lock_waitsпоказывает, сколько раз с момента запуска сервера транзакции в таблицах InnoDB ожидали блокировок на уровне строк. Эта переменная является счетчиком и будет постоянно увеличиваться, пока MySQL Server не будет перезапущен.Innodb_row_lock_timeпоказывает общее время в миллисекундах, затраченное сеансами на попытки установить блокировки для таблиц InnoDB.Innodb_row_lock_time_avgпоказывает среднее время в миллисекундах, которое требуется сеансу для получения блокировки на уровне строки в таблице InnoDB. Вы можете получить такое же значение, разделивInnodb_row_lock_timeнаInnodb_row_lock_waits. Это значение может увеличиваться и уменьшаться в зависимости от того, сколько ожиданий блокировки встречается и насколько увеличивается накопленное время блокировки.Innodb_row_lock_time_maxпоказывает максимальное время в миллисекундах, которое потребовалось для получения блокировки таблицы InnoDB. Это значение будет увеличиваться только в том случае, если рекорд будет побит какой-либо другой неудачной транзакцией.Вот пример сервера MySQL с умеренной нагрузкой на чтение/запись:
mysql> SHOW GLOBAL STATUS LIKE 'Innodb_row_lock%'; +-------------------------------+--------+ | Variable_name | Value | +-------------------------------+--------+ | Innodb_row_lock_current_waits | 0 | | Innodb_row_lock_time | 367465 | | Innodb_row_lock_time_avg | 165 | | Innodb_row_lock_time_max | 51056 | | Innodb_row_lock_waits | 2226 | +-------------------------------+--------+ 5 rows in set (0.00 sec)Было 2 226 отдельных транзакций, ожидающих блокировок, и для получения всех этих блокировок потребовалось 367 465 миллисекунд, при этом средняя продолжительность получения блокировки составила 165 миллисекунд, а максимальная — чуть более 51 секунды. В настоящее время нет сеансов, ожидающих блокировки. Сама по себе эта информация мало что нам говорит: ни много, ни мало. Однако мы знаем, что одновременно этим сервером MySQL было выполнено более 100 000 транзакций. Результирующие значения метрик блокировки более чем разумны для уровня параллелизма.
Проблемы с блокировкой являются частым источником головной боли как для администраторов баз данных, так и для разработчиков приложений. Хотя эти метрики, как и все, что мы обсуждали до сих пор, агрегируются для каждого запущенного сеанса, отклонение от нормальных значений может помочь вам выявить некоторые проблемы. Чтобы найти и исследовать отдельные ситуации блокировки, вы можете использовать отчет о состоянии InnoDB; см. «Отчет о состоянии InnoDB Engine» для получения более подробной информации.
Журнал медленных запросов
В разделе «Типы запросов и их качество» мы показали, как искать явные признаки неоптимизированных запросов в MySQL. Однако этого недостаточно, чтобы начать оптимизировать эти запросы. Нужны конкретные примеры. Есть несколько способов сделать это, но, вероятно, самый надежный из них — использование журнала медленных запросов. Журнал медленных запросов — это именно то, на что он похож: специальный текстовый журнал, в который MySQL помещает информацию о медленных запросах. Насколько медленными должны быть эти запросы, можно контролировать, и вы можете вести журнал каждого запроса.
Чтобы включить журнал медленных запросов, вы должны изменить настройку системной переменной slow_query_log на ON вместо значения по умолчанию OFF. По умолчанию, когда журнал медленных запросов включен, MySQL будет регистрировать запросы, занимающие более 10 секунд. Это можно настроить, изменив переменную long_query_time, которая имеет минимальное значение 0, что означает, что каждый запрос, выполненный сервером, будет регистрироваться. Расположение журнала контролируется переменной slow_query_log_file, которая по умолчанию имеет значение hostname-slow.log. Если путь к журналу медленных запросов относительный, то есть он не начинается с / в Linux или, например, C:\ в Windows, то этот файл будет находиться в каталоге данных MySQL.
Вы также можете указать MySQL регистрировать запросы, не используя индексы, независимо от времени их выполнения. Для этого необходимо установить для переменной log_queries_not_using_indexes значение ON. По умолчанию DDL и административные операторы не регистрируются, но это поведение можно изменить, задав для log_slow_admin_statements значение ON.
MariaDB и Percona Server расширяют функциональность журнала медленных запросов, добавляя возможности фильтрации, ограничения скорости и расширенной детализации. Если вы используете эти продукты, стоит прочитать их документацию по этому вопросу, чтобы узнать, можете ли вы использовать расширенный журнал медленных запросов.
Вот пример из записи в журнале медленных запросов, показывающий, что оператор SELECT занимает больше времени, чем настроенное значение long_query_time, равное 1 секунде:
# Time: 2021-05-29T17:21:12.433992Z
# User@Host: root[root] @ localhost [] Id: 11
# Query_time: 1.877495 Lock_time: 0.000823 Rows_sent: 9 Rows_examined: 3473725
use employees;
SET timestamp=1622308870;
SELECT
dpt.dept_name
, emp.emp_no
, emp.first_name
, emp.last_name
, sal.salary
FROM
departments dpt
JOIN dept_emp ON dpt.dept_no = dept_emp.dept_no
JOIN employees emp ON dept_emp.emp_no = emp.emp_no
JOIN salaries sal ON emp.emp_no = sal.emp_no
JOIN (SELECT dept_emp.dept_no, MAX(sal.salary) maxsal
FROM dept_emp JOIN salaries sal
ON dept_emp.emp_no = sal.emp_no
WHERE
sal.from_date < now()
AND sal.to_date > now()
GROUP BY dept_no
) largest_sal_by_dept ON dept_emp.dept_no = largest_sal_by_dept.dept_no
AND sal.salary = largest_sal_by_dept.maxsal;
Проанализировав этот вывод, вы можете сразу начать делать выводы по этому запросу. Это гораздо более информативно, чем просмотр метрик на уровне сервера. Например, мы можем видеть, что этот запрос был выполнен в 17:21:12 UTC пользователем root@localhost в базе данных employees, выполнялся 1,88 секунды и выдал 9 строк, но для получения этого результата пришлось отсканировать 3 473 725 строк. Эта информация сама по себе может многое рассказать вам о запросе, особенно если у вас уже есть опыт работы с MySQL. Теперь у вас также есть полный текст запроса, который вы можете превратить в информацию о плане выполнения, чтобы точно увидеть, как MySQL выполняет этот запрос. Вы можете найти более подробную информацию об этом процессе в разделе «Оператор EXPLAIN».
Если для параметра long_query_time задано низкое значение, журнал медленных запросов может стать большим. Иногда это может быть разумно, но чтение результирующего журнала может быть почти невозможным, если количество запросов велико. Есть инструмент под названием mysqldumpslow, который решает эту проблему. В качестве аргумента он принимает путь к файлу журнала медленных запросов, суммирует запросы из этого файла и сортирует их (по умолчанию по времени). В следующем примере команда запускается таким образом, что она покажет два самых популярных запроса, отсортированных по количеству возвращенных строк:
$ mysqldumpslow -s r -t 2 /var/lib/mysql/mysqldb1-slow.log
Reading mysql slow query log from /var/lib/mysql/mysqldb1-slow.log
Count: 2805 Time=0.00s (0s) Lock=0.00s (0s) Rows=100.0 (280500), sbuser[
sbuser]@localhost
SELECT c FROM sbtest1 WHERE id BETWEEN N AND N
Count: 2760 Time=0.00s (0s) Lock=0.00s (0s) Rows=100.0 (276000), sbuser[
sbuser]@localhost
SELECT c FROM sbtest1 WHERE id BETWEEN N AND N ORDER BY c
Вы можете видеть, что только эти два запроса были зарегистрированы в журнале медленных запросов 5565 раз. Представьте, что вы пытаетесь получить эту информацию без посторонней помощи! Другой инструмент, который может помочь в обобщении информации в журнале медленных запросов, — это pt-query-digest из Percona Toolkit. Инструмент немного более продвинутый и более сложный в использовании, чем mysqldumpslow, но дает много информации и имеет множество функций. Отчет, который он производит, начинается с резюме:
$ pt-query-digest /var/lib/mysql/mysqldb1-slow.log
# 7.4s user time, 60ms system time, 41.96M rss, 258.35M vsz
# Current date: Sat May 29 22:36:47 2021
# Hostname: mysqldb1
# Files: /var/lib/mysql/mysqldb1-slow.log
# Overall: 109.42k total, 15 unique, 7.29k QPS, 1.18x concurrency ________
# Time range: 2021-05-29T19:28:57 to 2021-05-29T19:29:12
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 18s 1us 10ms 161us 1ms 462us 36us
# Lock time 2s 0 7ms 16us 14us 106us 5us
# Rows sent 1.62M 0 100 15.54 97.36 34.53 0.99
# Rows examine 3.20M 0 200 30.63 192.76 61.50 0.99
# Query size 5.84M 5 245 55.93 151.03 50.37 36.69
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============= ===== ====== ====
# 1 0xFFFCA4D67EA0A78… 11.1853 63.1% 5467 0.0020 0.00 COMMIT
# 2 0xB2249CB854EE3C2… 1.5985 9.0% 5467 0.0003 0.00 UPDATE sbtest?
# 3 0xE81D0B3DB4FB31B… 1.5600 8.8% 54670 0.0000 0.00 SELECT sbtest?
# 4 0xF0C5AE75A52E847… 0.8853 5.0% 5467 0.0002 0.00 SELECT sbtest?
# 5 0x9934EF6887CC7A6… 0.5959 3.4% 5467 0.0001 0.00 SELECT sbtest?
# 6 0xA729E7889F57828… 0.4748 2.7% 5467 0.0001 0.00 SELECT sbtest?
# 7 0xFF7C69F51BBD3A7… 0.4511 2.5% 5467 0.0001 0.00 SELECT sbtest?
# 8 0x6C545CFB5536512… 0.3092 1.7% 5467 0.0001 0.00 INSERT sbtest?
# MISC 0xMISC 0.6629 3.7% 16482 0.0000 0.0 <7 ITEMS>
Затем каждый запрос резюмируется следующим образом:
# Query 2: 546.70 QPS, 0.16x concurrency, ID 0xB2249CB854E... at byte 1436377
# Scores: V/M = 0.00
# Time range: 2021-05-29T19:29:02 to 2021-05-29T19:29:12
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 4 5467
# Exec time 9 2s 54us 7ms 292us 1ms 446us 93us
# Lock time 61 1s 7us 7ms 203us 1ms 437us 9us
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 0 5.34k 1 1 1 1 0 1
# Query size 3 213.55k 40 40 40 40 0 40
# String:
# Databases sysbench
# Hosts localhost
# Users sbuser
# Query_time distribution
# 1us
# 10us ################################################################
# 100us ###############################################
# 1ms ############
# 10ms
# 100ms
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sysbench` LIKE 'sbtest2'\G
# SHOW CREATE TABLE `sysbench`.`sbtest2`\G
UPDATE sbtest2 SET k=k+1 WHERE id=497658\G
# Converted for EXPLAIN
# EXPLAIN /*!50100 PARTITIONS*/
select k=k+1 from sbtest2 where id=497658\G
Это много ценной информации в плотном формате. Одной из отличительных особенностей этого вывода является визуализация распределения длительности запроса, которая позволяет быстро увидеть, есть ли в запросе проблемы с производительностью, зависящие от параметров. Объяснение каждой функции pt-query-digest заняло бы отдельную главу, а это продвинутый инструмент, поэтому мы оставляем его вам, чтобы вы попробовали его, как только закончите изучение MySQL.
Журнал медленных запросов — это мощный инструмент, позволяющий получить очень подробное представление о запросах, выполняемых сервером MySQL. Мы рекомендуем использовать журнал медленных запросов следующим образом:
-
Установите для
long_query_timeзначение, достаточно большое, чтобы оно покрывало большинство запросов, обычно выполняемых в вашей системе, но достаточно малое, чтобы вы могли уловить резко отличающиеся значения. Например, в системе OLTP, где ожидается, что большинство запросов будут выполняться за миллисекунды, может быть разумным значение0.5, поскольку оно позволяет перехватывать только относительно медленные запросы. С другой стороны, если в вашей системе запросы выполняются в минутах, тоlong_query_timeследует установить соответствующим образом. -
Регистрация в журнале медленных запросов снижает производительность, и вам следует избегать регистрации большего количества запросов, чем вам нужно. Если у вас включен журнал медленных запросов, убедитесь, что вы изменили параметр
long_query_time, если считаете журнал слишком зашумленным. -
Иногда вам может понадобиться выполнить «аудит запросов», когда вы временно (на несколько минут) устанавливаете для
long_query_timeзначение0, чтобы перехватывать каждый запрос. Это хороший способ получить моментальный снимок загрузки вашей базы данных. Такие снимки можно сохранить и сравнить позже. Однако мы настоятельно не рекомендуем устанавливать слишком маленькое значение для параметраlong_query_time. -
Если у вас настроен журнал медленных запросов, мы рекомендуем периодически запускать на нем
mysqldumpslow,pt-query-digestили аналогичный инструмент, чтобы отслеживать, появляются ли новые запросы или существующие начинают вести себя хуже, чем обычно.
Отчет о состоянии ядра InnoDB
Механизм хранения InnoDB имеет встроенный отчет, в котором представлены подробные технические сведения о текущем состоянии механизма. Можно многое сказать о нагрузке и производительности InnoDB, прочитав только один этот отчет, в идеале выбранный за определенный период времени. Чтение отчета о состоянии InnoDB — сложная тема, требующая большего количества инструкций, чем мы можем передать в нашей книге, а также большой практики. Тем не менее, мы считаем, что вы должны знать, что этот отчет существует, и мы дадим вам несколько советов, что в нем искать.
Для просмотра отчета нужно выполнить всего одну команду. Мы рекомендуем использовать вертикальное отображение результатов:
mysql> SHOW ENGINE INNODB STATUS\G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2021-05-31 12:21:05 139908633830976 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 35 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 121 srv_active, 0 srv_shutdown, 69961 srv_idle
...
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
2 read views open inside InnoDB
Process ID=55171, Main thread ID=139908126139968 , state=sleeping
Number of rows inserted 2946375, updated 87845, deleted 46063, read 88688110
572.50 inserts/s, 1145.00 updates/s, 572.50 deletes/s, 236429.64 reads/s
Number of system rows inserted 109, updated 367, deleted 60, read 13218
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
Вывод, который мы здесь усекли, представлен разбитым на разделы. Сначала это может показаться пугающим, но со временем вы начнете ценить детали. А пока мы рассмотрим несколько разделов, которые, по нашему мнению, содержат информацию, которая будет полезна операторам любого уровня опыта:
- Транзакции
-
В этом разделе представлена информация о транзакциях каждого сеанса, включая продолжительность, текущий запрос, количество удерживаемых блокировок и информацию об ожидании блокировок. Вы также можете найти здесь некоторые данные о видимости транзакций, но это редко требуется. Обычно вы хотите просмотреть раздел транзакций, чтобы увидеть текущее состояние активных транзакций в InnoDB. Пример записи из этого раздела выглядит так:
---TRANSACTION 252288, ACTIVE (PREPARED) 0 sec 5 lock struct(s), heap size 1136, 3 row lock(s), undo log entries 4 MySQL thread id 82, OS thread handle 139908634125888,... ...query id 925076 localhost sbuser waiting for handler commit COMMIT Trx read view will not see trx with id >= 252287, sees < 252285В записи говорится о том, что транзакция в настоящее время ожидает завершения
COMMIT, она содержит три блокировки строк и выполняется довольно быстро, вероятно, завершится менее чем за секунду. Иногда вы увидите здесь длинные транзакции: вы должны стараться избегать их. InnoDB плохо обрабатывает длинные транзакции, и даже бездействующая транзакция, остающаяся открытой слишком долго, может повлиять на производительность.Этот раздел также покажет вам информацию о текущем поведении блокировки, если есть транзакции, ожидающие получения блокировки. Вот пример:
---TRANSACTION 414311, ACTIVE 4 sec starting index read mysql tables in use 1, locked 1 LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s) MySQL thread id 84, OS thread handle 139908634125888,... ...query id 2545483 localhost sbuser updating UPDATE sbtest1 SET k=k+1 WHERE id=347110 Trx read view will not see trx with id >= 414310, sees < 413897 ------- TRX HAS BEEN WAITING 4 SEC FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 333 page no 4787 n bits 144 index PRIMARY of... ...table `sysbench`.`sbtest1` trx id 414311 lock_mode X locks... ...rec but not gap waiting Record lock, heap no 33 ------------------К сожалению, отчет о состоянии не указывает напрямую на владельца блокировки, поэтому вам придется искать блокирующие транзакции отдельно. Некоторая информация об этом доступна в главе 6. Обычно, если вы видите одну активную транзакцию, в то время как другие ждут, это хороший признак того, что именно эта активная транзакция удерживает блокировки.
- Файловый ввод/вывод
-
Этот раздел содержит информацию о текущих операциях ввода-вывода, а также агрегированные сводки по времени. Мы обсуждали это более подробно в разделе «Метрики ввода-вывода и транзакций InnoDB», но это дополнительный способ проверки наличия в InnoDB ожидающих операций с данными и журналами.
- Буферный пул и память
-
В этом разделе InnoDB выводит информацию о своем пуле буферов и использовании памяти. Если у вас настроено несколько экземпляров пула буферов, в этом разделе будут показаны как итоговые значения, так и разбивка по экземплярам. В разделе много информации, в том числе о размере пула буферов и внутреннем состоянии пула буферов:
Total large memory allocated 274071552 Dictionary memory allocated 1377188 Buffer pool size 16384 Free buffers 1027 Database pages 14657 Old database pages 5390 Modified db pages 4168Эти параметры также представлены как переменные
Innodb_buffer_pool_%. - Семафоры
-
Этот раздел включает информацию о внутренних семафорах InnoDB или примитивах синхронизации. Проще говоря, семафоры — это специальные внутренние структуры в памяти, которые позволяют нескольким потокам работать, не мешая друг другу. Вы редко увидите что-либо ценное в этом разделе, если только в вашей системе нет конкуренции за семафоры. Обычно это происходит, когда InnoDB подвергается экстремальной нагрузке, поэтому каждая операция занимает больше времени, и есть больше шансов увидеть активное ожидание семафора в выводе состояния.
Методы исследования
Наличие такого количества доступных метрик, которые необходимо отслеживать, проверять и понимать, может привести к тому, что у вас закружится голова. Вы можете заметить, что мы не определили ни одной метрики с определенным диапазоном от хорошего до плохого. Блокировка плохая? Может быть, но это также ожидаемо и нормально. То же самое можно сказать почти о каждом аспекте MySQL, за исключением доступности сервера.
Эта проблема не уникальна для мониторинга серверов MySQL, она характерна для любой сложной системы. Много метрик, сложных зависимостей и почти нет строго определяемых правил, хорошо что-то или плохо. Чтобы решить эту проблему, нам нужен какой-то подход, какая-то методология, которую мы можем применить к большому количеству данных, чтобы быстро и легко делать выводы о текущей производительности системы.
К счастью, такие методики уже существуют. В этом разделе мы кратко опишем две из них и дадим идеи о том, как их применять для мониторинга метрик MySQL и ОС.
Метод USE
Метод Utilization, Saturation, Errors (USE), популяризированный Бренданом Греггом, представляет собой методологию общего назначения, которую можно применять к любой системе. Хотя он лучше подходит для ресурсов с четко определенными характеристиками производительности, такими как ЦП или диск, его также можно применять к некоторым частям MySQL.
Метод USE лучше всего использовать, создав контрольный список для каждой отдельной части системы. Во-первых, нам нужно определить, какие показатели использовать для измерения использования, насыщения и ошибок. Некоторые примеры контрольных списков для Linux можно найти на домашней странице USE: веб-сайт Грегга.
Давайте рассмотрим три разные категории на примере дискового ввода-вывода:
- Использование (Utilization)
-
Для дисковой подсистемы, как мы изложили в разделе «Диск», мы можем посмотреть метрики для любого из этих параметров:
Общее использование пропускной способности хранилища
Использование пропускной способности хранилища для каждого процесса
Текущий IOPS (где известен верхний предел IOPS для устройства)
- Насыщение (Saturation)
-
Мы упомянули насыщение, когда говорили о выводе
iostatи метриках диска. Это показатель объема работы, который ресурс не может обработать и который обычно ставится в очередь. Для диска это выражается как размер очереди запросов ввода-вывода (avgqu-szв выводеiostat). В большинстве систем значения >1 означают, что диск переполнен, и, таким образом, некоторые запросы будут поставлены в очередь и будут тратить время на бездействие. - Ошибки (Errors)
-
Для дисковых устройств это может означать ошибки ввода-вывода из-за деградации оборудования.
Проблема с методом USE заключается в том, что его трудно применить к сложной системе в целом. Возьмем, к примеру, MySQL: какие показатели мы могли бы использовать для измерения общего использования, насыщения и ошибок? Можно предпринять некоторые попытки применить USE к MySQL в целом, но он гораздо лучше подходит для использования в некоторых изолированных частях системы.
Давайте взглянем на некоторые возможные приложения MySQL:
- Метод USE для клиентских подключений
-
Метод USE хорошо подходит для понимания метрик подключения клиента, которые мы обсуждали в разделе «Основные рецепты мониторинга».
Метрики использования включают
Threads_connectedиThreads_running.Насыщение может быть определено произвольно на основе
Threads_running. Например, в системе OLTP, которая преимущественно ориентирована на чтение и не генерирует много операций ввода-вывода, точка насыщения дляThreads_running, скорее всего, будет примерно равна количеству доступных ядер ЦП. В системе, которая в основном связана с вводом-выводом, отправной точкой может быть удвоенное количество доступных ядер ЦП, но гораздо лучше определить, какое количество одновременно работающих потоков начинает насыщать подсистему хранения.Ошибки измеряются метриками
Aborted_clientsиAborted_connects. Как только значение переменной состоянияThreads_connectedстанет равным значению системной переменнойmax_connections, запросы на создание новых соединений будут отклонены, а клиенты получат ошибки. Соединения также могут не работать по другим причинам, и существующие клиенты могут нечисто завершать свои соединения, не дожидаясь ответа MySQL. - Метод USE для транзакций и блокировки
-
Другой пример того, как можно применять USE, — это просмотр показателей, связанных с блокировкой InnoDB, относительно количества запросов, обработанных системой.
Использование можно измерить с помощью синтетической метрики QPS, которую мы определили ранее.
Насыщение может быть связано с тем, что происходит некоторое количество ожиданий блокировки. Помните, что по определению USE насыщение — это мера работы, которая не может быть выполнена и должна ждать в очереди. Здесь нет очереди, но транзакции ждут получения блокировки. В качестве альтернативы обычное количество ожиданий блокировки можно умножить вдвое, чтобы создать произвольный порог, или, что еще лучше, можно провести некоторые эксперименты, чтобы найти количество ожиданий блокировки относительно количества запросов в секунду, которые приводят к тайм-аутам блокировки.
Ошибки могут быть измерены как количество раз, когда сеансы ожидали блокировок по тайм-ауту или были прекращены для разрешения ситуации взаимоблокировки. В отличие от ранее упомянутых метрик, эти две метрики не отображаются как глобальные переменные состояния, а вместо этого могут быть найдены в таблице
information_schema.innodb_metricsв разделахlock_deadlocks(количество зарегистрированных взаимоблокировок) иlock_timeouts(количество времени ожидания блокировки).
Определить частоту ошибок только на основе показателей мониторинга может быть сложно, поэтому часто используется только часть US в USE. Как видите, этот метод позволяет нам взглянуть на систему с предопределенной точки зрения. Вместо того, чтобы анализировать все возможные показатели при возникновении инцидента, можно просмотреть существующий контрольный список, что сэкономит время и усилия.
Метод RED
Метод Rate, Errors, Duration (RED) был создан для устранения недостатков USE. Методология аналогична, но ее проще применять к сложным системам и службам.
Логическое применение RED к MySQL выполняется с учетом производительности запросов:
- Скорость (Rate)
-
QPS базы данных
- Ошибки (Errors)
-
Количество или частота ошибок и неудачных запросов
- Продолжительность (Duration)
-
Средняя задержка запроса
Одна проблема с RED в контексте этой книги и изучения MySQL в целом заключается в том, что применение этого метода требует мониторинга данных, который нельзя получить, просто прочитав переменные состояния. Не каждое существующее решение для мониторинга MySQL также может предоставить необходимые данные, хотя вы можете увидеть пример того, как это делается, в блоге Петра Зайцева RED Method for MySQL Performance Analyses. Одним из способов применения RED к MySQL или любой другой системе баз данных является просмотр метрик со стороны приложения, а не со стороны базы данных. Несколько решений для мониторинга позволяют вам (вручную или автоматически) использовать ваши приложения для сбора данных, таких как количество запросов, частота сбоев и задержка запросов. Как раз то, что нужно для RED!
Вы можете и должны использовать RED и USE вместе. В статье, объясняющей RED, The RED Method: How to Instrument Your Services, ее автор Том Уилки упоминает, что «на самом деле это просто два разных взгляда на одну и ту же систему».
Одно, возможно, неожиданное преимущество применения RED, USE или любого другого метода заключается в том, что вы делаете это до того, как произойдет инцидент. Таким образом, вы вынуждены понимать, что именно вы отслеживаете и измеряете, и как это соотносится с тем, что действительно важно для вашей системы и ее пользователей.
Инструменты мониторинга MySQL
На протяжении всей этой главы мы говорили о метриках и методологиях мониторинга, но не упомянули ни одного реального инструмента, который мог бы превратить эти метрики в информационные панели или оповещения. Другими словами, мы не говорили о реальных инструментах и системах мониторинга. Первая причина этого достаточно проста: мы считаем, что в начале для вас гораздо важнее знать, что отслеживать и почему, а не как. Если бы мы сосредоточились на том, как, мы могли бы посвятить всю эту главу особенностям и различиям различных инструментов мониторинга. Вторая причина заключается в том, что метрики MySQL и ОС меняются нечасто, но если вы читаете эту книгу в 2025 году, наш выбор инструментов мониторинга уже может показаться устаревшим.
Тем не менее, в качестве отправной точки мы составили список известных популярных инструментов мониторинга с открытым исходным кодом, которые можно использовать для мониторинга доступности и производительности MySQL. Мы не будем слишком углубляться в особенности их настройки или конфигурации или сравнивать их. Мы также не можем перечислить все возможные доступные решения для мониторинга: краткое исследование показывает нам, что почти все, что является «инструментом мониторинга» или «системой мониторинга», может каким-то образом отслеживать MySQL. Мы также не рассматриваем не-открытые и несвободные решения для мониторинга, за одним исключением Oracle Enterprise Monitor. Мы ничего не имеем против таких систем в целом, и многие из них замечательны. Тем не менее, большинство из них имеют отличную документацию и доступную поддержку, поэтому вы сможете быстро с ними ознакомиться.
Здесь будут упомянуты следующие системы мониторинга:
Prometheus
InfluxDB и стек TICK
Zabbix
Nagios Core
Percona Monitoring and Management
Oracle Enterprise Monitor
Мы начнем с Prometheus и InfluxDB и его стека TICK. Обе эти системы представляют собой современный подход к мониторингу, они хорошо подходят для мониторинга микросервисов и обширных облачных развертываний, но также широко используются в качестве решений для мониторинга общего назначения:
- Prometheus
-
Созданная на основе внутренней системы мониторинга Google Borgmon, Prometheus является чрезвычайно популярной системой мониторинга и оповещения общего назначения. В его основе лежит база данных временных рядов и механизм сбора данных, основанный на pull-модели. Это означает, что именно сервер Prometheus активно собирает данные со своих целей мониторинга.
Фактический сбор данных с целей Prometheus осуществляется специальными программами, называемыми экспортерами. Экспортеры созданы специально: есть специальный экспортер MySQL, экспортер PostgreSQL, базовый экспортер метрик/узлов ОС и многие другие. Эти программы собирают метрики из системы, для мониторинга которой они написаны, и представляют эти метрики в формате, пригодном для использования сервером Prometheus.
Мониторинг MySQL с помощью Prometheus осуществляется запуском программы
mysqld_exporter. Как и большинство частей экосистемы Prometheus, она написана на Go и доступна для Linux, Windows и многих других операционных системах, что делает ее хорошим выбором для гетерогенной среды.Экспортер MySQL собирает все метрики, которые мы рассмотрели в этой главе (и многие другие!), и, поскольку он активно пытается получить информацию от MySQL, он также может сообщать о доступности сервера MySQL. Помимо стандартных метрик, можно задавать пользовательские запросы, которые будет выполнять экспортер, превращая их результаты в дополнительные метрики.
Prometheus предлагает только самые базовые возможности визуализации, поэтому в настройку обычно добавляется веб-приложение для аналитики и визуализации данных Grafana.
- InfluxDB и стек TICK
-
Созданная на основе базы данных временных рядов InfluxDB, TICK, обозначающая Telegraf, InfluxDB, Chronograf и Kapacitor, представляет собой полную платформу временных рядов и мониторинга. Сравнивая эту систему с Prometheus, Telegraf занимает место экспортеров; это единая программа, способная отслеживать множество целей. В отличие от экспортеров, Telegraf активно отправляет данные в InfluxDB вместо того, чтобы данные извлекались сервером. Chronograf — это административный интерфейс и интерфейс данных. Kapacitor — это механизм обработки данных и оповещения.
Там, где вам нужно было установить специальный экспортер для MySQL, Telegraf расширяется с помощью плагинов. Плагин MySQL является частью стандартного пакета и предоставляет подробный обзор показателей базы данных MySQL. К сожалению, он не может выполнять произвольные запросы, поэтому возможности расширения ограничены. В качестве обходного пути можно использовать плагин
exec. Telegraf также является мультиплатформенной программой и среди других ОС поддерживает Windows.Стек TICK часто используется частично, а Grafana добавляется в InfluxDB и Telegraf.
Общим для Prometheus и TICK является то, что они представляют собой наборы строительных блоков, позволяющих вам создать собственное решение для мониторинга. Ни один из них не предлагает готовых рецептов для информационных панелей, предупреждений и т. д. Они мощные, но могут потребовать некоторого привыкания. Кроме того, они очень ориентированы на автоматизацию и инфраструктуру как код. Prometheus особенно, но TICK также предоставляет минимальный графический интерфейс и изначально не был задуман для исследования и визуализации данных. Это мониторинг, реагирующий на изменения значений метрик путем оповещения, а не визуальной проверки различных метрик. Добавление Grafana к уравнению, особенно с самодельными панелями управления или инструментальными панелями сообщества для MySQL, делает возможным визуальный контроль. Тем не менее, большая часть конфигурации и настройки не будет выполняться в графическом интерфейсе.
Обе эти системы приобрели популярность в середине и конце 2010-х годов, когда произошел переход к использованию множества небольших серверов вместо нескольких крупных. Этот сдвиг потребовал некоторых изменений в подходах к мониторингу, и эти системы стали практически стандартными решениями для мониторинга де-факто для многих компаний.
Далее в нашем обзоре еще пара «олдскульных» решений для мониторинга:
- Zabbix
-
Zabbix — полностью бесплатная система мониторинга с открытым исходным кодом, впервые выпущенная в 2001 году, является проверенной и мощной. Zabbix поддерживает широкий спектр отслеживаемых целей и расширенные возможности автоматического обнаружения и оповещения.
Мониторинг MySQL с помощью Zabbix можно выполнять с помощью плагинов или официальных шаблонов MySQL. Покрытие метрик довольно хорошее, и каждый рецепт, который мы определили, доступен. Однако и
mysqld_exporter, и Telegraf предлагают больше данных. Стандартных метрик MySQL, которые собирает Zabbix, достаточно для настройки базового мониторинга MySQL, но для более глубокого понимания вам потребуется настроить или использовать некоторые шаблоны и плагины сообщества.Агент Zabbix является кроссплатформенным, поэтому вы можете отслеживать работу MySQL практически на любой ОС.
Хотя Zabbix предлагает довольно мощные оповещения, его возможности визуализации могут показаться немного устаревшими. Можно настроить пользовательские информационные панели на основе данных MySQL, а также можно использовать Zabbix в качестве источника данных для Grafana.
Zabbix полностью настраивается через графический интерфейс. Коммерческое предложение включает различные уровни поддержки и консультаций.
- Nagios Core
-
Как и Zabbix, Nagios — система мониторинга ветеранов, первый выпуск которой увидел свет в 2002 году. В отличие от других систем, которые мы видели до сих пор, Nagios — это система «open core». Дистрибутив Nagios Core бесплатный и с открытым исходным кодом, но есть и коммерческая система Nagios.
Мониторинг MySQL настраивается с помощью плагинов. Они должны предоставлять достаточно данных для настройки базового мониторинга, аналогичного официальным шаблонам Zabbix. При необходимости можно расширить собранные метрики.
Оповещения, визуализации и настройка аналогичны Zabbix. Одной из примечательных особенностей Nagios является то, что на пике популярности он многократно разветвлялся. Одними из самых популярных вилок Nagios являются Icinga и Shinken. Check_MK также изначально был расширением Nagios, которое в конечном итоге стало самостоятельным коммерческим продуктом.
И Nagios, и его ответвления, и Zabbix могут и успешно используются многими компаниями для мониторинга MySQL. Несмотря на то, что они могут показаться устаревшими в своей архитектуре и представлении данных, они могут выполнять свою работу. Их самая большая проблема заключается в том, что стандартные данные, которые они собирают, могут показаться ограниченными по сравнению с альтернативными, и вам нужно будет использовать плагины и расширения сообщества. Раньше Percona поддерживала набор плагинов мониторинга для Nagios, а также для Zabbix, но отказалась от них и теперь сосредоточилась на своем собственном предложении мониторинга, Percona Monitoring and Management (PMM), которое мы вскоре обсудим.
Все рассмотренные нами системы имеют одну общую черту: они представляют собой решения для мониторинга общего назначения, а не специально предназначенные для мониторинга баз данных. Это их сила, но и их слабость. Когда дело доходит до мониторинга и исследования глубоких внутренних баз данных, вам часто приходится вручную расширять возможности этих систем. Например, одной функцией, которой нет ни у одного из них, является сохранение статистики выполнения отдельных запросов. Технически добавить эту функцию можно, но это может быть громоздко и проблематично.
Мы закончим этот раздел рассмотрением двух ориентированных на базы данных решений для мониторинга: MySQL Enterprise Monitor от Oracle и Percona Monitoring and Management. Как вы увидите, они похожи по функциональности, которую они предоставляют, и обе они являются большими улучшениями по сравнению с неспециализированными системами мониторинга:
- MySQL Enterprise Monitor
-
Являясь частью MySQL Enterprise Edition, Enterprise Monitor представляет собой полную платформу мониторинга и управления базами данных MySQL.
С точки зрения мониторинга, MySQL Enterprise Monitor расширяет обычные метрики, собираемые системами мониторинга, добавляя сведения об использовании памяти MySQL, сведения о вводе-выводе для каждого файла и широкий спектр информационных панелей, основанных на переменных состояния InnoDB. Данные берутся из самой MySQL без участия каких-либо агентов. Теоретически все те же данные можно собрать и визуализировать любой другой системой мониторинга, но здесь они плотно забиты продуманными дашбордами и категориями.
Enterprise Monitor включает в себя подсистему событий, которая представляет собой набор предопределенных предупреждений. В дополнение к функциям, специфичным для базы данных, Enterprise Monitor включает обзор топологии репликации для обычной репликации и репликации с несколькими источниками, групповой репликации и кластера NDB. Еще одна функция — мониторинг состояния выполнения резервного копирования (для резервных копий, сделанных с помощью MySQL Enterprise Backup).
Мы упоминали, что статистика выполнения отдельных запросов и история запросов обычно отсутствуют в системах мониторинга общего назначения. MySQL Enterprise Monitor включает в себя анализатор запросов, который позволяет получить представление об истории запросов, выполненных с течением времени, а также о собранной статистике по запросам. Можно просматривать такую информацию, как среднее количество прочитанных и возвращенных строк и распределение продолжительности, и даже просматривать планы выполнения запросов.
Enterprise Monitor — хорошая система мониторинга баз данных. На самом деле его самым большим недостатком является то, что он доступен только в Enterprise Edition MySQL. К сожалению, большинство установок MySQL не могут извлечь выгоду из Enterprise Monitor и того уровня понимания, который он обеспечивает для базы данных и показателей операционной системы. Он также не подходит для мониторинга чего-либо, кроме MySQL, запросов, которые он выполняет, и ОС, на которой он работает, а мониторинг MySQL ограничен продуктами Oracle.
Доступна 30-дневная пробная версия MySQL Enterprise Edition, которая включает в себя Enterprise Monitor, и Oracle также поддерживает список визуальных демонстраций системы.
- Percona Monitoring and Management
-
Решение для мониторинга Percona, PMM, похоже по функциональности на Oracle Enterprise Monitor, но является полностью бесплатным и с открытым исходным кодом. Задуманный как «единое стекло», PMM пытается обеспечить глубокое понимание производительности MySQL и ОС, а также может использоваться для мониторинга баз данных MongoDB и PostgreSQL.
PMM построен на основе существующих компонентов с открытым исходным кодом, таких как уже рассмотренный Prometheus и его экспортеры, а также Grafana. Percona поддерживает форки используемых экспортеров баз данных, в том числе для MySQL, и добавляет функциональность и метрики, которых не было в исходных версиях. Кроме того, PMM скрывает сложность, обычно связанную с развертыванием и настройкой этих инструментов, и вместо этого предоставляет собственный пакет и интерфейс настройки.
Как и Enterprise Monitor, PMM предлагает набор информационных панелей, визуализирующих почти все аспекты работы MySQL и InnoDB, а также предоставляющих множество подробностей о состоянии базовой ОС. Это было расширено за счет включения таких технологий, как PXC/Galera, обсуждаемых в главе 13, и ProxySQL, обсуждаемых в главе 15. Поскольку PMM использует Prometheus и экспортеры, можно расширить диапазон отслеживаемых баз данных, добавив внешние экспортеры. В дополнение к этому PMM поддерживает системы DBaaS, такие как RDS и CloudSQL.
PMM поставляется с пользовательским приложением под названием Query Analytics (QAN), которое представляет собой систему мониторинга запросов и показателей. Как и анализатор запросов Enterprise Monitor, QAN показывает общую историю запросов, выполненных в данной системе, а также информацию об отдельных запросах. Это включает в себя историю количества выполнений запроса с течением времени, прочитанных и отправленных строк, блокировок и созданных временных таблиц, среди прочего. QAN позволяет просматривать план запроса и структуры задействованных таблиц.
Управляющая (Management) часть PMM пока существует только в названии, так как на момент написания это чисто система мониторинга. PMM поддерживает оповещения через стандартный AlertManager Prometheus или с помощью внутренних шаблонов.
Одна существенная проблема с PMM заключается в том, что по умолчанию он поддерживает только цели, работающие в Linux. Поскольку экспортеры Prometheus являются кроссплатформенными, вы можете добавить цели Windows (или другой ОС) в PMM, но вы не сможете использовать некоторые преимущества инструмента, такие как упрощенная настройка экспортера и пакетная установка клиентского программного обеспечения.
Оба автора этой книги в настоящее время работают в Percona, поэтому у вас может возникнуть соблазн отклонить наше описание PMM как рекламу. Тем не менее, мы попытались дать честный обзор нескольких систем мониторинга и не утверждаем, что PMM идеальна. Если ваша компания уже использует корпоративную версию MySQL, то вам обязательно нужно сначала посмотреть, что может предложить MySQL Enterprise Monitor.
Прежде чем мы закроем этот раздел, мы хотим отметить, что во многих случаях фактическая система мониторинга, которую вы используете, не имеет большого значения. Каждая система, которую мы упомянули, обеспечивает мониторинг доступности MySQL, а также некоторый уровень понимания внутренних показателей — достаточный для выбора рецептов, которые мы дали ранее. Особенно, когда вы изучаете MySQL и, возможно, начинаете использовать ее установки в производственной среде, вам следует попытаться использовать существующую инфраструктуру мониторинга. Спешка все изменить к лучшему часто приводит к неудовлетворительным результатам. По мере накопления опыта вы будете замечать, что в имеющихся у вас инструментах отсутствует все больше и больше данных, и сможете принять взвешенное решение о том, какой новый инструмент выбрать.
Инциденты/диагностика и ручной сбор данных
Иногда у вас может не быть настроенной системы мониторинга для базы данных или вы можете не доверять ей, чтобы она содержала всю информацию, которая может понадобиться для расследования какой-либо проблемы. Или у вас может быть запущен экземпляр DBaaS, и вы хотите получить больше данных, чем предоставляет вам ваш облачный провайдер. В таких ситуациях ручной сбор данных может быть жизнеспособным вариантом в краткосрочной перспективе, чтобы быстро получить некоторые данные из системы. Мы покажем вам несколько инструментов, которые вы можете использовать, чтобы сделать это: быстро собрать много диагностической информации из любого экземпляра MySQL.
Следующие разделы представляют собой короткие полезные рецепты, которые вы можете взять и использовать в своей повседневной работе с базами данных MySQL.
Периодический сбор значений переменных состояния системы
В разделах «Переменные состояния» и «Основные рецепты мониторинга» мы много говорили о том, как меняются значения различных переменных состояния с течением времени. Каждый инструмент мониторинга, упомянутый в предыдущем разделе, делает это для накопления данных, которые затем используются для построения графиков и предупреждений. Такую же выборку переменных состояния можно выполнить вручную, если вы хотите просмотреть необработанные данные или просто произвести выборку с меньшим интервалом, чем использует ваша система мониторинга.
Вы можете написать простой сценарий, запускающий монитор MySQL в цикле, но лучше использовать встроенную утилиту mysqladmin. Эту программу можно использовать для выполнения широкого спектра административных операций на работающем сервере MySQL, хотя следует отметить, что каждую из них можно выполнять и через обычный файл mysql. Однако mysqladmin можно использовать для простой выборки глобальных переменных состояния, именно это мы и собираемся использовать здесь.
mysqladmin включает два вывода состояния: обычный и расширенный. Обычный менее информативен:
$ mysqladmin status
Uptime: 176190 Threads: 5 Questions: 5287160 ...
... Slow queries: 5114814 Opens: 761 Flush tables: 3 ...
... Open tables: 671 Queries per second avg: 30.008
На этом этапе расширенный вывод будет вам знаком. Это то же самое, что и вывод SHOW GLOBAL STATUS:
$ mysqladmin extended-status
+-----------------------------------------------+---------------------+
| Variable_name | Value |
+-----------------------------------------------+---------------------+
| Aborted_clients | 2 |
| Aborted_connects | 30 |
| ... |
| Uptime | 176307 |
| Uptime_since_flush_status | 32141 |
| validate_password.dictionary_file_last_parsed | 2021-05-29 21:50:38 |
| validate_password.dictionary_file_words_count | 0 |
+-----------------------------------------------+---------------------+
Удобно, что mysqladmin может повторять команды, которые он запускает с заданным интервалом, заданное количество раз. Например, следующая команда заставит mysqladmin печатать значения переменной состояния каждую секунду в течение минуты (ext — это сокращение от extended-status (расширенное состояние)):
$ mysqladmin -i1 -c60 extПеренаправляя его вывод в файл, вы можете получить минутную выборку изменений метрик базы данных. Работать с текстовыми файлами не так приятно, как с полноценными системами мониторинга, но опять же, это обычно делается при особых обстоятельствах. В течение долгого времени сбор информации о MySQL с помощью mysqladmin был стандартной практикой, поэтому существует инструмент под названием pt-mext, который может преобразовать простые выходные данные SHOW GLOBAL STATUS в формат, более подходящий для использования людьми. К сожалению, инструмент доступен только в Linux. Вот пример его вывода:
$ pt-mext -r -- cat mysqladmin.output | grep Bytes_sent
Bytes_sent 10836285314 15120 15120 31080 15120 15120 31080 15120 15120
Начальное большое число — это значение переменной состояния в первой выборке, а значения после этого представляют собой изменение исходного числа. Если бы значение уменьшалось, отображалось бы отрицательное число.
Использование pt-stalk для сбора метрик MySQL и ОС
pt-stalk является частью Percona Toolkit и обычно запускается вместе с MySQL и используется для постоянной проверки определенных условий. Как только это условие выполнено — например, значение Threads_running больше 15 — pt-stalk запускает процедуру сбора данных, собирающую обширную информацию о MySQL и операционной системе. Однако можно использовать часть сбора данных без фактического вмешательства в работу сервера MySQL. Хотя это и неправильный способ использования pt-stalk, это полезный метод для быстрого просмотра неизвестного сервера или попытки собрать как можно больше информации о плохо работающем сервере.
pt-stalk, как и другие инструменты Percona Toolkit, доступен только для Linux, хотя целевой сервер MySQL может работать на любой ОС. Основной вызов pt-stalk для достижения этого прост:
$ sudo pt-stalk --no-stalk --iterations=2 --sleep=30 \
--dest="/tmp/collected_data" \
-- --user=root --password=<root password>;
Утилита запустит два раунда сбора данных, каждый из которых будет длиться минуту, и будет спать в течение 30 секунд между ними. Если вам не нужна информация об ОС или вы не можете ее получить, поскольку вашей целью является экземпляр DBaaS, вы можете использовать флаг --mysql-only:
$ sudo pt-stalk --no-stalk --iterations=2 --sleep=30 \
--mysql-only --dest="/tmp/collected_data" \
-- --user=root --password=<root password> \
--host=<mysql host> --port=<mysql port>;
Вот список файлов, созданных за один раунд сбора. Мы намеренно опустили файлы, относящиеся к ОС, но их довольно много:
2021_04_15_04_33_44-innodbstatus1
2021_04_15_04_33_44-innodbstatus2
2021_04_15_04_33_44-log_error
2021_04_15_04_33_44-mutex-status1
2021_04_15_04_33_44-mutex-status2
2021_04_15_04_33_44-mysqladmin
2021_04_15_04_33_44-opentables1
2021_04_15_04_33_44-opentables2
2021_04_15_04_33_44-processlist
2021_04_15_04_33_44-slave-status
2021_04_15_04_33_44-transactions
2021_04_15_04_33_44-trigger
2021_04_15_04_33_44-variables
Расширенный ручной сбор данных
pt-stalk не всегда доступен и работает не на всех платформах. Иногда вам также может понадобиться добавить (или удалить некоторые) данные, которые он собирает. Вы можете использовать ранее представленную команду mysqladmin, чтобы собрать немного больше данных и упаковать их в простой сценарий. Вариант этого сценария часто используется авторами этой книги в их повседневной работе.
Этот скрипт, который должен работать в любой Linux или Unix-подобной системе, будет выполняться непрерывно либо до завершения, либо до тех пор, пока не будет найден файл /tmp/exit-flag. Вы можете запустить touch /tmp/exit-flag, чтобы изящно завершить выполнение этого скрипта. Мы рекомендуем поместить его в файл и запустить через nohup ... & или выполнить его в сеансе screen или tmux. Если вы не знакомы с терминами, которые мы только что упомянули, все они представляют собой способы убедиться, что сценарий продолжает выполняться при отключении сеанса. Вот сценарий:
DATADEST="/tmp/collected_data";
MYSQL="mysql --host=127.0.0.1 -uroot -proot";
MYSQLADMIN="mysqladmin --host=127.0.0.1 -uroot -proot";
[ -d "$DATADEST" ] || mkdir $DATADEST;
while true; do {
[ -f /tmp/exit-flag ] \
&& echo "exiting loop (/tmp/exit-flag found)" \
&& break;
d=$(date +%F_%T |tr ":" "-");
$MYSQL -e "SHOW ENGINE INNODB STATUS\G" > $DATADEST/$d-innodbstatus &
$MYSQL -e "SHOW ENGINE INNODB MUTEX;" > $DATADEST/$d-innodbmutex &
$MYSQL -e "SHOW FULL PROCESSLIST\G" > $DATADEST/$d-processlist &
$MYSQLADMIN -i1 -c15 ext > $DATADEST/$d-mysqladmin ;
} done;
$MYSQL -e "SHOW GLOBAL VARIABLES;" > $DATADEST/$d-variables;
Мы также создали версию того же скрипта для Windows, написанную в PowerShell. Он ведет себя точно так же, как и предыдущий скрипт, и завершится сам по себе, как только будет найден файл C:\tmp\exit-flag:
$mysqlbin='C:\Program Files\MySQL\MySQL Server 8.0\bin\mysql.exe'
$mysqladminbin='C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqladmin.exe'
$user='root'
$password='root'
$mysqlhost='127.0.0.1'
$destination='C:\tmp\collected_data'
$stopfile='C:\tmp\exit-flag'
if (-Not (Test-Path -Path '$destination')) {
mkdir -p '$destination'
}
Start-Process -NoNewWindow $mysqlbin -ArgumentList `
'-h$mysqlhost','-u$user','-p$password','-e 'SHOW GLOBAL VARIABLES;' `
-RedirectStandardOutput '$destination\variables'
while(1) {
if (Test-Path -Path '$stopfile') {
echo 'Found exit monitor file, aborting'
break;
}
$d=(Get-Date -Format 'yyyy-MM-d_HHmmss')
Start-Process -NoNewWindow $mysqlbin -ArgumentList `
'-h$mysqlhost','-u$user','-p$password','-e 'SHOW ENGINE INNODB STATUS\G'' `
-RedirectStandardOutput '$destination\$d-innodbstatus'
Start-Process -NoNewWindow $mysqlbin -ArgumentList `
'-h$mysqlhost','-u$user','-p$password','-e 'SHOW ENGINE INNODB MUTEX;'' `
-RedirectStandardOutput '$destination\$d-innodbmutex'
Start-Process -NoNewWindow $mysqlbin -ArgumentList `
'-h$mysqlhost','-u$user','-p$password','-e 'SHOW FULL PROCESSLIST\G'' `
-RedirectStandardOutput '$destination\$d-processlist'
& $mysqladminbin '-h$mysqlhost' -u'$user' -p'$password' `
-i1 -c15 ext > '$destination\$d-mysqladmin';
}
Вы должны помнить, что сбор данных на основе скриптов не заменяет надлежащий мониторинг. У него есть свои применения, которые мы описали в начале этого раздела, но он всегда должен быть дополнением к тому, что у вас уже есть, а не единственным способом взглянуть на метрики MySQL.
К настоящему времени, прочитав эту главу, вы должны иметь довольно хорошее представление о том, как подходить к мониторингу MySQL. Помните, что проблемы, инциденты и сбои будут происходить — они неизбежны. Однако при надлежащем мониторинге вы можете убедиться, что одна и та же проблема не возникает дважды, поскольку вы сможете найти основную причину после первого возникновения. Конечно, вы также сможете избежать некоторых проблем, изменив свою систему, чтобы исправить проблемы, обнаруженные вашими усилиями по мониторингу MySQL.
Мы оставим вас с заключительной мыслью: идеальный мониторинг недостижим, но даже самый элементарный мониторинг лучше, чем его полное отсутствие.
Глава 13
Высокая доступность
В контексте ИТ термин высокая доступность определяет состояние непрерывной работы в течение определенного периода времени. Цель не в том, чтобы устранить риск неудачи — это было бы невозможно. Скорее, мы пытаемся гарантировать, что в случае сбоя система останется доступной для продолжения работы. Мы часто измеряем доступность по стандарту 100% работоспособности или безотказности. Общий стандарт доступности известен как пять девяток или 99,999% доступности. Две девятки — это система, гарантирующая доступность на уровне 99% и допускающая время простоя до 1%. В течение года это будет означать 3,65 дня недоступности.
При проектировании надежности используются три принципа системного проектирования, помогающие достичь высокой доступности: устранение единых точек отказа (SPOF), надежные точки пересечения или переключения при отказе и возможности обнаружения отказов (включая мониторинг, обсуждаемый в главе 12).
Избыточность требуется для многих компонентов для достижения высокой доступности. Простой пример — самолет с двумя двигателями. Если во время полета выйдет из строя один двигатель, самолет все равно сможет приземлиться в аэропорту. Более сложный пример — атомная электростанция, где существует множество избыточных протоколов и компонентов, позволяющих избежать катастрофических сбоев. Точно так же для достижения высокой доступности базы данных нам необходимо резервирование сети, резервирование дисков, различные источники питания, несколько серверов приложений и баз данных и многое другое.
В этой главе основное внимание будет уделено вариантам достижения высокой доступности, предлагаемым базами данных MySQL.
Асинхронная репликация
Репликация позволяет копировать данные с одного сервера базы данных MySQL (известного как источник (source))) на один или несколько других серверов базы данных MySQL (известных как реплики (replicas)). Репликация MySQL по умолчанию является асинхронной. При асинхронной репликации источник записывает события в свой бинарный журнал, а реплики запрашивают их по мере готовности. Нет никакой гарантии, что какое-либо событие когда-либо достигнет какой-либо реплики. Это слабосвязанная связь источник/реплика, где верно следующее:
-
Источник не ждет, пока реплика догонит.
-
Реплика определяет, сколько читать и с какой точки в бинарном журнале.
-
Реплика может произвольно отставать от источника при чтении или применении изменений. Эта проблема известна как задержка репликации (replication lag), и мы рассмотрим способы ее минимизации.
Асинхронная репликация обеспечивает меньшую задержку записи, поскольку запись подтверждается локально источником перед записью в реплики.
MySQL реализует свои возможности репликации, используя три основных потока, один на исходном сервере и два на репликах:
- Поток дампа бинарного журнала
-
Источник создает поток для отправки содержимого бинарного журнала реплике при подключении реплики. Мы можем идентифицировать этот поток в выводе
SHOW PROCESSLISTв источнике как потокBinlog Dump.Поток дампа бинарного журнала блокирует бинарный журнал источника для чтения каждого события, отправленного реплике. Когда источник считывает событие, блокировка снимается еще до того, как источник отправит событие реплике.
- Поток ввода/вывода репликации
-
Когда мы выполняем оператор
START SLAVEна сервере-реплике, реплика создает поток ввода-вывода, подключенный к источнику, и запрашивает отправку обновлений, записанных в его бинарных журналах.Поток ввода-вывода репликации считывает обновления, которые отправляет поток
Binlog Dumpисточника (см. предыдущий пункт), и копирует их в локальные файлы, составляющие журнал ретрансляции реплики.MySQL показывает состояние этого потока как
Slave_IO_runningв выводеSHOW SLAVE STATUS. - SQL-поток репликации
-
Реплика создает поток SQL для чтения журнала ретрансляции, записанного
Есть способы улучшить распараллеливание репликации, как вы увидите далее в этой главе.
На рисунке 13.1 показано, как выглядит архитектура репликации MySQL.

Рисунок 13-1. Архитектура потока асинхронной репликации
Репликация работает, потому что события, записываемые в бинарный журнал, считываются из источника, а затем обрабатываются на реплике, как показано на рисунке 13-1. События записываются в бинарный журнал в различных форматах в зависимости от типа события. Репликация MySQL имеет три вида бинарных форматов регистрации:
- Репликация на основе строк (RBR)
-
Источник записывает в бинарный журнал события, указывающие на изменение отдельных строк таблицы. Репликация источника в реплику работает путем копирования событий, представляющих изменения строк таблицы реплики. Для MySQL 5.7 и 8.0 это формат репликации по умолчанию.
- Репликация на основе операторов (SBR)
-
Источник записывает операторы SQL в бинарный журнал. Репликация источника в реплику работает путем выполнения инструкций SQL на реплике.
- Смешанная репликация
-
Вы также можете настроить MySQL для использования сочетания ведения журнала на основе операторов и на основе строк, в зависимости от того, какой из них наиболее подходит для регистрации изменений. С ведением журнала смешанного формата MySQL по умолчанию использует журнал на основе операторов, но переключается на журнал на основе строк для определенных небезопасных операторов, которые имеют недетерминированное поведение. Например, предположим, что у нас есть следующее выражение:
mysql> UPDATE customer SET last_update=NOW() WHERE customer_id=1;Мы знаем, что функция
NOW()возвращает текущую дату и время. Представьте, что источник повторяет оператор с задержкой в 1 секунду (для этого могут быть разные причины, например, реплика находится на другом континенте, чем источник). Когда реплика получает оператор и выполняет его, разница в дате и времени, возвращаемых функцией, составляет 1 секунду, что приводит к несогласованности данных между источником и репликой. Когда используется смешанный формат репликации, всякий раз, когда MySQL анализирует недетерминированную функцию, подобную этой, она преобразует оператор в репликацию на основе строк. Список других функций, которые MySQL считает небезопасными, можно найти в документации.
Основные параметры для установки источника и реплики
Есть некоторые основные настройки, которые нам нужно установить как на исходном сервере, так и на сервере-реплике, чтобы репликация работала. Они необходимы для всех методов, описанных в этом разделе.
На исходном сервере необходимо включить ведение бинарного журнала и определить ID сервера. Вам потребуется перезапустить сервер после внесения этих изменений (если вы еще этого не сделали), потому что эти параметры не являются динамическими.
Вот как это будет выглядеть в файле my.cnf:
[mysqld]
log-bin=mysql-bin
server-id=1
Вам также необходимо установить ID сервера для каждой реплики. Как и в случае с исходным кодом, если вы еще этого не сделали, вам необходимо перезапустить сервер-реплику после присвоения ему идентификатора. Не обязательно включать бинарный журнал на сервере-реплике, хотя это рекомендуется сделать:
[mysqld]
log-bin=mysql-replica-bin
server-id=1617565330
binlog_format = ROW
log_slave_updates
Использование параметра log_slave_updates сообщает серверу реплики, что команды с исходного сервера должны регистрироваться в собственном бинарном журнале реплики. Опять же, это не обязательно, но рекомендуется в качестве хорошей практики.
Каждая реплика подключается к источнику с использованием имени пользователя и пароля MySQL, поэтому вам также потребуется создать учетную запись пользователя на исходном сервере, которую реплика может использовать для подключения (для обновления информации см. «Создание и использование новых пользователей»). Для этой операции можно использовать любую учетную запись, если ей предоставлена привилегия REPLICATION SLAVE. Вот пример того, как создать пользователя на исходном сервере:
mysqll> CREATE USER 'repl'@'%' IDENTIFIED BY 'P@ssw0rd!';
mysqll> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
В следующих разделах вы увидите различные варианты создания сервера-реплики.
Создание реплики с помощью PerconaXtraBackup
Как мы видели в главе 10, инструмент Percona XtraBackup предоставляет метод выполнения горячего резервного копирования ваших данных MySQL во время работы системы. Он также предлагает расширенные возможности, такие как распараллеливание, сжатие и шифрование.
Первым шагом является копирование текущего источника, чтобы мы могли запустить нашу реплику. Инструмент XtraBackup выполняет физическое резервное копирование источника (см. «Физические и логические резервные копии»). Мы будем использовать команды, представленные в «Percona XtraBackup»:
# xtrabackup --defaults-file=my.cnf -uroot -p_<password>_ \
-H <host> -P 3306 --backup --parallel=4 \
--datadir=./data/ --target-dir=./backup/
Кроме того, вы можете использовать rsync, NFS или любой другой метод, который вам удобен.
Как только XtraBackup завершит резервное копирование, мы отправим файлы в каталог резервного копирования на сервере-реплике. В этом примере мы отправим файлы с помощью команды scp:
# scp -r ./backup/* <user>@<host>:/backupНа этом мы закончили с источником. Следующие шаги будут выполняться только на сервере-реплике. Следующим шагом будет подготовка нашей резервной копии:
# xtrabackup --prepare --apply-log --target-dir=./Когда все настроено, мы собираемся переместить резервную копию в каталог данных:
# xtrabackup --defaults-file=/etc/my.cnf --copy-back --target-dir=./backupНа реплике содержимое файла xtrabackup_binlog_info будет выглядеть примерно так:
$ cat /backup/xtrabackup_binlog_info
mysql-bin.000003 156
Эта информация важна, потому что она говорит нам, с чего начать репликацию. Помните, что источник все еще получал операции, когда мы делали резервную копию, поэтому нам нужно знать, в какой позиции находился MySQL в файле бинарного журнала, когда резервное копирование завершилось.
С этой информацией мы можем запустить команду для запуска репликации. Это будет выглядеть примерно так:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.2', MASTER_USER='repl',
-> MASTER_PASSWORD='P@ssw0rd!',
-> MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=156;
mysql> START SLAVE;
После того, как вы начали, вы можете запустить команду SHOW SLAVE STATUS, чтобы проверить, работает ли репликация:
mysql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 8332
Relay_Log_Space: 8752
Until_Condition: None
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Важно проверить, запущены ли оба потока (Slave_IO_Running и Slave_SQL_Running), были ли ошибки (Last_Error) и на сколько секунд реплика отстает от источника. Для больших баз данных с интенсивной рабочей нагрузкой записи реплике может потребоваться некоторое время, чтобы наверстать упущенное.
Создание реплики с помощью плагина Clone
MySQL 8.0.17 представил плагин клонирования, который можно использовать, чтобы сделать один экземпляр сервера MySQL клоном другого. Мы ссылаемся на экземпляр сервера, где выполняется оператор CLONE, как на получателя, а на исходный экземпляр сервера, с которого получатель будет клонировать данные, как на донора. Экземпляр-донор может быть локальным или удаленным. Процесс клонирования работает путем создания физического моментального снимка данных и метаданных, хранящихся в механизме хранения InnoDB на доноре, и передачи его получателю. И локальные, и удаленные экземпляры выполняют одну и ту же операцию клонирования; нет никакой разницы, связанной с данными между двумя вариантами.
Давайте рассмотрим реальный пример. По ходу дела мы покажем вам некоторые дополнительные подробности, например, как отслеживать ход выполнения долго выполняющейся команды CLONE, привилегии, необходимые для клонирования, и многое другое. В следующем примере используется классическая оболочка. Мы поговорим о MySQL Shell, представленном в MySQL 8.0, в главе 16.
Выберите сервер MySQL для клонирования и подключитесь к нему как пользователь root. Затем установите плагин клонирования, создайте пользователя для передачи данных с сервера-донора и предоставьте этому пользователю привилегию BACKUP_ADMIN:
mysql> INSTALL PLUGIN CLONE SONAME "mysql_clone.so";
mysql> CREATE USER clone_user@'%' IDENTIFIED BY "clone_password";
mysql> GRANT BACKUP_ADMIN ON *.* to clone_user;
Затем, чтобы наблюдать за ходом операции клонирования, нам нужно предоставить этому пользователю привилегии для просмотра базы данных performance_schema и выполнения функций:
mysql> GRANT SELECT ON performance_schema.* TO clone_user;
mysql> GRANT EXECUTE ON *.* to clone_user;
Теперь перейдем к серверу-получателю. Если вы предоставляете новый узел, сначала инициализируйте каталог данных и запустите сервер.
Подключитесь к серверу-получателю в качестве пользователя root. Затем установите плагин клонирования, создайте пользователя для замены данных текущего экземпляра клонированными данными и предоставьте этому пользователю привилегию CLONE_ADMIN. Мы также предоставим список действительных доноров, которых реципиент может клонировать (здесь только один):
mysql> INSTALL PLUGIN CLONE SONAME "mysql_clone.so";
mysql> SET GLOBAL clone_valid_donor_list = "127.0.0.1:21122";
mysql> CREATE USER clone_user IDENTIFIED BY "clone_password";
mysql> GRANT CLONE_ADMIN ON *.* to clone_user;
Мы предоставим этому пользователю те же привилегии, что и на стороне донора, чтобы наблюдать за прогрессом на стороне получателя:
mysql> GRANT SELECT ON performance_schema.* TO clone_user;
mysql> GRANT EXECUTE ON *.* to clone_user;
Теперь у нас есть все необходимое, так что пришло время начать процесс клонирования. Обратите внимание, что сервер-донор должен быть доступен для получателя. Получатель подключится к донору с предоставленным адресом и учетными данными и начнет клонирование:
mysql> CLONE INSTANCE FROM clone_user@192.168.1.2:3306
-> IDENTIFIED BY "clone_password";
Получатель должен завершить работу и перезапустить себя, чтобы операция клонирования прошла успешно. Мы можем отслеживать прогресс с помощью следующего запроса:
SELECT STAGE, STATE, CAST(BEGIN_TIME AS TIME) as "START TIME",
CASE WHEN END_TIME IS NULL THEN
LPAD(sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(now()) - UNIX_TIMESTAMP(BEGIN_TIME))), 10,' )
ELSE
LPAD(sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(END_TIME) - UNIX_TIMESTAMP(BEGIN_TIME))), 10, )
END AS DURATION,
LPAD(CONCAT(FORMAT(ROUND(ESTIMATE/1024/1024,0), 0)," MB"), 16, )
AS "Estimate",
CASE WHEN BEGIN_TIME IS NULL THEN LPAD('0%, 7, ' )
WHEN ESTIMATE > 0 THEN
LPAD(CONCAT(CAST(ROUND(DATA*100/ESTIMATE, 0) AS BINARY), "%"), 7, ' ')
WHEN END_TIME IS NULL THEN LPAD('0%, 7, ' )
ELSE LPAD('100%, 7, ' ') END AS "Done(%)"
from performance_schema.clone_progress;
Это позволит нам наблюдать за каждым состоянием процесса клонирования. Вывод будет примерно таким:
+-----------+-----------+------------+-----------+----------+---------+
| STAGE | STATE | START TIME | DURATION | Estimate | Done(%) |
+-----------+-----------+------------+-----------+----------+---------+
| DROP DATA | Completed | 14:44:46 | 1.33 s | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| FILE COPY | Completed | 14:44:48 | 5.62 s | 1,511 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| PAGE COPY | Completed | 14:44:53 | 95.06 ms | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| REDO COPY | Completed | 14:44:54 | 99.71 ms | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| FILE SYNC | Completed | 14:44:54 | 6.33 s | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| RESTART | Completed | 14:45:00 | 4.08 s | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
| RECOVERY | Completed | 14:45:04 | 516.86 ms | 0 MB | 100% |
+-----------+-----------+------------+-----------+----------+---------+
7 rows in set (0.08 sec)
Как упоминалось ранее, в конце есть перезагрузка. Обратите внимание, что репликация еще не началась.
В дополнение к клонированию данных операция клонирования извлекает позицию бинарного журнала и GTID с сервера-донора и передает их получателю. Мы можем выполнить следующие запросы к донору, чтобы просмотреть позицию бинарного журнала или GTID последней примененной транзакции:
mysql> SELECT BINLOG_FILE, BINLOG_POSITION FROM performance_schema.clone_status;
+------------------+-----------------+
| BINLOG_FILE | BINLOG_POSITION |
+------------------+-----------------+
| mysql-bin.000002 | 816804753 |
+------------------+-----------------+
1 row in set (0.01 sec)
mysql> SELECT @@GLOBAL.GTID_EXECUTED;
+------------------------+
| @@GLOBAL.GTID_EXECUTED |
+------------------------+
| |
+------------------------+
1 row in set (0.00 sec)
В этом примере мы не используем GTID, поэтому запрос ничего не возвращает. Далее мы запустим команду для запуска репликации:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.1.2', MASTER_PORT = 3306,
-> MASTER_USER = 'repl', MASTER_PASSWORD = 'P@ssw0rd!',
-> MASTER_LOG_FILE = 'mysql-bin.000002',
-> MASTER_LOG_POSITION = 816804753;
mysql> START SLAVE;
Как и в предыдущем разделе, мы можем проверить правильность работы репликации, выполнив команду SHOW SLAVE STATUS.
Преимущество такого подхода в том, что плагин клонирования автоматизирует весь процесс, и только в конце необходимо выполнить команду CHANGE MASTER. Минус в том, что плагин доступен только для MySQL 8.0.17 и выше. Хотя это все еще относительно новый процесс, мы считаем, что в ближайшие годы этот процесс может стать стандартным.
Создание реплики с помощью mysqldump
Это то, что можно назвать классическим подходом. Это типичный вариант для тех, кто только начинает работать с MySQL и все еще изучает экосистему. Как обычно, мы предполагаем, что вы выполнили необходимую настройку в разделе «Основные параметры для установки источника и реплики».
Давайте посмотрим на пример использования mysqldump для создания новой реплики. Мы выполним резервное копирование с исходного сервера:
# mysqldump -uroot -p<password> --single-transaction \
--all-databases --routines --triggers --events \
--master-data=2 > backup.sql
Дамп выполнен успешно, если в конце появляется сообщение Dump completed:
# tail -1f backup.sql
-- Dump completed on 2021-04-26 20:16:33
Сделав резервную копию, нам нужно импортировать ее на сервер-реплику. Например, вы можете использовать эту команду:
$ mysql < backup.sqlКак только это будет сделано, вам нужно будет выполнить команду CHANGE MASTER с координатами, извлеченными из дампа (для получения дополнительной информации о mysqldump см. «Программа mysqldump»). Поскольку мы использовали параметр --master-data=2, информация будет записана в начале дампа. Например:
$ head -n 35 out
-- MySQL dump 10.13 Distrib 5.7.31-34, for Linux (x86_64)
--
-- Host: 127.0.0.1 Database:
-- ------------------------------------------------------
-- Server version 5.7.33-log
...
--
-- Position to start replication or point-in-time recovery from
--
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=4089;
Или, если вы используете GTID:
--
-- GTID state at the beginning of the backup
-- (origin: @@global.gtid_executed)
--
SET @@GLOBAL.GTID_PURGED=00048008-1111-1111-1111-111111111111:1-16;
Далее мы собираемся выполнить команду для запуска репликации. Для сценария GTID это выглядит так:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.2', MASTER_USER='repl',
-> MASTER_PASSWORD = 'P@ssw0rd!', MASTER_AUTO_POSITION=1;
mysql> START SLAVE;
Для традиционной репликации вы можете начать репликацию с ранее извлеченной позиции файла бинарного журнала следующим образом:
mysql> CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=4089,
-> MASTER_HOST='192.168.1.2', MASTER_USER='repl',
-> MASTER_PASSWORD='P@ssw0rd!';
mysql> START SLAVE;
Чтобы убедиться, что репликация работает, выполните команду SHOW SLAVE STATUS.
Создание реплики с использованием mydumper и myloader
mysqldump — наиболее распространенный инструмент, используемый новичками для создания резервных копий и создания реплик. Но есть более эффективный метод: mydumper. Как и mysqldump, этот инструмент создает логическую резервную копию и может использоваться для создания согласованной резервной копии вашей базы данных. Основное различие между mydumper и mysqldump заключается в том, что mydumper в паре с myloader может делать дамп и восстанавливать данные параллельно, улучшая дамп и, особенно, время восстановления. Представьте себе сценарий, в котором ваша база данных имеет дамп размером 500 ГБ. Используя mysqldump, вы получите один огромный файл. С mydumper у вас будет один файл для каждой таблицы, что позволит позже выполнять процесс восстановления параллельно.
Настройка утилит mydumper и myloader
Вы можете запускать mydumper непосредственно на исходном сервере или с другого сервера, что в целом лучше, поскольку позволяет избежать накладных расходов в системе хранения на запись файлов резервных копий на тот же сервер.
Чтобы установить mydumper, загрузите пакет для используемой версии операционной системы. Релизы можно найти в репозитории mydumper на GitHub. Давайте посмотрим на пример для CentOS:
# yum install https://github.com/maxbube/mydumper/releases/download/v0.10.3/ \
mydumper-0.10.3-1.el7.x86_64.rpm -yТеперь у вас должны быть установлены обе команды mydumper и myloader на сервере. Вы можете подтвердить это с помощью:
$ mydumper --version
mydumper 0.10.3, built against MySQL 5.7.33-36
$ myloader --version
myloader 0.10.3, built against MySQL 5.7.33-36
Извлечение данных из источника
Следующая команда выполнит дамп всех баз данных (кроме mysql, test и схемы sys) с 15 одновременными потоками, а также будет включать триггеры, представления и функции:
# mydumper --regex '^(?!(mysql\.|test\.|sys\.))' --threads=15 \
--user=learning_user --password='learning_mysql' --host=192.168.1.2 \
--port=3306 --trx-consistency-only --events --routines --triggers \
--compress --outputdir /backup --logfile /tmp/log.out --verbose=2
Если вы проверите выходной каталог (outputdir), вы увидите сжатые файлы. Вот вывод на одной из машин авторов:
# ls -l backup/
total 5008
-rw...1 vinicius.grippa percona 182 May 1 19:30 metadata
-rw...1 vinicius.grippa percona 258 May 1 19:30 sysbench.sbtest10-schema.sql.gz
-rw...1 vinicius.grippa percona 96568 May 1 19:30 sysbench.sbtest10.sql.gz
-rw...1 vinicius.grippa percona 258 May 1 19:30 sysbench.sbtest11-schema.sql.gz
-rw...1 vinicius.grippa percona 96588 May 1 19:30 sysbench.sbtest11.sql.gz
-rw...1 vinicius.grippa percona 258 May 1 19:30 sysbench.sbtest12-schema.sql.gz
...
Восстановление данных на сервере-реплике
Как и в случае с mysqldump, нам нужно, чтобы копия экземпляра MySQL уже была запущена и работала. Когда данные готовы к импорту, мы можем выполнить следующую команду:
# myloader --user=learning_user --password='learning_mysql'
--threads=25 --host=192.168.1.3 --port=3306
--directory=/backup --overwrite-tables --verbose 3
Создание системы репликации
Теперь, когда мы восстановили данные, настроим репликацию. Нам нужно найти правильную позицию бинарного журнала в начале резервного копирования. Эта информация хранится в файле метаданных mydumper:
$ cat backup/metadata
Started dump at: 2021-05-01 19:30:00
SHOW MASTER STATUS:
Log: mysql-bin.000002
Pos: 9530779
GTID:00049010-1111-1111-1111-111111111111:1-319
Finished dump at: 2021-05-01 19:30:01
Теперь мы просто выполняем команду CHANGE MASTER, как мы это делали ранее для mysqldump:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.2', MASTER_USER='repl',
-> MASTER_PASSWORD='P@ssw0rd!', MASTER_LOG_FILE='mysql-bin.000002',
-> MASTER_LOG_POS=9530779, MASTER_PORT=49010;
mysql> START SLAVE;
Групповая репликация
Включение групповой репликации в группу асинхронной репликации может вызвать некоторые споры. Краткое объяснение этого выбора заключается в том, что групповая репликация является асинхронной. Путаницу здесь можно объяснить сравнением с Galera (обсуждается в разделе «Кластер Galera/PXC»), который утверждает, что является синхронным или виртуально синхронным.
Более подробное рассуждение состоит в том, что это зависит от того, как мы определяем репликацию. В мире MySQL мы определяем репликацию как процесс, который позволяет автоматически дублировать изменения, внесенные в одну базу данных (источник), в другую (реплику). Весь процесс включает пять различных этапов:
Локальное применение изменения к источнику
Генерация бинарного журнала событий
Отправка бинарного журнала событий в реплику(и)
Добавление бинарного журнала событий в журнал ретрансляции реплики
Применение бинарного журнала событий из журнала ретрансляции в реплике
В MySQL Group Replication и Galera (даже если кеш Galera в первую очередь заменяет файлы журналов бинарного и ретрансляции) синхронным является только шаг 3 — потоковая передача события бинарного журнала (или набора записей в Galera) в реплику (и).
Таким образом, хотя процесс отправки (репликации/потоковой передачи) данных на другие серверы является синхронным, применение этих изменений по-прежнему полностью асинхронно.
Установка групповой репликации
Первое преимущество групповой репликации по сравнению с Galera заключается в том, что вам не нужно устанавливать разные бинарные файлы. MySQL Server предоставляет групповую репликацию в качестве подключаемого модуля. Он также доступен для Oracle MySQL и Percona Server для MySQL; подробности об их установке см. в Главе 1.
Чтобы убедиться, что плагин групповой репликации включен, выполните следующий запрос:
mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS, PLUGIN_TYPE
-> FROM INFORMATION_SCHEMA.PLUGINS
-> WHERE PLUGIN_NAME LIKE 'group_replication';
На выходе должно отображаться значение ACTIVE, как вы видите здесь:
+-------------------+---------------+-------------------+
| PLUGIN_NAME | PLUGIN_STATUS | PLUGIN_TYPE |
+-------------------+---------------+-------------------+
| group_replication | ACTIVE | GROUP REPLICATION |
+-------------------+---------------+-------------------+
1 row in set (0.00 sec)
Если плагин не установлен, выполните следующую команду, чтобы установить его:
mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so';При активном плагине мы установим минимальные параметры, необходимые на серверах для запуска групповой репликации. Откройте my.cnf на сервере 1 и добавьте следующее:
[mysqld]
server_id=175907211
log-bin=mysqld-bin
enforce_gtid_consistency=ON
gtid_mode=ON
log-slave-updates
transaction_write_set_extraction=XXHASH64
master_info_repository=TABLE
relay_log_info_repository=TABLE
binlog_checksum=NONE
Давайте рассмотрим каждый из этих параметров:
server_id-
Как и в случае с классической репликацией, этот параметр помогает идентифицировать каждого члена группы с помощью уникального ID. Вы должны использовать разные значения для каждого сервера, участвующего в групповой репликации.
log_bin-
В MySQL 8.0 этот параметр включен по умолчанию. Он отвечает за запись всех изменений в базе данных в файлы бинарного журнала.
enforce_gtid_consistency-
Это значение должно быть установлено в
ON, чтобы указать MySQL выполнять операторы, безопасные для транзакций, чтобы обеспечить согласованность при репликации данных. gtid_mode-
Эта директива включает ведение журнала на основе идентификаторов глобальных транзакций, если установлено значение
ON. Это необходимо для групповой репликации. log_slave_updates-
Для этого значения установлено значение
ON, чтобы участники могли регистрировать обновления друг друга. Другими словами, директива объединяет серверы репликации в цепочку. transaction_write_set_extraction-
Это значение указывает серверу MySQL собирать наборы записей и кодировать их с использованием алгоритма хеширования. В данном случае мы используем алгоритм XXHASH64. Наборы записи определяются первичными ключами каждой записи.
master_info_repository-
Если установлено значение
TABLE, эта директива позволяет MySQL хранить сведения об исходных файлах бинарных журналов и позициях в таблице, а не в файле, чтобы обеспечить более быструю репликацию и гарантировать согласованность с использованием свойств ACID InnoDB. В MySQL 8.0.23 это значение по умолчанию, а параметрFILEустарел. relay_log_info_repository-
Если установлено значение
TABLE, это настраивает MySQL для хранения информации о репликации в виде таблицы InnoDB. В MySQL 8.0.23 это значение по умолчанию, а параметрFILEустарел. binlog_checksum-
Установка этого параметра в
NONEуказывает MySQL не записывать контрольную сумму для каждого события в бинарном журнале. Вместо этого сервер будет проверять события, когда они записываются, проверяя их длину. В версиях MySQL до 8.0.20 включительно групповая репликация не может использовать контрольные суммы. Если вы используете более позднюю версию и хотите использовать контрольные суммы, вы можете опустить этот параметр и использовать значение по умолчаниюCRC32.
Далее мы добавим некоторые параметры для групповой репликации:
[mysqld]
loose-group_replication_group_name="8dc32851-d7f2-4b63-8989-5d4b467d8251"
loose-group_replication_start_on_boot=OFF
loose-group_replication_local_address="10.124.33.139:33061"
loose-group_replication_group_seeds="10.124.33.139:33061,
10.124.33.90:33061, 10.124.33.224:33061"
loose-group_replication_bootstrap_group=OFF
bind-address = "0.0.0.0"
report_host = "10.124.33.139"
Давайте посмотрим, что делает каждый параметр:
group_replication_group_name-
Это название группы, которую мы создаем. Мы собираемся использовать встроенную в Linux команду
uuidgenдля создания универсального уникального идентификатора (UUID). Он производит вывод следующим образом:$ uuidgen 8dc32851-d7f2-4b63-8989-5d4b467d8251 group_replication_start_on_boot-
Если установлено значение
OFF, это значение указывает плагину не начинать работу автоматически при запуске сервера. Вы можете установить для этого значения значениеONпосле завершения настройки всех членов группы. loose-group_replication_local_address-
Это комбинация внутреннего IP-адреса и порта, используемая для связи с другими членами сервера MySQL в группе. Рекомендуемый порт для групповой репликации — 33061.
group_replication_group_seeds-
Этоn параметр настраивает IP-адреса или имена хостов членов, участвующих в групповой репликации, вместе с их коммуникационным портом. Новые участники используют это значение, чтобы утвердиться в группе.
group_replication_bootstrap_group-
Этот параметр указывает серверу, создавать ли группу или нет. Мы включим эту опцию только по запросу на сервере 1, чтобы избежать создания нескольких групп. Так что пока он останется выключенным.
bind_address-
Значение
0.0.0.0указывает MySQL прослушивать все сети. report_host-
Это IP-адрес или имя хоста, которые члены группы сообщают друг другу при регистрации в группе.
Настройка групповой репликации MySQL
Сначала мы настроим канал group_replication_recovery. MySQL Group Replication использует этот канал для передачи транзакций между участниками. Из-за этого мы должны настроить пользователя репликации с разрешением REPLICATION SLAVE на каждом сервере.
Итак, на сервере 1 войдите в консоль MySQL и выполните следующие команды:
mysql> SET SQL_LOG_BIN=0;
mysql> CREATE USER replication_user@'%' IDENTIFIED BY 'P@ssw0rd!';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%';
mysql> FLUSH PRIVILEGES;
mysql> SET SQL_LOG_BIN=1;
Сначала мы устанавливаем для SQL_LOG_BIN значение 0, чтобы предотвратить запись сведений о новом пользователе в бинарный журнал, а затем снова включаем его в конце.
Чтобы указать серверу MySQL использовать пользователя репликации, которого мы создали для канала group_replication_recovery, выполните следующую команду:
mysql> CHANGE MASTER TO MASTER_USER='replication_user',
-> MASTER_PASSWORD='P@ssw0rd!' FOR CHANNEL
-> 'group_replication_recovery';
Эти настройки позволят участникам, присоединяющимся к группе, запустить процесс распределенного восстановления, чтобы достичь того же состояния, что и другие участники (доноры).
Теперь мы запустим службу групповой репликации на сервере 1. Мы загрузим группу с помощью этих команд:
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
mysql> START GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;
Чтобы избежать запуска большего количества групп, мы устанавливаем group_replication_bootstrap_group обратно в OFF после успешного запуска группы.
Чтобы проверить статус нового участника, используйте эту команду:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+...
| CHANNEL_NAME | MEMBER_ID |...
+---------------------------+--------------------------------------+...
| group_replication_applier | d58b2766-ab90-11eb-ba00-00163ed02a2e |...
+-------------+-------------+--------------+-------------+---------+...
...+---------------+-------------+--------------+-------------+----------------+
...| MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
...+---------------+-------------+--------------+-------------+----------------+
...| 10.124.33.139 | 3306 | ONLINE | PRIMARY | 8.0.22 |
...+---------------+-------------+--------------+-------------+----------------+
1 row in set (0.00 sec)
Отлично. На данный момент мы загрузили и инициировали одного члена группы. Переходим ко второму серверу. Убедитесь, что вы установили ту же версию MySQL, что и на сервере 1, и добавьте следующие настройки в файл my.cnf:
[mysqld]
loose-group_replication_group_name="8dc32851-d7f2-4b63-8989-5d4b467d851"
loose-group_replication_start_on_boot=OFF
loose-group_replication_local_address="10.124.33.90:33061"
loose-group_replication_group_seeds="10.124.33.139:33061,
10.124.33.90:33061, 10.124.33.224:33061"
loose-group_replication_bootstrap_group=OFF
bind-address = "0.0.0.0"
Все, что мы изменили, это group_replication_local_address; остальные настройки остаются прежними. Обратите внимание, что для сервера 2 требуются другие конфигурации MySQL, и мы настоятельно рекомендуем сохранять их одинаковыми для всех узлов.
После настройки перезапустите службу MySQL:
# systemctl restart mysqldВведите следующие команды, чтобы настроить учетные данные для пользователя восстановления на сервере 2:
mysql> SET SQL_LOG_BIN=0;
mysql> CREATE USER 'replication_user'@'%' IDENTIFIED BY 'P@ssw0rd!';
mysql> GRANT REPLICATION SLAVE ON *. TO 'replication_user'@'%';*
mysql> SET SQL_LOG_BIN=1;
mysql> CHANGE MASTER TO MASTER_USER='replication_user', MASTER_PASSWORD='PASSWORD' FOR CHANNEL 'group_replication_recovery';
Затем добавьте сервер 2 в группу, которую мы загрузили ранее:
mysql> START GROUP_REPLICATION;И запустите запрос, чтобы проверить состояние члена:
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+...
| CHANNEL_NAME | MEMBER_ID |...
+---------------------------+--------------------------------------+...
| group_replication_applier | 9e971ba0-ab9d-11eb-afc6-00163ec43109 |...
| group_replication_applier | d58b2766-ab90-11eb-ba00-00163ed02a2e |...
+-------------+-------------+--------------+-------------+---------+...
...+---------------+-------------+--------------+...
...| MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |...
...+---------------+-------------+--------------+...
...| 10.124.33.90 | 3306 | ONLINE |...
...| 10.124.33.139 | 3306 | ONLINE |...
...+---------------+-------------+--------------+...
...+-------------+----------------+
...| MEMBER_ROLE | MEMBER_VERSION |
...+-------------+----------------+
...| SECONDARY | 8.0.22 |
...| PRIMARY | 8.0.22 |
...+-------------+----------------+
2 rows in set (0.00 sec)
Теперь вы можете выполнить те же шаги для сервера 3, которые мы использовали для сервера 2, снова обновив локальный адрес. Когда вы закончите, вы можете проверить, отвечают ли все серверы, вставив некоторые фиктивные данные:
mysql> CREATE DATABASE learning_mysql;
Query OK, 1 row affected (0.00 sec)
mysql> USE learning_mysql
Database changed
mysql> CREATE TABLE test (i int primary key);
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO test VALUES (1);
Query OK, 1 row affected (0.00 sec)
Затем подключитесь к другим серверам, чтобы увидеть, можете ли вы визуализировать данные.
Синхронная репликация
Синхронная репликация используется Galera Clusters, где у нас есть более одного сервера MySQl, но они действуют как единое целое для приложения. На рисунке 13-2 показан кластер Galera с тремя узлами.

Рисунок 13-2. В кластере Galera все узлы взаимодействуют друг с другом.
Основное различие между синхронной и асинхронной репликацией заключается в том, что синхронная репликация гарантирует, что если изменение произойдет на одном узле в кластере, то это изменение произойдет на других узлах в кластере синхронно или в то же время. Асинхронная репликация не дает никаких гарантий относительно задержки между применением изменений на исходном узле и распространением этих изменений на узлы-реплики. Задержка при асинхронной репликации может быть короткой или длинной. Это также означает, что в случае сбоя исходного узла в топологии асинхронной репликации некоторые из последних изменений могут быть потеряны. Эти концепции источника и реплики не существуют в кластере Galera. Все узлы могут получать операции чтения и записи.
Теоретически синхронная репликация имеет несколько преимуществ перед асинхронной репликацией:
-
Кластеры, использующие синхронную репликацию, всегда высокодоступны. Если один из узлов выйдет из строя, то потери данных не будет. Кроме того, все узлы кластера всегда согласованы.
-
Кластеры, использующие синхронную репликацию, позволяют выполнять транзакции на всех узлах параллельно.
-
Кластеры, использующие синхронную репликацию, могут гарантировать причинно-следственную связь во всем кластере. Это означает, что если
SELECTвыполняется на одном узле кластера после выполнения транзакции на другом узле кластера, он должен увидеть результаты этой транзакции.
Однако у синхронной репликации есть и недостатки. Традиционно нетерпеливые протоколы репликации координируют узлы по одной операции за раз, используя двухэтапную фиксацию или распределенную блокировку. Увеличение количества узлов в кластере приводит к увеличению времени отклика транзакций и вероятности возникновения конфликтов и взаимоблокировок между узлами. Это связано с тем, что все узлы должны подтвердить транзакцию и ответить сообщением OK.
По этой причине асинхронная репликация остается доминирующим протоколом репликации для производительности, масштабируемости и доступности базы данных. Непонимание или недооценка влияния синхронной репликации — одна из причин, по которой компании иногда отказываются от использования кластеров Galera и возвращаются к использованию асинхронной репликации.
На момент написания статьи две компании поддерживали Galera Cluster: Percona и MariaDB. В следующем примере показано, как настроить кластер Percona XtraDB.
Galera/PXC Cluster
Установка Percona XtraDB Cluster (PXC) аналогична установке Percona Server (разница в пакетах), поэтому мы не будем углубляться в детали для всех платформ. Вы можете вернуться к главе 1, чтобы просмотреть процесс установки. Процесс настройки, которому мы будем следовать, предполагает наличие трех узлов PXC.
| Узел | Хост | IP |
|---|---|---|
| Узел 1 | pxc1 | 172.16.2.56 |
| Узел 2 | pxc2 | 172.16.2.198 |
| Узел 3 | pxc3 | 172.16.3.177 |
Подключаемся к одному из узлов и устанавливаем репозиторий:
# yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -yУстановив репозиторий, установите бинарники:
# yum install Percona-XtraDB-Cluster-57 -yЗатем вы можете применить типичные конфигурации, которые вы использовали бы для обычного процесса MySQL (см. главу 11). С внесенными изменениями запустите процесс mysqld и получите временный пароль:
# 'systemctl start mysqld'
# 'grep temporary password'/var/log/mysqld.log'
Используйте предыдущий пароль для входа в систему как root и измените пароль:
$ mysql -u root -p
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'P@ssw0rd!';
Остановите процесс mysqld:
# systemctl stop mysqlПовторите предыдущие шаги для двух других узлов.
Имея двоичные файлы и базовую конфигурацию, мы можем начать работу над параметрами кластера.
Нам нужно добавить следующие переменные конфигурации в /etc/my.cnf на первом узле:
[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_name=pxc-cluster
wsrep_cluster_address=gcomm://172.16.2.56,172.16.2.198,172.16.3.177
wsrep_node_name=pxc1
wsrep_node_address=172.16.2.56
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth=sstuser:P@ssw0rd!
pxc_strict_mode=ENFORCING
binlog_format=ROW
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
Используйте ту же конфигурацию для второго и третьего узлов, за исключением переменных wsrep_node_name и wsrep_node_address.
Для второго узла используйте:
wsrep_node_name=pxc2
wsrep_node_address=172.16.2.198
Для третьего узла используйте:
wsrep_node_name=pxc3
wsrep_node_address=172.16.3.177
Как и обычный MySQL, Percona XtraDB Cluster имеет множество настраиваемых параметров, и те, которые мы показали, являются минимальными настройками для запуска кластера. Мы настраиваем имя и IP-адрес узла, адрес кластера и пользователя, который будет использоваться для внутренней связи между узлами. Более подробную информацию вы можете найти в документации.
На данный момент у нас настроены все узлы, но процесс mysqld не запущен ни на одном узле. PXC требует, чтобы вы запустили один узел в кластере в качестве контрольной точки для других, прежде чем другие узлы смогут присоединиться и сформировать кластер. Этот узел должен быть запущен в режиме начальной загрузки (bootstrap). Начальная загрузка — это начальный шаг для введения одного сервера в качестве основного компонента, чтобы другие могли использовать его в качестве точки отсчета для синхронизации данных.
Запустите первый узел с помощью следующей команды:
# systemctl start mysql@bootstrapПрежде чем добавлять другие узлы в новый кластер, подключитесь к узлу, который вы только что запустили, создайте пользователя для передачи моментальных снимков состояния (SST) и предоставьте ему необходимые привилегии. Учетные данные должны соответствовать тем, которые указаны в конфигурации wsrep_sst_auth, которую вы установили ранее:
mysql> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 'P@ssw0rd!';
mysql> GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON .
-> TO 'sstuser'@'localhost';
mysql> FLUSH PRIVILEGES;
После этого вы можете регулярно инициализировать другие узлы:
# systemctl start mysqlЧтобы убедиться, что кластер работает нормально, мы можем выполнить несколько проверок, таких как создание базы данных на первом узле, создание таблицы и вставка некоторых данных на втором узле и получение некоторых строк из этой таблицы на третьем узле. Во-первых, давайте создадим базу данных на первом узле (pxc1):
mysq> CREATE DATABASE learning_mysql;
Query ok, 1 row affected (0.01 sec)
На втором узле (pxc2) создайте таблицу и вставьте некоторые данные:
mysql> USE learning_mysql;
Database changed
mysql> CREATE TABLE example (node_id INT PRIMARY KEY, node_name VARCHAR(30));
Query ok, 0 rows affected (0.05 sec)
mysql> INSERT INTO learning_mysql.example VALUES (1, "Vinicius1");
Query OK, 1 row affected (0.02 sec)
Затем извлеките несколько строк из этой таблицы на третьем узле:
mysql> SELECT * FROM learning_mysql.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | Vinicius1 |
+---------+-----------+
1 row in set (0.00 sec)
Другое, более элегантное решение — проверка глобальных переменных состояния wsrep_%, в частности wsrep_cluster_size и wsrep_cluster_status:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
1 row in set (0.00 sec)
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+
1 row in set (0.00 sec)
Вывод этих команд говорит нам о том, что кластер имеет три узла и находится в первичном состоянии (может принимать операции чтения и записи).
Вы можете рассмотреть возможность использования ProxySQL в дополнение к кластеру Galera, чтобы обеспечить прозрачность приложения (см. главу 15).
Целью этой главы было просто познакомить вас с различными топологиями, чтобы вы знали, что они существуют. Обслуживание и оптимизация кластера — сложная тема, которая выходят за рамки этой книги.
Глава 14
MySQL в облаке
«Не беспокойтесь, это в облаке» — фраза, которую мы часто слышим. Это напоминает нам историю о женщине, которая переживала, что после того, как ее iPhone утонул в унитазе, она потеряла все свои семейные фотографии и фотографии из путешествий. К ее удивлению, когда она купила новый телефон, устройство «восстановило» все фотографии. Она использовала решение для резервного копирования iCloud от Apple для резервного копирования содержимого своего устройства в облако. (Другим сюрпризом, возможно, был счет за подписку на услуги, который она не осознавала, что платила.)
Как компьютерные инженеры, мы не можем позволить себе роскошь рисковать в отношении того, будут ли восстановлены наши данные или нет. Облачное хранилище — это масштабируемое и надежное решение. В этой главе мы рассмотрим несколько вариантов использования MySQL в облаке, которые есть у компаний. Они варьируются от вариантов «база данных как услуга» (DBaaS), которые легко масштабируются и обеспечивают автоматическое резервное копирование и функции высокой доступности, до более традиционных вариантов, таких как инстансы EC2, которые обеспечивают более детальный контроль. Как правило, начинающие компании, основной бизнес которых не связан с технологиями, предпочитают использовать варианты DBaaS, поскольку их проще реализовать и с ними проще работать. С другой стороны, компании, которым требуется более строгий контроль над своими данными, могут предпочесть использовать экземпляр EC2 или собственную облачную инфраструктуру.
База данных как услуга (DBaaS)
DBaaS — это вариант аутсорсинга, когда компании платят поставщику облачных услуг за запуск и обслуживание облачной базы данных для них. Оплата обычно производится за использование, и владельцы данных могут получать доступ к данным своих приложений по своему усмотрению. DBaaS предоставляет те же функции, что и стандартная реляционная или нереляционная база данных. Часто это хорошее решение для компаний, пытающихся избежать настройки, обслуживания и обновления своих баз данных и серверов (хотя это не всегда так). DBaaS существует в сфере программного обеспечения как услуги (SaaS), такой как платформа как услуга (PaaS) и инфраструктура как услуга (IaaS), где такие продукты, как базы данных, становятся услугами.
Amazon RDS для MySQL/MariaDB
Наиболее популярным DBaaS является Amazon RDS для MySQL. Начало работы с RDS похоже на настройку нового автомобиля на веб-сайте. Вы выбираете основной продукт и добавляете нужные параметры, пока он не будет выглядеть так, как вам нравится, а затем запускаете. На рисунке 14-1 показаны доступные продукты. В этом случае мы перейдем на MySQL (версия MariaDB имеет аналогичные настройки для развертывания).

Рисунок 14-1. Выбор продукта
Мы также можем выбрать версию — здесь мы выбрали 8.0.21. Далее нам нужно установить главного пользователя (похожего на root) и его пароль. Убедитесь, что вы выбрали надежный пароль, особенно если вы откроете свою базу данных для всего мира. На рисунке 14-2 показано, как определить имя пользователя и пароль для главного пользователя.

Рисунок 14-2. Настройка имени пользователя и пароля главного пользователя
Далее идет размер экземпляра, который напрямую влияет на окончательную цену. Мы выберем конфигурацию верхнего уровня, чтобы дать вам представление о том, насколько дорогостоящим может быть использование DBaaS. На рисунке 14.3 показаны доступные классы экземпляров; есть несколько вариантов с разной стоимостью.

Рисунок 14-3. Выбор класса экземпляра
Еще один параметр, который может напрямую повлиять на выставление счетов, — это параметры хранилища. Естественно, более высокая производительность (больше операций ввода-вывода в секунду) и больший объем хранилища приводят к более высокой стоимости. Рисунок 14-4 иллюстрирует выбор. Вы также можете выбрать, следует ли включить автомасштабирование.

Рисунок 14-4. Настройка размера хранилища и его производительности IOPS
Следующий вариант — важный выбор: хотите ли вы использовать развертывание в нескольких зонах доступности или нет? Вариант с несколькими зонами доступности — это высокая доступность. При предоставлении инстанса БД в нескольких зонах доступности Amazon RDS автоматически создает основной инстанс БД и синхронно реплицирует данные в резервный инстанс в другой зоне доступности (AZ). Зоны доступности физически разделены и имеют независимую инфраструктуру, что повышает общую доступность.
Если вы не хотите использовать развертывание в нескольких зонах доступности, RDS установит один экземпляр. В случае сбоя он запустит новый и перемонтирует свой том данных. Этот процесс занимает некоторое время, в течение которого ваша база данных будет недоступна. Даже крупные облачные провайдеры не являются пуленепробиваемыми, и могут случиться катастрофы, поэтому всегда рекомендуется иметь резервный сервер. На рисунок 14-5 показано, как настроить реплику.

Рисунок 14-5. Настройка резервной реплики
Следующая часть — настройка общей сетевой конфигурации. Мы рекомендуем настроить RDS для использования частной сети, к которой могут получить доступ только серверы приложений и IP-адреса разработчиков. На рисунке 14-6 показаны параметры сети.

Рисунок 14-6. Настройка сетевых параметров
Наконец, увы, приходят сметные расходы. На рисунке 14-7 показано, сколько вы будете платить в месяц за настроенные варианты.

Рисунок 14-7. Счет может достигать звезд при определенных конфигурациях!
Google Cloud SQL для MySQL
Google Cloud SQL предлагает управляемые службы баз данных, сопоставимые с Amazon RDS (и Azure), но с небольшими отличиями. Варианты Google Cloud для MySQL более просты, потому что вариантов меньше. Например, вы не можете выбрать между MySQL и MariaDB или выбрать минорную версию MySQL (только основную версию). Как показано на рисунке 14-8, вы можете начать работу либо с создания нового экземпляра, либо с переноса существующей базы данных в Google Cloud.

Рисунок 14-8. Google Cloud SQL
При создании нового экземпляра вам необходимо указать несколько параметров. Первый шаг – выбор товара. На рисунке 14-9 показаны параметры, доступные для MySQL.

Рисунок 14-9. Выбор продукта
После выбора MySQL вам нужно будет указать имя экземпляра, пароль root, версию базы данных и местоположение. Рисунок 14-10 показывает, как настроить эти параметры.

Рисунок 14-10. Настройка базовой конфигурации
Далее следуют настройки, которые могут повлиять на производительность, и, конечно же, стоимость — здесь важно найти правильный баланс. На рисунке 14-11 показаны доступные варианты хранения, памяти и ЦП.

Рисунок 14-11. Настройка типа машины и хранилища
Теперь экземпляр готов к запуску в Google Cloud.
Azure SQL
Последним из трех ведущих поставщиков облачных услуг является Azure SQL. На рисунке 14.12 показаны продукты баз данных, доступные в Azure. Вам нужно выбрать «Azure Database for MySQL servers».

Рисунок 14-12. Выбор MySQL в Azure
Azure предлагает два варианта: использовать простой сервер или более надежное решение с высокой доступностью в настройках. Рисунок 14-13 показывает разницу между двумя вариантами.

Рисунок 14-13. Выбор одного сервера или гибкого сервера
За этими выборами следуют аналогичные конфигурации в отношении производительности и стоимости услуг. На рисунке 14-14 показаны параметры управляемых служб MySQL.

Рисунок 14-14. Настройка нашего экземпляра управляемой службы MySQL
Amazon Aurora
Amazon Aurora — это совместимое с MySQL и PostgreSQL решение для реляционной базы данных, предоставляемое Amazon по коммерческой лицензии. Он предлагает функции, аналогичные MySQL, а также несколько дополнительных функций, разработанных Amazon.
Две из этих особенностей заслуживают упоминания. Во-первых, это Aurora Parallel Query (PQ), функция, которая распараллеливает некоторые операции ввода-вывода и вычисления, связанные с обработкой запросов с интенсивным использованием данных.
Aurora PQ работает, выполняя полное сканирование таблицы (уровень хранилища выполняет параллельное чтение). Когда мы используем параллельный запрос, запрос не использует буферный пул InnoDB. Вместо этого он переносит обработку запросов на уровень хранилища и распараллеливает ее.
Преимущество заключается в том, что перемещение обработки ближе к данным снижает сетевой трафик и задержку. Однако эта функция не является панацеей и работает не во всех случаях — она лучше всего подходит для аналитических запросов, которым необходимо обрабатывать большие объемы данных.
Функция PQ доступна не для всех экземпляров AWS. Для экземпляров, поддерживающих эту функцию, их класс экземпляра определяет количество параллельных запросов, которые могут быть активны в данный момент времени. Следующие экземпляры поддерживают функцию PQ:
-
db.r*.large: 1 одновременный сеанс параллельных запросов -
db.r*.xlarge: 2 одновременных сеанса параллельных запросов -
db.r*.2xlarge: 4 одновременных сеанса параллельных запросов -
db.r*.4xlarge: 8 одновременных сеансов параллельных запросов -
db.r*.8xlarge: 16 одновременных сеансов параллельных запросов. -
db.r4.16xlarge: 16 одновременных сеансов параллельных запросов.
Другой примечательной особенностью является глобальная база данных Amazon Aurora, предназначенная для приложений с глобальным охватом. Это позволяет одной базе данных Aurora охватывать несколько регионов AWS с быстрой репликацией, обеспечивающей глобальное чтение с малой задержкой и аварийное восстановление после сбоев в масштабах региона. Глобальная база данных Aurora использует репликацию на основе хранилища с использованием выделенной инфраструктуры Amazon в своих центрах обработки данных по всему миру.
Облачные экземпляры MySQL
Облачный экземпляр (cloud instance) — это не что иное, как виртуальный сервер. У разных поставщиков облачных услуг они называются по-разному: экземпляры Amazon Elastic Compute Cloud (EC2), экземпляры Google Compute Engine и виртуальные машины Azure.
Все они предлагают различные типы экземпляров в соответствии с бизнес-потребностями пользователя, начиная от неглубоких базовых конфигураций и заканчивая удивительно расширенными возможностями. Например, тип машины Compute Engine m2-megamem-416 — это монстр с 416 ЦП и 5888 ГБ ОЗУ.
Процесс установки MySQL для этих экземпляров является стандартным, описанным в главе 1. В этом случае наиболее значительным преимуществом использования облачных экземпляров по сравнению с решениями DBaaS является свобода настройки MySQL и операционной системы в соответствии с вашими потребностями без ограничений, присущих управляемым базам данных.
MySQL в Kubernetes
Самый последний вариант, доступный для развертывания экземпляров MySQL, — это Kubernetes. Kubernetes и платформа OpenShift добавили способ управления контейнерными системами, включая кластеры баз данных. Управление осуществляется контроллерами, объявленными в конфигурационных файлах. Эти контроллеры обеспечивают автоматизацию создания объектов, таких как контейнер или группа контейнеров, называемых pod, для прослушивания определенного события и выполнения задачи.
Эта автоматизация усложняет архитектуру на основе контейнеров и приложений с отслеживанием состояния, таких как базы данных. Оператор Kubernetes — это особый тип контроллера, введенный для упрощения сложных развертываний. Оператор расширяет API Kubernetes с помощью настраиваемых ресурсов.
О том, как работает Kubernetes, написано много хороших книг. Чтобы сделать этот раздел максимально кратким, мы обсудим важные компоненты, относящиеся к оператору Percona Kubernetes. Для быстрого ознакомления с Kubernetes вы можете ознакомиться с документацией от Linux Foundation. На рисунке 14-15 показаны компоненты Percona XtraDB Cluster в Kubernetes.

Рисунок 14-15. Компоненты кластера Percona XtraDB в Kubernetes
В следующем разделе описывается, как развернуть оператор Percona Kubernetes для кластера Percona XtraDB, который считается готовым к работе. Есть и другие операторы. Например:
-
Oracle предоставляет оператора Kubernetes для кластера MySQL InnoDB. На момент написания этой статьи оператор находится в состоянии предварительного просмотра, поэтому его не рекомендуется использовать в производстве.
-
У MariaDB есть оператор, но на момент написания он находится в стадии альфа-тестирования, поэтому, пожалуйста, проверьте его зрелость, прежде чем использовать его в производстве.
-
Presslabs выпустила оператор, который развертывает экземпляры MySQL вместе с оркестратором и функциями резервного копирования. Этот оператор готов к работе.
Развертывание Percona XtraDB Cluster в Kubernetes
В этом разделе описаны этапы развертывания кластера Kubernetes в Google Cloud с использованием Google Cloud SDK и Percona Kubernetes Operator для PXC:
-
Установка Google Cloud SDK.
SDK предоставляет инструменты и библиотеки для взаимодействия с продуктами и сервисами Google Cloud. Загрузите бинарный файл, подходящий для вашей платформы, и установите его. Вот пример для macOS:
$ wget https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/ \ google-cloud-sdk-341.0.0-darwin-x86_64.tar.gz $ tar -xvf google-cloud-sdk-341.0.0-darwin-x86_64.tar.gz $ cd google-cloud-sdk/ $ ./install.sh -
Установите
kubectlчерезgcloud.Установив
gcloud, установите компонентkubectlс помощью следующей команды:$ gcloud components install kubectl -
Создайте кластер Kubernetes.
Для создания кластера Kubernetes сначала необходимо пройти аутентификацию в сервисе Google Cloud:
$ gcloud auth loginПосле аутентификации создайте кластер. Команда принимает множество параметров, но в данном случае мы рассмотрим основы создания кластера Kubernetes:
$ gcloud container clusters create --machine-type n1-standard-4 \ --num-nodes 3 --zone us-central1-b --project support-211414 \ --cluster-version latest vinnie-k8Используемые здесь параметры — это лишь малая часть всего доступного — вы можете увидеть все параметры, запустив
gcloud container clusters --help. Для этого случая мы только что запросили кластер с тремя узлами экземпляров типаn1-standard-4.Этот процесс может занять некоторое время, особенно если узлов много. Вывод будет выглядеть следующим образом:
Creating cluster vinnie-k8 in us-central1-b... Cluster is being health-checked (master is healthy)...done. Created [https://container.googleapis.com/v1/projects/support-211414/ zones/us-central1-b/clusters/vinnie-k8]. To inspect the contents of your cluster, go to: https://console.cloud.google.com/kubernetes/workload_/gcloud/ us-central1-b/vinnie-k8?project=support-211414 kubeconfig entry generated for vinnie-k8. +-----------+---------------+------------------+---------------+... | NAME | LOCATION | MASTER_VERSION | MASTER_IP |... +-----------+---------------+------------------+---------------+... | vinnie-k8 | us-central1-b | 1.19.10-gke.1000 | 34.134.67.128 |... +-----------+---------------+------------------+---------------+... ...+---------------------------------+-----------+---------+ ...| MACHINE_TYPE NODE_VERSION | NUM_NODES | STATUS | ...+---------------------------------+-----------+---------+ ...| n1-standard-4 1.19.10-gke.1000 | 3 | RUNNING | ...+---------------------------------+-----------+---------+И мы можем проверить модули нашего кластера Kubernetes в Google Cloud:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION gke-vinnie-k8-default-pool-376c2051-5xgz Ready <none> 62s v1.19.10-gke.1000 gke-vinnie-k8-default-pool-376c2051-w2tk Ready <none> 61s v1.19.10-gke.1000 gke-vinnie-k8-default-pool-376c2051-wxd7 Ready <none> 62s v1.19.10-gke.1000Также можно использовать интерфейс Google Cloud для развертывания кластера, как показано на рисунке 14-16.
Рисунок 14-16. В главном меню выберите Kubernetes Engine, затем Clusters.
Чтобы создать новый кластер, выберите опцию CREATE, показанную в верхней части рисунка 14-17.

Рисунок 14-17. Создайте кластер Kubernetes, нажав CREATE


Последним шагом является установка оператора PXC. В документации по развертыванию оператора есть очень подробные инструкции. Мы будем следовать рекомендуемым здесь шагам.
Сначала настройте Cloud Identity and Access Management (Cloud IAM) для управления доступом к кластеру. Следующая команда даст вам возможность создавать роли и привязки ролей:
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole \
cluster-admin --user $(gcloud config get-value core/account)
Оператор return подтверждает создание:#############???
clusterrolebinding.rbac.authorization.k8s.io/cluster-admin-binding createdЗатем создайте пространство имен и установите контекст для пространства имен:
$ kubectl create namespace learning-mysql
$ kubectl config set-context $(kubectl config current-context) \
--namespace=learning-mysql
Теперь клонируйте репозиторий и перейдите в каталог:
$ git clone -b v1.8.0 \
https://github.com/percona/percona-xtradb-cluster-operator
$ cd percona-xtradb-cluster-operator
Разверните оператор с помощью следующей команды:
$ kubectl apply -f deploy/bundle.yamlЭто должно вернуть следующее подтверждение:
customresourcedefinition.apiextensions.k8s.io/perconaxtradbclusters.pxc.percona.com created
customresourcedefinition.apiextensions.k8s.io/perconaxtradbclusterbackups.pxc.percona.com created
customresourcedefinition.apiextensions.k8s.io/perconaxtradbclusterrestores.pxc.percona.com created
customresourcedefinition.apiextensions.k8s.io/perconaxtradbbackups.pxc.percona.com created
role.rbac.authorization.k8s.io/percona-xtradb-cluster-operator created
serviceaccount/percona-xtradb-cluster-operator created
rolebinding.rbac.authorization.k8s.io/service-account-percona-xtradb-cluster-operator created
deployment.apps/percona-xtradb-cluster-operator created
Оператор запущен, и вы можете убедиться в этом, выполнив:
$ kubectl get podsТеперь создайте кластер Percona XtraDB:
$ kubectl apply -f deploy/cr.yamlЭтот шаг может занять некоторое время. После этого вы увидите все запущенные поды:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cluster1-haproxy-0 2/2 Running 0 4m54s
cluster1-haproxy-1 2/2 Running 0 3m15s
cluster1-haproxy-2 2/2 Running 0 2m52s
cluster1-pxc-0 3/3 Running 0 4m54s
cluster1-pxc-1 3/3 Running 0 3m16s
cluster1-pxc-2 3/3 Running 0 105s
percona-xtradb-cluster-operator- 1/1 Running 0 7m18s
77bfd8cdc5-d7zll
На предыдущих этапах оператор сгенерировал несколько секретных данных, включая пароль для пользователя root, который понадобится вам для доступа к кластеру. Чтобы получить сгенерированные секретные данные, выполните следующую команду:
$ kubectl get secret my-cluster-secrets -o yamlВы увидите такой вывод:
apiVersion: v1
data:
clustercheck: UFZjdjk0SU4xWGtBSTR2VlVJ
monitor: ZWZja01mOWhBTXZ4bTB0bUZ4eQ==
operator: Vm10R0IxbHA4cVVZTkxqVVI4Mg==
proxyadmin: VXVFbkx1S3RmUTEzVlNOd1c=
root: eU53aWlKT3ZXaXJaeG16OXJK
xtrabackup: V3VNNWRnWUdIblVWaU1OWGY=
...
secrets/my-cluster-secrets
uid: 9d78c4a8-1926-4b7a-84a0-43087a601066
type: Opaque
Фактический пароль имеет кодировку base64, поэтому вам нужно будет выполнить следующую команду, чтобы получить пароль root:
$ echo 'eU53aWlKT3ZXaXJaeG16OXJK' | base64 --decode
yNwiiJOvWirZxmz9rJ
Теперь, когда у вас есть пароль, для проверки подключения к кластеру вы можете создать клиентский под (pod):
$ kubectl run -i --rm --tty percona-client --image=percona:8.0 \
--restart=Never -- bash -il
Затем подключитесь к MySQL:
$ mysql -h cluster1-haproxy -uroot -pyNwiiJOvWirZxmz9rJОбратите внимание, что оператор поставляется с HAProxy, который является балансировщиком нагрузки (мы обсудим балансировку нагрузки в следующей главе).
Глава 15
Балансировка нагрузки MySQL
Существуют различные способы подключения к MySQL. Например, для выполнения теста записи создается соединение, выполняется оператор, а затем соединение закрывается. Чтобы избежать затрат на открытие соединения каждый раз, когда оно необходимо, была разработана концепция пула соединений (connection pool). Пул соединений — это метод создания и управления пулом соединений, готовых для использования любым потоком приложения.
Распространяя концепцию высокой доступности, обсуждавшуюся в главе 13, на соединения с целью повышения отказоустойчивости производственной системы, можно использовать балансировщики нагрузки (load balancers) для подключения к кластеру базы данных. Балансировка нагрузки и высокая доступность MySQL позволяют поддерживать бесперебойную работу приложения (или с незначительными простоями). По сути, если исходный сервер или один из узлов кластера базы данных выходит из строя, клиенту просто нужно подключиться к другому узлу базы данных, и он может продолжать обслуживать запросы.
Балансировщики нагрузки были созданы для обеспечения прозрачности для клиентов при подключении к инфраструктуре MySQL. Таким образом, приложению не нужно знать топологию MySQL; используете ли вы классическую репликацию, групповую репликацию или кластер Galera, не имеет значения. Балансировщик нагрузки предоставит онлайн-узел, где можно будет читать и писать запросы. Наличие надежной архитектуры MySQL и надлежащего балансировщика нагрузки может помочь администраторам баз данных избежать бессонных ночей.
Балансировка нагрузки с помощью драйверов приложений
Чтобы подключить приложение к MySQL, вам нужен драйвер. Драйвер — это адаптер, используемый для подключения приложения к системе другого типа. Это похоже на подключение видеокарты к компьютеру; вам может потребоваться загрузить и установить драйвер, чтобы он работал с вашим приложением.
Современные драйверы MySQL из широко используемых языков программирования поддерживают пул соединений, балансировку нагрузки и отработку отказа. Примеры включают драйвер JDBC для MySQL (MySQL Connector/J) и драйвер PDO_MYSQL, который реализует интерфейс PHP Data Objects (PDO) для обеспечения доступа из PHP к базам данных MySQL.
Упомянутые нами драйверы базы данных созданы для обеспечения прозрачности для клиентов при подключении к автономному серверу MySQL или настройкам репликации MySQL. Мы не будем показывать вам, как использовать их в коде, потому что это выходит за рамки этой книги; однако вы должны знать, что добавление библиотеки драйверов облегчает разработку кода, поскольку драйвер абстрагирует значительный объем работы от разработчика.
Но для других топологий, таких как установка кластера, такая как Galera Cluster для MySQL или MariaDB, драйверы JDBC и PHP не знают о внутренней информации о состоянии Galera. Например, узел-донор Galera может находиться в режиме только для чтения, пока он помогает другому узлу повторно синхронизироваться (если используется метод SST mysqldump или rsync), или он может находиться в неосновном состоянии, если происходит разделение. Другое решение — использовать балансировщик нагрузки между клиентами и кластером базы данных.
Балансировщик нагрузки ProxySQL
ProxySQL — это прокси SQL. ProxySQL реализует протокол MySQL, и благодаря этому он может делать то, что не могут другие прокси. Вот некоторые из его преимуществ:
-
Обеспечивает «интеллектуальную» балансировку нагрузки запросов приложений к нескольким базам данных.
-
Понимает трафик MySQL, который проходит через него, и может отделять чтение от записи. Понимание протокола MySQL особенно полезно при настройке репликации источник/реплика, когда записи должны идти только к источнику, а чтение к репликам, или, в случае кластера Galera, для равномерного распределения запросов на чтение (линейное масштабирование чтения).
-
Понимает базовую топологию базы данных, включая то, работают ли экземпляры или нет, и поэтому может направлять запросы в работоспособные базы данных.
-
Предоставляет аналитику рабочей нагрузки запросов и кеш запросов, которые полезны для анализа и повышения производительности.
-
Предоставляет администраторам надежные, расширенные определения правил запросов для эффективного распределения запросов и кэширования данных, чтобы максимизировать эффективность службы базы данных.
ProxySQL работает как демон, за которым следит процесс мониторинга. Процесс отслеживает работу демона и перезапускает его в случае сбоя, чтобы свести к минимуму время простоя. Демон принимает входящий трафик от клиентов MySQL и перенаправляет его на внутренние серверы MySQL.
Прокси предназначен для непрерывной работы без необходимости перезапуска. Большинство конфигураций можно выполнить во время выполнения с помощью запросов, аналогичных операторам SQL в административном интерфейсе ProxySQL. К ним относятся параметры среды выполнения, группировка серверов и параметры, связанные с трафиком.
Хотя обычно ProxySQL устанавливается на автономном узле между приложением и базой данных, это может повлиять на производительность запросов из-за дополнительной задержки из-за сетевых переходов. На рисунке 15-1 показан ProxySQL в качестве промежуточного уровня.

Рисунок 15-1. ProxySQL между приложением и MySQL
Чтобы уменьшить влияние на производительность (и избежать дополнительных переходов по сети), другим вариантом архитектуры является установка ProxySQL на серверах приложений. Затем приложение подключается к ProxySQL (действующему как сервер MySQL) на локальном хосте, используя сокет домена Unix, избегая дополнительной задержки. Он использует свои правила маршрутизации, чтобы связаться с реальными серверами MySQL и использовать их пул подключений. Приложение понятия не имеет, что происходит помимо его подключения к ProxySQL. Рисунок 15-2 показывает ProxySQL на том же сервере, что и приложение.

Рисунок 15-2. ProxySQL на том же сервере, что и приложение
Установка и настройка ProxySQL
Давайте посмотрим, как развернуть ProxySQL для конфигурации источник/реплика.
Разработчики инструмента предоставляют официальные пакеты для различных дистрибутивов Linux для всех релизов ProxySQL на своей странице релизов GitHub, поэтому мы загрузим оттуда последнюю версию пакета и установим ее.
Перед установкой в этом процессе мы будем использовать следующие экземпляры:
+---------------------------------------+----------------------+
| vinicius-grippa-default(mysql) | 10.124.33.5 (eth0) |
+---------------------------------------+----------------------+
| vinicius-grippa-node1(mysql) | 10.124.33.169 (eth0) |
+---------------------------------------+----------------------+
| vinicius-grippa-node2(mysql) | 10.124.33.130 (eth0) |
+---------------------------------------+----------------------+
| vinicius-grippa-node3(proxysql) | 10.124.33.170 (eth0) |
+---------------------------------------+----------------------+
Для начала найдите подходящий дистрибутив для вашей операционной системы. В этом примере мы затем установим для CentOS 7. Сначала мы станем root'ом, установим клиент MySQL для подключения к ProxySQL и установим сам ProxySQL. Мы получаем URL-адрес со страницы загрузок и отправляем его в yum:
$ sudo su - root
# yum -y install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
# yum -y install Percona-Server-client-57
# yum install -y https://github.com/sysown/proxysql/releases/download/v2.0.15/ \
proxysql-2.0.15-1-centos7.x86_64.rpm
У нас выполнены все требования для запуска ProxySQL, но сервис не запускается автоматически после установки, поэтому запускаем его вручную:
# sudo systemctl start proxysqlТеперь ProxySQL должен работать с конфигурацией по умолчанию. Мы можем проверить это, выполнив эту команду:
# systemctl status proxysqlВывод процесса ProxySQL в активном состоянии должен быть примерно таким:
proxysql.service - High Performance Advanced Proxy for MySQL
Loaded: loaded (/etc/systemd/system/proxysql.service; enabled; vendor...
Active: active (running) since Sun 2021-05-23 18:50:28 UTC; 15s ago
Process: 1422 ExecStart=/usr/bin/proxysql --idle-threads -c /etc/proxysql...
Main PID: 1425 (proxysql)
CGroup: /system.slice/proxysql.service
├─1425 /usr/bin/proxysql --idle-threads -c /etc/proxysql.cnf
└─1426 /usr/bin/proxysql --idle-threads -c /etc/proxysql.cnf
May 23 18:50:27 vinicius-grippa-node3 systemd[1]: Starting High Performance...
May 23 18:50:27 vinicius-grippa-node3 proxysql[1422]: 2021-05-23 18:50:27...
May 23 18:50:27 vinicius-grippa-node3 proxysql[1422]: 2021-05-23 18:50:27...
May 23 18:50:27 vinicius-grippa-node3 proxysql[1422]: 2021-05-23 18:50:27...
May 23 18:50:28 vinicius-grippa-node3 systemd[1]: Started High Performance...
ProxySQL отделяет интерфейс приложения от интерфейса администратора. Это означает, что ProxySQL будет прослушивать два сетевых порта: интерфейс администратора будет прослушивать 6032, а приложение будет прослушивать 6033 (чтобы было легче запомнить, это обратный порт MySQL по умолчанию, 3306).
Затем ProxySQL необходимо связаться с узлами MySQL, чтобы проверить их состояние. Для этого ProxySQL необходимо подключиться к каждому серверу с выделенным пользователем.
Во-первых, мы собираемся создать пользователя на исходном сервере. Подключитесь к исходному экземпляру MySQL и выполните следующие команды:
mysql> CREATE USER 'proxysql'@'%' IDENTIFIED by '$3Kr$t';
mysql> GRANT USAGE ON *.* TO 'proxysql'@'%';
Далее мы настроим параметры ProxySQL для распознавания пользователя. Сначала подключаемся к ProxySQL:
# mysql -uadmin -padmin -h 127.0.0.1 -P 6032А затем задаем параметры:
proxysql> UPDATE global_variables SET variable_value='proxysql'
-> WHERE variable_name='mysql-monitor_username';
proxysql> UPDATE global_variables SET variable_value='$3Kr$t'
-> WHERE variable_name='mysql-monitor_password';
proxysql> LOAD MYSQL VARIABLES TO RUNTIME;
proxysql> SAVE MYSQL VARIABLES TO DISK;
Теперь, когда мы установили пользователя в базе данных и ProxySQL, пришло время сообщить ProxySQL, какие серверы MySQL присутствуют в топологии:
proxysql> INSERT INTO mysql_servers(hostgroup_id, hostname, port)
-> VALUES (10,'10.124.33.5',3306);
proxysql> INSERT INTO mysql_servers(hostgroup_id, hostname, port)
-> VALUES (11,'10.124.33.169',3306);
proxysql> INSERT INTO mysql_servers(hostgroup_id, hostname, port)
-> VALUES (11,'10.124.33.130',3306);
proxysql> LOAD MYSQL SERVERS TO RUNTIME;
proxysql> SAVE MYSQL SERVERS TO DISK;
Следующий шаг — определить, кто входит в группу записи и чтения. Серверы, присутствующие в группе записи, смогут получать операции DML, а запросы SELECT будут использовать серверы в группе чтения. В этом примере группа хостов 10 будет записывающим устройством, а группа хостов 11 будет читающим устройством:
proxysql> INSERT INTO mysql_replication_hostgroups
-> (writer_hostgroup, reader_hostgroup) VALUES (10, 11);
proxysql> LOAD MYSQL SERVERS TO RUNTIME;
proxysql> SAVE MYSQL SERVERS TO DISK;
Далее, у ProxySQL должны быть пользователи, которые могут получить доступ к внутренним узлам для управления соединениями. Давайте создадим пользователя на внутреннем исходном сервере:
mysql> CREATE USER 'app'@'%' IDENTIFIED by '$3Kr$t';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'app'@'%';
А теперь настроим ProxySQL с пользователем:
proxysql> INSERT INTO mysql_users (username,password,default_hostgroup)
-> VALUES ('app','$3Kr$t',10);
proxysql> LOAD MYSQL USERS TO RUNTIME;
proxysql> SAVE MYSQL USERS TO DISK;
Следующий шаг самый захватывающий, потому что именно здесь мы определяем правила. Правила сообщат ProxySQL, куда отправлять запросы на запись и чтение, балансируя нагрузку на серверы:
proxysql> INSERT INTO mysql_query_rules
-> (rule_id,username,destination_hostgroup,active,match_digest,apply)
-> VALUES(1,'app',10,1,'^SELECT.*FOR UPDATE',1);
proxysql> INSERT INTO mysql_query_rules
-> (rule_id,username,destination_hostgroup,active,match_digest,apply)
-> VALUES(2,'app',11,1,'^SELECT ',1);
proxysql> LOAD MYSQL QUERY RULES TO RUNTIME;
proxysql> SAVE MYSQL QUERY RULES TO DISK;
ProxySQL имеет поток, отвечающий за подключение к каждому серверу, указанному в таблице mysql_servers, и проверку значения переменной read_only. Предположим, что реплика отображается в группе записи, например:
proxysql> SELECT * FROM mysql_servers;
+--------------+---------------+------+-----------+...
| hostgroup_id | hostname | port | gtid_port |...
+--------------+---------------+------+-----------+...
| 10 | 10.124.33.5 | 3306 | 0 |...
| 11 | 10.124.33.169 | 3306 | 0 |...
| 11 | 10.124.33.130 | 3306 | 0 |...
+--------------+---------------+------+-----------+...
...+--------------+---------------+------+-----------+
...| status | weight | compression | max_connections |...
...+--------+--------+-------------+-----------------+...
...| ONLINE | 1 | 0 | 1000 |...
...| ONLINE | 1 | 0 | 1000 |...
...| ONLINE | 1 | 0 | 1000 |...
...+--------+--------+-------------+-----------------+...
...+---------------------+---------+----------------+---------+
...| max_replication_lag | use_ssl | max_latency_ms | comment |
...+---------------------+---------+----------------+---------+
...| 0 | 0 | 0 | |
...| 0 | 0 | 0 | |
...| 0 | 0 | 0 | |
...+---------------------+---------+----------------+---------+
3 rows in set (0.00 sec)
Поскольку мы не хотим, чтобы ProxySQL записывала данные на серверы-реплики, что могло бы привести к несогласованности данных, нам нужно установить опцию read_only на серверах-репликах, чтобы эти серверы обслуживали только запросы на чтение.
mysql> SET GLOBAL read_only=1;Теперь мы готовы использовать наше приложение. Выполнение следующей команды должно вернуть имя хоста, с которого ProxySQL подключился:
$ mysql -uapp -p'$3Kr$t' -h 127.0.0.1 -P 6033 -e "select @@hostname;"
+-----------------------+
| @@hostname |
+-----------------------+
| vinicius-grippa-node1 |
+-----------------------+
ProxySQL имеет гораздо больше возможностей и гибкости, чем мы показали здесь; наша цель в этом разделе состояла в том, чтобы просто представить инструмент, чтобы вы знали об этом параметре при выборе архитектуры.
Балансировщик нагрузки HAProxy
HAProxy расшифровывается как High Availability Proxy (прокси высокой доступности) и представляет собой балансировщик нагрузки TCP/HTTP. Он распределяет рабочую нагрузку по набору серверов, чтобы максимизировать производительность и оптимизировать использование ресурсов.
Чтобы расширить ваши знания об архитектуре MySQL и различных топологиях, в этом разделе мы настроим Percona XtraDB Cluster (Galera Cluster) с HAProxy вместо классической топологии репликации.
Варианты архитектуры аналогичны ProxySQL. HAProxy можно разместить вместе с приложением или в промежуточном слое. На рисунке 15-3 показан пример, когда HAProxy размещается на том же сервере, что и приложение.

Рисунок 15-3. HAProxy вместе с приложением
А на рисунке 15-4 показана топология с HAProxy на промежуточном уровне.

Рисунок 15-4. HAProxy на промежуточном уровне, работающем на выделенных серверах
Опять же, это архитектуры с разными плюсами и минусами. Пока в первом у нас нет лишнего хопа (что снижает латентность), мы добавляем дополнительную нагрузку на сервер приложений. Также вам необходимо настроить HAProxy на каждом сервере приложений.
С другой стороны, наличие HAProxy на промежуточном уровне упрощает управление и повышает доступность, поскольку приложение может подключаться к любому серверу HAProxy. Однако дополнительный переход увеличивает задержку.
Установка и настройка HAProxy
Распространенные операционные системы, такие как Red Hat/CentOS и Debian/Ubuntu, предоставляют пакет HAProxy, и вы можете установить его с помощью диспетчера пакетов. Процесс установки относительно прост.
Для Debian или Ubuntu используйте следующие команды:
# apt update
# apt install haproxy
Для Red Hat или CentOS используйте:
# sudo yum update
# sudo yum install haproxy
После установки HAProxy установит путь по умолчанию для файла конфигурации как /etc/haproxy/haproxy.cfg.
Перед запуском HAProxy нам нужно его настроить. Для этой демонстрации в нашем первом сценарии HAProxy будет расположен на том же сервере, что и приложение. Вот IP-адреса нашего трехузлового кластера Galera:
172.16.3.45/Port:3306
172.16.1.72/Port:3306
172.16.0.161/Port:3306
Давайте откроем наш файл /etc/haproxy/haproxy.cfg и посмотрим на него. Есть много параметров для настройки, разделенных на три раздела:
global-
Раздел в файле конфигурации для параметров всего процесса.
defaults-
Раздел в файле конфигурации для параметров по умолчанию
listen-
Раздел в конфигурационном файле, определяющий полный прокси, включая его внешние и внутренние части.
В Таблице 15-1 показаны основные параметры HAProxy.
| Параметр | Описание |
|---|---|
balance |
Определяет алгоритм балансировки нагрузки, который будет использоваться в серверной части |
clitimeout |
Устанавливает максимальное время бездействия на стороне клиента |
contimeout |
Устанавливает максимальное время ожидания успешной попытки подключения к серверу |
daemon |
Переводит процесс в фоновый режим (рекомендуемый режим работы) |
gid |
Изменяет идентификатор группы процесса на <number> |
log |
Добавляет глобальный сервер системного журнала |
maxconn |
Устанавливает максимальное количество одновременных подключений для каждого процесса равным <number> |
mode |
Устанавливает режим работы или протокол экземпляра |
option dontlognull |
Отключает регистрацию нулевых подключений |
optiontcplog |
Включает расширенную регистрацию TCP-соединений с состоянием сеанса и таймерами |
Чтобы заставить HAProxy работать, мы будем использовать следующий файл конфигурации на основе наших настроек:
global
log /dev/log local0
log /dev/log local1 notice
maxconn 4096
#debug
#quiet
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
log global
mode http
option tcplog
option dontlognull
retries 3
redispatch
maxconn 2000
contimeout 5000
clitimeout 50000
srvtimeout 50000
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
listen mysql-pxc-cluster 0.0.0.0:3307
mode tcp
bind *:3307
timeout client 10800s
timeout server 10800s
balance roundrobin
option httpchk
server vinicius-grippa-node2 172.16.0.161:3306 check port 9200
inter 12000 rise 3 fall 3
server vinicius-grippa-node1 172.16.1.72:3306 check port 9200 inter 12000
rise 3 fall 3
server vinicius-grippa-default 172.16.3.45:3306 check port 9200
inter 12000 rise 3 fall 3
Чтобы запустить HAProxy, мы используем команду haproxy. Мы можем передать любое количество параметров конфигурации в командной строке. Чтобы использовать файл конфигурации, используйте параметр -f. Например, мы можем передать один файл конфигурации:
# sudo haproxy -f /etc/haproxy/haproxy.cfgили несколько файлов конфигурации:
# sudo haproxy -f /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy-2.cfgили каталог:
# sudo haproxy -f conf-dirВ этой конфигурации HAProxy будет балансировать нагрузку между тремя узлами. В этом случае он проверяет только, прослушивает ли процесс mysqld порт 3306, но не принимает во внимание состояние узла. Таким образом, он может отправлять запросы узлу, на котором работает mysqld, даже если он находится в состоянии JOINING или DISCONNECTED.
Чтобы проверить текущий статус узла, нам нужно что-то более сложное. Эта идея была взята из группы Google Codership.
Для реализации этой настройки нам понадобятся два скрипта:
-
clustercheck, расположенный в /usr/local/bin и конфиг дляxinetd -
mysqlchk, расположенный в /etc/xinetd.d на каждом узле
Оба сценария доступны в виде двоичных файлов и исходных кодов Percona XtraDB.
Измените файл /etc/services, добавив следующую строку для каждого узла:
mysqlchk 9200/tcp # mysqlchkЕсли файл /etc/services не существует, скорее всего, xinetd не установлен.
Чтобы установить его для CentOS/Red Hat, используйте:
# yum install -y xinetdДля Debian/Ubuntu используйте:
# sudo apt-get install -y xinetdДалее нам нужно создать пользователя MySQL, чтобы скрипт мог проверить работоспособность узла. В идеале из соображений безопасности этот пользователь должен иметь минимальные необходимые привилегии:
mysql> CREATE USER 'clustercheckuser'@'localhost' IDENTIFIED BY 'clustercheckpassword!';
-> GRANT PROCESS ON *.* TO 'clustercheckuser'@'localhost';
Чтобы проверить, как наш узел работает при проверке работоспособности, мы можем запустить следующую команду и посмотреть результат:
# /usr/bin/clustercheck
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 40
Percona XtraDB Cluster Node is synced.
Если мы сделаем это для всех узлов, мы будем готовы проверить, работает ли наша установка HAProxy. Самый простой способ сделать это — подключиться к нему и выполнить некоторые команды MySQL. Давайте запустим команду, которая извлекает имя хоста, с которого мы подключены:
# mysql -uroot -psecret -h 127.0.0.1 -P 3307 -e "select @@hostname"
+-----------------------+
| @@hostname |
+-----------------------+
| vinicius-grippa-node1 |
+-----------------------+
Запуск этого во второй раз дает нам:
# mysql -uroot -psecret -h 127.0.0.1 -P 3307 -e "select @@hostname"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-----------------------+
| @@hostname |
+-----------------------+
| vinicius-grippa-node2 |
+-----------------------+
И в третий раз получаем:
# mysql -uroot -psecret -h 127.0.0.1 -P 3307 -e "select @@hostname"
mysql: [Warning] Using a password on the command line interface can be insecure.
+-------------------------+
| @@hostname |
+-------------------------+
| vinicius-grippa-default |
+-------------------------+
Как вы можете видеть, наш HAProxy подключается в циклическом режиме. Если мы отключим один из узлов, HAProxy будет маршрутизировать только к оставшимся.
MySQL Router
MySQL Router отвечает за распределение трафика между членами кластера InnoDB. Это похожее на прокси решение для сокрытия топологии кластера от приложений, поэтому приложениям не нужно знать, какой член кластера является основным узлом, а какой — вторичным. Обратите внимание, что MySQL Router не будет работать с кластерами Galera; он был разработан только для InnoDB Cluster.
MySQL Router способен выполнять разделение чтения/записи, предоставляя различные интерфейсы. Обычная настройка состоит в том, чтобы иметь один интерфейс чтения/записи и один интерфейс только для чтения. Это поведение по умолчанию, которое также предоставляет два аналогичных интерфейса для использования X Protocol (используемого для операций CRUD и асинхронных вызовов).
Разделение чтения/записи выполняется с использованием концепции ролей: первичная для записи и вторичная для чтения. Это аналогично тому, как называются члены кластера. Кроме того, каждый интерфейс предоставляется через порт TCP, поэтому приложениям нужно знать только комбинацию IP:порт, используемую для записи, и комбинацию, используемую для чтения. Затем MySQL Router позаботится о подключениях к членам кластера в зависимости от типа трафика на сервер.
При работе в производственной среде экземпляры сервера MySQL, составляющие InnoDB Cluster, работают на нескольких хост-машинах как часть сети, а не на одной машине. Таким образом, как и в случае с ProxySQL и HAProxy, MySQL Router может быть средним уровнем в архитектуре.
На рисунке 15-5 показано, как работает производственный сценарий.

Рисунок 15-5. Производственное развертывание MySQL InnoDB Cluster
Теперь, чтобы начать наш пример, давайте посмотрим на членов MySQL, которые являются частью InnoDB Cluster:
mysql> SELECT member_host, member_port, member_state, member_role
-> FROM performance_schema.replication_group_members;
+--------------+-------------+--------------+-------------+
| member_host | member_port | member_state | member_role |
+--------------+-------------+--------------+-------------+
| 172.16.3.9 | 3306 | ONLINE | SECONDARY |
| 172.16.3.127 | 3306 | ONLINE | SECONDARY |
| 172.16.3.120 | 3306 | ONLINE | PRIMARY |
+--------------+-------------+--------------+-------------+
3 rows in set (0.00 sec)
mysql> SELECT cluster_name FROM mysql_innodb_cluster_metadata.clusters;
+--------------+
| cluster_name |
+--------------+
| cluster1 |
+--------------+
1 row in set (0.00 sec)
Теперь, когда у нас есть конфигурация узлов MySQL и имя кластера, мы можем приступить к настройке MySQL Router. В целях повышения производительности рекомендуется настроить MySQL Router в том же месте, что и приложение, предположим, что у нас есть экземпляр для каждого сервера приложений, поэтому мы разместим наш маршрутизатор на сервере приложений. Во-первых, мы собираемся определить версию MySQL Router, совместимую с нашей ОС:
# cat /etc/*release
CentOS Linux release 7.9.2009 (Core)
Теперь мы проверим страницу загрузки и установим ее с помощью yum:
# yum install -y https://dev.mysql.com/get/Downloads/MySQL-Router/mysql-
router-community-8.0.23-1.el7.x86_64.rpm
Loaded plugins: fastestmirror
mysql-router-community-8.0.23-1.el7.x86_64.rpm
Examining /var/tmp/yum-root-_ljdTQ/mysql-router-community-8.0.23-1.el7.x
86_64.rpm: mysql-router-community-8.0.23-1.el7.x86_64
Marking /var/tmp/yum-root-_ljdTQ/mysql-router-community-8.0.23-1.el7.x86
_64.rpm to be installed
Resolving Dependencies
--> Running transaction check
...
Running transaction
Installing : mysql-router-community-8.0.23-1.el7.x86_64
1/1
Verifying : mysql-router-community-8.0.23-1.el7.x86_64
1/1
Installed:
mysql-router-community.x86_64 0:8.0.23-1.el7
Complete!
Теперь, когда MySQL Router установлен, нам нужно создать специальный каталог для его работы:
# mkdir /var/lib/mysqlrouterДалее мы собираемся загрузить MySQL Router. Начальная загрузка настроит маршрутизатор для работы с MySQL InnoDB Cluster:
# mysqlrouter --bootstrap root@172.16.3.120:3306 \
--directory /var/lib/mysqlrouter --conf-use-sockets \
--account app_router --account-create always \
--user=mysql
Please enter MySQL password for root:
# Bootstrapping MySQL Router instance at '/var/lib/mysqlrouter'...
Please enter MySQL password for app_router:
- Creating account(s)
- Verifying account (using it to run SQL queries that would be run by Router)
- Storing account in keyring
- Adjusting permissions of generated files
- Creating configuration /var/lib/mysqlrouter/mysqlrouter.conf
...
## MySQL Classic protocol
- Read/Write Connections: localhost:6446, /var/lib/mysqlrouter/mysql.sock
- Read/Only Connections: localhost:6447, /var/lib/mysqlrouter/mysqlro.sock
## MySQL X protocol
- Read/Write Connections: localhost:64460, /var/lib/mysqlrouter/mysqlx.sock
- Read/Only Connections: localhost:64470, /var/lib/mysqlrouter/mysqlxro.sock
В командной строке мы говорим маршрутизатору подключиться к пользователю root на нашем основном сервере (172.16.3.120) через порт 3306. Мы также говорим маршрутизатору создать файл сокета, чтобы мы могли подключиться с его помощью. Наконец, мы создаем нового пользователя (app_router) для использования в нашем приложении.
Давайте посмотрим на содержимое, созданное процессом начальной загрузки в нашем каталоге конфигурации (/var/lib/mysqlrouter):
# ls -l | awk '{print $9}'
data
log
mysqlrouter.conf
mysqlrouter.key
run
start.sh
stop.sh
Сгенерированный файл конфигурации MySQL Router (mysqlrouter.conf) выглядит примерно так:
# cat mysqlrouter.conf
# File automatically generated during MySQL Router bootstrap
[DEFAULT]
user=mysql
logging_folder=/var/lib/mysqlrouter/log
runtime_folder=/var/lib/mysqlrouter/run
...
[rest_routing]
require_realm=default_auth_realm
[rest_metadata_cache]
require_realm=default_auth_realm
В этом примере MySQL Router настроил четыре порта (два порта для чтения/записи с использованием обычного протокола MySQL и два порта для чтения/записи с использованием X Protocol) и четыре сокета. Порты добавляются по умолчанию, а сокеты были добавлены, потому что мы передали --conf-use-sockets. InnoDB Cluster с именем cluster1 является источником метаданных, а адресаты используют кэш метаданных InnoDB Cluster для динамической настройки информации о хосте.
Выполнив сценарий start.sh, мы можем запустить демон MySQL Router:
# ./start.sh
# PID 1684 written to '/var/lib/mysqlrouter/mysqlrouter.pid' logging facility initialized, switching logging to loggers specified in configuration
Теперь мы можем наблюдать за ходом процесса:
# ps -ef | grep -i mysqlrouter
root 1683 1 0 17:36 pts/0 00:00:00 sudo
ROUTER_PID=/var/lib/mysqlrouter/mysqlrouter.pid /usr/bin/mysqlrouter -c /var/lib/mysqlrouter/mysqlrouter.conf --user=mysql
mysql 1684 1683 0 17:36 pts/0 00:00:17 /usr/bin/mysqlrouter -c /var/lib/mysqlrouter/mysqlrouter.conf --user=mysql
root 1733 1538 0 17:41 pts/0 00:00:00 grep --color=auto -i mysqlrouter
И открываются порты:
# netstat -tulnp | grep -i mysqlrouter
tcp 0 0 0.0.0.0:64470 0.0.0.0:* LISTEN 1684/mysqlrouter
tcp 0 0 0.0.0.0:8443 0.0.0.0:* LISTEN 1684/mysqlrouter
tcp 0 0 0.0.0.0:64460 0.0.0.0:* LISTEN 1684/mysqlrouter
tcp 0 0 0.0.0.0:6446 0.0.0.0:* LISTEN 1684/mysqlrouter
tcp 0 0 0.0.0.0:6447 0.0.0.0:* LISTEN 1684/mysqlrouter
Мы настроили MySQL Router с InnoDB Cluster, так что теперь мы можем протестировать это с соединениями для чтения и чтения/записи. Сначала подключимся к порту записи (6446):
# mysql -uroot -psecret -h 127.0.0.1 -P 6446 \
-e "create database learning_mysql;"
# mysql -uroot -psecret -h 127.0.0.1 -P 6446 \
-e "use learning_mysql; select database()"
+----------------+
| database() |
+----------------+
| learning_mysql |
+----------------+
Как видите, в порту записи можно выполнять как чтение, так и запись.
Теперь мы проверим порт чтения (6447) с помощью оператора SELECT:
# mysql -uroot -psecret -h 127.0.0.1 -P 6447 \
-e "use learning_mysql; select database()"
+----------------+
| database() |
+----------------+
| learning_mysql |
+----------------+
Это работает, но давайте попробуем выполнить запись:
# mysql -uroot -psecret -h 127.0.0.1 -P 6447 \
-e "create database learning_mysql_write;"
ERROR 1290 (HY000) at line 1: The MySQL server is running with the --super-read-only option so it cannot execute this statement
Таким образом, порт чтения принимает только чтение. Также можно увидеть, как маршрутизатор балансирует нагрузку при чтении:
# mysql -uroot -psecret -h 127.0.0.1 -P 6447 -e "select @@hostname"
+-----------------------+
| @@hostname |
+-----------------------+
| vinicius-grippa-node1 |
+-----------------------+
# mysql -uroot -psecret -h 127.0.0.1 -P 6447 -e "select @@hostname"
insecure.
+-----------------------+
| @@hostname |
+-----------------------+
| vinicius-grippa-node2 |
+-----------------------+
Таким образом, если в одном из узлов MySQL произойдет какое-либо время простоя, MySQL Router направит запросы на оставшиеся активные узлы.
Глава 16
Разные темы
Идея этой главы состоит в том, чтобы выйти за рамки устранения неполадок в запросе, перегруженной системе или настройке различных топологий MySQL. Мы хотим показать вам арсенал инструментов, доступных для вас, чтобы упростить повседневные задачи или исследовать сложные проблемы. Начнем с MySQL Shell.
MySQL Shell
MySQL Shell — это продвинутый клиент и редактор кода для MySQL. Он расширяет функциональность традиционного клиента MySQL, с которым работало большинство администраторов баз данных в MySQL 5.6 и 5.7. MySQL Shell поддерживает такие языки программирования, как Python, JavaScript и SQL. Он также расширяет функциональные возможности с помощью синтаксиса команд API. Например, можно настроить сценарии для администрирования кластера InnoDB. Из MySQL Shell вы также можете запускать и настраивать экземпляры песочницы MySQL.
Установка оболочки MySQL
Для поддерживаемых дистрибутивов Linux самый простой способ установить MySQL Shell — использовать репозиторий MySQL yum или apt. Давайте посмотрим, как установить его на Ubuntu и CentOS.
Установка MySQL Shell на Ubuntu 20.04 Focal Fossa
Установка MySQL Shell в Ubuntu относительно проста, поскольку она является частью обычных репозиториев.
Во-первых, нам нужно настроить репозиторий MySQL. Мы можем использовать эти команды для загрузки репозитория apt на наш сервер и его установки:
# wget https://dev.mysql.com/get/mysql-apt-config_0.8.16-1_all.deb
# dpkg -i mysql-apt-config_0.8.16-1_all.deb
После установки обновите информацию о нашем пакете:
# apt-get updateЗатем выполните команду установки, чтобы установить MySQL Shell:
# apt-get install mysql-shellТеперь мы можем запустить MySQL Shell с помощью командной строки:
# mysqlsh
MySQL Shell 8.0.23
Copyright (c) 2016, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
MySQL JS >
Установка MySQL Shell на CentOS 8
Чтобы установить MySQL Shell в CentOS 8, мы выполняем те же шаги, что и для Ubuntu, но сначала нам нужно убедиться, что пакет MySQL по умолчанию, присутствующий в CentOS 8, отключен:
# yum remove mysql-community-release -y
No match for argument: mysql-community-release
No packages marked for removal.
Dependencies resolved.
Nothing to do.
Complete!
# dnf erase mysql-community-release
No match for argument: mysql-community-release
No packages marked for removal.
Dependencies resolved.
Nothing to do.
Complete!
Далее мы собираемся настроить наш репозиторий yum. Нам нужно скачать правильную версию, соответствующую версии ОС со страницы загрузки:
# yum install \
https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm -y
После установки репозитория мы установим бинарный файл MySQL Shell:
# yum install mysql-shell -yИ мы можем убедиться, что установка работает, запустив ее:
# mysqlsh
MySQL Shell 8.0.23
Copyright (c) 2016, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates.
Other names may be trademarks of their respective owners.
Type '\help' or '\?' for help; '\quit' to exit.
MySQL JS >
Развертывание изолированного кластера InnoDB с помощью MySQL Shell
MySQL Shell автоматизирует развертывание экземпляров песочницы с помощью AdminAPI, который предоставляет команду dba.deploySandboxInstance(port_number).
По умолчанию экземпляры песочницы размещаются в каталоге с именем $HOME/mysql-sandboxes/port. Давайте посмотрим, как изменить каталог:
# mkdir /var/lib/sandboxes
# mysqlsh
MySQL JS > shell.options.sandboxDir='/var/lib/sandboxes'
/var/lib/sandboxes
Предпосылкой для развертывания экземпляра песочницы является установка двоичных файлов MySQL. При необходимости просмотрите главу 1 для получения подробной информации. Вам нужно будет ввести пароль для пользователя root, чтобы завершить развертывание:
MySQL JS > dba.deploySandboxInstance(3310)
A new MySQL sandbox instance will be created on this host in
/var/lib/sandboxes/3310
Warning: Sandbox instances are only suitable for deploying and
running on your local machine for testing purposes and are not
accessible from external networks.
Please enter a MySQL root password for the new instance: ******
Deploying new MySQL instance...
Instance localhost:3310 successfully deployed and started.
Use shell.connect('root@localhost:3310') to connect to the instance.
Мы собираемся развернуть еще два экземпляра:
MySQL JS > dba.deploySandboxInstance(3320)
MySQL JS > dba.deploySandboxInstance(3330)
Следующим шагом является создание кластера InnoDB при подключении к начальному экземпляру MySQL Server. Исходный экземпляр — это экземпляр, к которому мы подключены через MySQL Shell и который мы хотим реплицировать на другие экземпляры. В этом примере все экземпляры песочницы являются пустыми экземплярами, поэтому мы можем выбрать любой экземпляр. В производственной настройке начальным экземпляром будет тот, который содержит существующий набор данных для репликации на другие экземпляры в кластере.
Мы используем эту команду для подключения MySQL Shell к начальному экземпляру, в данном случае к порту 3310:
MySQL JS > \connect root@localhost:3310
Creating a session to root@localhost:3310
Please provide the password for root@localhost:3310:
Save password for root@localhost:3310? [Y]es/[N]o/Ne[v]er (default No): Y
Fetching schema names for autocompletion... Press ^C to stop.
Your MySQL connection id is 12
Server version: 8.0.21 Source distribution
No default schema selected; type \use <schema> to set one.
Впоследствии мы будем использовать метод createCluster() для создания InnoDB Cluster с текущим подключенным экземпляром в качестве исходного:
MySQL localhost:3310 ssl JS > var cluster = dba.createCluster('learning_mysql')
A new InnoDB cluster will be created on instance 'localhost:3310'.
Validating instance configuration at localhost:3310...
NOTE: Instance detected as a sandbox.
Please note that sandbox instances are only suitable for deploying test clusters
for use within the same host.
This instance reports its own address as 127.0.0.1:3310
Instance configuration is suitable.
NOTE: Group Replication will communicate with other members using
'127.0.0.1:33101'. Use the localAddress option to override.
Creating InnoDB cluster 'learning_mysql' on '127.0.0.1:3310'...
Adding Seed Instance...
Cluster successfully created. Use Cluster.addInstance() to add MySQL instances.
At least 3 instances are needed for the cluster to be able to withstand up to
one server failure.
Как видно из выходных данных, три экземпляра способны поддерживать базу данных в оперативном режиме при отказе одного сервера, поэтому мы развернули три экземпляра песочницы.
Следующим шагом является добавление вторичных экземпляров в наш learning_mysql InnoDB Cluster. Любые транзакции, которые были выполнены начальным экземпляром, повторно выполняются каждым вторичным экземпляром по мере его добавления.
Исходный экземпляр в этом примере был недавно создан, поэтому он почти пуст. Следовательно, необходимо реплицировать небольшое количество данных из исходного экземпляра во вторичные экземпляры. Если необходимо реплицировать данные, MySQL будет использовать плагин клонирования (обсуждаемый в разделе «Создание реплики с помощью плагина Clone») для автоматической настройки экземпляров.
Давайте добавим один вторичный объект, чтобы увидеть процесс в действии. Чтобы добавить второй экземпляр в кластер InnoDB:
MySQL localhost:3310 ssl JS > cluster.addInstance('root@localhost:3320')
...
* Waiting for clone to finish...
NOTE: 127.0.0.1:3320 is being cloned from 127.0.0.1:3310
** Stage DROP DATA: Completed
** Clone Transfer
FILE COPY ############################################################
100% Completed
PAGE COPY ############################################################
100% Completed
REDO COPY ############################################################
100% Completed
NOTE: 127.0.0.1:3320 is shutting down...
* Waiting for server restart... ready
* 127.0.0.1:3320 has restarted, waiting for clone to finish...
** Stage RESTART: Completed
* Clone process has finished: 59.62 MB transferred in about 1 second
(~59.62 MB/s)
State recovery already finished for '127.0.0.1:3320'
The instance '127.0.0.1:3320' was successfully added to the cluster
Затем добавьте третий экземпляр:
MySQL localhost:3310 ssl JS > cluster.addInstance('root@localhost:3320')На данный момент мы создали кластер с тремя экземплярами: первичным и двумя вторичными. Мы можем увидеть статус, выполнив следующую команду:
MySQL localhost:3310 ssl JS > cluster.status()
{
"clusterName": "learning_mysql",
"defaultReplicaSet": {
"name": "default",
"primary": "127.0.0.1:3310",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"127.0.0.1:3310": {
"address": "127.0.0.1:3310",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.21"
},
"127.0.0.1:3320": {
"address": "127.0.0.1:3320",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.21"
},
"127.0.0.1:3330": {
"address": "127.0.0.1:3330",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.21"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "127.0.0.1:3310"
Предполагая, что MySQL Router уже установлен (см. «MySQL Router»), единственным необходимым шагом является его загрузка с указанием местоположения сервера метаданных InnoDB Cluster.
Мы наблюдаем загрузку маршрутизатора:
# mysqlrouter --bootstrap root@localhost:3310 --user=mysqlrouter
Please enter MySQL password for root:
# Bootstrapping system MySQL Router instance...
- Creating account(s) (only those that are needed, if any)
...
## MySQL Classic protocol
- Read/Write Connections: localhost:6446
- Read/Only Connections: localhost:6447
...
Утилиты MySQL Shell
Как мы уже говорили, MySQL Shell — это мощный продвинутый клиент и редактор кода для MySQL. Среди его многочисленных функций есть утилиты для создания логического дампа и логического восстановления всего экземпляра базы данных, включая пользователей. Преимущество, по сравнению, например, с mysqldump, заключается в том, что утилита обладает возможностью распараллеливания, что значительно повышает скорость дампа и восстановления.
Вот утилиты для выполнения процесса дампа и восстановления:
util.dumpInstance()-
Дамп всего экземпляра базы данных, включая пользователей
util.dumpSchemas()-
Дамп набора схем
util.loadDump()-
Загрузка дампа в целевую базу данных
util.dumpTables()-
Загрузить определенные таблицы и представления
Давайте подробнее рассмотрим каждый из них по очереди.
util.dumpInstance()
Утилита dumpInstance() создаст дамп всех баз данных, присутствующих в каталоге данных MySQL (см. «Содержимое каталога MySQL»). Она исключит схемы information_schema, mysql_, ndbinfo, performance_schema и sys при создании дампа.
Существует также опция пробного запуска, которая позволяет вам проверять схемы и просматривать проблемы совместимости, а затем запускать дамп с соответствующими параметрами совместимости, применяемыми для устранения проблем. Давайте попробуем это сейчас — мы рассмотрим возможные ошибки и посмотрим варианты утилиты дампа.
Чтобы запустить дамп, выполните следующую команду:
MySQL JS > shell.connect('root@localhost:48008');
MySQL localhost:48008 ssl JS > util.dumpInstance("/backup",
> {ocimds: true, compatibility:
dryRun: true})
Acquiring global read lock
Global read lock acquired
Gathering information - done
All transactions have been started
Locking instance for backup
...
NOTE: Database test had unsupported ENCRYPTION option commented out
ERROR: Table 'test'.'sbtest1' uses unsupported storage engine MyISAM
(fix this with 'force_innodb' compatibility option)
Compatibility issues with MySQL Database Service 8.0.23 were found.
Please use the 'compatibility' option to apply compatibility adaptations
to the dumped DDL.
Util.dumpInstance: Compatibility issues were found (RuntimeError)
Если для параметра ocimds задано значение true, утилита дампа проверит словарь данных и индексный словарь. Параметры шифрования в операторах CREATE TABLE закомментированы в файлах DDL, чтобы гарантировать, что все таблицы расположены в каталоге данных MySQL и используют шифрование схемы по умолчанию. strip_restricted_grants удаляет определенные привилегии, ограниченные службой базы данных MySQL, которые могут вызвать ошибку в процессе создания пользователя. dryRun (пробный запуск) не требует пояснений: он выполнит только проверку, и никакие данные фактически не будут сброшены.
Итак, у нас есть таблица MyISAM в базе данных test. Опция пробного запуска явно выдает ошибку.
Чтобы исправить эту ошибку, мы собираемся использовать параметр force_innodb, который преобразует все неподдерживаемые механизмы в InnoDB в операторе CREATE TABLE:
MySQL localhost:48008 ssl JS > util.dumpInstance("backup",
> {ocimds: true, compatibility:
> ["strip_restricted_grants","force_innodb"],
dryRun: true})
Теперь пробный прогон не выдает никаких ошибок, и исключений нет. Давайте запустим команду dumpInstance(), чтобы сделать резервную копию экземпляра. Целевой каталог должен быть пустым перед экспортом. Если каталог еще не существует в своем родительском каталоге, утилита создает его.
Мы собираемся обрабатывать дамп параллельно. Для этого мы будем использовать опцию threads и установим значение 10 потоков:
MySQL localhost:48008 ssl JS > util.dumpInstance("/backup",
> {ocimds: true, compatibility:
> ["strip_restricted_grants","force_innodb"],
> threads : 10 })
Если мы посмотрим на последнюю часть вывода, то увидим:
1 thds dumping - 100% (10.00K rows / ~10.00K rows), 0.00 rows/s, 0.00 B/s uncompressed, 0.00 B/s
uncompressed
Duration: 00:00:00s
Schemas dumped: 1
Tables dumped: 10
Uncompressed data size: 1.88 MB
Compressed data size: 598.99 KB
Compression ratio: 3.1
Rows written: 10000
Bytes written: 598.99 KB
Average uncompressed throughput: 1.88 MB/s
Average compressed throughput: 598.99 KB/s
Если бы мы использовали mysqldump, у нас был бы один файл. Как мы видим здесь, в каталоге резервных копий есть несколько файлов:
@.done.json
@.json
@.post.sql
@.sql
test.json
test@sbtest10@@0.tsv.zst
test@sbtest10@@0.tsv.zst.idx
test@sbtest10.json
test@sbtest10.sql
...
test@sbtest1@@0.tsv.zst
test@sbtest1@@0.tsv.zst.idx
test@sbtest1.json
test@sbtest1.sql
test@sbtest9@@0.tsv.zst
test@sbtest9@@0.tsv.zst.idx
test@sbtest9.json
test@sbtest9.sql
test.sql
Давайте посмотрим на них:
-
Файл @.json содержит сведения о сервере и списки пользователей, имена баз данных и их наборы символов.
-
Файлы @.post.sql и @.sql содержат сведения о версии MySQL Server.
-
Файл test.json содержит имена представлений, хранимых процедур и функций, а также список таблиц.
-
Файл @.users.sql (не показан) содержит список пользователей базы данных.
-
Файл test@sbtest10.json содержит имена столбцов и наборы символов. Для каждой выгруженной таблицы будет файл с таким же именем.
-
Файл test@sbtest1.sql содержит структуру таблицы. Будет по одному для каждой сброшенной таблицы.
-
Файл test@sbtest10@@0.tsv.zst является двоичным файлом. Он хранит данные. Для каждой выгруженной таблицы будет файл с таким же именем.
-
Файл test@sbtest10@@0.tsv.zst.idx представляет собой двоичный файл. Он хранит статистику индекса таблицы. Для каждой выгруженной таблицы будет файл с таким же именем.
-
Файл @.done.json содержит время окончания резервного копирования и размеры файлов данных в КБ.
-
Файл test.sql содержит инструкцию базы данных.
util.dumpSchemas()
Эта утилита похожа на dumpInstance(), но позволяет указать схемы для дампа. Она поддерживает те же параметры:
MySQL localhost:48008 ssl JS > util.dumpSchemas(["test"],"/backup",
> {ocimds: true, compatibility:
> ["strip_restricted_grants","force_innodb"],
> threads : 10 , dryRun: true})
Если мы хотим указать несколько схем, мы можем сделать это, запустив:
MySQL localhost:48008 ssl JS > util.dumpSchemas(["test","percona",
"learning_mysql"],"/backup",
> {ocimds: true, compatibility:
> ["strip_restricted_grants","force_innodb"],
> threads : 10 , dryRun: true})
util.dumpTables()
Если мы хотим извлечь более детализированные данные, например определенные таблицы, мы можем использовать утилиту dumpTables(). Опять же, большим преимуществом по сравнению с mysqldump является возможность параллельного извлечения данных из MySQL:
MySQL localhost:48008 ssl JS > util.dumpTables("test", [ "sbtest1",
> "sbtest2" ],"/backup",
> {ocimds: true, compatibility:
> ["strip_restricted_grants","force_innodb"],
> threads : 2 , dryRun: true})
util.loadDump(url[, options])
Мы видели все утилиты для извлечения данных, но осталась одна: та, которая загружает данные в MySQL.
Функция loadDump() обеспечивает потоковую передачу данных в удаленное хранилище, параллельную загрузку таблиц или фрагментов таблиц и отслеживание состояния выполнения. Она также предоставляет возможности возобновления и сброса, а также возможность одновременной загрузки во время создания дампа.
Обратите внимание, что эта утилита использует оператор LOAD DATA LOCAL INFILE, поэтому нам необходимо глобально включить параметр local_infile при импорте.
Утилита loadDump() проверяет, установлено ли для системной переменной sql_require_primary_key значение ON, и если да, возвращает ошибку, если в файлах дампа есть таблица без первичного ключа:
MySQL localhost:48008 ssl JS > util.loadDump("/backup",
> {progressFile :"/backup
> restore.json",threads :12})
Последняя часть вывода будет примерно такой:
[Worker006] percona@sbtest7@@0.tsv.zst: Records: 400000 Deleted: 0 Skipped: 0 Warnings: 0
[Worker007] percona@sbtest4@@0.tsv.zst: Records: 400000 Deleted: 0 Skipped: 0 Warnings: 0
[Worker002] percona@sbtest13@@0.tsv.zst: Records: 220742 Deleted: 0 Skipped: 0 Warnings: 0
Executing common postamble SQL
23 chunks (5.03M rows, 973.06 MB) for 23 tables in 3 schemas were loaded in 1 min 24 sec (avg throughput 11.58 MB/s)
0 warnings were reported during the load.
Обязательно ознакомьтесь с предупреждениями, указанными в конце, на случай, если они появятся.
Flame Graphs
Цитируя Брендана Грегга, определение того, почему процессоры заняты, является рутинной задачей для анализа производительности, которая часто включает в себя профилирование трассировки стека (stack traces). Профилирование путем выборки с фиксированной частотой — это грубый, но эффективный способ увидеть, какие пути кода являются горячими (занятыми на ЦП). Обычно это работает путем создания прерывания по времени, которое собирает текущий счетчик программы, адрес функции или всю трассировку стека и переводит их во что-то удобочитаемое при печати сводного отчета. Flame graphs — это тип визуализации выборочных трассировок стека, который позволяет быстро идентифицировать пути горячего кода.
Трассировка стека (также называемая обратной трассировкой стека (stack backtrace или stack traceback)) — это отчет об активных кадрах стека в определенный момент времени во время выполнения программы. Существует множество инструментов для сбора трассировки стека. Эти инструменты также известны как профилировщики процессора (CPU profilers). Профилировщик процессора, который мы собираемся использовать, — perf.
perf — это инструмент профилировщика для систем на базе Linux 2.6+, который абстрагирует аппаратные различия ЦП в измерениях производительности Linux и предоставляет простой интерфейс командной строки. perf основан на интерфейсе perf_events, экспортированном последними версиями ядра Linux.
perf_events — это инструмент наблюдения, ориентированный на события, который помогает решать сложные задачи по повышению производительности и устранению неполадок. Вопросы, на которые можно ответить, включают:
Почему так сильно загружено ядро процессора? Какие пути кода горячие?
Какие пути кода приводят к пропускам кэша 2-го уровня процессора?
Не зависают ли процессоры при вводе-выводе в память?
Какие пути кода выделяют память и в каком объеме?
Что вызывает повторную передачу TCP?
Вызывается ли определенная функция ядра и как часто?
Почему потоки покидают ЦП?
Обратите внимание, что в этой книге мы только поверхностно касаемся возможностей perf. Мы настоятельно рекомендуем посетить веб-сайт Брендана Грегга, который содержит гораздо более подробную информацию о perf и других профилировщиках ЦП.
Для создания графиков пламени (flame graphs) нам нужно начать собирать отчет о трассировке стека с perf на сервере MySQL. Эту операцию необходимо выполнить на хосте MySQL. Соберем данные за 60 секунд:
# perf record -a -g -F99 -p $(pgrep -x mysqld) -- sleep 60;
# perf report > /tmp/perf.report;
# perf script > /tmp/perf.script;
И если мы проверим каталог /tmp, мы увидим файлы perf:
# ls -l /tmp/perf*
-rw-r--r-- 1 root root 502100 Feb 13 22:01 /tmp/perf.report
-rw-r--r-- 1 root root 7303290 Feb 13 22:01 /tmp/perf.script
Следующий шаг не нужно выполнять на хосте MySQL; мы можем скопировать файлы на другой хост Linux или даже на macOS.
Для создания графиков пламени мы можем использовать репозиторий Брендана на GitHub. В этом примере мы клонируем репозиторий Flame Graph в каталог, где находится наш отчет о производительности:
# git clone https://github.com/brendangregg/FlameGraph
# ./FlameGraph/stackcollapse-perf.pl ./perf.script > perf.report.out.folded
# ./FlameGraph/flamegraph.pl ./perf.report.out.folded > perf.report.out.svg
Мы создали файл с именем perf.report.out.svg. Этот файл можно открыть в любом браузере для визуализации. На рисунке 16-1 показан пример графика пламени.

Рисунок 16-1. Пример графа пламени
Графики пламени показывают совокупность образцов по оси X и глубину стека по оси Y. Каждая функция (кадр стека) рисуется в виде прямоугольника, ширина которого зависит от количества выборок; поэтому чем больше полоса, тем больше процессорного времени тратится на эту функцию. Ось X охватывает коллекцию трассировки стека, но не показывает течение времени, поэтому порядок слева направо не имеет особого значения. Порядок выполняется в алфавитном порядке на основе имен функций, от корня до листа каждого стека.
Созданный файл является интерактивным, поэтому мы можем исследовать, на что тратится процессорное время ядра. В предыдущем примере операция INSERT потребляет 44% процессорного времени, как вы можете видеть на рисунке 16.2.

Рисунок 16-2. 44% процессорного времени используется для операции INSERT
Сборка MySQL из исходников
Как объяснялось в главе 1, дистрибутив MySQL доступен для большинства распространенных операционных систем. Некоторые компании также скомпилировали свои собственные версии MySQL (например, Facebook), которые работали на движке RocksDB и интегрировали его в MySQL. RocksDB — это встраиваемое постоянное хранилище ключей и значений для быстрого хранения, которое имеет несколько преимуществ по сравнению с InnoDB в отношении эффективности использования пространства.
Несмотря на свои преимущества, RocksDB не поддерживает репликацию или слой SQL. Это побудило команду Facebook создать MyRocks, проект с открытым исходным кодом, который интегрирует RocksDB в качестве механизма хранения MySQL. С MyRocks можно использовать RocksDB в качестве внутреннего хранилища и при этом пользоваться всеми функциями MySQL. Проект Facebook имеет открытый исходный код и доступен на GitHub.
Еще одним мотивом для компиляции MySQL является возможность настраивать ее сборку. Например, для очень конкретной проблемы мы всегда можем попытаться отладить MySQL, чтобы собрать дополнительную информацию. Для этого нам нужно настроить MySQL с параметром -DWITH_DEBUG=1.
Сборка MySQL для Ubuntu Focal Fossa и процессоров ARM
Поскольку процессоры ARM в настоящее время набирают обороты (особенно благодаря чипу Apple M1), мы покажем вам, как скомпилировать MySQL для Ubuntu Focal Fossa, работающего на ARM.
Во-первых, мы собираемся создать наши каталоги. Мы создадим один каталог для исходного кода, другой для скомпилированных двоичных файлов и третий для библиотеки boost:
# cd /
# mkdir compile
# cd compile/
# mkdir build
# mkdir source
# mkdir boost
# mkdir basedir
# mkdir /var/lib/mysql
Далее нам нужно установить дополнительные пакеты Linux, необходимые для компиляции MySQL:
# apt-get -y install dirmngr
# apt-get update -y
# apt-get -y install cmake
# apt-get -y install lsb-release wget
# apt-get -y purge eatmydata || true
# apt-get -y install psmisc pkg-config
# apt-get -y install libsasl2-dev libsasl2-modules libsasl2-modules-ldap || \
apt-get -y install libsasl2-modules libsasl2-modules-ldap libsasl2-dev
# apt-get -y install dh-systemd || true
# apt-get -y install curl bison cmake perl libssl-dev gcc g++ libaio-dev \
libldap2-dev libwrap0-dev gdb unzip gawk
# apt-get -y install lsb-release libmecab-dev libncurses5-dev libreadline-dev \
libpam-dev zlib1g-dev
# apt-get -y install libldap2-dev libnuma-dev libjemalloc-dev libeatmydata \
libc6-dbg valgrind libjson-perl libsasl2-dev
# apt-get -y install libmecab2 mecab mecab-ipadic
# apt-get -y install build-essential devscripts libnuma-dev
# apt-get -y install cmake autotools-dev autoconf automake build-essential \
devscripts debconf debhelper fakeroot
# apt-get -y install libcurl4-openssl-dev patchelf
# apt-get -y install libeatmydata1
# apt-get install libmysqlclient-dev -y
# apt-get install valgrind -y
Эти пакеты связаны с флагами CMake, которые мы будем запускать. Если мы удалим или добавим определенные флаги, некоторые пакеты не нужно будет устанавливать (например, если мы не хотим компилировать с помощью Valgrind, нам не нужен этот пакет).
Далее мы загрузим исходный код. Для этого воспользуемся репозиторием MySQL на GitHub:
# cd source
# git clone https://github.com/mysql/mysql-server.git
Вывод будет примерно таким:
Cloning into 'mysql-server'...
remote: Enumerating objects: 1639611, done.
remote: Total 1639611 (delta 0), reused 0 (delta 0), pack-reused 1639611
Receiving objects: 100% (1639611/1639611), 3.19 GiB | 42.88 MiB/s, done.
Resolving deltas: 100% (1346714/1346714), done.
Updating files: 100% (32681/32681), done.
Чтобы проверить, какую версию мы будем компилировать, мы можем запустить следующее:
# cd mysql-server/
# git branch
Затем мы перейдем в наш каталог сборки и запустим CMake с выбранными нами флагами:
# cd /compile/build
# cmake ../source/mysql-server/ -DBUILD_CONFIG=mysql_release \
-DCMake_BUILD_TYPE=${CMake_BUILD_TYPE:-RelWithDebInfo} \
-DWITH_DEBUG=1 \
-DFEATURE_SET=community \
-DENABLE_DTRACE=OFF \
-DWITH_SSL=system \
-DWITH_ZLIB=system \
-DCMake_INSTALL_PREFIX="/compile/basedir/" \
-DINSTALL_LIBDIR="lib/" \
-DINSTALL_SBINDIR="bin/" \
-DWITH_INNODB_MEMCACHED=ON \
-DDOWNLOAD_BOOST=1 \
-DWITH_VALGRIND=1 \
-DINSTALL_PLUGINDIR="plugin/" \
-DMYSQL_DATADIR="/var/lib/mysql/" \
-DWITH_BOOST="/compile/boost/"
Вот что делает каждый из них:
-
DBUILD_CONFIGнастраивает исходный дистрибутив с теми же параметрами сборки, что и для выпусков MySQL (мы собираемся переопределить некоторые из них). -
DCMake_BUILD_TYPEсRelWithDebInfoвключает оптимизацию и создает отладочную информацию. -
DWITH_DEBUGпозволяет использовать параметр--debug="d,parser_debug"при запуске MySQL. Это приводит к тому, что синтаксический анализатор Bison, используемый для обработки операторов SQL, выводит трассировку синтаксического анализатора в стандартный вывод ошибок сервера. Обычно этот вывод записывается в журнал ошибок. -
DFEATURE_SETуказывает, что мы собираемся установить функции сообщества. -
DENABLE_DTRACEвключает поддержку зондов DTrace. Зонды DTrace на сервере MySQL предназначены для предоставления информации о выполнении запросов в MySQL и различных областях системы, используемых во время этого процесса. -
Опция
DWITH_SSLдобавляет поддержку зашифрованных соединений, энтропию для генерации случайных чисел и другие операции, связанные с шифрованием. -
DWITH_ZLIBвключает поддержку библиотеки сжатия для функцийCOMPRESS()иUNCOMPRESS(), а также сжатие протокола клиент/сервер. -
DCMake_INSTALL_PREFIXзадает расположение нашего базового каталога установки. -
DINSTALL_LIBDIRуказывает, куда установить файлы библиотеки. -
DINSTALL_SBINDIRуказывает, куда установитьmysqld. -
DWITH_INNODB_MEMCACHEDсоздает общие библиотеки memcached (libmemcached.so и innodb_engine.so). -
DDOWNLOAD_BOOSTзаставляет CMake загрузить библиотекуboostи поместить ее в место, указанное с помощьюDWITH_BOOST. -
DWITH_VALGRINDвключает Valgrind, открывая Valgrind API коду MySQL. Это полезно для анализа утечек памяти. -
DINSTALL_PLUGINDIRопределяет, где компилятор будет размещать библиотеки плагинов. -
DMYSQL_DATADIRопределяет расположение каталога данных MySQL. -
DWITH_BOOSTопределяет каталог, в который CMake будет загружать библиотекуboost.
После того, как мы запустим CMake, мы собираемся скомпилировать MySQL с помощью команды make. Для оптимизации процесса компиляции мы будем использовать параметр -j, который указывает, сколько потоков мы собираемся использовать для компиляции MySQL. Поскольку в нашем случае у нас есть 16 ядер ARM, мы собираемся использовать 15 потоков (оставив один для действий ОС):
# make -j 15
# make install
Этот процесс может занять некоторое время, и он очень подробный. После его завершения мы можем увидеть бинарники в каталоге baseir:
# ls -l /compile/basedir/binОбратите внимание, что мы не найдем двоичный файл mysqld в каталоге /compile/build/bin/, вместо этого мы увидим mysqld-debug. Это связано с параметром DWITH_DEBUG, который мы установили ранее:
# /compile/build/bin/mysqld-debug --version
/compile/build/bin/mysqld-debug Ver 8.0.23-debug-valgrind for Linux on aarch64 (Source distribution)
Теперь мы можем протестировать наш двоичный файл. Для этого мы собираемся вручную создать каталоги и настроить разрешения:
# mkdir /var/log/mysql/
# mkdir /var/run/mysqld/
# chown ubuntu: /var/log/mysql/
# chown ubuntu: /var/run/mysqld/
Затем добавим эти настройки в /etc/my.cnf:
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
log-error = /var/log/mysql/error.log
Далее мы собираемся инициализировать словарь данных MySQL:
# /compile/basedir/bin/mysqld-debug --defaults-file=/etc/my.cnf --initialize \
--user ubuntu
Теперь MySQL готов к запуску:
# /compile/basedir/bin/mysqld-debug --defaults-file=/etc/my.cnf --user ubuntu &Будет создан временный пароль, и мы можем извлечь его из журнала ошибок:
# grep "A temporary password" /var/log/mysql/error.log
2021-02-14T16:55:25.754028Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: yGldRKoRf0%T
Теперь мы можем подключиться с помощью клиента MySQL по нашему выбору:
# mysql -uroot -p'yGldRKoRf0%T'
mysql: [Warning] Using a password on the command line interface can be
insecure. Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.23-debug-valgrind
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Анализ сбоев MySQL
Мы говорим, что MySQL аварийно завершает работу, когда процесс mysqld завершает работу без соответствующей команды завершения работы. MySQL может аварийно завершать работу по разным причинам, включая следующие:
Аппаратный сбой (память, диск, процессор)
Ошибки сегментации (неверный доступ к памяти)
Ошибки
Был убит процессом
OOMРазличные другие причины, такие как космические лучи.
Процесс MySQL может получать ряд сигналов от Linux. К числу наиболее распространенных относятся следующие:
- Signal 15 (
SIGTERM) -
Вызывает отключение сервера. Это похоже на выполнение оператора
SHUTDOWNбез необходимости подключения к серверу (для завершения работы требуется учетная запись с привилегиейSHUTDOWN). Например, следующие две команды приводят к обычному завершению работы:# systemctl stop mysql # kill -15 -p $(pgrep -x mysqld) - Signal 1 (
SIGHUP) -
Заставляет сервер перезагружать таблицы разрешений и очищать таблицы, журналы, кэш потоков и кэш хоста. Эти действия похожи на различные формы оператора
FLUSH:mysql> FLUSH LOGS;или:
# kill -1 -p $(pgrep -x mysqld) - Signal 6 (
SIGABRT) -
Бывает, потому что что-то пошло не так. Он обычно используется
libcи другими библиотеками для прерывания программы в случае критических ошибок. Например,glibcотправляетSIGABRT, если обнаруживает двойное освобождение или другое повреждение кучи.SIGABRTзапишет подробности сбоя в журнал ошибок MySQL, например:18:03:28 UTC - mysqld got signal 6 ; Most likely, you have hit a bug, but this error can also be caused by... Thread pointer: 0x7fe6b4000910 Attempting backtrace. You can use the following information to find out where mysqld died. If you see no messages after this, something went terribly wrong... stack_bottom = 7fe71845fbc8 thread_stack 0x46000 /opt/mysql/8.0.23/bin/mysqld(my_print_stacktrace(unsigned char const*... /opt/mysql/8.0.23/bin/mysqld(handle_fatal_signal+0x323) [0x1032cc3] /lib64/libpthread.so.0(+0xf630) [0x7fe7244e5630] /lib64/libc.so.6(gsignal+0x37) [0x7fe7224fa387] /lib64/libc.so.6(abort+0x148) [0x7fe7224fba78] /opt/mysql/8.0.23/bin/mysqld() [0xd52c3d] /opt/mysql/8.0.23/bin/mysqld(MYSQL_BIN_LOG::new_file_impl(bool... /opt/mysql/8.0.23/bin/mysqld(MYSQL_BIN_LOG::rotate(bool, bool*)+0x35)... /opt/mysql/8.0.23/bin/mysqld(MYSQL_BIN_LOG::rotate_and_purge(THD*... /opt/mysql/8.0.23/bin/mysqld(handle_reload_request(THD*, unsigned... /opt/mysql/8.0.23/bin/mysqld(signal_hand+0x2ea) [0xe101da] /opt/mysql/8.0.23/bin/mysqld() [0x25973dc] /lib64/libpthread.so.0(+0x7ea5) [0x7fe7244ddea5] /lib64/libc.so.6(clone+0x6d) [0x7fe7225c298d] Trying to get some variables. Some pointers may be invalid and cause the dump to abort. Query (0): Connection ID (thread ID): 0 Status: NOT_KILLED The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains information that should help you find out what is causing the crash. 2021-02-14T18:03:29.120726Z mysqld_safe mysqld from pid file... - Signal 11 (
SIGSEGV) -
Указывает на ошибку сегментации, ошибку шины или нарушение прав доступа. Как правило, это попытка доступа к памяти, к которой процессор не может физически обратиться, или нарушение прав доступа. Когда MySQL получает
SIGSEGV, будет создан дамп ядра, если настроен параметрcore-file. - Signal 9 (
SIGKILL) -
Заставляет процесс немедленно завершиться (убивает его). Это, наверное, самый известный сигнал. В отличие от
SIGTERMиSIGINT, этот сигнал нельзя перехватить или проигнорировать, а процесс-получатель не может выполнить какую-либо очистку после получения этого сигнала. Помимо вероятности повреждения данных MySQL,SIGKILLтакже заставит MySQL выполнить процесс восстановления при перезапуске, чтобы привести его в рабочее состояние. В следующем примере показано, как вручную отправить сигналSIGKILLпроцессу MySQL:# kill -9 -p $(pgrep -x mysqld)Кроме того, процесс Linux
OOMвыполняетSIGKILLдля завершения процесса MySQL.
Давайте попробуем проанализировать сбой, когда MySQL получил сигнал 11:
11:47:47 UTC - mysqld got signal 11 ;
Most likely, you have hit a bug, but this error can also be caused by...
Build ID: Not Available
Server Version: 8.0.22-13 Percona Server (GPL), Release 13, Revision 6f7822f
Thread pointer: 0x7f0e46c73000
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 7f0e664ecd10 thread_stack 0x46000
/usr/sbin/mysqld(my_print_stacktrace(unsigned char const*, unsigned...
/usr/sbin/mysqld(handle_fatal_signal+0x3c3) [0x1260d33]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x128a0) [0x7f0e7acd58a0]
/usr/sbin/mysqld(Item_splocal::this_item()+0x14) [0xe36ad4]
/usr/sbin/mysqld(Item_sp_variable::val_str(String*)+0x20) [0xe38e60]
/usr/sbin/mysqld(Arg_comparator::compare_string()+0x27) [0xe5c127]
/usr/sbin/mysqld(Item_func_ne::val_int()+0x30) [0xe580e0]
/usr/sbin/mysqld(Item::val_bool()+0xcc) [0xe3ddbc]
/usr/sbin/mysqld(sp_instr_jump_if_not::exec_core(THD*, unsigned int*)+0x2d)...
/usr/sbin/mysqld(sp_lex_instr::reset_lex_and_exec_core(THD*, unsigned int*...
/usr/sbin/mysqld(sp_lex_instr::validate_lex_and_execute_core(THD*, unsigned...
/usr/sbin/mysqld(sp_head::execute(THD*, bool)+0x5c7) [0x1068e37]
/usr/sbin/mysqld(sp_head::execute_trigger(THD*, MYSQL_LEX_CSTRING const&...
/usr/sbin/mysqld(Trigger::execute(THD*)+0x10b) [0x12288cb]
/usr/sbin/mysqld(Trigger_chain::execute_triggers(THD*)+0x18) [0x1229c98]
/usr/sbin/mysqld(Table_trigger_dispatcher::process_triggers(THD*...
/usr/sbin/mysqld(fill_record_n_invoke_before_triggers(THD*, COPY_INFO*...
/usr/sbin/mysqld(Sql_cmd_update::update_single_table(THD*)+0x1e98) [0x11ec138]
/usr/sbin/mysqld(Sql_cmd_update::execute_inner(THD*)+0xd5) [0x11ec5f5]
/usr/sbin/mysqld(Sql_cmd_dml::execute(THD*)+0x6c0) [0x116f590]
/usr/sbin/mysqld(mysql_execute_command(THD*, bool)+0xaf8) [0x110e588]
/usr/sbin/mysqld(mysql_parse(THD*, Parser_state*, bool)+0x4ec) [0x111327c]
/usr/sbin/mysqld(dispatch_command(THD*, COM_DATA const*...
/usr/sbin/mysqld(do_command(THD*)+0x204) [0x1116554]
/usr/sbin/mysqld() [0x1251c20]
/usr/sbin/mysqld() [0x2620e84]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x76db) [0x7f0e7acca6db]
/lib/x86_64-linux-gnu/libc.so.6(clone+0x3f) [0x7f0e78c95a3f]
Trying to get some variables.
Some pointers may be invalid and cause the dump to abort.
Query (7f0e46cb4dc8): update table1 set c2_id='R', c3_description='testing...
Connection ID (thread ID): 111
Status: NOT_KILLED
Please help us make Percona Server better by reporting any
bugs at https://bugs.percona.com/
Трассировка стека анализируется сверху вниз. Из сбоя видно, что это Percona Server v8.0.22. Далее мы видим, что поток создается на уровне ОС в этот момент:
/lib/x86_64-linux-gnu/libpthread.so.0(+0x76db) [0x7f0e7acca6db]Продолжая движение вверх по стеку, путь кода входит в MySQL и начинает выполнять команду:
/usr/sbin/mysqld(do_command(THD*)+0x204)...И путь кода, который дает сбой, — это функция Item_splocal:
/usr/sbin/mysqld(Item_splocal::this_item()+0x...Немного изучив код MySQL, мы обнаруживаем, что Item_splocal является частью кода хранимой процедуры. Если мы посмотрим на конец трассировки стека, то увидим запрос:
Query (7f0e46cb4dc8): update table1 set c2_id='R', c3_description='testing...Триггеры также могут использовать путь к хранимой процедуре, если они содержат переменные. Если мы проверим, есть ли в этой таблице триггеры, мы увидим следующее:
CREATE DEFINER=`root`@`localhost` TRIGGER `table1_update_trigger`
BEFORE UPDATE ON `table1` FOR EACH ROW BEGIN
DECLARE vc1_id VARCHAR(2);
SELECT c2_id FROM table1 WHERE c1_id = new.c1_id INTO vc1_id;
IF vc1_id <> P THEN
INSERT INTO table1_hist(
c1_id,
c2_id,
c3_description)
VALUES(
old.c1_id,
old.c2_id,
new.c3_description);
END IF;
END
;;
Со всей этой информацией мы можем создать тестовый пример и сообщить об ошибке:
USE test;
CREATE TABLE `table1` (
`c1_id` int primary key auto_increment,
`c2_id` char(1) NOT NULL,
`c3_description` varchar(255));
CREATE TABLE `table1_hist` (
`c1_id` int,
`c2_id` char(1) NOT NULL,
`c3_description` varchar(255));
insert into table1 values (1, T, test crash);
delimiter ;;
CREATE DEFINER=`root`@`localhost` TRIGGER `table1_update_trigger`
BEFORE UPDATE ON `table1` FOR EACH ROW BEGIN
DECLARE vc1_id VARCHAR(2);
SELECT c2_id FROM table1 WHERE c1_id = new.c1_id INTO vc1_id;
IF vc1_id <> P THEN
INSERT INTO table1_hist(
c1_id,
c2_id,
c3_description)
VALUES(
old.c1_id,
old.c2_id,
new.c3_description);
END IF;
END
;;
Чтобы воспроизвести его, мы запускаем несколько команд одновременно в одной таблице, пока не произойдет ошибка:
$ mysqlslap --user=msandbox --password=msandbox \
--socket=/tmp/mysql_sandbox37515.sock \
--create-schema=test --port=37515 \
--query="update table1 set c2_id='R',
*c3_description='testing crash' where c1_id=1" \
--concurrency=50 --iterations=200
Эту ошибку относительно легко воспроизвести, и мы рекомендуем вам протестировать ее. Вы можете найти более подробную информацию об этой ошибке в системе Percona Jira.
Также мы можем видеть, что Oracle исправила ошибку в версии 8.0.23 благодаря примечаниям к выпуску:
Иногда ошибки нелегко воспроизвести, и их исследование может быть очень утомительным. С этим возникают проблемы даже у опытных инженеров, особенно при расследовании утечек памяти. Мы надеемся, что мы пробудили ваше любопытство к расследованию сбоев.
Об авторах
Винисиус Гриппа (Vinicius Grippa) — старший инженер службы поддержки, работающий в Percona, и старший партнер Oracle. Винисиус имеет степень бакалавра компьютерных наук и уже 13 лет работает с базами данных. Он имеет опыт проектирования баз данных для критически важных приложений и за последние несколько лет стал специалистом по экосистемам MySQL и MongoDB. Работая в команде поддержки, он помог клиентам Percona с сотнями различных случаев с широким спектром сценариев и сложностей. Винисиус также активно участвует в сообществе ОС, участвуя в виртуальных комнатах, таких как Slack, выступая на встречах и выступая на конференциях в Европе, Азии, Северной и Южной Америке.
Сергей Кузьмичев — старший инженер службы поддержки Percona. Ему нравится разгадывать хорошие технические загадки, работать с базами данных и создавать надежные системы. Сергей часто пишет код и отправляет отчеты об ошибках в проекты с открытым исходным кодом, а также пишет сообщения в блогах о MySQL и других базах данных с открытым исходным кодом. До прихода в Percona Сергей почти десять лет работал администратором баз данных и DevOps-инженером.
Колофон
Животные на обложке Learning MySQL — синие пятнистые вороны (Euploea midamus), бабочки, обитающие в Индии и Юго-Восточной Азии.
Этот вид бабочек в основном черный и темно-коричневый, с белыми пятнами на груди и внешней части крыльев. Синие пятна на их крыльях создаются преломленным светом как структурный цвет и на самом деле не являются цветом поверхности крыла.
Как и у многих видов бабочек, гусеницы синих пятнистых ворон питаются в основном листьями и стеблями одной группы растений; в их случае семейство Apocynaceae/dogbane. Их яйца откладываются на нижней стороне растений этого семейства. Гусеницы проходят через пять возрастов, прежде чем окукливаются и становятся взрослыми. Затем взрослые бабочки питаются нектаром многих цветов, иногда собираясь в большом количестве, чтобы питаться на одном растении. Они используют свой хоботок, чтобы направить цветочный нектар в рот.
Внутренние мембраны крыльев бабочки покрыты тонким слоем мелких перекрывающихся чешуек. Края этих крошечных чешуек рассеивают и преломляют свет, создавая переливчатость, а также синий цвет (чешуйки также выполняют функциональную функцию, защищая от воды и помогая рассеивать тепло). Исследования показывают, что крылья бабочек (таких как Euploea) имеют свои собственные четкие узоры чешуи. Некоторые бабочки из рода Euploea также были изучены на предмет их ультра-черной окраски.
Часто встречается сине-пятнистая ворона, и, хотя в некоторых частях ее ареала вид находится под защитой, IUCN не оценивал ее охранный статус. Многие животные на обложках O'Reilly находятся под угрозой исчезновения; все они важны для мира.
Цветная иллюстрация на обложке выполнена Карен Монтгомери на основе черно-белой гравюры из Музея живой природы Чарльза Найта (1844). Шрифты обложки — Gilroy Semibold и Guardian Sans. Текстовый шрифт — Adobe Minion Pro; шрифт заголовка — Adobe Myriad Condensed; а шрифт кода — Ubuntu Mono Далтона Маага.